
Arbori de Decizie in Recunoasterea Modelului
1.Introducere
O metoda interesanta si eleganta din punct de vedere estetic si intuitiv in luarea unei decizii este aceea de a actiona pe mai multe etape, luand decizii partiale pe parcurs. Astfel de proceduri au cateva caracteristici atractive, cea mai importanta dintre acestea fiind, poate, intelegerea. Cel care ia decizia are sentimentul ca el sau ea (sau algoritmul, daca este implementat pe o masina de calcul) are controlul asupra situatiei astfel incat unele erori in deciziile partiale pot fi corectate in etape ulterioare sau chiar luand-o de la capat spre inceput. In multe situatii, luarea unor astfel de decizii partiale este simpla deoarece ele cer examinarea informatiei relevante doar pentru etapa curenta. Acest lucru ar salva cheltuiala de a aduna informatii ce nu sunt necesare pentru etapa curenta. Aceste aspecte au contribuit la popularitatea luarii deciziei in etape multiple in cateva probleme de tehnologie, recunoasterea formelor devenind una majora.
O definitie aproximativa a recunoasterii formelor in contextul unor metode cu etape multiple este atribuirea unui obiect fizic sau a unui eveniment la una dintre categoriile specificate inainte. Problema principala in sistemele cu mai multe etape este proiectarea unei scheme de clasificare. Alte probleme importante sunt definirea informatiilor potrivite avand elemente pentru clasificare, specificarea metodelor pentru extragerea lor, modelarea si validarea datelor si estimarea performantei schemei proiectate. Destul de des, doar o multime finita de informatii este data pentru a ajuta proiectarea si acest lucru ar putea necesita sa faci presupuneri rapide asupra structurii statistice a datelor. Arborii de decizie ofera avantaje diferite cand reprezentarea foarte variata este nerealista pentru cantitatea limitata de date. Daca un arbore de decizie este bine proiectat, rezultatul este o schema de clasificare care este precisa, flexibila si eficienta din punct de vedere al calculului. Flexibilitatea in luarea deciziei asupra modelului mareste aplicabilitatea sa intr-o gama larga de probleme. Totusi, aceasta reprezentare mai putin restrictiva deschide atat de multe posibilitati in construirea unei scheme cu mai multe nivele astfel incat nu exista metoda directa pentru a proiecta arborii de decizie. Proiectantul poate permite schite care au functii de decizie extrem de complexe pentru fiecare nod sau foarte simple precum deciziile binare avand ca punct de plecare comparatia unei singure variabile. Mai mult, un arbore care este simplu de schitat poate sa nu fie simplu in operarea asupra (exemplelor-modelelor de teste) testelor exemplu si vice versa. Aceste aspecte tind sa-l incurce pe proiectant, care ar putea sfarsi cu un arbore de decizie fara sa poata specifica de ce sau cum clasificatorul particular este potrivit pentru aceasta problema. Obiectivele acestei analize sunt :
-(I) sa consolideze metodologiile majore pentru schitarea arborelui de
decizie ;
-(II) sa prezinte lucrurile pe care le au in comun ;
-(III) sa dea o semnificatie in mecanismul de clasificare in mai multe
etape;
-(IV) sa discrediteze anumite mituri precum ideea ca arborii de decizie sunt intotdeauna simplu de proiectat si folosit ;
-(V) sa mentioneze ariile lor de aplicare ;
-(VI) in general sa ajute proiectantul in selectarea unei tehnici adecvate sau in elaborarea uneia potrivite pentru problema particulara in cauza.
Nevoia unei analize noi apare din trei motive. Primul, cresterea recunoasterii ca in ansamblu schemele optime pe mai multe etape nu sunt nici necesare, nici utile pentru aplicatiile practice de scurta durata. Al doilea,ezitanta a faptului ca marimea setului testului proba este intotdeauna mai mica decat se doreste. Si in sfarsit, ca o consecinta, dezvoltarea unor tehnici destul de variate in proiectarea arborilor de decizie.
Principala dificultate in atingerea scopurilor de mai sus este imposibilitatea virtuala de a descrie pe scurt munca diferitilor autori intr-o insemnare comuna. Sectiunea 2, dupa prezentarea principalei insemnari, stabileste nevoia si descrie o metoda pentru luarea unei decizii pe mai multe etape pentru anumite probleme de recunoastere a modelului. Sectiunea 3 clasifica o multime a scheletelor arborelui de decizie in trei mari grupe. Dificultatea chiar si numai in folosirea arborelui, ce are o structura pe mai multe etape cu trasaturi si clase specifice, este infatisata in mod clar. Un tur al principalelor metode de proiectare este realizat in Sectiunea 4. Nu s-au raportat prea multe despre analiza performantei arborilor de decizie. Marea majoritate a metodelor de proiectare se bazeaza pe antrenament si preciziile setului de teste. Sectiunea 5 atinge acest aspect. Sectiunea 6 este devotata unei discutii comparative a tuturor metodelor si a unor probleme specifice care nu sunt altfel acoperite. Cateva aplicatii sunt indicate in Sectiunea 7 si Sectiunea 8 rezuma concluziile majore.
O referinta avantajoasa pentru a incepe discutia despre recunoasterea modelului arborilor este Kanal [35], care studiaza abordari demersuri interactive ale analizei modelului. Pe atunci, era notat ca performanta datelor testului independent ale invatarii singure si alte noi demersuri cad nu departe de asteptare. Acest lucru a dus la recunoasterea ca solutia problemelor de clasificare ale modelului nu se afla in intregime in echipamentele de invatare, demersuri statistice, filtrarea spatiala, programare euristica, demersuri lingvistice formale sau in orice alta solutie particulara sustinuta viguros de unul sau alt grup din acel timp. Analiza interactiva a modelului este un mod de a permite examinarea structurii datelor modelului. Structurile ierarhice formeaza o importanta categorie a reprezentarii datelor si arborii de decizie sunt potriviti in mod natural pentru recunoasterea modelului cu o astfel de reprezentare a datelor. Wu [63] descrie apropierea arborelui de decizie de clasificarea datelor multivariate in mod normal, distribuite multispectral. Avantajele majore considerate aici sunt imbunatatirea in acuratetea clasificarii cu modele finite, eficienta calculului si oportunitatea in aplicatii. Ele furnizeaza perspicacitate in problema dimensionalitatii si propun abordarea arborelui pentru a o invinge. Interpretarea histograma, gruparea secventiala si apropierea optima de model sunt descrise.
Kulkarni [40] investigheaza proprietatile teoretice ale unui model general de scheme de recunoastere cu mai multe etape si clase. Modelul permite o larga clasa de scheme parametrice si nonparametrice in interiorul scheletului. El propune doua clase de strategii de cautare pentru a obtine decizii optime. Clasificatorii ierarhici sunt tipuri speciale mult mai practice de scheme de recunoastere a modelului pe mai multe etape. O interpretare de trei faze este propusa pentru schema clasificatorilor ierarhici. Fazele individuale sunt proiectarea scheletului arborelui, caracteristica selectiei la nodurile sale si expresia functiei de decizie la fiecare nod. Aceste metode optime de proiectare sunt grele din punct de vedere al calculului pentru probleme medii si mari. Cateva metode euristice sunt explorate pentru a reduce complexitatea modelului. Unele dintre ele sunt:
(I) gruparea regulilor de decizie si eliminarea multimilor de reguli
suboptimale fara sa le evalueze individual si
(II) ordonarea trasaturilor si metode ramificate si marginite. Mai este examinata si relatia dintre performanta, dimensiunea modelului si numarul nivelelor de cuantificare. Anderson si Fu [1] in dezvoltarea arborilor liniari binari pentru clasificarea leucocita, revizuiesc alte metode precum spatiul de stari, arborele-joc si abordarile de partitionare.
In descrierea muncii anterioare, Bell [4] propune ajungerea la un tabel de decizie cu reguli initiale de inceput si interactiv schimband regulile de la nu-mi pasa la da sau nu si vice versa. Tabelul de decizie astfel obtinut este convertit in arbori binari de una din cele cateva metode sugerate. Payne si Preece [53] incearca o sinteza a unei literaturi mari si destul de dispersate in identificarea cheilor si tabelelor diagnostic. Ei definesc cheia ca un tabel cu doua coloane. Prima coloana este un set de teste. A doua este identificarea sau indexul pentru testul urmator de a fi condus. Pe de alta parte, un tabel diagnostic este definit ca avand atatea randuri ca numarul de identificari (clase). Intrari corespunzatoare coloanei a doua de aici inainte sunt proprietatile reprezentand identificarile. Autorii discuta despre meritele relative a celor doua tipuri de reprezentari si recunoasterea modelului citat ca o aplicatie pentru folosirea lor. Ei ating concepte optime si probabilistice si interpretari teoretice de decizie pentru selectia testelor (caracteristicilor). Ei mai mentioneaza aplicatii botanice, codate, electronice, medicale, microbiologice si zoologice, cat si aplicatii ale tabelelor de decizie si prime implicants. Moret [48] studiaza arborii de decizie si diagramele avand aplicatii raspandite oriunde functiile discrete trebuie sa fie evaluate secvential. El stabileste o schema comuna a definitiilor si revizuieste contributiile de la cateva campuri de aplicatii precum bazele de date, programarea tabelului de decizie, teoria complexitatii concrete, teoria schimbarii si recunoasterea modelului. Cartea recenta a lui Bretman [6] dezvolta clasificarea si progresul arborilor ca o unealta pentru analiza statistica a datelor. Metodologia lor principala este impartirea de sus in jos pentru a structura si clasifica datele. Acest lucru este mai potrivit pentru analiza datelor si regresiunea nonlineara decat pentru problemele curente de recunoastere a modelului. Prezenta lucrare subliniaza arborii de decizie si aplicatiile lor la recunoasterea modelului.
2. O baza formala pentru Arborii de Decizie
Un mod convenabil de a introduce arborii de decizie consta in considerarea unei probleme pentru care clasificatorul optim pare sa fie o decizie pe mai multe etape pentru realizarea unei scheme. Incorporarea costurilor caracteristicilor stabilite ca parte a costului total pentru minimizare asigura o astfel de baza.
Problema fundamentala in recunoasterea statistica a modelului este design-ul clasificatorului de risc minim al lui Bayes. Schema diminueaza costul asteptat al clasificarii atunci cand valorile costului general sunt asociate cu combinatii posibile de clasificari corecte si gresite. O tratare excelenta a acestei probleme este disponibila in Duda si Hart [21]. Daca costul fiecarei clasificari gresite este unitatea si cel al fiecarei clasificari corecte este zero, schema de decizie este identica cu aceea a probabilitatii minime de eroare. O extindere a problemei de clasificare de risc minim este permiterea masurarii caracteristicilor pentru a crea costuri.
Intr-un asemenea mediu de recunoastere a modelului, cel care ia decizia sau schema de clasificare ar trebui sa evalueze valoarea informatiei ce trebuie descoperita de catre o masurare a caracteristicii relationata cu costul sau. Reducerea posibila a riscului clasificarii folosind rezultatul masuratorii poate fi neinsemnata in comparatie cu costul masurarii caracteristicii. Cel mai bun exemplu pentru a ilustra acest lucru este in diagnosticul medical. Pentru a diagnostica intre orice multime de presupuse tulburari, exista de obicei un set mare de teste disponibile. Unele pot fi foarte costisitoare, vatamatoare sau poate chiar potential fatale pentru pacient. Astfel, daca nu este necesar, nu toate testele vor fi realizate. Intuitiv, este mai bine sa incepem cu teste simple. Bazat pe rezultatele acestor teste, este posibil, in anumite instante, sa poata fi luata o decizie. Chiar daca mai multe teste sunt necesare, rezultatele observate anterior pot indica care din teste costisitoare este posibil sa ofere informatia ceruta pentru diagnostic. Astfel, luarea unei decizii se realizeaza in mai multe etape. La fiecare etapa schema presupune doua optiuni principale: Decizia asupra unei etichete de clasa si terminarea procesului sau masurarea unei caracteristici pentru a aduna mai multe informatii. Ar trebui notat ca daca masuratorile nu costa nimic, nu se obtine nimic daca nu se masoara caracteristica, asa ca cea mai buna schema ar conduce toate masuratorile si decide asupra etichetei clasei intr-un singur mod. Acest lucru reduce schema la clasificatorul de risc minim.
2.1 Costul minim al problemei de recunoastere a modelului
Argumentele calitative de mai sus sunt dezvoltate prin studierea proprietatilor schemei optime pentru urmatoarea problema. Se da
(I) O multime Ω de M clase ωi cu probabilitatile lor a priori P (ωi),
i = 1, , M,
(II) Un vector de N caracteristici , F = (f 1, , fN) in care
caracteristicile sunt ordonate arbitrar, cu costurile lor corespunzatoare
masurarii ci, i = 1, , N,
(III) M functii de densitate ale probabilitatii conditionate pentru clasele complet cunoscute (sau functii concentrate) p (x | ωi), i = 1,, M, unde x = (x1, .., xN) este un rezultat N-variabil al celor N caracteristici si
(IV) Matricea A de dimensiune M x M a pierderilor cu
λij ![]() 0 reprezentand costul creat daca se
hotaraste ca o mostra a modelului de la o clasa
adevarata ωi apartine lui ωj.
0 reprezentand costul creat daca se
hotaraste ca o mostra a modelului de la o clasa
adevarata ωi apartine lui ωj.
Se cere sa se ajunga la construirea unei scheme de decizie cu un cost total minim asteptat, in care costul total este suma dintre costul masuratorii si riscul clasificarii.
Evident, pe orice mostra a modelului, folosind mai multe caracteristici va micsora riscul de clasificare gresita, dar va creste costul masuratorii. Posibilitatile extreme sunt :
(I) De a nu realiza nici o masuratoare si de a clasifica mostra la o baza minima de risc a priori si
(II) De a realiza masuratorile tuturor caracteristicilor (creand costurile lor) si dinimuarea riscului a posteriori.
Cea mai buna alegere se gaseste undeva la mijloc si dificultatea este ca variaza de la mostra la mostra, facand ca desenul schemei optime sa fie foarte complex.Argumentele anterioare dau niste idei despre comportamentul schemei optime. Aceste idei sunt perfectionate in continuare prin revizuirea unor fapte elementare, dar interesante despre recunoasterea modelului.
Cel mai important dintre toate este faptul ca, clasificatorul optim pentru problema costului minim este o decizie pe mai multe etape de realizare a schemei. Prin realizarea etapelor multiple, schema retine optiunea de a se imprastia-raspandi si fara o particularitate costisitoare nemasurata inca, daca masuratorile deja realizate indica (din punct de vedere statistic) non-optimalitatea sa. Daca, totusi, rezultatele observate indica faptul ca masuratori viitoare sunt necesare, una sau mai multe dintre caracteristicile ramase pot fi masurate. Extinzand acest argument in continuare, este mai usor de aratat ca masurarea unei singure caracteristici dintr-o etapa este optima. Dovezi exacte sunt disponibile la Dattatreya [18]. Wald [62] considera o problema si mai generala unde costurile masuratorilor caracteristicilor sunt functii ale rezultatelor lor si ale secventelor in care sunt masurate. In unele dintre aceste cazuri, masuratoarea a mai mult de o caracteristica la o etapa pare sa fie optima. Totusi, pentru recunoasterea practica a modelului, costurile caracteristicilor sunt cel mai bine modelate ca si constante permitand unei caracteristici pe etapa sa fie optima.
Daca caracteristicile sunt cerute sa fie masurate pe rand, o solutie directa este o secventa optima a masuratorilor caracteristicii. Se poate ajunge la cea mai buna secventa a unei probleme date. Schema de decizie gaseste urmatoarea caracteristica specificata pentru masurare daca precizia asteptata (sau riscul de clasificare) este imbunatatita. Aceasta este recunoasterea secventiala a modelului studiata intensiv de Fu [25]. O secventa de caracteristici care nu se schimba cand masuratorile sunt facute nu este optima asa cum arata urmatorul exemplu; la orice etapa intermediara, cea mai buna caracteristica pentru urmatoarea masuratoare este o functie a tuturor masuratorilor disponibile.
Exemplu: Un clasificator al modelului de doua clase masoara o caracteristica f 1 la prima etapa. Costul masuratorii a inca doua caracteristici disponibile f 2 si f 3 sunt egale si sunt suficient de mari pentru a opri o masuratoare viitoare, dupa masurarea unei dintre ele la o a doua etapa. Toate caracteristicile sunt binare si sunt clase in mod conditionat independente statistic. Clasa functiilor concentrate de probabilitati conditionate ale lui f 2 si f 3 sunt date in Tabelul 1. Probabilitatile modificate ale clasei ω1 la sfarsitul primei etape, P (ω1| x1) sunt date in Tabelul 2. Obiectivul acestui exemplu este aceea de a arata ca f 2 este mai bun decat f 3 pentru un rezultat al lui f si f 3 este mai bun decat f 2 pentru celalalt rezultat al lui f 1. Probabilitatile de erori pentru cele doua scheme sunt reprezentate in Tabelul 2 ca si functii ale rezultatelor lui f 1. In mod clar f 2 da o rata mai mica de eroare daca x1 = 0 si f 3, daca x1 = 1. Astfel schema de decizie aratata in Fig. 1 (c) este mai buna decat cele din Figurile 1 (a) si 1 (b). In figura, nodurile neterminale conduc la masuratori de caracteristici specificate si lasa ca in schema de decizie sa intre nodurile descendente bazate pe rezultatul caracteristicii masurate. Rezultatele sunt indicate pe ramurile relevante.
2.2 Solutii de programare dinamica
S-a aratat in mod logic nevoia teoretica pentru arborii de decizie pentru o clasa a problemelor de recunoastere a modelului (cele ce implica costuri de masurare a caracteristicilor), decat recurgerea la arbori de decizie ca o alternativa la alta schema. Exemplul este trivial din moment ce este stiut ca folosirea tuturor celor trei masuratori este extrem de costisitoare. Daca ar fi fost mai multe caracteristici de costuri tolerate, ar trebui sa punem doua intrebari:
(I) Care este costul asteptat daca masuratoarea viitoare este abandonata in favoarea deciderii asupra etichetei clasei cel mai putin riscante?
(II) Care este costul asteptat (suma dintre costul masuratorii si riscul de clasificare) daca schema masoara o caracteristica candidata f i si foloseste metoda optima dupa aceea?
Pentru a raspunde la aceste intrebari, avem nevoie de o nota pentru a face structuri de decizie pe mai multe etape. Multi termeni, de ex. noduri, ramuri, si descendenti directi se presupune ca nu sunt ambigui.
TABELUL 1 TABELUL 2
Functiile concentrate de probabilitate P(eroare | x1) ca functie a
-------- ----- ------ ------- caracteristicii utilizata la
P(xi |![]() j etapa a doua
j etapa a doua ![]()
![]()
![]()
![]() ----- ----- --------- ----- -------- -------- ----- ------ -------
----- ----- --------- ----- -------- -------- ----- ------ -------
Clasa x x Eroare
![]()
![]() ----- ----- --------- ----- -------- x P(
----- ----- --------- ----- -------- x P(![]() |x ) ----- ----- --------
|x ) ----- ----- --------
0 1 0 1 f f
![]()
![]() -------- ----- ------ ------- -------- ----- ------ -------
-------- ----- ------ ------- -------- ----- ------ -------
![]()
![]()
![]() 0.6 0.4 0.2 0.8 0 0.4 0.22 0.26
0.6 0.4 0.2 0.8 0 0.4 0.22 0.26
0.1 0.9 0.7 0.3 1 0.6 0.28 0.24
-------- ----- ------ ------- -------- ----- ------ --------
![]()
![]()
![]()
![]()
0/1 0/1
![]()
![]()
![]()
![]()
![]()
![]()
0 1 0 1
![]()
![]()
![]()
![]()
(a) (b


![]() 0 1
0 1
![]()
![]()
![]()
![]()
![]()
![]()
0 1 0 1
![]()
![]()
![]()
![]()
(c)
Fig.1 Schemele de alternare pentru exemplul dat.
ni este al i-ulea nod neterminal in stuctura luarii deciziei. Neterminal, in sensul ca exista o masuratoare a caracteristicii la ni. Felul in care aceste noduri sunt numerotate nu este inca specificat. Un nod terminal este un descendent direct al unui nod neterminal si corespunde unei decizii de clasa ωj. In general, ni are atat multimi de noduri direct descendente terminale cat si multimi de noduri direct descendente neterminale..
D(ni) este multimea nodurilor neterminale direct descendente (daca exista) ale nodului neterminal ni.
Daca nj este descendentul
neterminal al lui ni, f(ni nj)
este caracteristica care va fi masurata la nj, daca schema de decizie coboara de la ni
la nj. In mod natural, f (ni nj)
![]() . c
(ni nj) este
costul masurarii f (ni nj). z (ni nj) este
rezultatul obtinut la masurarea lui f (ni nj).
. c
(ni nj) este
costul masurarii f (ni nj). z (ni nj) este
rezultatul obtinut la masurarea lui f (ni nj).
F(ni) este o submultime a multimii de caracteristici F si cuprinde toate caracteristicile masurate pana la, si incluzand, nodul ni. y (ni ) este rezultatul obtinut dupa masurarea tuturor F (ni). y (ni) este | F(ni ) | - variabila in cadrul careia rezultatele individuale sunt ordonate ca in vectorul x = (x , , xN ) .
Dupa masuratoarea caracteristicii la nodul ni, riscul sau costul asteptat al clasificarii (a fi creat daca se decide ca sa se clasifice mostra ca apartinand lui ωj) este dat de
R
ωj y (ni)) = ![]() λkj P(ωk | y (ni)
λkj P(ωk | y (ni) ![]() (2.1)
(2.1)
folosind notatia de mai sus si terminologia problemei definite mai devreme.
R* y (ni)) = ![]() R(ωj | y (ni) (2.2)
R(ωj | y (ni) (2.2)
![]()
este riscul minim (conditionat de y (ni), observatiile facute) daca se decide sa se termine masurarea caracteristicii si sa se faca o clasificare dupa nodul ni.
Totusi, daca nodul neterminal ni are decendenti care sunt ei insisi neterminali, masurarea caracteristicii este posibila in continuare. Pentru a decide intre masurarea caracteristicii in continuare si clasificare, este nevoie sa se astepte crearea costului daca o sa se faca in continuare masuratori. Fie nj un descendent direct al lui ni ; E*( y (nj )), costul optim asteptat ce va fi creat dupa observarea lui z (ni nj) la nodul nj. Retinem ca z (ni nj) si y (ni) impreuna (ordonate corespunzator) constituie y (nj ). De asemenea E*(y (nj)) insusi depinde de deciziile optime la nj si descendentii lui. Costul asteptat inca sa fie creat dupa ni la deciderea de a cobori la nj este costul asteptat sa fie creat la si dupa nj.Acesta este costul masurarii caracteristicii la nj, c(ni nj), plus costul optim asteptat a fi creat ulterior. Aceasta ar trebui sa fie in mod corespunzator totalizata intr-o medie a tuturor rezultatelor lui f (ni nj), deoarece nu am observat z (ni nj), dar doar studiem mutarea de la nj la ni. Asadar,
E(ni y (ni)) = c (ni nj)
+ ![]() E*(y (nj)) p( z(ni nj) | y (ni)) dz
(ni nj) (2.3)
E*(y (nj)) p( z(ni nj) | y (ni)) dz
(ni nj) (2.3)
este costul optim asteptat, conditionat de rezultatele observate y (ni), inca de a fi creat daca este luata o decizie de a cobori la nodul nj de la ni . Dar coborarea la nj in particular poate sa nu fie optima daca sunt alte elemente in
D (ni ). Deci,
E*(y (ni)) min (2.4)
este costul minim asteptat al tuturor deciziilor posibile la nodul ni, conditionate de toate observatiile facute pana la acel stadiu, y (ni).
La unele noduri din graful caracteristicilor, nu vor mai fi alte caracteristici pentru a fi masurate in continuare. Asemenea noduri au doar noduri terminale ca descendenti. Daca nk este un asemenea nod, F (nk) = F,
multimea totala de caracteristici si y (nk) = x, rezultatul N-variabil. Costul minim asteptat (inca de a fi creat) intr-un asemenea nod este dat de insusi riscul minim al clasificarii.
E*(nk | x) = ![]()
![]() λij
P(ωi | x) (2.5)
λij
P(ωi | x) (2.5)
Deci, fiind data o structura a luarii unei decizii cu mai multe etape ca cea din Fig.1 (c), este posibil prin procedura de programare dinamica recursiva sa calculezi costul minim asteptat al intregului arbore. Un produs secundar al unui asemenea calcul il reprezinta regulile optime de decizie in fiecare etapa, pentru fiecare rezultat. Dar daca ne sunt date doar statisticile si costurile, cum procedam? Proprietatile clasificatorului optim discutat mai devreme ne ajuta. In orice etapa, consideram masurarea unei caracteristici, pe rand, din toate caracteristicile inca nemasurate. Aceasta este prea greoaie pentru a fi folositoare in practica, in special daca numarul caracteristicilor este prea mare si caracteristicile sunt continue. Cu toate acestea, este folositor sa studiezi un asemenea mecanism al schemei construirii unei decizii optime si design-ului ei.
2.3 Reprezentarea grafului deciziei
Structura luarii unei decizii (numita de acum inainte graful caracteristicilor) pe care pot fi scrise ecuatiile de programare dinamica cuprinde :
(I) Un nod radacina ce corespunde etapei zero cu nici o caracteristica
atribuita;
(II) N nivele de noduri sub nodul radacina, ce corespund celor N
etape posibile de masurari ale caracteristicilor;
(III) N-i noduri direct descendente pentru fiecare al i-ulea nod al
etapei (conectat prin legaturi unidirectionale); fiecare nod direct
descendent masoara o caracteristica ce nu a fost deja masurata la
primele i etape pe drumul ce conduce la al i-ulea nod al etapei
considerate, si
(IV) N! drumuri distincte dar suprapuse de la etapa zero, ce corespund
celor N! ordonari ale caracteristicilor.
Doua sau mai multe drumuri se unesc intr-un nod la etapa i daca ele masoara aceeasi multime de i caracteristici pana la, si incluzand nodul de unire. Asadar, exista un nod ce corespunde fiecarei submultimi de caracteristici. In total, sunt 2N noduri, incluzand nodul radacina ce corespunde multimii vide de caracteristici.
Un graf al caracteristicilor cu patru caracteristici este desenat in Fig. 2. Nodurile sunt numerotate intr-o ordine anume. Observati ca daca nj este descendentul lui ni, atunci ni >nj. Cu o asemenea numerotare, costurile optime in timpul procedurii de programare dinamica sunt evaluate pornind de la primul nod si urcand in concordanta cu numerele atasate nodurilor, pana la nodul radacina. Aceasta asigura utilitatea costurilor optimale ale tuturor descendentilor unui nod cand acestea sunt necesare pentru a evalua costul optim al nodului in discutie.

![]()

![]()
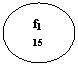
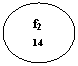
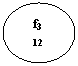
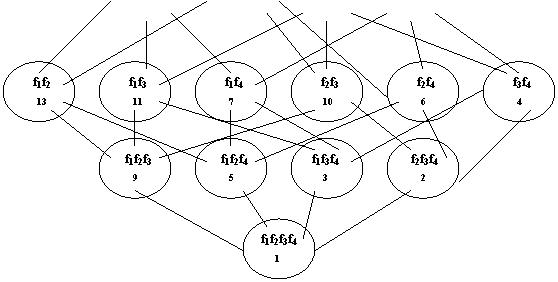
Fig.2 Graful caracteristicilor al unei probleme cu patru caracteristici.
Numerotarea nodurilor din Fig. 2 este specifica si nu avanseaza cu un rand la o extindere. Aceasta este facuta pentru a simplifica calcularea numerelor nodurilor tuturor descendentilor directi ale unui nod arbitrar in timpul calcularii costului sau optim. Matematic, fie
L( ni ) = ( ![]() (ni ) , ,
(ni ) , , ![]() N ( ni )) (2.6)
N ( ni )) (2.6)
o formula binara ce corespunde fiecarui nod ni in graful caracteristicilor astfel incat
![]()
0, daca fj ![]() F( ni
F( ni
![]() j (ni =
j (ni =
1, altfel (2.7)
L (ni) denota caracteristicile masurate pana la, si inluzand, nodul ni. Apoi numarul nodului (sau index-ul nodului) i al nodului ni, este dat de
i = 1 + ![]()
![]() j (ni j-1 (2.8)
j (ni j-1 (2.8)
Aceasta permite calcularea numarului unui nod dand caracteristicile masurate si vice versa. Se observa ca indexul nodului radacina (stadiul zero) este 2N, la care nicio caracteristica nu este masurata. Numarul descendentilor directi ai nodului ni este doar numarul celor din formula binara L (ni), deoarece γj = daca f j nu a fost masurat. Asadar
| D(ni) | = ![]()
![]() j (ni (2.9)
j (ni (2.9)
Fie dk (ni) al k-lea descendent direct al nodului ni, adica
D(ni) = , k= 1, , ![]()
![]() j (ni (2.10)
j (ni (2.10)
Suntem interesati de calcularea numarului nodului pentru dk (ni). Fie dk (ni) = nj. Se observa ca L (ni ) este obtinut prin inlocuirea celui de-al k-lea cu zero in L (ni). Prin urmare,
j = i - 2m-1
unde m este cel mai mic numar intreg ce satisface
![]()
![]() t (ni ) = k
(2.12)
t (ni ) = k
(2.12)
Este acum posibil sa rezolvam sistematic procedura de programare dinamica pe graful caracteristicilor cu noduri numerotate (sau indexate) pornind de la primul nod in care toate caracteristicile ar fi fost masurate. Metodologia completa este conturata mai jos.
Pasul 1: pentru nodul n1 se evalueaza
E*(y (n1)) ![]()
![]() λkj
P(ωk | x)
λkj
P(ωk | x)
Aceasta, de asemenea, da regulile de decizie adecvate pentru toti y (n ). Se retine ca: y (n ) = x .
Pasul 2: Pentru ni, i = 2, , (2N - 1), se evalueaza
R*(y (ni)) ![]()
![]() λkj
P(ωk | y( ni ))
λkj
P(ωk | y( ni ))
Pentru nj = dk (ni), k = 1, , | D (ni ) |, se evalueaza
E(nj |
y (ni)) = c(ni nj )
+ ![]() E y nj p z ni nj y ni dz ni nj
E y nj p z ni nj y ni dz ni nj
E*(y (ni)) min
Aceasta de asemenea da regulile de decizie pentru toti y (ni).
Pasul 3: La nodul radacina, ni , i = 2N , y (ni) = ø este vid ; se evalueaza
R*(ni |
![]()
![]() λkj
P(ωk | ø)
λkj
P(ωk | ø)
Regula optima de decizie este doar caracteristica optima care sa fie masurata in prima etapa, mai putin atunci cand se dovedeste ca problema este una patologica, in cazul in care metoda optima este de a decide o eticheta a clasei bazandu-se pe riscul a priori.
Imposibilitatea procedurii de mai sus pentru problemele practice de recunoastere a modelului, chiar avand un numar moderat de caracteristici, este imediat evidenta. In primul rand, pentru caracteristicile continue nu este posibil sa se obtina expresii inchise pentru E (nj | y (ni)) chiar si cu cele mai simple functii de densitate a probabilitatii. Aceasta, precum si faptul ca diferitele regiuni ale deciziei dau functii diferite pentru integrarea peste spatiul caracteristicilor masurate, face calcularea unei medii pentru a obtine costurile optime si regulile de decizie pentru toate valorile variabilelor continue y (ni) virtual imposibila. Independenta conditionata statistic de clasa a caracteristicilor nu simplifica procedura, deoarece densitatea conditionata p (z ( ni nj ) | y (ni)) folosita in expresia (2.3) este un amestec al tuturor claselor. Densitatile amestecului nu pot avea niciodata componente statistic independente. Daca
p ( x1x2)
= P(![]() 1) p (x1x2 |
1) p (x1x2 | ![]() 1)
+ P(
1)
+ P(![]() 2)
p (x1x2 |
2)
p (x1x2 | ![]() 2)
(2.13)
2)
(2.13)
poate fi factorizat ca g1(x1) g2(x2),
atunci p (x1x2 | ![]() 1)
si p (x1x2 |
1)
si p (x1x2 | ![]() 2)
trebuie sa aiba aceiasi factori (din moment ce acestea sunt
functii nenegative ce integreaza aceeasi valoare, adica
unitatea) cauzand caracteristicilor sa degenereze in aceeasi
functie de densitate pentru ambele clase.
2)
trebuie sa aiba aceiasi factori (din moment ce acestea sunt
functii nenegative ce integreaza aceeasi valoare, adica
unitatea) cauzand caracteristicilor sa degenereze in aceeasi
functie de densitate pentru ambele clase.
Pentru caracteristicile discrete, procedura optima poate fi perfectionata pentru design-ul masinilor arborilor de decizie, dar doar pentru un numar redus de caracteristici cu cel mult cateva nivele discrete pentru fiecare. Metoda descrisa in [19] si [20] ordoneaza toate rezultatele ale tuturor caracteristicilor masurate pana in stadiul actual (in graful caracteristicilor, de exemplu, in Fig, 2) intr-un mod special convenabil. Un calcul recurent al costurilor optime este apoi implementat pe computer.
Un alt neajuns al acestui schelet teoretic este ca cere specificarea completa a structurii probabilistice fundamentale. In practica, o problema de recunoastere a modelului este de obicei definita pornind de la o multime de probe experimentate (etichetate). Numarul probelor va fi inadecvat pentru a modela sau estima dependenta caracteristicilor prin mijloace pur statistice. Alte particularitati precum incapacitatea modelului formal de a incorpora sarcina de calculare a dus la modele alternative pentru recunoasterea modelului in mai multe etape.
3. Modele pentru recunoasterea modelelor cu mai multe etape
Fu [25], vazand problema costului minim ca o versiune generalizata a recunoasterii secventiale a modelului, a propus un algoritm atat pentru ordonarea caracteristicilor cat si pentru clasificarea acestora. Dar schema rezultata nu a fost interpretata ca simplificata la un arbore de decizie aplicabil in practica. Ulterior, cateva schelete de arbori de decizie, care in principiu incearca sa exploateze proprietatile favorabile si sa usureze unele probleme asociate cu schema costului minim al deciziei, au evoluat. Modelele individuale se concentreaza pe sub-seturi ale aspectelor proprietatilor de atractie si folosesc de asemenea tehnici pentru a depasi dezavantajele specifice. Desi o astfel de abordare nu este recomandabila din punct de vedere al dezvoltarii unei teorii generale, ar trebui sa retinem ca pentru o problema data cu un numar finit de probe de instruire si cu resurse de calculare limitate, nu este nici posibil, nici necesar sa fie incercate solutii foarte generale. Concentrarea asupra particularitatilor specifice problemei este de ajutor in realizarea celor mai bune rezultate.
La particularitati si regularitati specifice ale unei probleme particulare de recunoastere a modelului se ajunge prin analiza modelului. Analiza interactiva a modelului (Kanal [36], [37]) este un mod de a permite examinarea structurii de date intr-un spatiu de mare dimensiune. Oamenii sunt superiori in recunoasterea anumitor tipuri de structuri. Examinarea umana este in general facilitata de expunerea grafica a diferitelor trasformari de date. Procedura consta in folosirea oricarei informatii despre problema in discutie pentru a ghida strangerea datelor despre modelele si clasele de modele care pot exista in mediul ce este examinat, si apoi a supune datele la o varietate de proceduri pentru a deduce structurile deterministe si probabiliste care sunt prezente in date. Aceasta se mai numeste si analiza de exploatare a datelor si include graficele de histograme, de dispersie, rutinele de analiza a grupurilor, analiza lineara diferentiata, aplicatia nelineara, analiza variatiei, etc. Un exemplu relevant al unui sistem de analiza interactiva a modelului este ISPAHAN (Gelsema [26]). Acest sistem permite utilizatorului sa investigheze interactiv structura datelor multidimensionale folosind un meniu de optiuni, incluzand clasificarea supervizata si non-supervizata, aplicarea algoritmilor si transformarea caracteristicilor. De asemenea, suporta analiza interactiva si design-ul sistemelor de clasificare cu mai multe etape. Intr-un alt studiu recent, Friedman si Stuetzle [24] raporteaza niste scheme de urmarire a proiectiei pentru detectarea, descrierea si validarea structurii in multimi de puncte
p-dimensionale. Acestea, precum si multe alte metode de analiza a datelor ajuta in selectarea unui model in mai multe etape deja existent sau in dezvoltarea unui nou model pentru problema de recunoastere a modelui in discutie.
3.1 Modelele spatiului de stari.
O structura de decizie schitata pentru problema costului minim arata in mod obisnuit precum cea prezentata in Fig. 3. Caracteristica ce trebuie masurata initial in prima etapa este specificata. Ulterior, nodurile ce trebuie traversate depind de rezultatele observate. Precum este explicat in Sectiunea 2, este foarte greu sa tii socoteala sau sa precizezi regulile optime de decizie, deoarece acest lucru implica realizarea unei medii a tuturor costurilor la nodurile descendente.

![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Un graf al spatiului de stari G este asemanator cu un subgraf (Fig. 3) al grafului caracteristicilor cu diferenta ca nodurile neterminale din G pot masura mai mult de o caracteristica la un nod si ca fiecare nod neterminal ni tine socoteala multimii de clase care apar ca nodurile sale descendente terminale (nu neaparat descendente direct). Nodurile terminale cu etichete de clasa sunt de asemenea explicit incluse in graful spatiului de stari, lucru care nu se intampla si in cazul grafului caracteristicilor. Matematic, G este format din sapte componente:
G
unde:
(i) S = este mutimea nodurilor (starilor);
(ii) E = este multimea arcelor . Exista arc de la nodul ni la
nodul nj doar daca nj este un descendent direct al lui ni ;
(iii) F este multimea totala a caracteristicilor;
(iv) este multimea totala a claselor;
(v) C este o functie reala nenegativa de evaluare a costului pe arce;
c (ni nj) este costul caracteristicilor masurate cu o tranzitie de la
ni la unul dintre descendentii sai directi, nj.
(vi) R este o functie cu valoare reala definita pe multimea nodurilor
tinta (terminale) ce reprezinta valoarea asteptata a costului sau
pierderii creata in realizarea clasificarii deciziei asociate cu
nodul tinta si
(vii) T este strategia folosita in deciderea caror noduri vor fi
traversate in graf.
Diferenta esentiala intre aceasta formulare si graful deciziei din Fig. 3 este ca f (ni nj), caracteristica masurata intr-o singura tranzitie de la ni la nj nu este in mod necesar unica. f (ni nj) este o submultime a lui F. Similar, c (ni nj) este suma costurilor tuturor caracteristicilor in f (ni nj) si z (ni nj) este mai degraba un vector variabil decat un scalar. Aceste definitii sunt extinse pentru cazul in care nj nu este un descendent direct, dar este un descendent oarecare al lui ni. Adica, f (ni nj) este multimea caracteristicilor masurate dupa ni pana la, si inclusiv nj. De asemenea, Ω (nj) este o submultime a lui este setul claselor in discutie la nj.
Daca nj este un nod terminal, | Ω (nj)|= . In afara de aceste adaptari, notatia este esential aceeasi ca cea din Sectiunea 2. Cativa termeni noi sunt introdusi atunci cand este nevoie. Nu este bine ca complexitatea situatiilor posibile in recunoasterea modelului pe mai multe etape sa nu permita folosirea unei notatii simple.
O importanta clasa de scheme in interiorul modelului spatiului de stari este clasificatorul ierarhic in care grupuri de clase formeaza o ierarhie. Astfel de scheme au avantajul de a putea folosi o cunostinta a priori in ceea ce priveste relatiile fizice si biologice dintre subgrupurile multimii de clase. Chiar si in situatii fara astfel de relatii, o analiza explorativa a datelor poate sa scoata in evidenta usurinta distingerii diferitelor submultimi de clase folosind diferite submultimi de trasaturi. Aceasta abordare va reduce de asemenea complexitatea clasificatorului rezultat. Cel mai lung drum in graful spatiului de stari nu va fi mai mare decat numarul claselor, din moment ce, cel putin o clasa este eliminata la o etapa. Astfel, Ω (nj) este o sbumultime potrivita a lui Ω (ni) daca nj este un descendent al lui ni. La nodul radacina (sau starea initiala) nicio caracteristica nu este masurata si este considerata multimea tuturor claselor. De asemenea, in clasificatorii ierarhici fiecare nod are un parinte unic.
Un proces de clasificare este o strategie pentru cautarea in graf a unui nod terminal cu costul cel mai mic. Acest proces depinde de formularea costului. Costul unui nod tinta ni este suma dintre costurile masuratorilor si riscul clasificarii. Riscul poate fi o functie de observatii doar de-a lungul drumului catre nodul tinta acceptat sau pe toate masuratorile. Strategia de cercetare depinde in mod natural de acest lucru. In primul caz, costul total al nodului terminal ni este
s (ni) = C (ni) + R ( (ni) | y (ni))
unde y (ni) reprezinta observatiile facute de-a lungul drumului doar catre ni . In al doilea caz
s (ni) = C (ni) + R ( (ni) | x) (3.2)
unde x este observatia datorata tuturor masuratorilor posibile. Urmatorii algoritmi, Algoritm-S si Algoritm-B, corespund celor doua cazuri.
Algoritm-S
Pasul 1: Pune nodul radacina intr-o mutime OPEN. Goleste o multime numita CLOSED.
Pasul 2 Pentru fiecare ni ![]() OPEN, se evalueaza
OPEN, se evalueaza
s (ni) = C (ni) + h (ni) + r (ni)
unde h (ni)![]()
![]() = 0 daca ni este
un nod tinta
= 0 daca ni este
un nod tinta
![]() minnj
minnj![]() T
(ni C (ni nj) daca ni nu este
un nod tinta
T
(ni C (ni nj) daca ni nu este
un nod tinta
r (ni) = R ( (ni) | y (ni)) daca ni este un nod tinta
=min nj![]() T
(ni min z(ni nj) R( (nj), z (ni nj)]
daca ni nu este
T
(ni min z(ni nj) R( (nj), z (ni nj)]
daca ni nu este
un nod tinta
Pasul 3: Fie nk un nod care apartine multimii OPEN avand s () minim. Se elimina nk din multimea OPEN si se adauga la multimea CLOSED. Se adauga toti descendentii directi ai lui nk in multimea OPEN. Daca nk este un not teminal, se accepta eticheta corespunzatoare clasei si se iese din algoritm. Altfel se merge la Pasul 2.
In algoritmul de mai sus, functia s (ni) calculata este o limita inferioara a costului total care ar fi creat de un exemplu de model dat care ar fi intrat in nodul ni cu caracteristica de observare y (ni). Daca aceasta limita inferioara este suficient de aproximativa pentru a egala costul actual, exemplul de model va ajunge la nodul tinta adecvat fara sa se faca masuratori inutile. Altfel, schema va conduce masuratoarea nu numai pe drumul catre tinta finala acceptata, dar si la mai multe noduri. Totusi, ceea ce este minimizata este suma dintre riscul de clasificare la nodul tinta si costul doar acelor caracteristici masurate de-a lungul drumului catre nodul tinta.
Presupunerea ca riscul este o functie a observatiilor de-a lungul drumului catre nodul tinta (si nu catre alte noduri) poate fi valabila in problemele in care diferite multimi de caracteristici sunt cunoscute a fi folositoare pentru clase diferite. In cazuri extreme densitati conditionate ale claselor anumitor caracteristici pot sa nu fie definite sau pot degenera sa fie egale pentru anumite clase. In general, totusi, riscul este o functie a tuturor masuratorilor (vezi expresia 3.2) pentru care este relevanta urmatoarea procedura.
Algoritm-B
Pasul 1: Se pune starea initiala in multimea OPEN. Multimea
CLOSED se face vida .
Pasul 2 Pentru fiecare nod ni ![]() OPEN, se evalueaza
OPEN, se evalueaza
s (ni) = C (ni) + h (ni) + r (ni)
unde h (ni) = 0, daca ni este un nod tinta
![]() minnj
minnj![]() T(nj)
C (ni nj), daca
ni nu este un nod tinta
T(nj)
C (ni nj), daca
ni nu este un nod tinta
r (ni ) ![]() min
v R ( (ni) | y (ni)
, v) daca ni
este un nod tinta
min
v R ( (ni) | y (ni)
, v) daca ni
este un nod tinta
![]() min
v min nj
min
v min nj![]() T
(ni R( (nj) | y (ni) , v) daca ni nu este
T
(ni R( (nj) | y (ni) , v) daca ni nu este
un nod tinta
unde v este rezultatul tuturor caracteristicilor care nu apartin lui F (ni).
Pasul 3 Fie nk nodul care apartine multimii OPEN cu s () minima. Se muta nk din multimea OPEN in multimea CLOSED si se pun toti descendentii directi al lui nk (daca exista vreunul) in multimea OPEN.
Pasul 4 Pentru fiecare nod tinta ni
![]() CLOSED, se evalueaza limita
superioara a lui b (ni) unde
CLOSED, se evalueaza limita
superioara a lui b (ni) unde
b (ni) = C (ni ) + max v R ( (ni) | y (ni) , v)
Fie nk nodul terminal care
apartine multimii CLOSED pentru care b ( ) este minima.
Daca pentru toate nodurile nj ![]() OPEN
OPEN ![]() CLOSED,
nj ≠ nk ,
CLOSED,
nj ≠ nk ,
b (nk) ≤ s (nj), atunci se iese cu nk ca si tinta optima B; Altfel se merge la Pasul 2.
Cand riscul este o functie a tuturor masuratorilor, se poate termina cautarea doar atunci cand este sigur ca masuratori aditionale nu vor conduce spre o oricare alta tinta clasificata mai sus decat nodul tinta deja aflat in multimea CLOSED. Acest lucru este indeplinit prin folosirea unei limitei superioare a functiei b (ni). Dovezi exacte ca acesti algoritmi sunt admisibili in respectivele lor sensurile sunt disponibile in Kulkarni [40]. El mai discuta de asemenea despre modelele spatiului de stari pentru recunoasterea modelului nonparametric ca scheme vecine cele mai apropiate in care costurile masuratorii caracteristicilor dau nastere din nou la scheme pe mai multe etape. Tipic, costul ce trebuie minimizat este suma dintre costul masuratorii si distanta dintre modelul test si cel mai apropiat vecin. Schema de recunoastere poate fi implementata ca o strategie de cautare similara cu cea discutata mai sus. Aceste strategii de cautare presupun existenta unui graf al spatiului de stari adecvat problemei respective. Design-ul unor astfel de structuri de decizie este discutat in Sectiunea 4.
3.2 Modele independente de subrecunoastere
Una din modalitatile de simplificare a recunoasterii modelului este impartirea problemei in alte cateva probleme mai mici. Daca una urmareste o schema optima din punct de vedere global, interactiunea acestor subscheme devine inadmisibil de complexa si design-ul lor chiar si mai complex. O schimbare practica ar fi sa se faca design-ul subschemelor ignorand interdependenta lor. O combinatie logica a rezultatelor acestor subscheme ar trebui atunci sa fie corespunzatoare pentru clasificarea finala a exemplului de model dat.
Ichino [33]-[35] studiaza cateva modele de acest tip. Specificatii majore ale unor astfel de modele sunt tipurile de subscheme ce trebuie folosite si metoda combinarii rezultatelor lor. Primul tip este sistemul dual de recunoastere de clasa. In aceasta metoda, un clasificator este proiectat pentru fiecare pereche de clase folosind o submultime de caracteristici pentru fiecare pereche. Rezultatul fiecarui subclasificator este eticheta uneia sau a doua clase considerate. Fie ca numarul claselor sa fie M. Pentru a ajunge la eticheta clasei finale, se face o contorizare a fiecarei clase din rezultatul subsistemelor M (M-1)/2. Numarul maxim pentru orice clasa este M-1, deoarece M-1 clasificatori sunt considerati pentru orice clasa particulara. De asemenea, daca contorizarea unei clase este M-1, nici o alta clasa nu poate sa aiba aceeasi proprietate, deoarece orice alta clasa ar fi fost eliminata de cel putin un clasificator care considera acea clasa si pe aceea a carei contorizare a fost M-1. Asadar, Ichino sugereaza faptul ca un model este decis in final ca apartinand unei clase daca si numai daca acea clasa are contorizarea M- . Altfel, modelul este respins ca fiind neclasificat. Totusi, ar trebui notat ca alte combinatii precum majoritatea deciziilor de calcul sunt posibile. Aceasta metoda are unele avantaje cand analiza a priori a cunostintelor sau datelor indica posibilitatea distingerii intre perechi de clase diferite si submultimi mici de caracteristici. Dar daca numarul claselor este mare, numarul schemelor de subrecunoastere, M(M-1)/2, tinde sa fie impracticabil.
Alternativ, subschemele pot considera o clasa in defavoarea restului, caz in care vor exista doar M subscheme. Aceasta se numeste sub-recunoastere simetrica a "clasei intelepte". Clasificarea finala este facuta doar daca o schema accepta acea clasa. In aceasta metoda exista doua tipuri de eliminare. Primul tip, cand doua sau mai multe scheme de subrecunoastere accepta clasele lor respective. Celalalt tip, cand nicio schema nu-si accepta clasa sa. O modalitate de a evita primul tip de respingere este aceea de a accepta prima clasa pe care schema de subrecunoastere o accepta. Dar, atunci, este importanta ordonarea claselor intr-un anume mod.
Cand un numar mare de clase formeaza o multime omogena de puncte intr-un spatiu metric, cea mai buna metoda este aceea de a realiza un clasificator bun pentru o multime mica de etichete ale clasei desenate la intamplare din multimea mare originala. Acest clasificator poate fi folosit ca ultima etapa a unei scheme cu mai multe etape in care multe clase sunt eliminate cu o acuratete mare in etapele initiale. Acest model este propus si folosit pentru recunoasterea vorbirii la populatii mari de catre Dante [12] si de catre Dante si Sarma [13], [14]. Tehnica pe care ei o folosesc pentru a simplifica modelul este de a presupune, pentru scopuri analitice, ca insasi eticheta clasei este o variabila continua dintre variabilele continue de caracteristici. Starea sistemului de clasificare in orice etapa este definita ca un numar de vorbitori luati inca in calcul. Problema realizarii clasificatorului pare atunci sa fie alocarea caracteristicilor la etape potrivite si definirea metodelor pentru tranzitiile starilor. Problema este rezolvata prin folosirea tehnicilor stochastice de control optim.
3.3 Modele top- down
Discutia de pana acum clarifica faptul ca singura modalitate de a obtine decizii optime in recunoasterea modelului pe mai multe etape este de a folosi costurile optime ale posibilelor cursuri ale actiunii dupa etapa prezenta. Aceasta procedura "bottom-up" necesita calcul si memorie enorme. In practica, utilizatorul poate fi mai interesat de scheme simple ce duc la un compromis intre complexitatea operatiei si performanta in termeni a costurilor. Un model evident pentru acest scop este acela in care schema de decizie specifica explicit actiunea ca o functie a caracteristicii masurate in etapa in discutie. Acesta este un avantaj doar din punctul de vedere al operatiei clasificatorului si se adauga la complexitatea design-ului. Dattatreya si Sarma [18] propun o astfel de metoda si o demonstreaza pentru o problema foarte mica cu trei caracteristici Gaussiene . Metoda implica realizarea schemei costului minim si modificarea ei intr-un arbore de decizie care ia decizii prin comparatii initiale cu caracteristica masurata la orice etapa. Fie nj un descendent direct al nodului ni din prima etapa, si nk descendentul direct al lui nj. Cu terminologia uzuala (considerand doar o caracteristica pe etapa), costul optim ce trebuie sa fie creat daca este luata o decizie de a cobori la nodul nk
E* (nk | y (nj))
este o functie a observatiei z (ni nj) la nodul nj , la fel ca si singura observatie anterioara y (ni). Cea mai buna modalitate de a scapa de y (ni) este de a calcula o medie a lui y (ni).
E (nk
| z (ni nj))
= ![]() E* nk | y (nj), z(ni nj))
p(y
(ni)) dy (ni) (3.3)
E* nk | y (nj), z(ni nj))
p(y
(ni)) dy (ni) (3.3)
unde regiunea de integrare se extinde doar peste acele valori ale lui y (ni) pentru care un exemplu al modelului ajunge la nodul nj. Acesta, facut din toti descendentii directi nk ai lui nj, faciliteaza luarea deciziei la nj bazata pe functia unei singure variabile z (ni nj). Schema de decizie ce rezulta poate fi implementata folosind comparatii initiale. Calculul mediei trebuie sa fie facut de sus in jos, dupa realizarea schemei costului minim si implica eliminarea unei singure variabile la un moment dat. Aceasta este o tehnica pentru a modifica regiunile complexe de decizie in regiuni hiper rectangulare pentru a ajunge la o schema foarte simpla pentru operatie. Totusi, dincolo de asigurarea perspicacitatii in mecanismul clasificarii pe mai multe etape, metoda este putin folosita pentru probleme practice. In general, simplitatea design-ului este de asemenea foarte importanta.
Metodele top-down" in realizarea arborilor de decizie de obicei implica in mod repetat selectarea unei caracteristici si segmentarea regiunii sale. De obicei aceste metode realizeaza scheme de clasificare de la o multime relativ mica de modele etichetate si foloseste reguli nonparametrice de impartire. Doua clase distincte ale acestor metode sunt:
(I) Partitionarea intregului spatiu caracteristic de intrare si convertirea schemei de decizie rezultate intr-un arbore. Convertirea acestor tabele in arbori poate fi realizata de sus in jos sau de jos in sus. Henrichon si Fu [30] prezinta o astfel de procedura care in general nu clasifica in mod corect toate modelele design-ului. Meisel si Michalopoulos [47] prezinta o alta procedura pentru o clasificare suta la suta corecta.
(II) Partitionarea caracteristicilor pe rand si repetarea acestui lucru asupra subregiunilor rezultate in vederea dezvoltarii dinamice a unui arbore.
Amintim ca un clasificator poate fi intotdeauna realizat astfel incat sa clasifice corect toate modelele etichetate date. Din moment ce acesta va avea un efect advers asupra modelelor test ce vor fi clasificate (vezi Hughes [31]), multe din metodele de mai sus incorporeaza reguli de oprire pentru a preveni impartiri prea fine ale spatiului caracteristic.
Unele scheme folosesc o privire inainte cu un pas sau functii simple de evaluare pentru costuri dupa etapa prezenta, decat sa fie pur si simplu de sus in jos. Brelman [6], [7] foloseste o functie a complexitatii arborelui aditionala preciziei de clasificare. Aceste modele de design al arborilor de sus in jos nu considera costurile masuratorilor caracteristicilor cum au fost definite in Sectiunea 2. Intrebarea evidenta, asadar, este de ce folosim arborii de decizie ? Wu [63] scoate in evidenta nevoia ca clasificatorii de arbori de decizie sa rezolve problemele dimensionalitatii si dimensiunii mici a modelului. Alte avantaje precum eficienta calculului pe durata operarii asupra arborilor de decizie si intelegerea procesului de clasificare justifica folosirea lor. Sectiunea urmatoare discuta despre metodologii de design pentru arborii de decizie.
|
Politica de confidentialitate |
| Copyright ©
2024 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |