Baze
de date distribuite
Cuprins
Initiere
De
ce distribuite?
Concepte
Exemple de baze de date distribuite
Proiectarea
Procesarea
Prioritati
Principiu fundamental
Douasprezece
scopuri
Autonomie
locala.
Independenta
fata de nodul central
Functionare
continua
Independenta
de amplasare
Independenta
de fragmentatie
Independenta
de replicatie
Prelucrarea
adresarilor distribuite
Manajarea
tranzactiilor distribuite
Independenta
de dotarea tehnica
Independenta
de sistema de operare
Independenta
de retea
Independenta
de SGDB
Sisteme client -Server
Concluzii
Consideratii
finale
Bibliografie
Initiere
Centralizare
si descentralizare: doua tendinte opuse care au marcat alternativ evolutia
sistemelor informatice. Bazele de date distribuite reprezinta unul dintre
compromisurile cele mai profitabile, pastrind avantajele ambelor
abordari.
In 1988
Stonebraker prognoza ca in urmatorii 10 ani bazele de date
centralizate vor deveni doar o "curiozitate antica". [Stonebraker, pag.
189].
Chiar
daca "era" bazelor de date centralizate nu este оnca
terminata - dimpotriva, in ultimii doi ani acestea sunt din nou in
voga - interesul de care se bucura bazele de date distribuite, atit
in comunitatea stiintifica cit si in cercurile comerciale, demonstreaza
importanta acestui subiect pentru perioada actuala.
Spre deosebire de bazele de date centralizate, bazele de
date distribuite ofera o noua gama de posibilitati,
concepte de abordare si tehnologii, care bineinteles sint necesare
dezvoltarii gestionarii bazelor de date.
Odata cu dezvoltarea retelelor, o
tendinta vadita este utilizarea unor date in comun, accesul
la unele date indepartate, estimarea unor indicatori din analiza mai
multor baze de date diferite, separate una de alta, logic si fizic.
Anume acesta este obiectul si destinatia
bazelor de date distribuite, baze ale viitorului. In continuare, prezentam
o analiza a bazelor de date distribuite.
De ce distribuite?
Exista citeva elemente cheie care au motivat trecerea multor
companii de la sistemele centralizate de baze de date la cele distribuite. in
primul rind, costurile de comunicatie sunt mai mici in sistemele distribuite,
atita timp cit accesul la un computer local este mai ieftin decit accesul la
distanta. Pe de alta parte, autonomia locala a reprezentat unul
dintre cele mai importante avantaje oferite de sistemele de baze de date
distribuite. Conform unui studiu realizat de D'Oliviera in anul 1977,
"posibilitatea partitionarii autoritatii si a responsabilitatii
in sistemele informationale din management este unul dintre motivele principale
care au determinat multe organizatii sa treaca la sisteme
informationale distribuite". Si, cum in prezent sistemele informationale din
management sunt in general "computerizate", trecere la sisteme informatice
distribuite, respectiv la sisteme distribuite de baze de date, a fost
fireasca.
Sistemele distribuite de baze de date (DDBS - Distributed Database
Systems) ofera sistemelor informationale o serie de alte avantaje: permit
managerilor locali libertatea de a manipula informatiile astfel оncit
sa rezolve necesitatile departamentului pe care оl conduc,
reduc impactul provocat de eventualele caderi ale echipamentului. De
asemenea, prin crearea unor baze de date mai mici, la diferite locatii, se
asigura prevenirea pierderii datelor.
In luarea deciziei de trecere de la un sistem centralizat de baze de date la un
DDBS, firmele trebuie sa analizeze si dezavantajele prezentate de
sistemele distribuite. Daca structura firmei si stilul de management sunt
centralizate, atunci implementarea unui DDBS nu-si are rostul. Costurile de
reciclare a personalului si cele pentru achizitionarea software-ului adecvat
pot sa fie atit de ridicate оncit, mai ales pentru firmele mici,
modificarea sistemului informatic sa nu fie justificata din punct de
vedere economic. De asemenea, DDBS pot ridica atit probleme de sincronizare, de
consistenta si integritate a datelor, cit si probleme legate de controlul
accesului.
Sistemele distribuite de baze de date au aparut la granita dintre
doua domenii aparent opuse din punct de vedere al procesarii datelor:
sisteme de baze de date si retele de calculatoare. Bazele de date distribuite
se definesc [Ozsu] ca o colectie de baze de date logic interconectate,
distribuite peste o retea de calculatoare. Este bine de subliniat faptul
ca bazele de date distribuite nu sunt doar o colectie de tabele care pot
fi stocate individual in fiecare nod al retelei. Pentru a forma un DDBS,
tabelele trebuie sa fie logic interconectate, iar accesul la aceste tabele
se face printr-o interfata comuna.
Transformarea unui sistem centralizat de baze de date оntr-un
sistem distribuit consta in scindarea bazei de date centralizate in
sectiuni corespunzatoare si repartizarea acestor sectiuni in nodurile
retelei. Este important ca principiul fundamental al DDBS sa fie
respectat: "Utilizatorul trebuie sa vada un sistem distribuit exact
ca pe un sistem ne-distribuit". Scindarea bazei de date se realizeaza doar
la nivel fizic, la nivel logic ea ramine centralizata.
Software-ul DBMS evolueaza in permanenta. De-a lungul anilor
s-a trecut de la bazele de date ierarhice la cele normalizate, de la
centralizare la distribuire, fiecare dintre aceste etape implicind concepte
suplimentare de descriere, stocare si regasire a datelor. Daca
structurile de date pot sa para naturale unui inginer, nu acelasi
lucru trebuie prespus si pentru utilizatorul obisnuit. in realizarea unui
sistem de baze de date, distribuit sau nu, este esential caracterul "prietenos"
pe care acesta trebuie sa il prezinte utilizatorului final.
Realizarea sistemului distribuit implica luarea de decizii in ceea
ce priveste plasarea datelor si a programelor peste nodurile retelei de
calculatoare. in cazul sistemelor distribuite de baze de date, distributia
aplicatiei presupune atit distributia software-lui DBMS cit si distributia
programelor de aplicatie care vor rula pe acest software. in ceea ce priveste
softul DBMS, se presupune ca exista o copie a acestuia in fiecare nod
al retelei. Din punct de vedere al proiectarii DDBS, ceea ce intereseaza
este distributia programului aplicatie. Daca consideram ca reteaua de
calculatoare este deja proiectata, realizarea sistemului distribuit de
baze de date revine la rezolvarea a doua etape: proiectarea bazelor de
date distribuite si procesarea distribuita a cererilor.
Majoritatea DDBS-urilor actuale satisfac urmatoarele trei
presupuneri:
a. Fiecare nod al retelei este
un calculator care executa atit aplicatii program cit si functii de management
a bazelor de date distribuite;
b. Reteaua de calculatoare
poate sa fie de tip LAN sau WAN;
c. Gestiunea bazelor de date se
bazeaza pe modelul relational.
Concepte
Sistemele
de baze de date distribuite constau dintr-un set de noduri, legate intre ele printr-o retea comunicativa, in
care:
Fiecare
nod poseda bazele sale de deate proprii;
Nodurile
lucreaza sincronic, deaceia utilizatorul poate avea acces la orice nod al
retelei, ca si cum toate datele se afla pe nodul sau
propriu.
De
aici reiese ca asa numita "baza de date distribuita" in
esenta este o baza virtuala,
partile careia se pastreaza intr-o o serie de baze de
date reale aflate pe noduri diferite
ale retelei. Practic ea este imaginea logica a tuturor acesto baze de
date reale.
Trebuie
de mentionat insa ca fiecare nod poseda bazele de date
proprii utilizatorilor locali, un Sistem de Gestiune a Bazelor de Date (SGBD)
propriu, si softul necesar lucrului cu baza de date. In particular
utilizatorii unui nod pot opera cu baza nodului in asa fel ca si cum
acest nod nu este o parte a unui sistem distribuit a unei baze de date, ci este
o unitate complexa a bazei de date. In asa mod o baza de date
distribuita poate fi privita ca o modalitate de conlucrare
comuna a diferitor SGBD-uri, situate pe diferite noduri locale separate,
unde o componenta soft noua pe fiecare nod poseda toate
functiile lucrului in comun, adica este o continuitate logica a
bazei de date locale. Anume combinatia intre acest produs soft si
SGDB-ul existent de obicei este numita sistema distribuita de
manajare a bazelor de date.
De
cele mai dese ori se presupune ca nodurile sint despartite fizic
si geografic, dupa cum este indicat in desenul 1, cu toate ca in
realitate este de ajuns ca ele sa fie despartite logic. Cu toate ca este permis ca
doua "noduri" sa fie situate pe acelasi computer, mai ales in
timpul elaborarii si testarii sistemei. In ultimii ani sensul
unei baze de date distribuite s-a
schimbat usor. Necatind la toate ca in primele cercetari in
domeniul bazelor de date distribuite se descriau sisteme separate geografic,
printre primele sisteme comerciale distribuite foloseau o distribuire locala cu mai multe noduri,
amplasate in una si aceiasi cladire, unite intre ele printr-o retea locala. Insa din
punct de vedere a bazelor de date distribuite intre aceste doua
modalitati nu exista difirentieri substantiale,
deoarece in ambele cazuri este necesar de solutionat una si
aceleasi probleme tehnice si logice, deaceia situatia
prezentata in desenul 1 poate fi analizata ca o situatie tipica
a unei sisteme de baze distribuite.
Cu
toate ca teoria bazelor de date distribuite mentioneaza ca
SGDB-urile aflate pe nodurile retelei pot fi de diferite tipuri, in
practica de cele mai dese ori se intilnesc sisteme cu acelasi tip de
SGDB. Aceasta are loc din cauza simplificarii problemei de
comunicatie si compatibilitate intre SGBD-uri. Astfel de sisteme,
care utilizeaza acelasi tip de SGDB se numiesc unigene.
Sistemele
unigene au mai multe proprietati fata de sistemele
distribuite obisnuite din mai multe motive:
Compatibilitate
in comunicatie - de cele mai multe ori SGBD-urile avansate au o
varianta proprie de comunicare intre ele, necatind la toate ca
exita anumite standarde special elaborate pentru a solutiona aceste
probleme, ca de exemplu SQL (Structured Query Language). In multe cazuri, din
interese comerciale si eficacitate in lucru cu baza de date,
producatorii de SGBD-uri isi creaza un limbaj propriu, derivat
de la cel standard, care proseda un sir de caracteristici
imbunatatiri. De exemplu Oracle a elaborat PLSQL, InterBase -
SCSQL, sau Microsoft SQL a inventat MSSQL. Toate aceste derivari sint
compatibile cu standardul de baza SQL, sau SQL92, insa producatorilor
de soft le vine dificil de a elabora programe folosind numai standardul SQL,
deoarece acesta ofera un set mai restrins de posibilitati
si comenzi de tratare a bazelor de date fata de extensiile
acestora.
Concept de
abordare - cu toate ca teoria bazelor de date are una si
aceiasi ideologie in conceptul bazei de date, mecanisme de abordare
si lucru, multe SGBD-uri actuale au variantre proprii de abordare si
lucru cu baze de date. De exemplu InterBase are ca concept tratarea multiversionala a bazei de date,
metodologie care in Oracle sau Microsoft SQL Server nu este prezenta, sau
invers Oracle poseda functii avansate statistice, pe care InterBase
la curent nu le poseda, insa pot fi incluse prin definirea UDF (User
Defined Function). Toate aceste diversificatii ingreuneaza cu mult
elaborarea unui produs soft care ar asigura lucrul sincron distribuit al
diferitor SGBD-uri, cu toate ca teoria bazelor distribuite accepta
acest fapt si analizeaza problemele ce pot aparea la proiectarea
unei astfel de baze distribuite numai la nivel logic, in practica o pondere destul de mare in reusita
proiectului o au si problemele fizice
si specifice pe care le are fiecare
SGBD in parte.
Exemple de baze de date distribuite
In
calitate de exemle se poate de mentionat unele sisteme cunoscute de baze
de date distribuite. Dintre multiplele prototipe si sistemele
stiintifice de cercetare se poate de amintit sistema SDD-1, elaborata la sfirsitul
anilor "70 - inceputul anilor "80 in centrul de cercetare
stiintifica a companiei Computer Corporation of America; sistema R*
(se citeste R-star), care este versiunea distribuita a sistemei
System R elaborata la sfirsitul anilor "80 de compania IBM; si
deasemenea sistema Distributed INGRES,
care este versiunea distribuita a SGDB-ului INGRES, elaborata de
asemenea la sfirsitul anilor "80 in universitatea Berkley din California.
In
cea ce priveste produsele comerciale, atunci in majoritatea sistemelor
relationale sint precautate diferite metode si concepte de
abordari ale bazelor de date distribuide cu diferite nivele de
functionalitate si posibilitati. Dintre, pe cele mai
cunoscute, putem mentiona sistemul INGRES-STAR
o ramura a companiei Ingres Division, sistemul ORACLE al firmei Oracle Corporation, deasemenea componentele de
organizare a lucrului cu bazele de date distribuide ale sistemului DB2 ale companiei IBM, si ale
sistemului InterBase ale corporatiei InterBase. Trebuie de mentionat
ca toate sistemele amintite sint sisteme relationale de gestiune a
bazelor de date. Desigur exita multe motive dupa care un sitem eficace
distribuit trebuie sa fie
si relational, dar tehnologia relationala, este un factor
sau un mediu in care se poate de creat
un sistem efectiv de lucru distribuit.
Proiectarea
Problema proiectarii bazelor de date
distribuite (sau, altfel spus, cum vor fi plasate bazele de date si aplicatiile
in nodurile retelei) consta in fragmentarea bazelor de date, adica
descompunerea relatiilor initiale in subrelatii si apoi alocarea acestor
fragmente in nodurile retelei.
Exista doua modele de plasare a bazelor de
date in nodurile retelei:
a. Partitionat (total nereplicat): baza de date este оmpartita in
partitii disjuncte (fragmente), fiecare dintre aceste partitii fiind
plasata apoi in alt nod al retelei.
b. Replicat: acest model are la rindul lui doua variante - total replicat,
respectiv partial replicat. In varianta "total replicat" оntreaga
baza de date este stocata in fiecare nod al retelei. In varianta
"partial replicat" fiecare partitie a bazei de date este stocata in mai
multe noduri ale retelei, dar nu in toate.
In ceea ce priveste bazele de date replicate (total sau partial) s-au dezvoltat
doua mecanisme fundamentale de replicare : dinamica si respectiv
statica.
Definirea fragmentelor in
baze de date distribuite se realizeaza conform unor reguli similare cu
cele pentru definirea relatiilor virtuale (view) in bazele de date
centralizate. Mai mult decit atit, datele replicate pot fi tratate in acelasi
mod.
Intrebarile la care
trebuie sa raspundem pentru a realiza o fragmentare cit mai
"buna" sunt: "de ce sa fragmentam?", "cum fragmentam", "cit
de mult fragmentam?" si "cum putem verifica corectitudinea descompunerii?".
Raspunsurile la aceste intrebari depind in general de aplicatie.
Argumentul esential in
favoarea fragmentarii consta in posibilitatea executiei unor operatii
in paralel, pe diverse fragmente. Deci, fragmentarea creste concurenta.
Exista si argumente оmpotriva fragmentarii, si acestea se
refera la problemele de control semantic si integritate a datelor.
S-au dezvoltat doua
strategii fundamentale de partitionare:
a. Fragmentarea orizontala - partitioneaza o relatie de-a lungul tuplelor
sale; deci fiecare fragment contine un subset din tuplele relatiei.
b. Fragmentarea verticala - produce din relatia R partitiile R1, R2, Rn,
fiecare continind un subset al atributelor din R, inclusiv cheia primara.
Fragmentarea verticala a fost tratata pe larg in cazul bazelor de
date centralizate, dar in contextul bazelor de date distribuite ceea ce
intereseaza in primul rind este nesuprapunerea fragmentelor (exceptind
cheia primara).
De cele mai multe ori, pentru o aplicatie
reala, o simpla partitionare verticala sau orizontala nu este
suficienta, deci se aplica ambele variante, conducind astfel la
aparitia celui de-al treilea tip de fragmentare, numita hibrida.
Al doilea pas in proiectarea
bazelor de date distribuite consta in alocarea fragmentelor in nodurile
retelei. in cazul in care alocarea se realizeaza conform modelului
partitionat, procesarea cererilor este dificila dar controlul concurentei
este relativ usor de realizat. Alternativa replicarii totale conduce la o
procesare usoara a cererilor, dar controlul concurentei este moderat.
Daca consideram un set
de fragmente F= pe
care ruleaza un set de aplicatii Q, problema alocarii revine la
determinarea distributiei optime a lui F peste R.
Un pas important pentru
aflarea solutiei este definirea "optimului", care poate fi considerat:
a. costul minimal - functia de cost consta din costul stocarii fiecarui
fragment Fi in nodul Rj, costul procesarii lui Fi la nodul Ri, costul
actualizarii lui Fi in toate nodurile unde este stocat si costul
comunicatiilor de date.
b. performanta - strategia de alocare este proiectata astfel оncit sa
mentina o anumita performanta (de exemplu minimizarea timpului
de raspuns).
Problema alocarii poate
fi specificata ca o problema de minimizare a costului in care se
оncearca gasirea unui set I din S care specifica unde vor
fi stocate copiile fragmentelor.
Problema este NP-hard, in
concluzie solutiile propuse sunt euristice si depind, in general, de aplicatie.
In literatura de
specialitate exista citeva linii de cercetare in domeniu. Chang a
dezvoltat independent o teorie pentru fragmentarea si alocarea bazelor de date
[Chang]. Mai utilizata in implementarea sistemelor distribuite este
оnsa teoria fragmentarii propusa de Ceri, Pelagatti si
Widerhold [Ceri1], [Ceri2].
In ceea ce priveste problema
alocarii, majoritatea modelelor se ocupa de alocarea fisierelor
simple, fara a lua in considerare aspectele legate de distributia
datelor. Ozsu si Valduriez au prezentat un model care rezolva, la un nivel
minim, problemele specifice alocarii bazelor de date [Ozsu].
In luarea deciziei privind
proiectarea bazelor de date distribuite pentru un anumit sistem trebuie, in
general, sa se raspunda urmatoarelor оntrebari:
Vor reduce fisierele locale volumul traficului de comunicatii (mesaje,
tranzactii, etc.)?
Este necesar pentru toate statiile sa actualizeze aceleasi
оnregistrari?
Daca statiile au nevoie sa acceseze оnregistrari,
cit de des trebuie acestea sa fie actualizate? De exemplu, pretul
marfurilor de vindut se modifica la anumite intervale de timp.
Pot fi utilizate fisierele locale pentru a verifica datele de intrare?
Fac parte inregistrarile unei tabele, in mod natural, din
fragmente care sa poata fi pastrate in noduri dispersate?
Cine este responsabil de pastrarea integritatii
оnregistrarilor din fisier si de actualizarea acestora? Daca
responsabilitatea revine unui departament central, este necesar ca acesta
sa informeze pe toti detinatorii fisierelor distribuite de fiecare
data cind au fost facute modificari?
Siguranta bazelor de date distribuite este pastrata
satisfacator in mod local?
Procesarea
Procesarea distribuita a cererilor are
urmatorul scop: dindu-se o interogare pentru o BDD, sa se
gaseasca o strategie de executie corespunzatoare care
minimizeaza costurile de comunicatie. Strategia este descrisa in
termenii operatorilor din algebra relationala folosind si primitive de
comunicatie (send/recevie) aplicate bazelor de date locale.
Procesul este compus din urmatoarele etape:
a. Descompunerea cererilor: realizeaza transformarea cererilor din calcul
relational (limbaj de nivel оnalt) in termenii algebrei relationale.
Deoarece atit cererile de intrare cit si cele de iesire sunt globale,
fara cunostinte despre distributia datelor, problema se trateaza
similar cu cazul bazelor de date centralizate.
Procesul are 4 pasi:
normalizarea - se transforma in forma conjunctiva
normala sau in forma disjunctiva normala.
analiza semantica - determina cererile incorecte din punct de
vedere semantic si le elimina.
eliminarea redundantei - prin aplicarea unor reguli de simplificare
asupra predicatelor obtinute in prima etapa se elimina predicate
inutile.
rescriere - se rescrie cererea in termenii algebrei relationale.
b. Localizarea datelor: se transforma cererea globala exprimata in termenii
algebrei relationale оntr-o cerere fragmentata aplicata
fragmentelor bazei de date.
c. Optimizarea globala si locala a cererilor: cererea rezultata din
primii doi pasi poate fi executata dupa simpla adaugare a
primitivelor de comunicatie. Permutarile posibile in ordinea operatiilor
din cerere pot sa conduca la diverse strategii de executie. Rolul
acestui pas consta in gasirea unei ordini "optimale".
Exista doi algoritmi de
optimizare "clasici" - algoritmul propus in Ingres (Stonebraker), care este un
algoritm dinamic si algoritmul propus in System R (Astrahan), care este un
algoritm static.
Pentru implementarea unui sistem distribuit de baze
de date este necesar un limbaj de date relational (SQL) bazat fie pe algebra
relationala, fie pe calculul relational. Pentru scrierea aplicatiilor
complexe, SQL nu este suficient si de aceea interfatarea cu un limbaj de
programare (procedural) este de obicei necesara. Un astfel de limbaj de
programare este PASCAL/R, care contine un nou tip de variabila, numit
relation.
Limbajele de generatia a 4-a (4GL) sunt limbaje de nivel оnalt care
combina operatorii din algebra relationala cu constructii de program.
Posibilitatea de a utiliza variabile temporare si constructii puternice de
program face ca aceste limbaje numite "limbaje de programare orientate spre
baze de date" (Oracle, Ingres, etc.) sa fie deosebit de utile la scrierea
aplicatiilor.
Prioritati
De ce oare sint atit de necesare bazele de date
distribuite? In general pentru aceia ca unitalile mari, au de
regula o structura distribuita, macar din motive ca ele
sint despartite logic, in departamente, sectoare, sectii, sau
chiar fizic, de exemplu in uzine, fabrici, laboratoare, linii de prelucrare
etc. Din aceasta reiese ca datele intre ele deasemenea sint distribuite,
deoarece la diferite nivele organizationale se duce lucrul cu date
specifice sau necesare acestui nivel. In asa mod, intr-o sistema
distribuita se poate de elucidat structura organizationala a
unitatii reiesind din structura logica a bazei de date,
adica datele cu destinatie
locala pot fi salvate in bazele locale, iar accesul la datele indepartate
se face numai dupa necesitati.
Sa
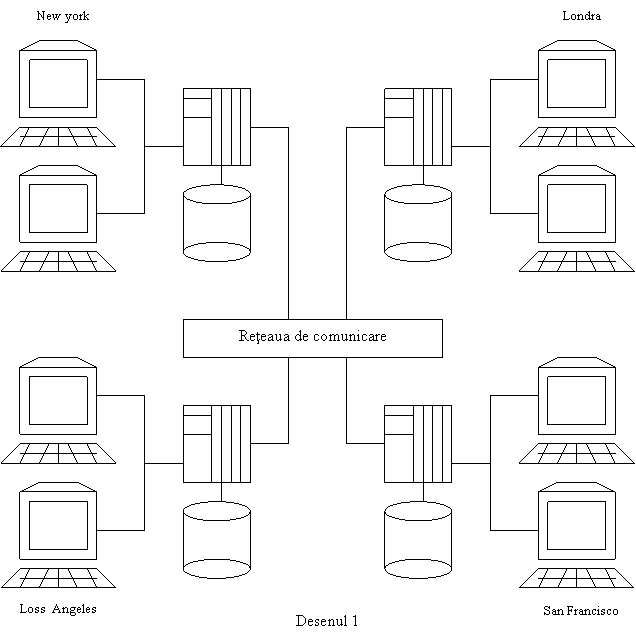
analizam de exemplu Desenul 1, unde este elucidata o schema
bancara simplificata care deserveste patru orasele New
York, Loss Angeles, Londra si San Francisco. Conforma acestei scheme, in
fiecare din orase, se pastreaza datele bancare despre
clientii din aceste orase. O prioritate a acestui sistem este
vizibia: in sistemele cu baze de date distribuite este combinata prelucrarea eficace a datelor, deoarece
datele se afla aproape de locul unde se prelucreaza si se
mareste vadit accesul la
date, de exemplu din New York, putem usor controla orice
informatie despre un client, sau a face orice tip de operatii bancare
cu conturile clientului din Londra si invers.
Posibilitatea
oglindirii structurii orgranizatieie in structura logica a bazei de
date, este, poate, cea mai substantiala prioritate a bazei de date
distribuite. Insa bazele de date distribuite au o serie de prioritati,
pe care le vom analiza mai jos. Insa trebuie de mentionat ca
bazele de date distribuide si lucrul cu ele au deasemenea si unele
neajunsuri, in particular compeyitatea
bazei de date distribuite, macar din punct de vedere tehnic. In cazul ideal
aceasta va fi o "surpriza" pentru programator, dar nu pentru utilizator.
Insa daca nu se iau toate aspectele si masurile necesare,
la elaborarea produsului soft, unele nuante din aceasta complexitate
pot fi actuale si pentru utilizatori.
Principiu fundamental
Acum
dupa o mica introducere putem formula principiului fundamental al bazei de date distribuite:
Pentru utilizator o sistema
distribuita trebuie sa apara ca si cum ar fi o sistema
Hedistribuita
Altfel
vorbind, lucrul utilizatorului intr-o sistema distribuita trebuie de
organizat in asa fel incit, ca si cum ea nu ar fi distribuita. Tote problemele legate de
particularitatile sistemelelor distribuite trebuie sa fie
interne, si trebuie sa apara numai la un nivel intern, la
nivelul elaborarii, dar nu la un nivel extern sau la nivelul
utilizatorului.
Remarca. In contextul dat termenul de "utilizator" se
refera la utilizatorul sau utilizatorii sistemului, care executa
operatii de gestiune a datelor.
Toate aceste operatii trebuie sa fie logic neschimbate, spre
deosebire de operatiile de determinare
a datelor, care din contra pot fi extinse chiar si de utilizator. De
exemplu utilizatorul nodului X poate
indica ca relatia pastrata poate fi "fragmentata" pe
nodurile Y si Z.
Principiul
fundamental al bazelor de date distribuite duce la un set de reguli
ajutatoare si scopuri proprii unei baze de date distribuite:
a.
Autonomie locala.
b. Independenta
fata de nodul central
c.
Functionare continua
d. Independenta
de amplasare
e.
Independenta de fragmentatie
f.
Independenta de replicatie
g. Prelucrarea
adresarilor distribuite
h. Manajarea
tranzactiilor distribuite
i.
Independenta de dotarea tehnica
j.
Independenta de sistema de operare
k. Independenta
de retea
l.
Independenta de SGDB
A ceste douasprezece scopuri nu se afla independente una
fata de alta, plus la toate nu toate din ele au acelasi grad de
insemnatate, si cu ele sigur inca nu se incheie lista tuturor
scopurilor posibile. Ele insa sint foarte utile la intelegerea
conceptului de baze de date relationale si pentru functionarea
generala a unui sistem de baze de date distribuite.
Trebuie de difirentiat insa sistemele
cu baze de date distribuite
fata de sistemele cu baze de date indepartate.
Intr-un sistem cu baze de date distribuite utilizatorul lucreaza cu o
multime de baze de date indepartate concomitent si sincron de
parca ar fi locale, insa in sistemele cu baze de date
indepartate, toate datele se afla pe un nod indepartat,
utilizatorul indicindu-i nodului indepartat operatiile cuvenite de
gesionare a bazei de date. Printre tehnicile ce folosesc baze de date
indepartate poate fi amintia tehnologia Client/Server.
Douasprezece scopuri
Autonomie locala
Intr-o sistema de baze de date
distribuite, nodurile trebuie sa fie autonome.
Autonomie locala presupune ca operatiile efectuate pe acest nod trebuie
sa fie conduse anume de acest nod, adica functionarea
oricarui nod X nu depinde de
succesul functionarii sau realizarii operatiilor pe un
oricare alt nod Y, in caz contrar
lipsa acestei reguli duce la consecinte neplacute, daca de
exemplu un nod Y este defectat, nodul
X, dependent de Y, deasenea nu poate functiona. Din principiul autonomiei
locale reiese inca si faptul ca odata cu prelucrarea
datelor local are loc deasemenea in mod local si controlulul
integritatii si a tuturor restrictiilor aplicate bazei de
date.
In realitate scopul autonomiei locale nu se
atinge complet, din cauza ca exista o multime de
situatii in care nodul X trebuie sa-I acore o parte din
controlul datelor altui nod Y.
Deaceia scopul atingerii autonomiei locale are nevoie de o formulare mai
precisa, si anume: nodurile trebuie autonomizate pina la nivelul maxim posibil.
Independenta de
nodul central
Sub termenul de autonomie locala se
subintelege ca toate nodurie
trebuie abordate ca egale. Rezultativ nu trebuie sa existe nici o
dependenta de nodul central, de "baza", cu o oarecare deservire
centralizata, ca de exemplu prelucrarea centralizata a
adresarilor la baza de date sau organizarea centralizata a lucrului
cu tranzactiile asupra bazei. In asa mod, al doilea scop este o continuare
logica a primului, adica daca este atins primul scop, atunci al
doilea este indestulat cu atat mai mult. Insa daca autonomia
locala nu este atinsa total, atunci si independenta de
nodul central este foarte importanta si poate fi tratata ca un
scop aparte.
Dependenta de nodul central este de
nedorit in cel mai rau caz din doua motive. In primul rind, nodul
central poate fi "ingust" pentru tot sistemul, iar intr-al doilea caz sistemul
devine legat, si in cazul defectarii centrului poate iesi din
functiune tot sistemul.
Functionarea
continua
Una din principalele prioritati ale
sistemului distribuit este aceia ca ele asigura o stabilitate si
o accesibilitate sporita.
Stabilitate
- probabilitatea ca sistemul este in functiune si
functioneaza in orice moment de timp nu lucraza dupa
principiul "tot sau nimic", dar in regim continuu, adica lucrul sistemului
continua, cu toate ca la un nivel mai scazut, chiar daca
unele noduri ale sistemei au iesit din functiune.
Accesibilitate
- probabilitatea ca sistemul este in functiune si
functioneaza in decursul unei perioade de timp se mareste
partial din cauza aceluiasi motiv, cit si din motivul
posibilitatii replicatiei datelor, metoda care o vom descrie
putin mai tarziu.
Independenta de
amplasare
Principala ideie a independentei de
amplasare, care se mai numeste si transparenta aplasarii, este destul de simpla:
utilizatorii nu urmeaza sa cunoasca in ce loc fizic are loc
pastrarea datelor, invers, din punct de vedere logic, utilizatorilor
trebuie sa li se asigure un asa regim, in care sa apara
iluzia ca toate datele se afla pe nodurile sale proprii. Asigurarea
independenlei de amplsare este foarte benefica, deoarece aceasta
simplifica mult, la nivel exterior, programul utilizatorului si
insasi conceptul si termenii de lucru. In particular aceasta
permite de efectuat migrarea datelor de la un nod la altul.
Independenta de
fragmentatie
Intr-o
baza distribuita se sustine fragmentatia
datelor, daca o oricare relatie, cu scopul pastrarii
fizice poate fi despartita pe parti sau "fragmente".
Fragmentatia este de binevenit, deoarecea ea mareste
productivitatea bazei distribuite, deoarece datele e bine de pastrat in acel
loc, unde ele mai des sau uzual se folosesc. La o asa organizare, multe
operatii vor fi pur si simplu locale, si fluxul de date in
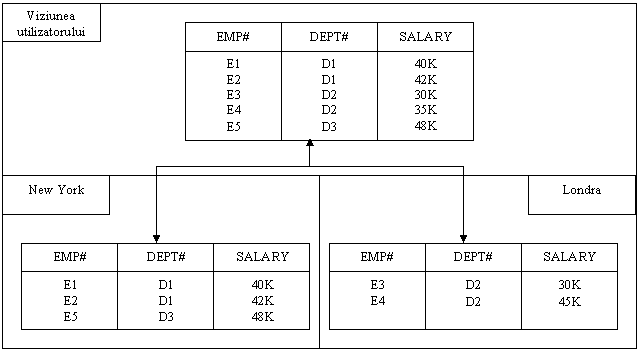
retea se va micsora considerabil. De exemplu sa analizam
relatia sistemului bancar international (EMP) din desenul 1. In
aceasta sistema este sustinuta fragmentatia, ti
sint determinate doua fragmente, dupa cum e indicat in desenul 2:
Printr-un set de operatori SQL, aceasta ar
avea forma:
FRAGMENT
EMP INTO
N_EMP AT SITE "New York" WHERE DEPT# =
"D1" OR DEPT# = "D3"
N_EMP
AT SITE "Londra" WHERE DEPT# = "D2";
Remarca: Se presupune ca toata informatia
despre clientii bancii din New-Yourk se pastreaza numai pe
nodul New-York, si resprectiv pentru clientii bancilor din
Londra, in Londra. Acrasta este elucidata in structura interna a
tabelelor (relatiilor) N_EMP si L_EMP.
Deosebim
doua tipuri de fragmentatie - pe orizontala si pe
verticala, care sint legate cu operatii de selectie si
proiectie. Trebuie de resprectat insa urmatoarele
restrictii:
a.
Se presupune ca tuplurile relatiei date sint independente unul fata de
altul, adica nici una din relatii nu poate fi determinata de
altul. Ca exeplu putem lua exemplul nostru, unde suma, sau contul unui client
al bancii din New York
nu are nici o legatura cu nici un client din Londra, sau invers. Daca
apare necesitatea salvarii uneia si aceiasi informatie,
atunci folosim mecanismul replicarii, care il vom analiza mai jos.
b. Proiectiile
nu trebuie sa permita pierderea informatiei
c. Trebuie
de mentionat faptul ca anume usurinta realizarii
fragmentatiei si a reconstruirii structurii bazei de date - este una
din principalele motive din care intr-o baza de date relationala
se utilizeaza baze de date relationale. Adica, pentru a putea
fragmenta baza, este nevoie de un set de operatii compatibile cu bazele de
date cu o structura relationala.
O baza de date distribuita, care
suporta fragmentatia datelor, trenuie de asemenea sa se
supuna criteriului independentei
de fragmentatie. Cu alte cuvinte, din punc de vedere logic,
utilizatorilor trebuie sa le oferim un asa regim de lucru in care
datele par absolut nefragmentate. Independenta de fragmentatie este
foarte benevenita, deoarece simplifica mult realizarea
interfetelor terminale, pentru utilizator.
Independenta de fragmentatie
presupune ca datele vor fi prezentate pentru utilizator intr-o forma
de combinatii logice. Cu aceasta optimizatorul de sistem gestioneaza
si determina fragmentele respective carora trebuie sa le
acorde acces fizic utilizatorului, pentru executarea oricarei
interpelari ale utilizatorului. In calitate de exemplu presupunem, ca
pentru fragmentarea ilustrata in desenul 2 utilizatorul se adreseaza
cu urmtoarea interpelare:
EMP
WHERE SALARY > 40K AND DEPT# =
"D1"
In
acest caz, optimizatorul, determina adresa fizica a datelor,
adica pe ce nod se afla, New-York sau Londra. Daca analizam
exemplul mai detaliat, observam ca relatia EMP este
sezizata de utilizator ca prezentarea
fragmentelor N_EMP si L_EMP:
EMP
= N_EMP UNION L_EMP.
Reiesind
din aceasta, optimizatorul reformuleaza interpelarea utilizatorului in
urmatoarea forma:
(N_EMP
UNION L_EMP) WHERE SALARY > 40K AND DEPT# = "D1"
Iar
aceasta expresie poate fi reformulata astfel:
(N_EMP
WHERE SALARY > 40K AND
DEPT# = "D1")
UNION
(L_EMP
WHERE SALARY > 40K AND
DEPT# = "D1")
Din
fragmenul bazei de date distribuie L_EMP, optimizatorul cunoaste ca
partea a doua a interpelarii va intoarce o multime vida, deaceia
interpelarea initiala a utilizatorului intr-o forma finala
are forma:
N_EMP WHERE SALARY > 40K AND DEPT# = "D1".
Independenta de
replicatie
Intr-o
baza de date distribuita exista independenta de replicatie, daca relatia
data sau portiunea data poate fi prezentata ca o
multime de copii diferite, sau replici,
pastrate pe noduri diferite, ale bazei de date distribuite.
Prezentam
acum un exemplu de replicatie, in desenul 3:
REPLICATE
N_EMP
LN_EMP AT SITE "Londra" ;
REPLICATE
L_EMP
LN_EMP AT SITE "New York" ;
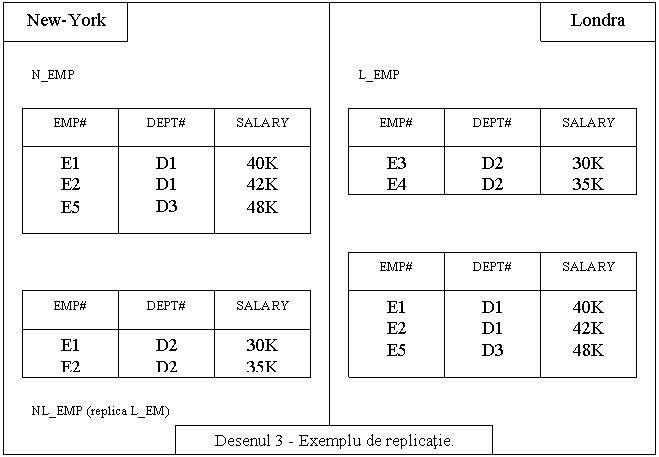
Replicatia e folositoare, in principal din
doua motive. In primul rind, datorita ei, se atinge o productivitate
sporita, aceasta se explica prin faptul ca aplicatiile
lucreaza cu copiile datelor, pe nodul local, si nu face schimb de
informatii cu nodurile indepartate. Intr-al doilea rind
replicatia sporeste accesibilitatea datelor, deoarece se poate de
efectuat orice operatie cu datele atit timp cit exista macar o
replica a datelor.
Principalul neajuns
al replicatiei consta in faptul ca reinnoind obiectul
relational analizat, toate replicile acestui obiect, trebuiesc deasemenea
actualizate. Acest neajuns se numeste problema actualizarii distribuie, pe care o vom cerceta putin mai
jos.
Printre altele, trebuie de mentionat
ca replicatia intr-o baza de date distribuita prezinta
un mod special de tratare a neajunsurilor.
Intr-un caz ideal, replicatia, ca si
fragmentatia, intr-o baza de date distribuita trebuie sa
fie "nesesizata de utilizator". Altfel vorbind, intr-o baza de date
distribuita, in care este prezenta replicatia datelor, trebuie
de asemenea sa fie prezenta si independenta de replicatie, adica pentru
utilizatori, macar din punct de vedere logic, trebuie sa lucreze intr-un
asa regim, ca si cum datele nu sint replicate de loc.
Independenta de replicatie presupune
ca optimizatorul sistemului raspunde de locatia fizica a
datelor replicate si are sub control actualizarea tuturor replicilor, la o modificare a datelor replicate.
In incheiere trebuie sa
mentionam ca multe SGDB-uri comerciale, in timpul de
fata propun o forma de replicatie care nu asigura
independenta totala de replicatie.
Prelucrarea
interpelarilor distribuite
Prezentam in
continuare doua intrebari largi si complexe.
Analizam interpelarea "A primi informatii despre
distribuitorii de piese rosii, aflati in Londra", unde mai presupunem
ca utilzatorul se afla in New-York, iar datele se
afla pe nodul din Londra. Presupunem de asemenea, ca conform
interpelarii utilizatorului corespund n distribuitori. Daca sistemul
este relational, atunci adresarea la baza va fi constituita din
doua fluxuri informationale sau traficrui, sau traficuri - unul cu
interpelarea clientului, adresata nodului din New-York, si altul cu
intoarcerea rezultatelor - raspuns pentru utilizatorul din Londra. In
cazul cind sistemul nu este relational, vom avea de a face cu 2*n traficuri, spre New-York pentru
gasirea urmatorui
distribuitor ce satisface conditiile propuse, si din New-York,
raspunsul respectiv despre urmatorul
distribuitor. Acest exemplu ne arata ca de cele mai multe ori, bazele
de date relationale operaza cu datele de citeva ori mai repede decit
alte modele, macar la prelucrarea datelor la nivel de multimi.
Problema optimizarii etste mult mai "dureroasa" si mai
principala in cazul bazelor de date distribuite, decit in cazul celor
centralizate. Principala problema si ideie consta in faptul
ca la procesarea unei interpelari ale utilizatorului adresata la
mai multe noduri, se poate efectuat in mai multe feluri, in ce priveste
deplasarea datelor de la un nod la altul. In acest caz, este foarte rezonabil
de gasit solutia optima in ceia ce priveste gestiunea
datelor si prelucrarea interpelarilor. De exemplu, o interpelare
adresata bazei de date ce are ca rezultat uniunea multimilor Rx aflata pe nodul X si multimea Ry aflata pe nodul Y, poate fi realizata prin
deplasarea relatiei Rx la nodul Y, deplasarea relatiei Ry la nodul X, sau prin deplasarea ambelor relatii pe un alt nod Z. Uneori strategia optima aleasa
difera prin timpul de prelucrare chiar cu ordinul orelor fata de
unele mai putin optimizate, nemaivorbind de cele neoptimizate.
Gestionarea tranzactiilor distribuite
Exista doua aspecte de baza de gestionare a
tranzactiilor distribuite, si anume gestionarea "recuperarii"
si gestionarea "paralelismului". Ambelor acestor aspecte trebuie sa
le acordam o atentie deosebita. Gestionarea tranzactiilor
asupra bazelor de date distribuite este mult mai dificla de realizat, din
motivul ca o interpelare a unui client poate modifica, adauga,
sterge noi date de pe diferite noduri ale bazei. Aici poate de vorbit
despre notiunea de agent, care
desemneaza o operatie facuta asupra datelor de pe un nod al
bazei distribuite. De exemplu, incazul cind modificam, printr-o singura
interpelare preturile petroluilui, de pe toate nodurile, atunci pe toate
nodurile, se creaza asa numitii agenti, niste procese,
care duc contul despre operatia in cauza, la o alta interpelare
a altui utilizator apar alti agenti pe nodurile respective. La
operatia salvarii lucrului COMMIT WORK sau la anularea lui, ROOLBACK
WORK, sistemul trebuie sa determine corelatia agentilor si
a relatiilor dintre ei, sau a conflictelor ce pot aparea, ca de
exemplu DEADLOOK.
Aplicarea "recuperarii" presupune ca la
sfirsitul tranzactiei primim succes sau insucces, de tipul "totul sau
nimic". Pentru a evita insuccesele, care de cele mai dese ori sint nedorite, se
utilizeaza deseori tranzactie
multifaza, axata pe generarea automata a tranzactiilor
asupra operatiilor respective.
In cea ce priveste "paralelismul", atunci in bazele de
date distribuite, ca si in cazul celor cemtralizate se aplica
blocarea inregistrarilor, care de multe ori este nedorita, mai ales
cind se executa operatii asupra multimilor. O solutie,
intilnita in SGDB-urile moderne este tehnologia "multiversiunilor",
aplicata de exemplu in SGDB-ul InterBase al Corporatiei Inprise.
Independenta de dotarea tehnica
Practic la acest capitol nici nu prea avem ce mentiona,
deoarece totul este explicat deja insati in denumirea capitolui. In
prezent deosebim o larga diversificare a calculatoarelor, in ce-a ce
compania producatoare, din care putem mentiona Hewleet Packard, IBM,
DELL etc. Deci o conditie necesara bazelor de date distribuite este
compatibilitea ei cu calculatoarele respective.
Independenta de dotarea tehnica
In ultimul timp observam o diversificare larga a
sistemelor de operare existente. Din ele putem mentiona Windows 95-98,
Windows NT, familia Unix, QNX, Beo etc.
In legatura cu aceasta exista o problema
reala in ceia ce priveste compatibilitatea bazei de date sau a
SGDB-ului cu sistemul de operare cuvenit. Multe sisteme de gestiuen a bazelor
de date sint cunoscute ca fiind compatibile cu mai mai multe sisteme de
operare. Insa deseori ele apar cu mici modificari sau limitari,
de exemplul InterBase ruleaza pe sistemele Windows 95-98, Windows NT,
Unix, Linux, FreeBSD, insa pe platformele Unix sau Linux, utilieaza
tehnologia SimpleServer, iar pe platformele Windows 95-98, Windows NT, FreeBSD
tehnologia SuperServer, in cea ce priveste prelucrarea
interpelarilor.
Independenta de retea
Cunoastem deja mai multe tipuri de retea, care in
cazul bazei de date distribuite pot lega intre ele nodurile. Pot fi insa
cazuri cind unele segmente de retea ce unesc nodurile respective sa
fie de diferite tipuri de retea. Atunci este binevenit faptul ca SGDB-ul
ce suporta bazele de date distribuite trebuie sa fie compatibil la
fel, ca si in cazul sistemelor de operare cu mai multe tipuri de
retea.
Independenta de SGDB
O baza de date
distribuita, cel putin teoretica, necesita compatibilitatea
cu diferite SGDB-uri, aceasta se explica prin faptul ca unele noduri
ale bazei de date distribuite pot fi gestionate de un SGDB, iar o alta
parte din noduri de alt SGDB. De multe ori, in practica, este intilnit
cazul cind exita deja diferite baze de date, gestionate de difertite
SGDB-uri, care cer reformalizate si reunite intr-o baza de date
distribuita. Teoretic aceste SGDB-uri ar trebui sa "comunice" intre
ele, mai ales daca ambele suporta standardul SQL, insa in multe
carui multe SGDB-uri isi dezvolta propriile sale extensii ale
limbajului SQL, derivate care sint facilitati necompatibile intre
ele.
Sisteme de tip Client-Server
Sistemele Client-Server pot fi percepute ca o varianta
sau un caz particular al bazelor de date distribuite. Mai precis, sistemele
Client-Server sint niste sisteme distribuite in care unele noduri sint clientii iar altele serverul. Datele se pastreaza
pe server, iar interfetele, sau programele ruleaza pe clienti.
Sistemele Client-Server, se deosebesc putin de bazele reale distribuite
prin faptul ca datele se pastreaza numai pe server, adica
de la clienti parvin numai interpelarile, iar toate
modificarile, operatiile sint executate de server, serverul in acest
caz duce controlul total asupra tranzactiilor efectuate de clienti.
Cu toate acestea, putem considera sistemele Client-Server ca o varianta
simplificata a bazelor de date distribuite.
Concluzii
Conceptia, elaborarea, exploatarea,
оntretinerea si evaluarea sistemelor distribuite de baze de date
constituie un proiect care impune concentrarea unor resurse umane si materiale
importante pe o perioada оndelungata de timp.
Aceste greutati sunt generate atit de
dimensiunea si complexitatea problemelor ce trebuie rezolvate, cit si de faptul
ca instrumentele tehnologice specifice sunt inca destul de
sarace. in acelasi timp, cerintele aplicatiilor ce urmeaza sa le
deserveasca - performanta, fiabilitate, interfata de utilizare -
si raportul performanta/cost, reprezinta tot atitea elemente de
dificultate puse in fata celor care concep astfel de sisteme.
Este necesara o teorie a sistemelor distribuite
de baze de date care sa permita оntelegerea limitarilor
teoretice si a complexitatii, limbajele de specificare trebuie extinse
pentru a permite o tratare cit mai completa a naturii distribuite a
sistemului. De asemenea, este nevoie de o metodologie de conceptie, construire
si оntretinere a DDBS complexe.
Un impact puternic asupra dezvoltarii bazelor
de date distribuite l-a avut aparitia statiilor de lucru (workstation)
puternice si a calculatoarelor paralele.
Intrucit se estimeaza ca un sistem cu
prelucrare distribuita va fi un sistem expert extensibil, adaptabil, fizic
distribuit dar logic integrat, bazele de date distribuite iau locul bazelor de
date centralizate, cu un caracter local. Viitorul promite acestor tipuri de
baze un nivel inalt de aplicabilitate, devenind bazele de date obisnuite,
uzual folosite.
Insa trebuie de tinind cont si de
faptul ca noile directii de cercetare cuprind si aspecte specifice de
inteligenta artificiala. Cu aceasta ocazie bazele de date
relationale distribuite vor fi inlocuite vor avea o forma de baze de
cunostinte distribuite sau baze de date distribuite orientate-obiect.
Bibliografie
[Adiba] M. Adiba, B.G. Lindsay. Databases Snapshots. in
Proc. 6th Int. Conf. on Very Large Data Bases, Montreal, Oct. 1980, pag. 86-91.
[Ceri1] S. Ceri, S.B. Navathe, G. Widerhold.
Distributin Design of Logical Databases Schemes. IEEE Trans. Software Eng., July
1983, pag. 487-503.
[Ceri2] S. Ceri, M.Negri, G. Pelagatti. Horizontal Data
Partitioning in Database Design. Proc ACMSIGMOD Int. Conf. on Management of
Data, Orlando,
June 1982, pag. 128-136.
[Chang] S.K. Chang, W.H. Cheng. A Metodology for
Structured Database Decomposition. IEEE Trans. Software Eng., March
1980, pag. 205-218.
[Ozsu] M.T. Ozsu, P. Valduriez. Principles of
Distributed Systems. Prentice-Hall International, 1991.
[Smith] G. Smith. Symmetric Replication. Asynchronous
Distributed Technology. Oracle Magazine, vol. VIII, nr. 4, 1994.
[Stonebraker] M. Stonebraker. Readings in Database Systems. San Mateo, Calif.:
Morgan Kaufmann, 1988.
Adrese Internet
https://www.wargaming.net/Programming/125/Distributed_Databases_index.htm
https://nash.baruch.cuny.edu/oracle/server803/A54643_01/ch21.htm
https://www.seas.smu.edu/~mhd/dist.html
https://www.eecs.usma.edu/courses/cs393/lessons/lsn35/summary.htm
https://www.interbase.com/products/q89.html
https://www.busn.ucok.edu/bmorey/LectureNotes/Hansn/hansench12/sld001.htm
https://www.sunworld.com/sunworldonline/swol-09-1995/swol-09-unix.html
https://www-star.st-and.ac.uk/starlink/stardocs/sun162.htx/node35.html
https://www.oracle.com/database/features/o8/dtp.html
https://www.eecs.usma.edu/courses/cs393/lessons/lsn35/summary.htm