Asupra altor metode de inmultire binara
In acest paragraf final al capitolului destinat inmultirii binare, ne propunem sa prezentam si alte tendinte in constructia de multiplier-e, compensand prezentarea rezumata prin indicarea unui numar sporit de repere bibliografice.
1. O idee distincta consta in constructia de inmultitoare asa numit bit-serial (bit-serial multiplier) uzitand de matrici sistolice (systolic arrays) [Parh00], [Haye88], [ObVo92], [RaPe96].
In general, aritmetica bit seriala, asa cum s-a vazut si in cazul sumatoarelor seriale, este atractiva atunci cand exista constrangeri la nivelul numarului de pini (pin count), a lungimii conexiunilor sau a ariei disponibile implementarii in tehnologie VLSI. In anumite aplicatii, intrarile sunt furnizate, oricum, in maniera seriala, cazuri in care utilizarea unor inmultitoare paralele ar duce la risipa intrucat paralelismul ar putea sa nu aduca niciun beneficiu de viteza. In plus, exista aplicatii care reclama un numar mare de inmultiri independente, cand bit-serial multiplier-ele s-ar putea sa fie mai eficiente prin prisma costului decat unitatile complexe cu un grad avansat de pipeline-izare.
In ceea ce priveste systolic arrays, acestea sunt obtinute prin interconectarea, intr-o maniera uniforma, a unui set de celule de procesare a datelor. Cuvintele de date sunt transmise, in mod sincron, de la celula la celula, fiecare dintre acestea executand un pas corespunzator intregii operari a matricii. Datele nu sunt complet procesate pana cand rezultatele finale nu sunt disponibile in celule de interfata cu exteriorul matricii. Interconexiunile dintre celulele de procesare sunt scurte permitand frecventa ridicata pentru trenul impulsurilor de clock [Korn94]. O matrice sistolica unidimensionala ar putea fi asimilata cu un gen de structura pipeline. Numele de sistolic provine de la natura ritmica a fluxului de date care poate fi comparata cu contractia ritmica a inimii (the systole) atunci cand pompeaza sangele prin corp.
Dar, inainte de a discuta o structura sistolica
veritabila, sa consideram un multiplier semisistolic, denumit
astfel intrucat el implica difuzarea fiecarui bit xi al
inmultitorului la un numar de celule de procesare, violand
constrangerea de fire scurte, locale ("short, local wires") a unui proiect
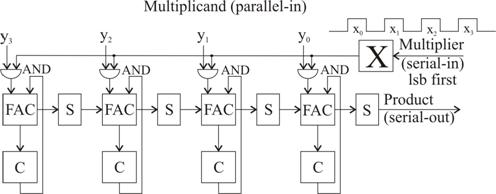
sistolic pur [Kung82]. Astfel, in fig. 3.61 se prezinta, schematic,
structura unui dispozitiv care permite inmultirea unor operanzi de 4
biti, considerati, pentru simplitate, fara semn.
Multiplicand-ul Y este furnizat in paralel, iar multiplier-ul X se aplica
in maniera seriala, bit cu bit, la cate un impuls de clock, cu bitul
cel mai semnificativ (lsb) sosind primul. Dupa cum poate fi observat in
mod facil, fiecare bit xi formeaza produse ![]() , care sunt adunate la produsul partial cumulativ stocat
in forma CSA la latch-urile de suma (sum), respectiv transport (carry). In timp
ce bitii sum sunt "impinsi", in cadenta clock-ului, inspre
dreapta, bitii carry raman atasati la pozitia
curenta unde au fost generati. In mod normal, asa cum am
intalnit pana acum, bitii sum raman ficsi ca pozitie,
iar bitii de carry sunt deplasati inspre stanga, dar rezultatul nu
este afectat daca se procedeaza ca in fig. 3.61, deplasand la
dreapta bitii sum si mentinand ficsi biti carry.
, care sunt adunate la produsul partial cumulativ stocat
in forma CSA la latch-urile de suma (sum), respectiv transport (carry). In timp
ce bitii sum sunt "impinsi", in cadenta clock-ului, inspre
dreapta, bitii carry raman atasati la pozitia
curenta unde au fost generati. In mod normal, asa cum am
intalnit pana acum, bitii sum raman ficsi ca pozitie,
iar bitii de carry sunt deplasati inspre stanga, dar rezultatul nu
este afectat daca se procedeaza ca in fig. 3.61, deplasand la
dreapta bitii sum si mentinand ficsi biti carry.
|
|
|
Fig.3.61 |
In acest mod, bitii rezultatului devin disponibili la iesirea latch-ului S cel mai din dreapta, de unde sunt captati in acelasi mod serial. Tot procesul se deruleaza pe durata a opt cicluri de clock, iar, in mod general, pentru operanzi de n biti, dureaza 2n perioade de clock.
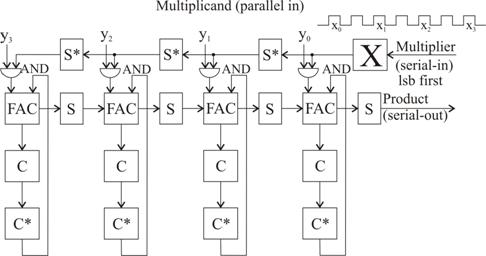
Pentru a transforma structura din fig. 3.61 intr-una complet sistolica, trebuie sa renuntam la difuzarea bitilor multiplier-ului X. In ideea respectiva constrangerii "short, local wires", sectionam conexiunea pe care se transmite xi in fig. 3.61 si urmarim, de asemenea, ca semnalele sa fie transmise doar intre celule adiacente la fiecare impuls de clock, asa cum o impune constrangerea de sistolic pur. Pentru a nu afecta corecta executie, in cazul nostru, a operatiei de inmultire, trebuie aplicat ceea ce in literatura [Parh00] este cunoscut drept sistolic retiming si care, la proiectul din fig. 3.61, este asigurat prin dublarea tuturor intarzierilor. Acestea se realizeaza substituind toate elementele de memorare S si C cu o cascada de doua flip-flop-uri, modalitate prin care, poate fi verificat cu siguranta, operatia se executa corect, fiind indeplinite anterior mentionate deziderate si, in plus, nu mai exista probleme de fan-out pentru linia de difuzare a lui x din fig. 3.61. Noua configuratie de inmultitor, de aceasta data, complet sistolica este data in fig. 3.62. Dublurile elementelor de memorare, marcate prin *, reclama un numar dublat de impulsuri de clock (la exemplul nostru, 15) sau un intreg sistem de clock mai sofisticat cu doua trenuri de impulsuri fara suprapuneri (non overlapping), ceea ce s-ar contura intr-o degradare consistenta de performanta. Pe de alta parte insa, conexiunile mai scurte, cu tot ceea ce implica, permit majorarea frecventei clock-ului estompand anterior amintitul dezavantaj.
Pe langa forma rudimentara de systolic array din fig. 3.62 exista procesoare sistolice menite a rezolva probleme aritmetice complexe cum ar fi inmultirea de matrici, solutionarea de sisteme de ecuatii liniare, evaluari de evolutie pentru aplicatii de prelucrare digitala a semnalelor s.a. [Haye98].
|
|
|
Fig.3.62 |
2. La multe din aplicatiile amintite, dar in special la
inmultiri de matrici, apar frecvent calcule de tipul ![]() , implicand succedarea unei inmultiri de o adunare.
Pentru a accelera asemenea calcule, multe dintre procesoare [HePa03], [Haye98]
au prevazute instructii speciale destinate acestor operatii
multiply-add, precum si unitati hardware dedicate care sa
permita implementarea eficienta prin prisma costului a celor
doua operatii combinate (combined multiply-add units). De asemenea
multe procesoare digitale de semnal (digital signal processors, DSPs)
prezinta facilitati hardware incorporate (built-in) pentru
operatii multiply-add, precum si pentru multiply-accumulate [DaTa05], [ErLa04], reprezentand o variatie de multiply-add
utila la evaluarea unei sume de produse.
, implicand succedarea unei inmultiri de o adunare.
Pentru a accelera asemenea calcule, multe dintre procesoare [HePa03], [Haye98]
au prevazute instructii speciale destinate acestor operatii
multiply-add, precum si unitati hardware dedicate care sa
permita implementarea eficienta prin prisma costului a celor
doua operatii combinate (combined multiply-add units). De asemenea
multe procesoare digitale de semnal (digital signal processors, DSPs)
prezinta facilitati hardware incorporate (built-in) pentru
operatii multiply-add, precum si pentru multiply-accumulate [DaTa05], [ErLa04], reprezentand o variatie de multiply-add
utila la evaluarea unei sume de produse.
Una dintre solutiile eficiente de implementare a acestor
unitati consta in apelarea la asa numita additive multiply
modules [Parh00], caror caracteristica este includerea
operandului de adunat z in procesul de inmultire ![]() . Astfel, exista constructii care prevad o
structura arborescenta de CSA-uri pentru realizarea inmultirii
care, inainte de a efectua insumarea finala prin CPA, prevede un nivel CSA
suplimentar pentru adunarea operandului z. In mod alternativ, procesul de calcul multiply-add nu se executa, in forma CSA, in mod
succesiv, ci printr-o operare multiply-add unificata (merged multiply-add
operation). Acestea din urma nu considera in mod distinct punctele
(produsele de un bit) intrarii de adunat z si cele ale matricii de puncte
corespunzatoare produselor partiale, ci le trateaza ca un tot
unitar operand in mod direct asupra lor [ErLa04].
. Astfel, exista constructii care prevad o
structura arborescenta de CSA-uri pentru realizarea inmultirii
care, inainte de a efectua insumarea finala prin CPA, prevede un nivel CSA
suplimentar pentru adunarea operandului z. In mod alternativ, procesul de calcul multiply-add nu se executa, in forma CSA, in mod
succesiv, ci printr-o operare multiply-add unificata (merged multiply-add
operation). Acestea din urma nu considera in mod distinct punctele
(produsele de un bit) intrarii de adunat z si cele ale matricii de puncte
corespunzatoare produselor partiale, ci le trateaza ca un tot
unitar operand in mod direct asupra lor [ErLa04].
3.
Constructia dispozitivelor de inmultire se poate confrunta cu
problema sintezei unui multiplier de dimensiune ![]() atunci cand se dispune
de multiplier-e n x n cand solutia poate fi gasita aplicand
strategia "divide-and-conquer" [Parh00]. Caracteristic acesteia este ca pleaca de
la cei doi operanzi pe 2n biti, X si Y, pe care ii considera
injumatatiti, adica, pentru multiplier-ul X, avem
partile XH si XL (cu indicii de la high
pentru partea mai semnificativa, respectiv low pentru cea mai putin
semnificativ), iar pentru multiplicand-ul Y, avem partile YH
si YL. Prin intermediul a patru inmultitoare n x n se
calculeaza cele patru produse partiale
atunci cand se dispune
de multiplier-e n x n cand solutia poate fi gasita aplicand
strategia "divide-and-conquer" [Parh00]. Caracteristic acesteia este ca pleaca de
la cei doi operanzi pe 2n biti, X si Y, pe care ii considera
injumatatiti, adica, pentru multiplier-ul X, avem
partile XH si XL (cu indicii de la high
pentru partea mai semnificativa, respectiv low pentru cea mai putin
semnificativ), iar pentru multiplicand-ul Y, avem partile YH
si YL. Prin intermediul a patru inmultitoare n x n se
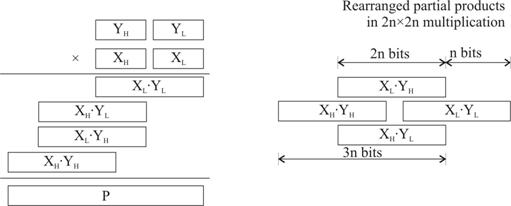
calculeaza cele patru produse partiale ![]() , dupa cum este aratat in fig. 3.63 [Parh00], [DaTa05]. Aceste patru valori trebuie adunate in vederea
obtinerii produsului final. Rearanjand produsele partiale asa
cum se arata in partea dreapta a fig. 3.63 si considerand
ca
, dupa cum este aratat in fig. 3.63 [Parh00], [DaTa05]. Aceste patru valori trebuie adunate in vederea
obtinerii produsului final. Rearanjand produsele partiale asa
cum se arata in partea dreapta a fig. 3.63 si considerand
ca ![]() si
si ![]() - intrucat nu se
suprapun - formeaza un singur numar, de fapt avem de adunat doar trei
valori. Prin urmare, problema initiala a sintezei unui inmutitor
- intrucat nu se
suprapun - formeaza un singur numar, de fapt avem de adunat doar trei
valori. Prin urmare, problema initiala a sintezei unui inmutitor
![]() a fost redusa la
cea a unui inmultitor
a fost redusa la
cea a unui inmultitor ![]() , replicat de 4 ori, si la cea a unui sumator de trei
operanzi.
, replicat de 4 ori, si la cea a unui sumator de trei
operanzi.
Evident, problema se supune la extensii de inmultitoare pentru ![]() biti,
biti, ![]() biti,
s.a.m.d. bazat pe blocuri constructive de inmultire pentru
biti,
s.a.m.d. bazat pe blocuri constructive de inmultire pentru ![]() biti [ErLa04].
biti [ErLa04].
|
|
|
Fig.3.63 |
4. Un caz special il constituie ridicarea la patrat (squaring)
si, prin extensie,
exponentierea. In mod evident, oricare dintre dispozitivele prezentate
poate executa operatia ![]() , la care avem multiplicand-ul
, la care avem multiplicand-ul ![]() . Totusi, acolo unde primeaza operatii ca
ridicarea la patrat si, mai general exponentierea, merita,
in general, investitia intr-un inmultitor dedicat acestui scop care
sa fie "ingropat" in hardware, intrucat el prezinta atat un cost mai
redus, cat si o intarziere mai mica decat un dispozitiv de
inmultire universal.
. Totusi, acolo unde primeaza operatii ca
ridicarea la patrat si, mai general exponentierea, merita,
in general, investitia intr-un inmultitor dedicat acestui scop care
sa fie "ingropat" in hardware, intrucat el prezinta atat un cost mai
redus, cat si o intarziere mai mica decat un dispozitiv de
inmultire universal.
Pentru a constata simplificarea pe care o aduce un dispozitiv dedicat
ridicarii la patrat, sa revenim la exemplul dat de (3.24), in
care il substituim pe Y cu X, si sa intervenim asupra relatiei
(3.26) luand in consideratie ca ![]() si
si ![]() . Obtinem deci:
. Obtinem deci:
|
|
Daca in (3.44) tinem cont ca inmultirea produsului ![]() cu 2 inseamna, de
fapt, mutarea lui in paranteza cu pondere mai mare, atunci avem:
cu 2 inseamna, de
fapt, mutarea lui in paranteza cu pondere mai mare, atunci avem:
|
|
Asupra relatiei (3.45) se mai poate interveni daca tinem seama de urmatoarele identitati evidente:
|
|
Aplicand (3.46) de doua ori, (3.45) devine:
|
|
Interventia noastra are un dublu efect benefic, anume, pe de o parte, reduce numarul de termeni din paranteza cu ponderea 24 (diminuand cu un nivel implementarea CSA), si, pe de alta parte, reducerea cu un rang a sumatorului CPA. Ar mai fi de observat ca am fi modificat si paranteza cu ponderea 26, dar aceasta nu ar mai avut o consecinta favorabila, ci dimpotriva.
Ar mai fi de mentionat ca valoarea ridicarii la
patrat a unui numar de n biti revendica un tabel, asa
denumit "lookup table" [ErLa04], de dimensiune maximala ![]() biti, mult mai
mica decat cea necesara inmultirii a doua numere de n
biti.
biti, mult mai
mica decat cea necesara inmultirii a doua numere de n
biti.
|
|
|
||||||
|
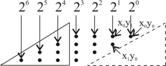
Fig.3.64a |
Fig.3.64b |
Fig.3.64c |
Plecand de la acest fapt, atunci cand se apeleaza la aritmetica
bazata pe look-up tables (arithmetic by table lookup) constituind o
alta modalitate de implementare a operatiilor aritmetice, doua
numere pot fi inmultite, prin trei adunari si doua
cautari in putin extinsul lookup table la valorile de patrate
uzitand de identitatea: ![]() .
.
in final, referindu-ne la exponentierea de forma ![]() , unde a este numarul intreg
fara semn, acesta se poate executa printr-o secventa de
pasi de ridicare la patrat sau combinatii de astfel de pasi
cu unii de inmultire. Pentru simplificare, avem
, unde a este numarul intreg
fara semn, acesta se poate executa printr-o secventa de
pasi de ridicare la patrat sau combinatii de astfel de pasi
cu unii de inmultire. Pentru simplificare, avem ![]() .
.
5. Pentru implementarea operatiei de inmultire a numerelor reziduale (rezidue numbers) se folosesc dispozitive speciale denumite modulare (modular multipliers) [Parh00], [RaFu89]. Atunci cand se inmultesc doua numere intregi si fara semn, un modular multiplier permite obtinerea produsului modulo o valoare fixa, constanta, denumita modul, pe care o notam cu μ. Implementarea unui astfel de dispozitiv se poate face prin atasarea la iesirea unui inmultitor binar de tipul celor studiate a unei scheme care sa permita obtinerea restului atunci cand valoarea produsului este impartita la μ, realizand asa numita operatie de reductie modulara. Aceasta solutie reclama stocarea intermediara a unor valori cu un numar, in general, insemnat de biti, ceea ce constituie un dezavantaj. Este insa posibil sa fie combinata reductia modulara cu acumularea produselor partiale ducand la o solutie superioara prin prisma impactului performanta-cost.
Sinteza dispozitivelor de inmultire modulara depinde in mod
decisiv de valoarea modulului μ. Fara a insista asupra
discutiei legata de alegerea lui μ [EfVN03], [Vlad86], aratam ca doua cazuri de
interes, datorita simplitatii solutiilor tehnice, sunt
reprezentate de ![]() si
si ![]() , unde, din nou, n reprezinta dimensiunea operanzilor.
Astfel, daca produsele partiale sunt acumulate prin adunare CSA,
atunci, pentru
, unde, din nou, n reprezinta dimensiunea operanzilor.
Astfel, daca produsele partiale sunt acumulate prin adunare CSA,
atunci, pentru ![]() , transportul (carry output) din celula sumator
, transportul (carry output) din celula sumator ![]() , cea mai semnificativa, este ignorat, asa cum,
pentru
, cea mai semnificativa, este ignorat, asa cum,
pentru ![]() , acelasi transport este aplicat celulei sumator 0, cea
mai putin semnificativa din etajul urmator. Fara a intra in
alte justificari, daca admitem
, acelasi transport este aplicat celulei sumator 0, cea
mai putin semnificativa din etajul urmator. Fara a intra in
alte justificari, daca admitem ![]() , atunci pentru
, atunci pentru ![]() , transportul din rangul 3 al CSA reprezinta valoarea 16
care mod 16 da 0, validand ignorarea, asa cum, pentru
, transportul din rangul 3 al CSA reprezinta valoarea 16
care mod 16 da 0, validand ignorarea, asa cum, pentru ![]() , transportul din rangul 3 al CSA inseamna
, transportul din rangul 3 al CSA inseamna ![]() deci adaosul unei
unitati binare la rangul 0 al proximului etaj CSA.
deci adaosul unei
unitati binare la rangul 0 al proximului etaj CSA.
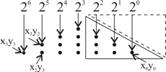
Ramanand in sfera aceluiasi exemplu si apeland la dot
notation, concordant cu relatia (3.26), dar si fig. 3.60(c), avem
repartitia de puncte corespunzatoare produselor de un bit ca in fig.
3.64(a), avand inramate intr-un triunghi, cu linie plina, punctele
corespunzatoare produselor de un bit insumate avand ponderile ![]() ,
, ![]() si
si ![]() . Intrucat nu se modifica ponderile respectivelor sume,
ele pot fi mutate in locurile vacante marcate prin triunghiul cu linie
punctata astfel incat se ajunge la repartitia de puncte a matricii
din fig. 3.64(b). In aceeasi figura, punctele din partea stanga
sunt inramate intr-un triunghi cu linie plina in vederea mutarii
lor in locurile vacante marcate prin triunghiul cu linie punctata. Mutarea
este justificata intrucat
. Intrucat nu se modifica ponderile respectivelor sume,
ele pot fi mutate in locurile vacante marcate prin triunghiul cu linie
punctata astfel incat se ajunge la repartitia de puncte a matricii
din fig. 3.64(b). In aceeasi figura, punctele din partea stanga
sunt inramate intr-un triunghi cu linie plina in vederea mutarii
lor in locurile vacante marcate prin triunghiul cu linie punctata. Mutarea
este justificata intrucat ![]() , adica ponderea
, adica ponderea ![]() , apoi
, apoi ![]() , adica pondere
, adica pondere ![]() , si, in fine,
, si, in fine, ![]() , adica ponderea
, adica ponderea ![]() . In consecinta, punctele au fost repartizate dand
configuratia din fig. 3.64(c), in care se arata noua pozitie in
dot matrice a unora dintre produsele de un bit.
. In consecinta, punctele au fost repartizate dand
configuratia din fig. 3.64(c), in care se arata noua pozitie in
dot matrice a unora dintre produsele de un bit.
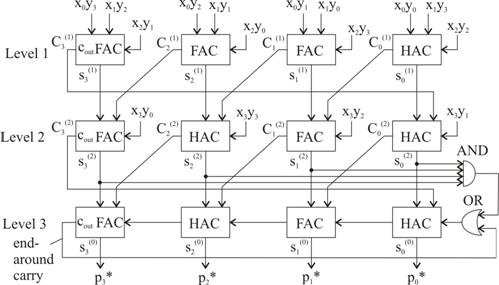
De fapt, matricea de puncte din fig. 3.64(c) sugereaza modul in
care trebuie adunate produsele de un bit astfel incat produsele partiale
sa rezulte modulo 15. Daca preconizam o implementare prin
calcule de vectori CSA, atunci structura de FAC-uri corespunzatoare
repartizarii punctelor din fig. 3.64(c), forme romboida de amplasare a
acestora din fig. 3.41 fiind substituita printr-una dreptunghiulara,
asa cum se prezinta in fig. 3.65. Conform cu cele deja convenite, se
observa conectarea legaturilor de carry-out din msb in lsb-ul proximului
etaj, precum si conexiunea de end-around carry ![]() si nu 0 cat este
normal intru-cat
si nu 0 cat este
normal intru-cat ![]() . Bitii pi (i=0,3) corespund valorii
produsului modulo 15.
. Bitii pi (i=0,3) corespund valorii
produsului modulo 15.
|
|
|
Fig.3.65 |
In calitate de exemplu, in fig. 3.66, am considerat inmultirea ![]() , la a carei rezultat, 182, daca se aplica
modulul 15 trebuie sa conduca la valoarea
, la a carei rezultat, 182, daca se aplica
modulul 15 trebuie sa conduca la valoarea ![]() . Dupa cum se observa din fig. 3.66, aceasta nu a
necesitat calculul produsului in extenso, adica a valorii
. Dupa cum se observa din fig. 3.66, aceasta nu a
necesitat calculul produsului in extenso, adica a valorii ![]() si apoi, acesteia sa i se aplice reductia
modulara, ci reductia modulara a fost combinata cu
acumularea produselor partiale.
si apoi, acesteia sa i se aplice reductia
modulara, ci reductia modulara a fost combinata cu
acumularea produselor partiale.
Rationamentele aplicate anteriorului caz rudimentar pot fi extinse la variate valori ale modului μ, conferind, prin intermediul codurilor reziduale, o importanta alternativa pentru verificarea operatiilor aritmetice, in general, iar, in particular, pentru inmultirea binara.
Bibliografie (se prezinta in ordinea alfabetica a numelor autorilor)
[HePa03] John L. Hennessy, David A. Patterson: "Computer Arhitecture, A Quantitative Approach" Morgan Kaufmann Publishers, Inc, Third edition, 2003
[PaHe96] David A. Patterson, John L. Hennessy: "Computer Arhitecture, A Quantitative Approach" Morgan Kaufmann Publishers, Inc, Second edition, 1996
[HePa94] John L. Hennessy, David A. Patterson: "Computer Organisation and Design. The Hardware/ Software Interface" Morgan Kaufmann Publishers, Inc, 1994
[Haye98] John P. Hayes: "Computer Arhitecture and Organisation" McGraw-Hill, Third edition, 1998
[Parh00] Behrovz Parhami: "Computer Arithmetic. Algorithms and Hardware Design" Oxford University Press, 2000
[ErLa04] Milos D. Ercegovac, Thoms Lang: "Digital Arithmetic" Morgan Kaufmann publishers, 2004
[Omond94] Amos R. Omandi: "Computer Arithmetic System. Algorithme, Arhitecture and Implementations" C.A.R. Hoare Series Editor, 1994
[Poll90] L. Howard Pollard: "Computer Design and Arhitecture" Prentice-Hall International, Inc, 1990
[Haye88] John P. Hayes: "Computer Arhitecture and Organisation" McGraw-Hill Book Company, 1988
[Yarb97] John M. Yarbrough: "Digital logic. Aplication and Design" West Publishing company, 1997
[ObVo92] Walter Oberschelp, Gottfried Vossen: "Rechneraufbau and Rechnerstrukturen" R. Oldenbourg Verlag, 1992
[Kuli02] Wrich w. Kulusch: "Advanced Arithmetics for the Digital Computer. Design of Arithmetic Units" Springer-Verlag, 2002
[RaPe96] Jan M. Rabaey, Massored Pedram: "Low Power Desing Methodologies" Kluwer Academic Publishers, 1996
[HiPe78] Fredrik J. Hill, Gerald R. Peterson: "Digital Systems: Hardweare Organisation and Design" John Wiley&Sons, Inc, Second edition, 1978
[BoTi05] Nicolas Boullis, Armand Tisserand: "Some Optimisations of Hardware Multiplication by Constant Matrices" IEEE Trans. on Computers, vol 54, no.10, October 2005, pp.1271-1282
[HuEr05] Zhijun Huang, Milos D. Ercegovac: "High-Performance Low-Power Left-to-Right Array Multiplier Design" IEEE Trans. on Computers, vol. 54, no.3, March 2005, pp. 272-283
[DaTa05] Albert Danysh, Dimitri Tan: "Arhitecture and Implementation of a Vector/ SIMD Multiply-Accumulate Unit" IEEE Trans. on Computers, vol. 54, no.3, March 2005, pp. 284-293
[SeFM05] Peter-Michael Sedel, Lee D. McFearin, David W. Matula: "Secondary Radix Recordings for Higher Radix Multipliers" IEEE Trans. on computers, vol. 54, no.2, February 2005, pp. 111-123
[EfVN03] Costas Efstathion, Haridimos T. Vergos, Dimitris Nikolos: "Modulo 2n±1 Adder Design Using Select-Prefic Blocks" IEEE Trans. on Computers, vol. 52, no.11, November 2003, pp. 1399-1406
[Korn94]
Peter
Kornerup: "A Systolic, Linear-Array Multiplier for a Class of Righ-Shift
Algorithms"
[Kung82] T.H. Kung: "Why Systolic Arhitectures?" Compter, vol. 15, no.1, 1982, pp.37-46
[Oliv01] Mauro Olivieri: "Design of Synchronous and Asynchronous Variable-Latency Pipelined Multipliers" Trans. on VSLI Systems, vol. 9, no.2, April 2001, pp. 365-376
[Vlad86] Mircea Vladutiu: "Tehnica testarii sistemelor de calcul" Litografia Institutului Politehnic Timisoara, 1986
[RaFu89] T.R.N.Rav, E. Fujiwara: "Error-Control Coding for Cumputer Systems" Prentice-Hall International, Inc, 1989
[ITRS01] International Tehnology Roadmap for SemiConductors-Interconnect, 2001
[Wake00] John F. Wakely: "Digital Design. Principles and Practices" Prentice-Hall, 2000
[Stal99] Willian Stallings: "Computer Organization and Arhitecture Design for Performance" Prentice Hall International, 1999
[TaYY85] N. Takagi, N. H. Yasuura, S. Yajima: "High-Speed VSLI Multiplication Algorithm with a Redundant Binary Addition Tree" IEEE Trans. on Computers, vol. 34, no.9, September 1985, pp.789-796
|
Politica de confidentialitate |
| Copyright ©
2024 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |