
Pentru inceput, o scurta definitie: normalizarea unei baze de date este procesul de modificare a schemei unei baze de date astfel incat sa fie eliminate redundantele si situatiile in care apar anomalii legate de operarea cu baza de date (vom vedea in continuare care sunt acestea ).
Inainte de a trece la subiect, sa discutam cateva concepte preliminare:
Ce este o relatie? Ei bine o relatie e definita in mai multe feluri, dar o definitie simpla ar fi ca o relatie e o submultime a unui produs cartezian A1xA2xA3xxAn. De aici rezulta un lucru simplu: daca o tabela reprezinta in mod corect o relatie atunci nu exista tuple(linii) identice, pentru ca o multime contine elemente distincte (intr-un fel sau altul), lucru imposibil de facut in cazul a doua linii identice. (incercati de exemplu sa efectuati un UPDATE sau DELETE doar pe una din mai multe lunii identice dintr-o tabela care evident nu are cheie primara).
O cheie a unei tabele este o combinatie de coloane care identifica in mod unic liniile, adica nu ex. doua linii care sa fie diferite si sa aiba aceleasi valori pe coloanele care constituie cheia. Daca aceasta cheie este ireductibila, adica scotand o coloana din cheie, oricare ar fi aceasta coloana, nu se mai respecta regula de mai sus si noua combinatie de coloane nu mai e cheie, atunci cheia se numeste cheie candidata.
Cheia primara se alege arbitrar dintre cheile candidate, dar este de preferat sa aiba cat mai putine coloane. In caz ca nu se poate, uneori e recomandabil sa se adauge o coloana IDENTITY care sa fie cheia primara a tabelei
De mentionat ca alegerea cheii se face pe baza regulilor abstracte pe care informatiile dintr-o tabela le respecta, si nu pe baza observatiei asupra datelor aflate la un moment dat. Simpla observare a datelor este insuficienta pentru ca deduce toate regulile modelului abstract reprezentat.
Chei "artificiale" si chei "reale": cheile reale sunt cele care rezulta din modelul abtract si sunt constituite din atribute ale entitatilor sau relatiilor reprezentate, cele artificiale sunt folosite pentru o gestionare mai usoara a datelor si sunt adaugate atunci cand se face implementarea modelului.
In general o baza de date denormalizata ridica mai multe probleme legate de consistenta si simplitatea operatiilor efectuate asupra datelor. Sa presupunem ca o tabela contine informatii legate de 2 entitati diferite: elevi si cursuri. Datorita acestui lucru pot apare urmatoarele probleme:
Redundanta: avem aceeasi informatie stocata de mai multe ori -> spatiu ocupat inutil
Anomalii de Insert: daca vrem sa adaugam un curs nou trebuie sa introducem si cel putin un elev
Anomalii de Update: acelasi elev care participa la doua cursuri poate avea informatii diferite pentru acelasi atribut ( de exemplu doua nume diferite - big mistake!!! )
Anomalii de Delete: daca stergem ultimul elev de la un curs stergem si informatiile legate de curs.
Cum putem gandi de fapt normalizarea: fiecare tabela trebuie sa contina informatii despre o singura "tema": entitate sau relatie, din modelul reprezentat. Este evident ca daca ea contine sa spunem informatii despre doua entitati apar anomaliile de IUD. Daca exista informatii despre o entitate si o relatie atunci atributele entitatii pot apare de mai multe ori, in functie de natura relatiei, si de asemenea nu pot stoca date de spre entitate fara a exista o relatie, ceea ce este de multe ori nenatural.
Asadar, daca avem grija sa nu avem intr-o tabela informatii legate de mai mult decat o entitate sau relatie, totul e ok.
Normalizarea unei baze de date se bazeaza pe principiul de compozitiei nedistructive, care spune in principiu ca o tabela care nu respecta formele normale trebuie fragmentata in mai multe tabele normalizate, cu conditia sa nu pierdem informatii (in special relatii intre entitati) si sa putem reconstitui prin join-uri forma initiala a tabelei.
Pentru o inregistrare r dintr-o tabela si o combinatie de coloane X din acea tabela r(X) inseamna valorile de pe coloanele din X din inregistrarea r.
Intr-o tabela o combinatie de coloane Y este dependenta functional de o combinatie de coloane X daca oricare ar fi doua inregistrari din tabela, r1 si r2, daca r1(X) = r2(X) atunci r1(Y) = r2(Y). Se noteaza X->Y. ( adica Y depinde functional de X ).
In acest caz X se numeste determinant.
O proprietate importanta a dependintei functionale este tranzitivitatea. Este usor de constatat ca daca X->Y si Y->Z atunci X->Z. O dependinta X->Z este intranzitiva daca nu exista Y diferit de X sau Z astfel incat X->Y si Y->Z.
In general daca X este un determinant atunci din punct de vedere al molelului ER (entitate-relatie) X reprezinta pentru o entitate o combinatie de atribute care o identifica in mod unic. Exemple are fi: CNP-ul pentru persoane, numarul de inmatriculare pentru masini etc.
De asemenea daca X->Y si Y nu are coloane comune cu X iar dependenta este intranzitiva atunci Y reprezinta o combinatie de atribute a entitatii identificate de X.
De mentionat ca o entitate poate avea mai multe combinatii de atribute care o identifica in mod unic, cum ar fi de exemplu pentru o masina numarul de inmatriculare sau seria sasiului.
O tabela este in prima forma normala daca are o cheie primara(adica nu exista linii duplicate), nu exista grupuri repetitive si toate atributele sunt atomice si consitente(au acelasi tip). Cu alte cuvinte o inregistrare e consistenta "in ea insasi".
Grupuri repetitive: combinatii de coloane care contin exact acelasi gen de informatii si se repeta. De exemplu avem o tabela de genul:
|
NR_FACTURA |
COD_PROD1 |
CANT1 |
COD_PROD2 |
CANT2 |
Atribute nonatomice: atribute care pot fi divizate fara a se pierde semnificatia lor. De exemplu un camp de adresa poate fi impartit in strada, numar, bloc, scara, ap. etc. O observatie importanta este ca atomicitatea unui camp poate tine de natura aplicatiei. Daca de exemplu nu vom avea nevoie niciodata sa obtinem separat numele strazii sau numarul apartamentului, atunci putem considera adresa un atribut atomic, altfel nu. O greseala ar fi sa exageram, fragmentand atributele atunci cand nu este nevoie.
Coloanele sunt consistente daca contin informatii de acelasi gen. Este o greseala de exemplu sa facem o coloana de tip caracter care contine informatii numerice pe care le procesam mai apoi prin conversie, si in cazul in care lipsesc sa trecem acolo "-". De exemplu o colana cu varsta, iar in caz ca nu o stim sa trecem "necunoscuta".
O tabela este in a doua forma normala daca este in prima forma normala si toate atributele nonchei depind de intreaga cheie primara.
Ce inseamna asta? Facand analogia cu modelul ER, asta inseamna de exemplu ca intr-o tabela toate atributele trebuie sa apartina entitatii pe care o identifica cheia primara, adica nu trebuie sa amestecam atributele a doua entitati diferite. Daca anumite atribute depind de o parte a cheii primare atunci ele apartin unei alte entitati identificata de partea respectiva. ( in acest caz atributiul apartine entitatii master , caci intreaga cheie identifica entitatea detail iar partea identifica entitate master, intr-o relatie master-detail ). De exemplu:
|
NR_FACTURA |
COD_CLIENT |
COD_PROD |
CANT |
Cheia primara este NR_FACTURA, COD_PROD si identifica liniile unei facturi, care sunt entitatile detail. NR_FACTURA identifica factura, care este master. Este o greseala sa punem in aceasta tabela COD_CLIENT, pentru ca este un atribut al facturii, nu al liniei din factura. Codul clientului va apare de mai multe ori si chiar putem gresi, punand doua coduri diferite la aceeasi factura.
O tabela este in a treia forma normala daca este in a doua forma normala si toate dependintele atributelor nonchei trebuie sa fie intranzitive, adica toate atributele depind direct de cheia primara.
Ce inseamna acest lucru? Pe scurt. nu trebuie sa punem intr-o tablela "atribute ale atributelor". Evident, din acelasi motiv pe care il mentionam mereu: nu trebuie sa amestecam atributele a doua entitati.
Daca X este cheia primara a unei tabele si X->Y->Z (X,Y si Z fiind distincte) asta inseamna ca Y identifica un atribut al entitatii, atribut care la randul sau este o entitate, iar Z este un atribut al ei.
Exemplu:
|
COD_FIRMA |
NUME |
COD_LOC |
LOCALITATE |
Cheia primara este COD_FIRMA, iar COD_LOC este un atribut al firmei, localitatea in care se afla. Desi numele localitatii depinde de codul firmei, el este un atribut al localitatii, si nu al firmei. Prima problema care apare este ca nu putem adauga o localitate noua in baza de date daca nu adaugam si o firma.
O tabela este in forma normala Boyce-Codd daca este in a treia forma normala si orice determinant este o cheie candidata.
Ce inseamna acest lucru? Dupa cum am mai spus orice determinant identifica o entitate ale carei atribute sunt coloanele determinate. Daca avem intr-o tabela un determinant care nu este cheie candidata asta inseamna ca el identifica o alta entitate decat cea identificata de cheia primara, si prin urmare avem in tabela atribute nonchei a doua entitati diferite. ( A se nota ca e permis sa avem intr-o tabela atribute chei a doua entitati diferite, in acest caz tabela exprimand o relatie )
Notand K cheia primara si X determinantul si daca exista N si Y diferite de celelalte, si K->N, X->Y si Y nu depinde de K si reciproc N nu depinde de X atunci avem in aceeasi tabela atribute a doua entitati diferite (N si Y).
O tabela este in a patra forma normala daca este in forma normala Boyce-Codd si nu contine mai mult de o dependinta multivalori.
Ce este o dependinta multivalori? Sa presupunem ca o entitate are un atribut, dar acel atribut poate apare de mai multe ori. De exemplu culoarea intr-o camera. Intr-o camera exista in cele mai multe cazuri mai mult de o culoare. Aceasta este o dependinta multivalori. In cazul in care o entitate are doua asemenea dependinte, acestea trebuie puse in tabele separate. De exemplu, pentru o factura avizele si ordinele de plata. O factura poate avea asociate mai multe avize si mai multe ordine de plata. In cazul in care avizele si ordinele de plata sunt indepentdente ar fi incorect sa construim o tabela de genul:
|
NR_FACTURA |
NR_AVIZ |
NR_ORDIN |
A cincea forma normala trateaza un caz destul de rar, care se numeste "Join dependencies". Aceasta apare in cazul in care avem trei tipuri de entitati care se relationeaza fiecare cu fiecare dar relatiile sunt sau nu independente. Exemplu:
Avem un vanzator la un dealer de masini. Acesta a facut diverse cursuri de specializare, astel incat este capabil sa prezinte mai multe tipuri de masini (decapotabile, dubite, minivan etc.). De asemenea el cunoaste mai multe firme producatoare de masini, asa incat poate prezenta masini FORD, OPEL, BMW. In mod natural, daca nu exista alte restrictii, daca el stie sa prezinte un tip de masina, stie sa prezinte o anumita firma si firma produce acel tip de masina atunci el poate prezenta acel tip de masina produsa de firma respectiva. De exemplu daca el stie sa prezinte masini FORD, are cunostinte legate de masini decapotabile si FORD produce masini decapotabile atunci el poate prezenta masini decapotabuile FORD. In cazul in care cele trei relatii sunt dependente atunci ele trebuie stocate in trei tabele separate. Daca am face urmatoarea tabela:
|
FIRMA |
TIP_MASINA |
VANZATOR |
|
|
BMW |
COUPE |
DAN |
|
|
BMW |
SUV |
DAN |
|
|
FORD |
MINIVAN |
IOANA |
|
|
FORD |
COUPE |
IOANA |
|
|
FORD |
SUV |
IOANA |
|
|
BMW |
COUPE |
IOANA |
|
|
BMW |
SUV |
IOANA |
si DAN ar face un curs de specializare la FORD, atunci ar trebui sa adaugam in tabela doua noi inregistrari, si nu una:
|
FORD |
COUPE |
DAN |
|
FORD |
SUV |
DAN |
Acest lucru este nenatural ( ar trebui adaugata doar noua informatie: FORD - DAN ) si poate genera erori (un dezvoltator ar putea uita sa bage doua linii ). Daca construim trei tabele cu perechile (FIRMA, TIP_MASINA), (FIRMA, VANZATOR) si (TIP_MASINA,VANZATOR) atunci totul e OK. Insa nu trebuie uitat ca atunci cand se citesc datele din baza de date trebuie JOIN-ate toate cele trei relatii, pentru ca altfel pot apare anomalii de genul:
Ioana stie sa prezinte BMW. Ioana stie sa prezinte minivan-uri. In concluzie Ioana poate prezenta minivan-uri BMW. Incorect, pur si simplu pentru ca BMW nu produce minivan-uri.
Dimpotriva, daca relatiile respective sunt independente (adica (x,y),(y,z) si (x,z) nu implica (x,y,z)) atunci ele pot fi stocate in aceeasi tabela (cazul in care trebuie cate o specializare pentru fiecare model de masina).
Asta este o zicala din folclor, folosita pentru a va putea aminti mai usor primele trei forme normale, care trebuie satisfacute de orice baza de date "decenta". Zicala se interpreteaza asa:
"The KEY" : adica "CHEIA!", adica orice tabela trebuie sa aiba o cheie primara, adica sa fie consistenta (inclusiv fara grupuri repetitive sau atribute neatomice) -> forma normala 1
"the whole KEY": adica toate atributele trebuie sa depinda de intreaga cheie primara -> forma normala 2
"and nothing but the KEY": adica toate atributele nu depind de nimic altceva decat de cheia primara (adica dependinta nu e tranzitiva) -> forma normala 3
Pentru cei care nu stiu Codd este unul dintre cei care a pus bazele teoretice ale bazelor de date relationale, enuntand printre altele si formele normale.
Asa cum am discutat mai inainte, exista o stransa legatura intre entitatile si relatiile dintr-un model ER si baza de date normalizata care il implementeaza. In general, daca modelul ER e realizat corect atunci asociind fiecarei entitati si fiecarei relatii cate o tabela obtinem o baza de date suficient de bine normalizata.
Plecand de la regula simpla ca o tabela trebuie sa contina o singura tema (entitate sau relatie) putem normaliza usor o baza de date, fara a aplica un set rigid si complicat de reguli si pasi de normalizare.
Regula e simpla: daca avem un atribut care depinde de altceva decat de o cheie candidatata atunci inseamna ca apartine unei alte entitati, si trebuie pus intr-o tabela separata impreuna cu determinantul sau, faca ca acesta din urma sa fie scos din tabela initiala (pentru ca altfel se pierde relatia dintre cele doua entitati)
Dupa ce am terminat acest proces simplu trebuie sa ne asiguram ca nu avem doua dependinte multivalori in aceeasi tabela si ca join-dependencies-urile sunt corect reprezentate.
Pentru ca totul sa fie ceva mai clar, sa examinam un exemplu: o baza de date care stocheaza informatii despre catei, dresori si comenzile invatate de catei. Sa presupunem ca secretara firmei pentru care trebuie sa faceti programul va prezinta o tabela Excel facuta asa cum s-a priceput ea, intr-o forma condensata si simplu de utilizat:
![]()
Dupa cum vedeti aceasta forma poate crea dureri de cap oricarui dezvoltator de aplicatii, si este sinucidere curata sa o folosim asa. Nici macar nu este in prima forma normala: observati ca exista grupuri repetitive. Primul pas va fi sa eliminam grupurile repetitive:

Tabela este acum in 1NF. Vom continua procesul, transformand schema astfel incat sa ajungem la forma normala 2. Pentru asta va trebui sa scoatem din aceasta tabela coloanele care depind de o parte din cheia primara, care este SERIE, IDC, ACCESORII.
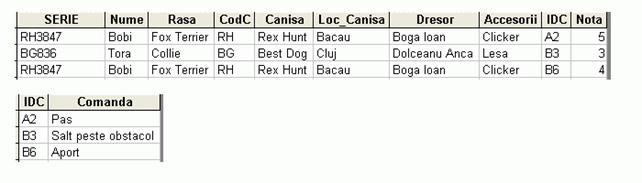
Primul pas a fost sa scoatem in alta tabela coloana COMANDA, care depinde doar de IDC (codul comenzii)

Dupa aceea scoatem coloanele care depind de SERIE
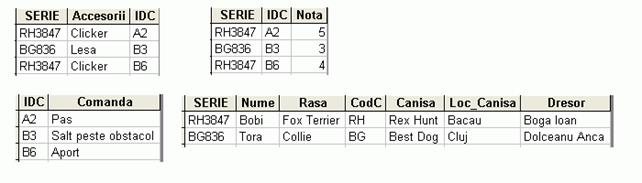
Si in ultimul pas am scos NOTA, care depinde numai de SERIE, IDC. In acest moment schema respecta 2FN. Vom continua procesul de normalizare, mutand in noi tabele coloanele care nu depind direct de cheia primara:
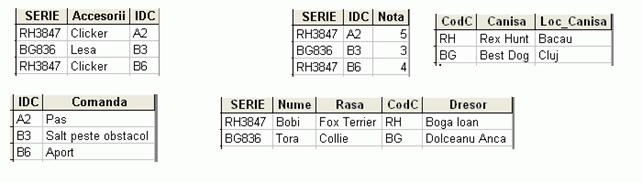
Au fost scoase in afara coloanele CANISA si LOC_CANISA, care depindeau tranzitiv de SERIE prin intermediul coloanei CODC ( codul canisei ). Schema este acum in forma normala 3 si chiar forma normala Boyce-Codd, dar mai exista inca probleme: dependintele multivalori: se poate observa ca un catel poate executa mai multe comenzi si de asemenea este obisnuit cu anumite accesorii. Daca modelul nu face o legatura directa intre acestea ( cum e si cazul in general ) atunci acestea sunt atribute multivalori si trebuie separate:
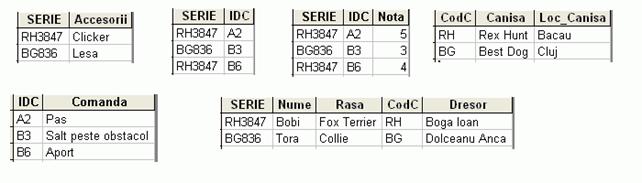
In acest moment avem doua tabele care contin informatii similatre, si le putem unifica, obtinand forma finala, normalizata, a bazei de date:
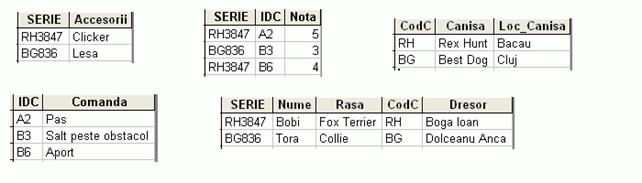
Bineinteles ca exista loc de imbunatatire, pentru ca am putea separa rasele si dresorii, introducand coduri fictive si construind doua tabele noi, dar din punct de vedere al teoriei totul este ok, pentru ca numele acestora identifica entitatile.
Acum cativa ani buni, pe la inceputurile programarii, aparuse conceptul de programare structurata. Acesta spunea pe scurt ca algoritmii ( schemele logice ) trebuie construite astfel incat sa poata fi descompuse in cateva structuri standard: IF-THEN-ELSE, DO-UNTIL, WHILE-DO etc. si se critica aspru instructiunea GOTO, care datea nastere uneori la algoritmi complet ilizibili. Existau multe polemici si unii considerau chiar ca aceasta instructiune ar trebui complet eliminata. Se poate demostra ca orice algoritm poate fi convertit la unul echivalent care sa folosesca doar structuri standard ( adica sa fie structurat ), dar din pacate asta nu e un panaceu: uneori rezulta niste algoritmi mari, frumosi asa la prima vedere, dar foarte greu de inteles. Concluzia e simpla: nu folositi GOTO prea des dar ,cand este cazul, nu ezitati.
Orice lucru in lumea asta are doua fete contradictorii, parti bune si parti rele. Asa sta situatia si cu normalizarea. E buna ea sa reduca redundantele si sa elimine inconsistentele, dar de asemenea reduce performanta. Daca va intoarceti la exemplul dat o sa observati ca pentru a obtine lista in forma sa initiala trebuie sa facem join intre 5 tabele, iar daca datele sunt multe asta nu e chiar asa de comod. In general listele de aceasta forma se folosesc la rapoarte, si acesta este scopul final ar oricarui sistem informatic: sa ne furnizeze informatii pe care sa le putem intelege. Nimeni nu intelege nimic daca se uita la 5 tablele disparate legate prin coduri.
De asemenea exista cazuri in care anumite redundante ajuta foarte mult ca interogarile frecvente asupra bazei de date sa fie executate mai repede. In concluzie, normalizarea trebuie facuta cu atentie, pentru a nu face prea lenta interogarea bazei de date. In acest caz insa redundantele trebuie controlate, pentru a nu genera inconsistente. Pe scurt: daca e nevoie folositi GOTO, dar cu grija! :-).
Normalizarea se foloseste in cazul bazelor de date OLTP, pentru ca elimina redundantele deci implicit codul care ar fi verificat consistenta si favorizeaza executia rapida a operatiior DML ( de modificare a datelor ), care sunt punctul central al acestui tip de aplicatii. Cu toate acestea introducerea de informatii presupune adesea o incarcare prealabila a unor date auxiliare ( nomenclatoare, liste etc. ) sau chiar a datelor introduse initial si care acum trebuie modificate. Acest lucru se observa mai ales in cazul interfetelor moderne, care afiseaza multe informatii.
Asa cum am spus si mai inainte, interogarile schemele normalizate presupun multe join-uri, iar acest lucru poate duce la o alterare a performatelor. In acest caz este de dorit o denormalizare controlata care sa permita ameliorarea timpilor de raspuns ai sistemului.
Exemplul A: - Sumele pe nivele intr-un arbore
Sa presupunem ca avem o aplicatie care gestioneaza fisele de fabricatie a diverse masini industriale. Mai multe piese formeaza un subansamblu, care intra in componenta unei parti a masinii, iar partile formeaza masina. Sa presupunem ca greutatea finala a masinii este suma greutatilor componentelor. Asta poate sa nu fie impresionant, dar ganditi-va ca exista masinarii care sunt formate din mii de piese, cu multi pasi de asamblare ( ceea ce implica multe nivele in arborele care descrie componenta masinii ). Daca aplicatia trebuie sa afiseze alaturi de alte informatii si greutatile diverselor subansamble sau produse finite poate sa fie cam incomod ca se calculeze de fiecare data suma greutatilor.
O imbunatatire ar fi sa stocam pentru fiecare produs, parte sau subansamblu greutatea sa, obtinuta prin sumarea greutatilor componentelor sale de pe nivelul imediat inferior. Daca modul de constructie a unei masini nu se schimba prea des ( asa cu se intampla de obicei ), dar se fac multe interogari legate de greutate atunci costul mentinerii consistentelor este mic in comparatie cu costul recalcularii la fiecare interogare.
Exemplul B: - Preturile valabile pe o anumita perioada
Avem o lista de preturi, cu mai multe preturi pentru un anumit obiect, fiecare pret avand asociata data intrarii in vigoare. Este destul de dificil sa aflam pretul unui obiect la o anumita data. Ar trebui sa facem o interogare de genul:
SELECT P.VALOARE
FROM PRETURI P
WHERE
P.FK_PROD = @PK_PROD
AND P.DATA = (
SELECT MAX(DATA) FROM PRETURI P2
WHERE P2.FK_PROD = @PK_PROD
AND P2.DATA <= @DATA
)
Aceasta operatie poate fi mare consumatoare de timp, mai ales daca sunt implicate multe obiecte. Chiar daca definim indecsi pe coloanele FK_PROD si DATA, performantele vor fi mult mai mici decat daca am avea si coloana DATA_END, care sa contina data expirarii pretului. Acum putem imbunatati si mai mult performantele introducand indecsi pe cele trei coloane. In acest caz fraza SQL ar arata asa :
SELECT P.VALOARE
FROM PRETURI P
WHERE
P.FK_PROD = @PK_PROD
AND @DATA BETWEEN DATA AND DATA_END
Desigur ca acum problema se muta in alta parte: cum sa mentinem corecte datele, astfel incat de exemplu stergerea unui pret sa nu lase un interval de timp neacoperit, astfel incat sistemul sa raporteze in mod incorect ca la o anumita data un produs nu are pret. Multe imbunatatiri de performanta presupun anumite riscuri si scaderea performantelor in cazul altor operatii. Daca preturile s-ar modifica de 10 ori mai des decat s-ar face interogarile dupa pret atunci in mod sigur nu merita sa introducem redundante, pentru ca sistemul va merge mai incet in medie.
Metode de mentinere a consistentei redundantelor:
a) Trigger-e. Aceasta metoda este foarte buna din punct de vedere al mentenabilitatii sistemului daca, si aici e un "daca" destul de mare, trigger-ele sunt corect definite. Acest mecanism poate crea probleme daca cei care il folosesc nu au suficienta experienta. Daca de exemplu cel care scrie trigger-ul se gandeste ca se va adauga/modifica/sterge doar o singura inregistrare odata va scrie algoritmul conform presupunerii sale, si in momentul in care cineva ar face de exemplu un delete in bloc consistenta ar fi distrusa. De asemenea cineva ar putea uita de trigger si nu ar intelege comportamentul sistemului in anumite cazuri. Cu toate aceste inconveniente, daca cel care scrie trigger-ul are suficienta experienta avantajele sunt mari, pentru ca totul se face intr-un singur loc si exact la momentul modificarii, cea ce duce la costuri mici de mentenabilitate si o viteza mare de aspuns in cazul interogarilor.
b) Reguli stricte verificate in procedurile stocate. Aceasta metoda este buna, pentru ca ofera un control mai mare asupra operatiilor efectuate, dar are de asemenea dezavantaje: daca cineva uita sa apeleze procedura de recalculare sau isi costruieste propriul algoritm de actualizare si uita ceva atunci consistenta este ruinata. In plus pot apare probleme de mentenabilitate, pentru ca trebuie sa verificam daca s-au actualizat corect toate secventele care mentin consistenta.
c) Marcare si recalculare periodica sau atunci cand sunt interogari. O alta metoda este sa marcam inregistrarile modificate si periodic sau in momentul primei interogari sa recalculam redundantele. Metoda prezinta avantajul ca nu incetineste operatiile de actulizare a datelor dar, la fel ca mai sus, problema apare in cazul in care cineva uita sa verifice daca exista inregistrari marcate si nu face actualizarea inainte de interogare.
|
Politica de confidentialitate |
| Copyright ©
2024 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |