Accelerarea procesului de adunare/scadere in virgula flotanta
Vom aborda problematica imbunatatirii performantei adunarii si scaderii in virgula flotanta, supunand analizei, prin prisma operatiilor consumatoare de timp, algoritmul din anteriorul paragraf. Dintre toate operatiile in care poate fi disecata procedura, drept critice se prezinta adunarile si scaderile [HePa03].
Astfel, referindu-ne
mai intai la adunari, acestea apar in pasii 3 (la evaluarea
complementului de doi), 5 (la calculul sumei/diferentei preliminare si
la eventuala complementare de doi a significand-ului rezultat preliminar)
si 8 (la adunarea unei unitati binare pentru rotunjire). Aparent
am fi confruntati cu patru activari ale sumatorului, dar, asa
cum remarcam la prezentarea pasului 5, atunci cand sunt indeplinite
conditiile care reclama complementarea de doi a lui![]() , avem
, avem ![]() deci adunarea/scaderea se executa exact si nu
mai este necesara rotunjirea din pasul 8. Cu alte cuvinte, algoritmul
prezentat implica, in caz defavorabil, cel mult trei activari ale
sumatorului. Dar oricum, acestea revendica un consum insemnat de timp,
luand in consideratie ca ele se executa pe (
deci adunarea/scaderea se executa exact si nu
mai este necesara rotunjirea din pasul 8. Cu alte cuvinte, algoritmul
prezentat implica, in caz defavorabil, cel mult trei activari ale
sumatorului. Dar oricum, acestea revendica un consum insemnat de timp,
luand in consideratie ca ele se executa pe (![]() ) biti, avand, conform standardului IEEE 754,
) biti, avand, conform standardului IEEE 754, ![]() biti in single -
precision, respectiv
biti in single -
precision, respectiv ![]() biti in double -
precision.
biti in double -
precision.
Pe de alta
parte, referindu-ne la deplasari, acestea, in mod evident, sunt cu atat
mai critice cu cat se realizeaza pe mai multe pozitii binare. Ca
si anterior, in mod aparent, astfel de deplasari pe mai multi
biti ar trebui efectuate atat in pasul 4 (de aliniere a numerelor
significand), cat si in pasul 6 (dedicate normalizarii preliminare a
significand-ului rezultat), intrucat la normalizarea definitiva de
dupa rotunjirea din pasul 8 poate aparea doar deplasare cu o
pozitie la dreapta. Sa defalcam aceasta analiza in
functie de valoarea absoluta a diferentei exponentilor d,
si anume sa consideram, mai intai, situatia cand ![]() deci cand, in pasul 4, avem o deplasare - la dreapta - de cel
mult o pozitie. In aceste conditii, in pasul 6 poate rezulta o
deplasare - la stanga - de doua (a se vedea si cazul exemplu f, din
fig. 5.12) sau mai multe pozitii binare. Daca insa
deci cand, in pasul 4, avem o deplasare - la dreapta - de cel
mult o pozitie. In aceste conditii, in pasul 6 poate rezulta o
deplasare - la stanga - de doua (a se vedea si cazul exemplu f, din
fig. 5.12) sau mai multe pozitii binare. Daca insa ![]() in pasul 4 avem o deplasare - la dreapta - de mai multi
biti, situatie in care in pasul 6, asa cum am vazut, are
loc o deplasare - la stanga - de cel mult un bit (vezi si cazurile exemplu
a la e din fig. 5.12). Conclusiv, deplasari pe doua sau mai multe
pozitii binare nu pot aparea in ambii pasi, 4 si 6, ci doar
in unul dintre ei.
in pasul 4 avem o deplasare - la dreapta - de mai multi
biti, situatie in care in pasul 6, asa cum am vazut, are
loc o deplasare - la stanga - de cel mult un bit (vezi si cazurile exemplu
a la e din fig. 5.12). Conclusiv, deplasari pe doua sau mai multe
pozitii binare nu pot aparea in ambii pasi, 4 si 6, ci doar
in unul dintre ei.
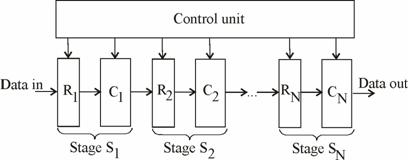
A Relativ la situatia expusa, o prima posibilitate de accelerare a procesului de adunare/scadere consta in apelarea la conceptul de pipeline aritmetic cu care imbunatatirea de performanta provine de la cresterea capacitatii de trecere (throughput). Aceasta inseamna ca, suprapunand etape ale desfasurarii procesului de adunare/scadere pentru diferite astfel de operatii inlantuite mai degraba decat executand in secventa aceste operatii, in acelasi interval de timp pot fi executate mai multe adunari/scaderi. Pentru a putea fi aplicata, metoda de executie suprapusa in maniera pipeline a operatiilor implica necesitatea ca acestea sa fie divizate in suboperatii atribuite unor asa numite stagii (stages) sau segmente, a caror durata sa fie cat mai echilibrata si care sa nu produca conflicte de resurse sau de date dupa modelul executiei suprapuse a instructiilor unui procesor [HePa03]. O schema generala pentru
|
|
|
Fig. 5.16 |
o structura pipeline destinata
aritmeticii este prezentata in fig. 5.16 [Haye98]. Fiecare stagiu ![]() are alocat un registru
latch
are alocat un registru
latch ![]() , uzual multicuvant pentru stocarea datelor, si o
subunitate de prelucrare a datelor
, uzual multicuvant pentru stocarea datelor, si o
subunitate de prelucrare a datelor ![]() , constand, uzual, dintr-o schema
combinationala. Registrele
, constand, uzual, dintr-o schema
combinationala. Registrele ![]() retin rezultatele
procesate partial pe masura ce acestea avanseaza prin
pipeline, dar folosesc si ca tampoane intre stagii vecine pentru a preveni
interferenta acestora. Schimbarile de stare la registrele
retin rezultatele
procesate partial pe masura ce acestea avanseaza prin
pipeline, dar folosesc si ca tampoane intre stagii vecine pentru a preveni
interferenta acestora. Schimbarile de stare la registrele![]() au loc, in mod sincron, sub controlul unui semnal de clock
comun. Fiecare registru
au loc, in mod sincron, sub controlul unui semnal de clock
comun. Fiecare registru ![]() obtine un set de
date de intrare provenite de la anteriorul stage
obtine un set de
date de intrare provenite de la anteriorul stage ![]() (exceptandu-l pe
(exceptandu-l pe ![]() la care se aplica
date de la sursa externa) si reprezentand rezultate ale unor calcule
efectuate, prin
la care se aplica
date de la sursa externa) si reprezentand rezultate ale unor calcule
efectuate, prin![]() , in anteriorul ciclu de clock, asupra carora
opereaza prin
, in anteriorul ciclu de clock, asupra carora
opereaza prin ![]() , in ciclul de clock current, inaintand rezultatele acestei
noi prelucrari urmatorului stagiu
, in ciclul de clock current, inaintand rezultatele acestei
noi prelucrari urmatorului stagiu ![]() . In acest mod, in fiecare ciclu de clock, fiecare stage
transfera rezultatele anterioare la urmatorul stage si
calculeaza un nou set de rezultate. Cu alte cuvinte, in fiecare stage se
realizeaza cate o parte din calcule, dar rezultatul final este
obtinut dupa ce un set de operanzi traverseaza toate stage-urile
pipeline-ului. Cresterea capacitatii de trecere se obtine atunci
cand se efectueaza mai multe operatii inlantuite intrucat
un stagiu care in ciclul de clock curent, executa o prelucrare
specifica asupra unui set de operanzi, devine disponibil pentru a executa o
prelucrare asupra setului urmator de operanzi. In acest mod de
executie suprapusa decalata pot fi in executie, la un
moment dat, in cazul ideal al lipsei unor conflicte de resurse sau date,
pana la m operatii, m fiind considerata adancimea pipeline-ului
(pipeline depth).
. In acest mod, in fiecare ciclu de clock, fiecare stage
transfera rezultatele anterioare la urmatorul stage si
calculeaza un nou set de rezultate. Cu alte cuvinte, in fiecare stage se
realizeaza cate o parte din calcule, dar rezultatul final este
obtinut dupa ce un set de operanzi traverseaza toate stage-urile
pipeline-ului. Cresterea capacitatii de trecere se obtine atunci
cand se efectueaza mai multe operatii inlantuite intrucat
un stagiu care in ciclul de clock curent, executa o prelucrare
specifica asupra unui set de operanzi, devine disponibil pentru a executa o
prelucrare asupra setului urmator de operanzi. In acest mod de
executie suprapusa decalata pot fi in executie, la un
moment dat, in cazul ideal al lipsei unor conflicte de resurse sau date,
pana la m operatii, m fiind considerata adancimea pipeline-ului
(pipeline depth).
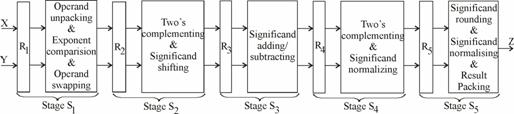
Orice operatie care poate fi descompusa intr-o secventa de suboperatii de aproximativ aceeasi complexitate poate fi implementata, asa cum am vazut in cazul operatiei de inmultire prin structuri matriciale combinationale (fig. 3.51), printr-o structura pipeline de tipul celei din fig. 5.16. referindu-ne la procedura de
|
|
|
Fig. 5.17 |
|
|
|
Fig. 5.18 |
adunare din paragraful anterior, o divizare
ipotetica de suboperatii pe potentiale stage ar fi cea din fig.
5.17. Astfel, la dimensionare, s-a luat in consideratie situatia cea
mai defavorabila in sensul ca, spre exemplu, la stage ![]() au fost atribuite
suboperatiile obligatorii de despachetare a operanzilor (operand
unpacking) si de comparare a exponentilor (exponent comparison), dar
si, doar in unele cazuri, necesara interschimbare a operanzilor (operand
swapping). La stage
au fost atribuite
suboperatiile obligatorii de despachetare a operanzilor (operand
unpacking) si de comparare a exponentilor (exponent comparison), dar
si, doar in unele cazuri, necesara interschimbare a operanzilor (operand
swapping). La stage ![]() , complementarea de doi (two's complementing) a unuia dintre
operanzi se realizeaza doar cand semnele operanzilor difera, dar deplasarea
unui significand (significand shifting) fiind necesara in toate cazurile,
exceptand-ul pe cel cand
, complementarea de doi (two's complementing) a unuia dintre
operanzi se realizeaza doar cand semnele operanzilor difera, dar deplasarea
unui significand (significand shifting) fiind necesara in toate cazurile,
exceptand-ul pe cel cand ![]() . In stage-ul
. In stage-ul ![]() se executa operatia
propriu-zisa de adunare/scadere a numerelor significand, pe cand in
stage-ul
se executa operatia
propriu-zisa de adunare/scadere a numerelor significand, pe cand in
stage-ul ![]() , complementarea de doi a significand-ului rezultat are loc
doar atunci cand semnele operanzilor sunt diferite si cand, asa cum
am vazut,
, complementarea de doi a significand-ului rezultat are loc
doar atunci cand semnele operanzilor sunt diferite si cand, asa cum
am vazut, ![]() . La suboperatia de normalizare a significand-ului
rezultat (significand normalizing), prevazuta tot in stage
. La suboperatia de normalizare a significand-ului
rezultat (significand normalizing), prevazuta tot in stage ![]() , se apeleaza frecvent. Ultimului stage,
, se apeleaza frecvent. Ultimului stage, ![]() , i-au fost atribuite potentialele suboperatii de
rotunjire a significand-ului rezultat (significand rounding) si de
eventuala noua normalizare a acestuia, precum si
suboperatia obligatorie de impachetare a rezultatului (result packing).
, i-au fost atribuite potentialele suboperatii de
rotunjire a significand-ului rezultat (significand rounding) si de
eventuala noua normalizare a acestuia, precum si
suboperatia obligatorie de impachetare a rezultatului (result packing).
Din analiza atribuirii suboperatiilor la cele 5 stage-uri se poate constata ca a primat rezultarea unei durate cat mai echilibrate a stage-urilor prevazute cu numarul defavorabil (cel mai mare) de suboperatii. In acest context, se impune remarcat faptul ca, dependent de tehnologia de care dispune proiectantul, suboperatiile din figura 5.17 pot fi grupate in mod diferit, asa cum se prezinta, spre exemplu, in [HePa03] variantele de implementare a unitatilor de adunare/scadere din unele chip-uri comerciale.
In situatia ca exista o asa numita pipeline-izare completa a subunitatilor functionale (sumatoare/scazatoare, dispozitive de deplasare, s.a.), adica structura unitatii de adunare/scadere include un numar suficient de resurse astfel incat sa poata fi executate simultan cate operatii de un anumit tip sunt necesare, atunci operatii inlantuite pot fi executate in maniera cu suprapunere decalata ideala ca in fig. 5.18. Daca insa, o anume subunitate functionala, spre exemplu, un adder, nu exista suficiente copii ale acestuia, atunci activitatea la nivelul respectivei subunitati trebuie serializata (se spune ca avem de-a face cu un hazard la nivel de structura) si situatia ideala prin prisma cresterii capacitatii de trecere se degradeaza in mod corespunzator.
B Pe langa solutiile bazate pe principiul pipeline-izarii aritmetice, accelerarea procesului de adunare/scadere poate fi intreprinsa uzitand de conceptul de paralelism, in particular, referindu-ne la executia simultana, in paralel, a doua procese de adunare/scadere [SeEv04] [SeEv01]. Fara a pierde din generalitate, vizam in mod concret adunarea, adaptarea problematicii la scadere fiind imediata. De asemenea, in scop de concretete, admitem ca, in ceea ce priveste rotunjirea, modul acceptat este cel "toward to nearest even" (fig. 5.9). In ceea ce priveste analiza accelerarii bazata pe paralelism, dependent de semnele operanzilor si de valoarea diferentei exponentilor, se impun luate in consideratie urmatoarele trei cazuri:
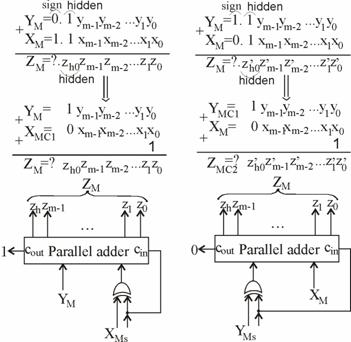
B1 Cazul cand semnele celor doi operanzi, X si Y, sunt identice (sign(X)=sign(Y)).
Parcurgerea algoritmului
descris anterior arata ca, in acest caz, complementarile de doi
din pasii 3 si 5 sunt evitate (vezi exemplul 2, fig. 5.15), deci nu
este activat sumatorul care ar fi implicat in aceasta operatie,
activare care este insa obligatorie pentru adunarea preliminara din
pasul 5 si este potentiala in pasul 8, de rotunjire. Problema
apare la adunarea din pasul 5 intrucat la aceasta operatie se poate
genera carry-out (![]() ), respectiv acest lucru poate sa nu se intample. Ca
atare, pozitia msb-ului sumei nu este cunoscuta apriori. Pentru o
introspectie mai amanuntita a situatiei, sa
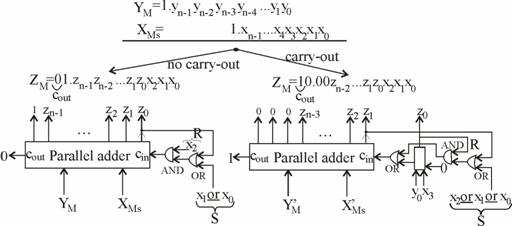
consideram cazul, edificator in opinia noastra, din fig. 5.19, unde
am folosit doua sumatoare paralele (parallel adder), la cel din stanga admitand
ca nu se genereaza carry-out (
), respectiv acest lucru poate sa nu se intample. Ca
atare, pozitia msb-ului sumei nu este cunoscuta apriori. Pentru o
introspectie mai amanuntita a situatiei, sa
consideram cazul, edificator in opinia noastra, din fig. 5.19, unde
am folosit doua sumatoare paralele (parallel adder), la cel din stanga admitand
ca nu se genereaza carry-out (![]() ), iar la cel din dreapta admitand ca se genereaza
carry-out (
), iar la cel din dreapta admitand ca se genereaza
carry-out (![]() ). Dar, pentru cele doua situatii, bitii de
rotunjire R si S pot fi generati in mod anticipativ, fara a
astepta terminarea adunarii, asa cum este ilustrat si in
figura 5.19.
). Dar, pentru cele doua situatii, bitii de
rotunjire R si S pot fi generati in mod anticipativ, fara a
astepta terminarea adunarii, asa cum este ilustrat si in
figura 5.19.
|
|
|
Fig. 5.19 |
In acest sens, la
ambele alternative, se face uz de intrarea de carry-in (![]() ) corespunzatoare celor doua sumatoare, dar in mod
diferit. La adunarea significand-ului nedeplasat
) corespunzatoare celor doua sumatoare, dar in mod
diferit. La adunarea significand-ului nedeplasat ![]() cu cel shift-at
cu cel shift-at ![]() , in cazul in care avem no carry-out (
, in cazul in care avem no carry-out (![]() ), functia generala de rotunjire R (
), functia generala de rotunjire R (![]() ) (fig. 5.9) se particularizeaza prin
) (fig. 5.9) se particularizeaza prin ![]() si
si ![]() , in asa fel incat pentru significand-ul suma, pe care
il notam, corespunzator acestei situatii, cu
, in asa fel incat pentru significand-ul suma, pe care
il notam, corespunzator acestei situatii, cu ![]() obtinem:
obtinem:
![]() (5.2)
(5.2)
unde prin inmultirea
cu ![]() s-a sugerat ca bitul general de rotunjire este
adunat la lsb-ul sumei, mantisa significand-ului fiind subunitara.
s-a sugerat ca bitul general de rotunjire este
adunat la lsb-ul sumei, mantisa significand-ului fiind subunitara.
In
celalalt caz, cand se genereaza carry-out (![]() ), lucrurile se prezinta nitel mai complicat
avand in vedere ca la functia de rotunjire participa acum doi
biti ai sumei (
), lucrurile se prezinta nitel mai complicat
avand in vedere ca la functia de rotunjire participa acum doi
biti ai sumei (![]() si
si ![]() ) si aceasta se impune aplicata cu un rang
decalat la stanga (datorita
) si aceasta se impune aplicata cu un rang
decalat la stanga (datorita ![]() ) fata de situatia anterioara.
Avand in vedere aceste aspecte, in fig. 5.19, sumatorul paralel a fost
sectionat in doua parti, una constituita de rangul lsb
(intrari, in cazul adoptat,
) fata de situatia anterioara.
Avand in vedere aceste aspecte, in fig. 5.19, sumatorul paralel a fost
sectionat in doua parti, una constituita de rangul lsb
(intrari, in cazul adoptat, ![]() si
si ![]() , iesire
, iesire ![]() ) si celelalte ranguri la care se aplica
segmentele
) si celelalte ranguri la care se aplica
segmentele ![]() si
si ![]() reprezentand
numerele significand
reprezentand
numerele significand![]() si
si ![]() mai putin
rangurile lor lsb. Luand in consideratie noile particularitati
mai putin
rangurile lor lsb. Luand in consideratie noile particularitati ![]() si
si ![]() si rangul
la care se aplica bitul general de rotunjire, precum si notand cu
si rangul
la care se aplica bitul general de rotunjire, precum si notand cu ![]() significand-ul
suma din cazul cand
significand-ul
suma din cazul cand ![]() , obtinem:
, obtinem:
![]() (5.3)
(5.3)
Avand in
vedere ca avem ![]() (la
sectiunea cu intrarile
(la
sectiunea cu intrarile ![]() si
si ![]() ) doar atunci cand
) doar atunci cand ![]() , se poate constata in mod facil ca bitul general
de rotunjire poate fi aplicat rangului lsb, eliminand poarta OR dintre
sectiuni (fig. 5.19) din calea critica, adica:
, se poate constata in mod facil ca bitul general
de rotunjire poate fi aplicat rangului lsb, eliminand poarta OR dintre
sectiuni (fig. 5.19) din calea critica, adica:
![]() (5.4)
(5.4)
Cu aceste
precizari, mentionam ca sumatoarele functioneaza
simultan obtinand, in general, doua rezultate dintre care unul este,
in mod cert, corect. Acesta din urma se alege in functie de valoarea
obtinuta pentru ![]() si anume,
daca aceasta este 0, se alege rezultatul furnizat de sumatorul din stanga
(fig. 5.19), iar daca valoarea lui
si anume,
daca aceasta este 0, se alege rezultatul furnizat de sumatorul din stanga
(fig. 5.19), iar daca valoarea lui ![]() este 1, rezultatul ales
va fi cel furnizat de sumatorul din dreapta (fig. 5.19). Remarcam ca
exista si o situatie limita, cand in urma adunarii
prin sumatorul din stanga se obtine un significand rezultat format doar
din biti de 1, iar prin sumatorul din dreapta doar biti de 0, cand aparent
ambele rezultate ar fi corecte. In acest caz, significand-ul rezultat al
sumatorului din dreapta depaseste plaja valoric tolerata (
este 1, rezultatul ales
va fi cel furnizat de sumatorul din dreapta (fig. 5.19). Remarcam ca
exista si o situatie limita, cand in urma adunarii
prin sumatorul din stanga se obtine un significand rezultat format doar
din biti de 1, iar prin sumatorul din dreapta doar biti de 0, cand aparent
ambele rezultate ar fi corecte. In acest caz, significand-ul rezultat al
sumatorului din dreapta depaseste plaja valoric tolerata (![]() ), deci rezultatul corect este cel furnizat de sumatorul din
stanga.
), deci rezultatul corect este cel furnizat de sumatorul din
stanga.
Relativ la cazul sign(X)=sign(Y), se poate conchide ca apeland la executia simultana, in paralel, a celor doua adunari, in termeni de durata a calculelor intervalul pesimistic revendicat de cele trei activari de sumator, rezultate intr-o prima analiza, se poate reduce la cel corespunzator unei singure activari, constand intr-o accelerare consistenta.
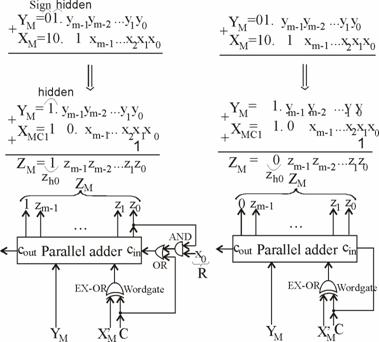
B2 Cazul cand semnele celor doi operanzi, X
si Y, difera (![]() dar au acelasi exponent (
dar au acelasi exponent (![]()
Parcurgerea
algoritmului descris anterior arata ca, in acest caz, devine
obligatorie complementarea de doi din pasul 3, ca de altfel, si adunarea
preliminara din pasul 5, care ar putea fi succedata, in
conditiile cand msb-ul sumei rezulta 1 si nu exista carry -
out, de o noua complementare de doi, de aceasta data, a
significand-ului rezultat. In mod evident, in acest caz, suma este exacta,
facand inutila rotunjirea din pasul 8. Totusi, in caz
defavorabil, aceasta situatie reclama activarea de trei ori a
sumatorului paralel, admitand ca prin intermediul acestuia se
realizeaza complementarea de doi adunand un 1 aplicat intrarii de
carry - in la valoarea complementului de unu. Si aceasta
situatie pesimista poate fi surmontata uzitand de doua sumatoare
care sa opereze simultan, efectuand operatiile din fig. 5.20.
specificand ca, pentru simplitate, am folosit aceiasi notatie (![]() ) si pentru numerele significand cu semn si ca
am notat cu 1 acea unitate binara care se aduna la cifrele lsb,
fara a mai lua in consideratie ponderea acesteia, se poate
remarca faptul ca in partea stanga se
) si pentru numerele significand cu semn si ca
am notat cu 1 acea unitate binara care se aduna la cifrele lsb,
fara a mai lua in consideratie ponderea acesteia, se poate
remarca faptul ca in partea stanga se
|
|
|
Fig. 5.20 |
efectueaza operatia ![]() , iar in partea dreapta se efectueaza operatia
, iar in partea dreapta se efectueaza operatia
![]() , unde prin
, unde prin ![]() si
si ![]() au fost notate
valorile complement de unu obtinute prin trecerea numerelor significand
au fost notate
valorile complement de unu obtinute prin trecerea numerelor significand ![]() si
si ![]() prin wordgate-urile EXCLUSIVE
- OR, atunci cand este activ (pe 1) semnalul de control c, generat, la
indeplinirea conditiilor (
prin wordgate-urile EXCLUSIVE
- OR, atunci cand este activ (pe 1) semnalul de control c, generat, la
indeplinirea conditiilor (![]() ), de catre unitatea de control. Aplicand
), de catre unitatea de control. Aplicand ![]() si la
intrarile
si la
intrarile ![]() ale celor
doua sumatoare, se obtin complementele de doi, astfel incat se
obtin rezultatele adunarilor
ale celor
doua sumatoare, se obtin complementele de doi, astfel incat se
obtin rezultatele adunarilor ![]() , respectiv
, respectiv ![]() , care conduc la sumele
, care conduc la sumele ![]() , respectiv
, respectiv ![]() , ultima reprezentand complementul de doi a celei
dintai. In
acest mod, au fost comprimate intr-o
singura operatie complementarea de doi din pasul 3 si adunarea
din pasul 5, urmand a mai stabili semnul rezultatului. Sub acest aspect, este
de remarcat ca un rezultat suma,
, ultima reprezentand complementul de doi a celei
dintai. In
acest mod, au fost comprimate intr-o
singura operatie complementarea de doi din pasul 3 si adunarea
din pasul 5, urmand a mai stabili semnul rezultatului. Sub acest aspect, este
de remarcat ca un rezultat suma, ![]() , este pozitiv, cel pentru care
, este pozitiv, cel pentru care ![]() , iar celalalt,
, iar celalalt, ![]() , este negativ, cel pentru care
, este negativ, cel pentru care ![]() . Pentru a obtine forma dorita semn - marime a
significand-ului rezultat,
. Pentru a obtine forma dorita semn - marime a
significand-ului rezultat, ![]() ar trebui supus unei
suplimentare complementari de doi. In consecinta, se
opteaza pentru valoarea
ar trebui supus unei
suplimentare complementari de doi. In consecinta, se
opteaza pentru valoarea ![]() a carei alegere
se realizeaza pe seama faptului ca ea corespunde acelui sumator la
care s-a sesizat
a carei alegere
se realizeaza pe seama faptului ca ea corespunde acelui sumator la
care s-a sesizat ![]() .
.
Concluzia care se desprinde pentru acest caz este una similara cu cea de la B1 in sensul ca, apeland la doua sumatoare (in loc de unul) cu functionare simultana, procesul de adunare poate fi accelerat fiind necesara doar durata corespunzatoare unei singure activari a sumatorului in loc de cea corespunzatoare la, defavorabil, trei.
B3 Cazul cand semnele celor doi operanzi, X si Y,
difera (![]() si difera si valorile exponentilor (
si difera si valorile exponentilor (![]() ).
).
Preconizam
defalcarea analizei corespunzatoare acestui caz in functie de valoarea
absoluta a diferentei dintre valorile exponentilor, anume ![]()
B3a Subcazul ![]() si
si ![]()
Corespunzator
acestui subcaz, remarcam mai intai obligativitatea complementarii de
doi din pasul 3, precum si a adunarii preliminare din pasul 5. Problema
se pune in legatura cu rotunjirea din pasul 8, care devine nenecesara
daca suma prezinta doi sau mai multi biti leading de 0
(vezi si cazul exemplu f, fig. 5.12) intrucat, prin deplasare la stanga,
bitii implicati in rotunjire devin 0, deci adunarea se executa
exact. Exista
insa o situatie cand s-ar putea sa fie necesara rotunjirea
in sus, anume atunci cand bit-ul leading 1 al rezultatului coincide ca pozitie
cu respectivul bit al significand-ului operand nedeplasat, deci rezultatul e
normalizat si nu mai trebuie shift-at. Cu toate ca bitul sticky S
este 0, intrucat R si ![]() (bitul lsb al rezultatului) pot fi 1, conform cu fig. 5.9,
este posibil sa rezulte rotunjire in sus in pasul 8. In vederea
accelerarii, sa cumulam, mai intai, operatiile din
pasii 3 si 5, efectuand, la activarea semnalului de control c (cu o
semnificatie asemanatoare celei de la cazul B2), diferenta
dintre numerele significand
(bitul lsb al rezultatului) pot fi 1, conform cu fig. 5.9,
este posibil sa rezulte rotunjire in sus in pasul 8. In vederea
accelerarii, sa cumulam, mai intai, operatiile din
pasii 3 si 5, efectuand, la activarea semnalului de control c (cu o
semnificatie asemanatoare celei de la cazul B2), diferenta
dintre numerele significand ![]() si
si ![]() (reprezentand significand-ul
(reprezentand significand-ul ![]() mai putin bitul
sau lsb,
mai putin bitul
sau lsb, ![]() ), asa cum se prezinta in fig. 5.20. A fost
exemplificat, fara a pierde din generalitate, cazul in care sign(X)=1
si sign(Y)=0. Se observa la sumatorul din partea stanga
situatia corespunzatoare careia bitul din pozitia hidden a
significand-ului rezultat
), asa cum se prezinta in fig. 5.20. A fost
exemplificat, fara a pierde din generalitate, cazul in care sign(X)=1
si sign(Y)=0. Se observa la sumatorul din partea stanga
situatia corespunzatoare careia bitul din pozitia hidden a
significand-ului rezultat ![]() admitem ca este 1
ca si omologul sau, al significand-ului operand
admitem ca este 1
ca si omologul sau, al significand-ului operand ![]() , cand, atunci cand
, cand, atunci cand ![]() (alias
(alias ![]() ), rezulta ca necesara rotunjirea in sus. Dar
si aceasta operatie poate fi combinata cu celelalte
doua, toate fiind executate la momentul de timp corespunzator pasului
5, intrucat normalizarea lui
), rezulta ca necesara rotunjirea in sus. Dar
si aceasta operatie poate fi combinata cu celelalte
doua, toate fiind executate la momentul de timp corespunzator pasului
5, intrucat normalizarea lui ![]() (pas 6) nu mai e
necesara (1 in pozitia hidden,
(pas 6) nu mai e
necesara (1 in pozitia hidden, ![]() -vezi si fig. 5.20) si nici ajustarea valorilor lui
R si S (pas 7). Nu trebuie omis ca operatia de complementare din
pasul 3 se realizeaza concomitent cu adunarea preliminara din pasul
5, deci apare o inversare a pasului 4, de aliniere a numerelor significand, cu
pasul 3 in algoritmul descris in paragraful anterior. Din punct de vedere
tehnic, combinarea rotunjirii cu celelalte suboperatii este posibila
prin adaosul portii OR de intrarea
-vezi si fig. 5.20) si nici ajustarea valorilor lui
R si S (pas 7). Nu trebuie omis ca operatia de complementare din
pasul 3 se realizeaza concomitent cu adunarea preliminara din pasul
5, deci apare o inversare a pasului 4, de aliniere a numerelor significand, cu
pasul 3 in algoritmul descris in paragraful anterior. Din punct de vedere
tehnic, combinarea rotunjirii cu celelalte suboperatii este posibila
prin adaosul portii OR de intrarea ![]() a sumatorului,
respectiv a portii AND avand ca intrari pe
a sumatorului,
respectiv a portii AND avand ca intrari pe ![]() si
si ![]() . Pe de alta parte, daca bitul
. Pe de alta parte, daca bitul ![]() a
significand-ului suma
a
significand-ului suma ![]() rezulta 0,
atunci pasul 6, de normalizare, nu poate fi omis, dar, prin aceasta, R devine
0, deci rotunjirea nu trebuie realizata rezultatul fiind exact. Cu alte
cuvinte, sumatorul din dreapta nu efectueaza rotunjirea, iar
rezulta 0,
atunci pasul 6, de normalizare, nu poate fi omis, dar, prin aceasta, R devine
0, deci rotunjirea nu trebuie realizata rezultatul fiind exact. Cu alte
cuvinte, sumatorul din dreapta nu efectueaza rotunjirea, iar ![]() urmeaza
ca, dupa evaluarea significand-ului
urmeaza
ca, dupa evaluarea significand-ului ![]() , sa devina, prin normalizare, un bit al
acestuia. Prin urmare, alegerea dintre cele doua rezultate
, sa devina, prin normalizare, un bit al
acestuia. Prin urmare, alegerea dintre cele doua rezultate ![]() , obtinute simultan, se face in functie de
valoarea bitului lor hidden,
, obtinute simultan, se face in functie de
valoarea bitului lor hidden, ![]() (cand este 1,
(cand este 1, ![]() este
obtinut rotunjit, iar cand este 0,
este
obtinut rotunjit, iar cand este 0, ![]() nu trebuie
rotunjit, dar trebuie normalizat). In acest mod, din nou, cele altfel trei
activari de sumator se reduc, in termeni de timp, la doar una, corespunzatoare
solutiei paralele descrise.
nu trebuie
rotunjit, dar trebuie normalizat). In acest mod, din nou, cele altfel trei
activari de sumator se reduc, in termeni de timp, la doar una, corespunzatoare
solutiei paralele descrise.
|
|
|
Fig. 5.21 |
B3b Subcazul ![]() si
si ![]() .
.
Corespunzator
acestui subcaz, din nou, complementarea de doi din pasul 3 si adunarea
preliminara din pasul 5 sunt obligatorii, fiind posibila, dependent
de indeplinirea conditiilor din fig. 5.9, si rotunjirea din pasul 8
(vezi si cazurile exemplu a la e, fig. 5.12). Pe baza analizelor
anterioare, corespunzator acestei situatii pozitia bitului
leading 1 a diferentei poate fi doar una din doua, anume pozitia
bitului hidden sau cea imediat adiacenta pozitional la dreapta. In
vederea accelerarii executiei operatiei, preconizam si
in acest caz combinarea complementarii de doi din pasul 3 cu adunarea
preliminara din pasul 5 printr-o solutie asemanatoare cu
cea de la subcazul B3a, devansandu-le pe acestea doua prin pasul 4, de
aliniere a numerelor significand. Sa analizam efectele
interschimbarii pasilor 3 si 4 in ceea ce priveste valorile
bitilor de rotunjire g, r si s. Astfel, se poate observa in mod facil
ca la nivelul lui s nu apar modificari avand aceeasi valoare la
forma semn - marime ca si in cea complementata de doi. Lucrurile
se prezinta diferit referitor la g si r. Pentru a obtine
valorile corecte corespunzatoare acestora se impune o investitie
suplimentara constand din extensia sumatorului utilizat la calculul lui ![]() cu doua ranguri
la dreapta. Pentru a urmari modul de fructificare a acestei extensii, vom
face mai intai unele observatii referitoare la efectuarea diferentei
exemplu din fig. 5.22. Este de remarcat ca, atunci cand toate cifrele
binare ale operandului
cu doua ranguri
la dreapta. Pentru a urmari modul de fructificare a acestei extensii, vom
face mai intai unele observatii referitoare la efectuarea diferentei
exemplu din fig. 5.22. Este de remarcat ca, atunci cand toate cifrele
binare ale operandului ![]() situate la dreapta
celor (
situate la dreapta
celor (![]() ) cifre binare a
) cifre binare a
|
|
|
Fig. 5.22 |
operand-ului ![]() sunt 0 (in fig. 5.22,
sunt 0 (in fig. 5.22, ![]() ), atunci bitul de 1 adunat la bitul
), atunci bitul de 1 adunat la bitul ![]() al complementului de
unu,
al complementului de
unu, ![]() , a lui
, a lui ![]() se propaga in calitate
de carry fiind adunat, in ultima instanta, la perechea lsb din
cele (
se propaga in calitate
de carry fiind adunat, in ultima instanta, la perechea lsb din
cele (![]() ) ale operanzilor
) ale operanzilor ![]() si
si ![]() , astfel ca suma
, astfel ca suma ![]() , pe (
, pe (![]() ) biti, rezulta in a consta din
) biti, rezulta in a consta din ![]() . Pe de alta parte, daca doar unul sau mai
multi dintre bitii operandului
. Pe de alta parte, daca doar unul sau mai
multi dintre bitii operandului ![]() situati la
dreapta celor (
situati la
dreapta celor (![]() ) ai operandului
) ai operandului ![]() (in fig. 5.22,
(in fig. 5.22, ![]() si
si ![]() ), atunci propagarea transportului provocat de adunarea la
bitul
), atunci propagarea transportului provocat de adunarea la
bitul ![]() al complementului de
unu
al complementului de
unu ![]() , a lui
, a lui ![]() va fi blocata,
astfel incat la perechea lsb din cele (
va fi blocata,
astfel incat la perechea lsb din cele (![]() ) ale operanzilor
) ale operanzilor ![]() si
si ![]() ajunge sa se
adune 0, modalitate in care suma
ajunge sa se
adune 0, modalitate in care suma ![]() , pe (
, pe (![]() ) biti, rezulta a consta din
) biti, rezulta a consta din ![]() .
.
Cu aceasta
observatie, revenind la sumatorul extins cu doua ranguri la dreapta
celor (![]() ) biti in vederea obtinerii valorilor corecte
pentru bitii de rotunjire g si r, prezentam situatiile
alternative din fig. 5.23. Am considerat ca din significand-ul
) biti in vederea obtinerii valorilor corecte
pentru bitii de rotunjire g si r, prezentam situatiile
alternative din fig. 5.23. Am considerat ca din significand-ul ![]() se scade
se scade ![]() deplasat in vederea
alinierii, la care am considerat, fara a pierde din generalitate,
cazul particular
deplasat in vederea
alinierii, la care am considerat, fara a pierde din generalitate,
cazul particular ![]() ,
, ![]() si
si ![]() . Operandul
. Operandul ![]() este extins cu doua 0-uri nesemnificative, la dreapta bitului
sau lsb (
este extins cu doua 0-uri nesemnificative, la dreapta bitului
sau lsb (![]() ), devenind
), devenind ![]() , iar complementul de unu al operandului
, iar complementul de unu al operandului ![]() are, in pozitiile
corespondente celor doua 0-uri a
lui
are, in pozitiile
corespondente celor doua 0-uri a
lui ![]() , bitii
, bitii ![]() si
si ![]() , devenind
, devenind ![]() . Cele doua cazuri alternative apar in functie de
bitul sticky preliminar, s, a carui valoare a fost stabilita, in mod
corect in pasul 4. Astfel, cand
. Cele doua cazuri alternative apar in functie de
bitul sticky preliminar, s, a carui valoare a fost stabilita, in mod
corect in pasul 4. Astfel, cand ![]() , se observa ca adunarea unui 1 la
, se observa ca adunarea unui 1 la ![]() face sa se propage
un
face sa se propage
un
|
|
|
Fig. 5.23 |
carry (1 marcat cu sageata) inspre
rangul lsb al sumatorului, astfel ca, in conformitate cu adunarea din
partea stanga a fig. 5.22, obtinem significand-ul suma ![]() extins si el cu
corespondentele doua ranguri la dreapta, in forma
extins si el cu
corespondentele doua ranguri la dreapta, in forma ![]() . In mod similar, cand
. In mod similar, cand ![]() , prin adunarea unui 1 la
, prin adunarea unui 1 la ![]() nu se genereaza
carry (0 marcat cu sageata) inspre rangul lsb al sumatorului, astfel
ca, in conformitate cu adunarea din partea dreapta a fig. 5.22,
obtinem pe
nu se genereaza
carry (0 marcat cu sageata) inspre rangul lsb al sumatorului, astfel
ca, in conformitate cu adunarea din partea dreapta a fig. 5.22,
obtinem pe ![]() , de aceasta data in forma
, de aceasta data in forma ![]() . Mentionam ca esential este faptul
ca, in ambele situatii, bitii din pozitiile extinse ale lui
. Mentionam ca esential este faptul
ca, in ambele situatii, bitii din pozitiile extinse ale lui
![]() au valori corecte,
astfel incat poate fi intreprinsa, prin intermediul lor, rotunjirea in
conformitate cu cerintele algoritmului.
au valori corecte,
astfel incat poate fi intreprinsa, prin intermediul lor, rotunjirea in
conformitate cu cerintele algoritmului.
Cu aceste
precizari, in vederea accelerarii procesului de adunare, sa
incercam combinarea celor trei suboperatii amintite intr-una
singura, luand in consideratie cele doua situatii conform
carora bitul ![]() (hidden) a lui
(hidden) a lui ![]() ia valoarea 0,
respectiv 1. Obtinem deci alternativele prezentate in fig. 5.24, in care
ambele sumatoare paralele au fost extinse la dreapta cu doua full adder
cell (FAC) interconectate in maniera ripple carry adder (RCA).
Situatia din partea stanga a fig. 5.24 corespunde situatiei cand
ia valoarea 0,
respectiv 1. Obtinem deci alternativele prezentate in fig. 5.24, in care
ambele sumatoare paralele au fost extinse la dreapta cu doua full adder
cell (FAC) interconectate in maniera ripple carry adder (RCA).
Situatia din partea stanga a fig. 5.24 corespunde situatiei cand
![]() , cand significand-ul suma final
, cand significand-ul suma final ![]() ar mai trebui normalizat
prin deplasare la stanga cu o pozitie binara. Aceasta
ultima suboperatie nu trebuie facuta daca luam
bitii lui
ar mai trebui normalizat
prin deplasare la stanga cu o pozitie binara. Aceasta
ultima suboperatie nu trebuie facuta daca luam
bitii lui ![]() decalati,
adica la pozitia hidden se aloca
decalati,
adica la pozitia hidden se aloca ![]() iar lsb-ul lui
iar lsb-ul lui ![]() devine
devine ![]() . In mod corespunzator trebuie aplicata iesirea
functiei logice de rotunjire (vezi fig. 5.9) si anume prin
intermediul portii OR conectata pe intrarea
. In mod corespunzator trebuie aplicata iesirea
functiei logice de rotunjire (vezi fig. 5.9) si anume prin
intermediul portii OR conectata pe intrarea ![]() a FAC-ului avand
iesirea
a FAC-ului avand
iesirea ![]() . De asemenea, la aceasta alternativa, conform cu
cele din fig. 5.8,
. De asemenea, la aceasta alternativa, conform cu
cele din fig. 5.8, ![]() si
si ![]() , unde s preliminar se presupune ca a fost determinat in
pasul 4, de aliniere, care precede pasul combinat prezentat in fig. 5.24. In
rest, se remarca portile EX - OR care, conform si cu cele din
fig. 5.23, permit obtinerea lui
, unde s preliminar se presupune ca a fost determinat in
pasul 4, de aliniere, care precede pasul combinat prezentat in fig. 5.24. In
rest, se remarca portile EX - OR care, conform si cu cele din
fig. 5.23, permit obtinerea lui ![]() (prin
(prin ![]() au fost notati
doar acei biti ai lui
au fost notati
doar acei biti ai lui ![]() care sunt aliniati
cu bitii lui
care sunt aliniati
cu bitii lui ![]() ) si care sunt toate comandate de semnalul c, cu o
semnificatie asemanatoare cu cea de la fig. 5.20, respectiv fig.
5.21, provenit de la unitatea de
) si care sunt toate comandate de semnalul c, cu o
semnificatie asemanatoare cu cea de la fig. 5.20, respectiv fig.
5.21, provenit de la unitatea de
|
|
|
Fig. 5.24 |
control si care este, de asemenea, aplicat
intrarii ![]() a adder-ului extins,
permitand obtinerea complementului de doi.
a adder-ului extins,
permitand obtinerea complementului de doi.
Pe de
alta parte, situatia din partea dreapta a fig. 5.24
prezinta unele elemente distinctive cauzate de faptul ca la
aceasta alternativa avem bitul ![]() , ceea ce exclude operatia de normalizare.
Desigur, aceasta reclama ca significand-ul suma finala
, ceea ce exclude operatia de normalizare.
Desigur, aceasta reclama ca significand-ul suma finala ![]() sa
aiba
sa
aiba ![]() ca msb si z0
ca lsb, dar mai implica si mutarea portii OR astfel incat
functia logica de rotunjire (vezi fig. 5.9) sa fie aplicata,
prin intermediul acestei porti, pe intrarea
ca msb si z0
ca lsb, dar mai implica si mutarea portii OR astfel incat
functia logica de rotunjire (vezi fig. 5.9) sa fie aplicata,
prin intermediul acestei porti, pe intrarea ![]() a FAC-ului
avand iesirea
a FAC-ului
avand iesirea ![]() . De asemenea, la aceasta alternativa,
conform cu cele din fig. 5.8,
. De asemenea, la aceasta alternativa,
conform cu cele din fig. 5.8, ![]() si
si ![]() , unde, din nou s se presupune ca a fost
determinat in pasul de aliniere.
, unde, din nou s se presupune ca a fost
determinat in pasul de aliniere.
In consecinta, si la acest subcaz, cele trei activari inlantuite ale unui sumator se reduce, in termeni de timp, la doar una in care functioneaza in paralel doua sumatoare, ca si in toate celelalte situatii analizate. Intr-o versiune de proiectare economica, se poate aplica reconfigurarea schemelor sumatoarelor in functie de semnele operanzilor, respectiv diferenta valorilor exponentilor, rezultand o solutie tehnica care sa se constituie intr-un concurent acerb pentru varianta bazata pe conceptual pipeline [BrLa01].
|
Politica de confidentialitate |
| Copyright ©
2024 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |