Ramificatii si predictia ramificatiilor - INTEL
Calculatoarele moderne contin intern cel putin o banda de asamblare. Banda de asamblare are uneori 10 segmente sau chiar mai multe. Tehnica benzii de asamblare lucreaza cel mai bine pe cod liniar, astfel ca unitatea de citire poate extrage pur si simplu cuvinte consecutive din memorie si le poate trimite unitatii de decodificare mai inainte ca ele sa poata fi exexutate. Dar programele nu sunt secvente liniare de cod, ci includ o multime de instructiuni de ramificatie. Sa consideram segmentul de program din figura 4(a). Prima instructiune este o instructiune conditionata de ti if, else. O variabila i este comparata cu 0. O variabila, k, va primi una din doua valori posibile in functie de rezultatul comparatiei.
if(i==0) CMPi,0 ;compara i cu 0
k=1; BNE ;salt la Else daca nu este egal
else Then: MOV j,1 ; incarca 1 in k
k = 2 BR Next ; salt neconditionat la Next
Else MOV k,2 ; incarca 2 in k
Next
(a) (b)
Figura (a) Un fragment de program. (b) Translatarea sa
intr-un limbaj generic de asamblare.
O translatare posibila a acestui program intr-un limbaj de asamblare este data in figura 4(b). In functie de masina si de compilator, este probabil un cod asemanator cu cel din figura 4(b). Prima instructiune compara i cu 0. A doua transfera controlul la eticheta Else (inceputul clauzei else) daca i nu este 0. A treia instructiune atribuie 1 lui k. A patra instructiune transfera controlul codului instructiunii urmatoare. Compilatorul a plasat acolo in mod convenabil o eticheta, Next deci exista un loc unde sa se sara. Cea de-a patra instructiune atribuie 2 lui k.
Se obserba ca din cele cinci instructiuni doua sunt de ramificatie. Mai mult, una din acestea, BNE, este o ramificatie conditionata (saltul se face daca si numai daca o anumita conditie este indeplinita, in acest caz daca cei doi operanzi din CMP precedent sunt egali). Cea mai lunga secventa liniara de cod este aici de doua instructiuni. Deci se pare ca citirea instructiunilor la o rata mare pentru a alimenta banda de asamblare nu este posibila .
La prima vedere se pare ca ramificatiile neconditionate ca instructiunea BR Next din figura 4(b) nu ar constitui o problema pentru ca nu exista dubiu asupra asupra adresei la care are loc saltul.. Apare atunci intrebarea de ce sa nu poata unitatea de citire sa continue sa extraga instructiuni de la adresa tinta, aceasta reprezentand adresa la care va avea loc saltul. Problema consta in natura prelucrarii in banda de asamblare. De exemplu, decodificarea instructiunii are loc in al doilea segment. Astfel unitatea de citire trebuie sa decida unde sa extraga in continuare inainte sa cunoasca ce fel de instructiune tocmai a primit. De abia cu un ciclu mal tarziu poate sa-si dea seama ca tocmai a primit o ramificatie neconditionata, dar incepand deja sa citeasca instructiunea urmatoare ramificatiei neconditionate. Asa se explica faptul ca un numar mare de masini in banda de asamblare (ca UltraSPARC II) au proprietatea ca instructiunea urmatoare unei ramificatii neconditionate este executata chiar daca logic nu ar trebui. Pozitia de dupa o ramificatie este numita pozitie de intarziere (delay slot). Pentium II (si masina utilizata in figura 4(b)) nu au aceasta proprietate, dar complexitatea interna de gestiune a acestei probleme este adesea foarte mare. Un compilator optimizant va incerca sa gaseasca unele instructiuni utile pe care sa le puna in pozitia de intarziere. Uneori nu este nimic disponibil, asa invat compilatorul este fortat sa insereze aici o instructiune NOP. In acest fel pastreaza programul corect, dar il face mai mare si implicit mai lent.
Ramificatiile conditionate pot fi si mai suparatoare decat sunt ramificatiile neconditionate. Nu numai ca au de asemenea pozitii de intarziere, dar unitatea de citire nu are de unde sa citeasca decat mult mai tarziu in banda de asamblare. Masinile mai vechi cu banda de asamblare se blocau (stalled) doar pana ce se cunostea daca ramificatia avea loc sau nu. Blocarea pentru trei sau patru cicluri la fiecare ramificatie conditionata, inrautateste dezastruos performanta in special daca, sa zicem, 20% din instructiuni sau mai mult sunt ramificatii conditionate. De aceea, majoritatea masinilor, cand intalnesc o ramificatie conditionata, incearca sa prezica daca aceasta se va efectua sau nu.
Au fost concepute diverse moduri de predictie. O varianta foarte simpla ar fi urmatoarea: presupunem ca vor fi facute toate ramificatiile conditionate inapoi si ca nu vor fi facute cele inainte. Prima parte a presupunerii se justifica prin faptul ca ramificatii inapoi sunt foarte des intalnite la sfarsitul unui ciclu (unei bucle). Majoritatea ciclurilor se executa de mai multe ori, deci mizand pe o ramificatie inapoi la inceputul ciclului, in general, probabilitatea de succes este mare. A doua parte este mai putin fondata. Se produc anumite ramificatii inainte cand sunt detectate conditii de eroare in software (de exemplu, un fisier nu se poate deschide). Erorile sunt rare, asa ca majonitatea ramificatiilor asociate cu acestea nu sunt executate. Desigur ca exista o multitudine de ramificatii inainte care nu sunt legate de gestiunea erorilor. Rata de succes nu poate fi asa de mare ca la ramificatiile inapoi. Aceasta regula, desi nu are un suport teoretic grozav, este oricum mai buna decat nimic.
Daca predictia unei ramificatii a fost facuta corect, executia continua la adresa tinta. Problemele apar cand predictia unei ramificatii este gresita. Nu este dificil sa se estimeze unde sa se mearga in program si apoi sa se execute instructiunile de acolo. Partea mai dificila este sa se anuleze efectul instructiunilor care deja au intrat in banda de asamblare, au fost executate si nu trebuiau executate.
In principiu exista doua moduri de rezolvare. Prima cale este sa se permita executia instructiunilor citite dupa predictia unei ramificatii conditionate pana cand acestea incearca sa modifice starea masinii (de exemplu sa memoreze intr-un registru). In loc sa fie inscrisa in registru valoarea calculata este pusa intr-un registru temporar secret si copiata in registrul real de abia dupa ce se stie ca predictia a fost corecta. Cea de a doua cale este sa se inregistreze valoarea oricarui registru inainte sa fie suprascris, de exemplu, intr-un registru temporar secret. Dispunand astfel de registrii initiali, masina poate fi adusa inapoi in starea pe care a avut-o inainte de predictia gresita. Ambele solutii sunt complexe si necesita o putere mare de contabilizare pentru a functiona corect. Daca se atinge o a doua ramificatie conditionata inainte sa se cunoasca daca predictia primei a fost corecta, lucrurile se pot incurca si mai mult.
Predictia dinamica a ramificatiilor
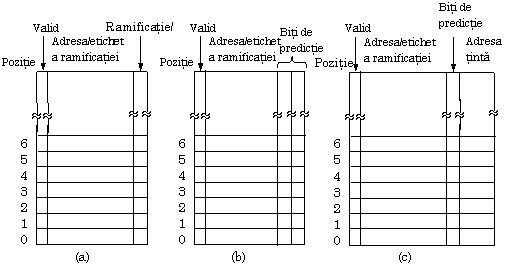
Din cele spuse este esential ca atunci cand se fac predictii acestea sa fie corecte. Acest lucru permite UCP sa lucreze la viteza maxima permisa de banda de asamblare. A existat preocupare si cercetare orientata catree imbunatatirea algoritmilor de predictie a ramificatiilor [4],[6],[11],[13]. O posibila abordare este ca UCP sa mentina o tabela a istoriei intr-un hardware special, in care plaseaza ramificatiile conditionate pe masura ce acestea apar, astfel incat acestea pot fi cautate daca apar din nou. Versiunea cea mai simpla a acestei scheme este aratata in Fig. 5(a). Tabela istoriei contine o intrare pentru fiecare instructiune de ramificatie conditionata. Intrarea contine adresa instructiunii de ramificatie impreuna cu un bit care arata daca a fost efectuata ramificatia ultima data cand a fost executata instructiunea. Utilizand aceasta schema, predictia consta in a spune pur si simplu ca ramificatia va urma aceeasi cale ca ultima data. Daca predictia este gresita, bitul din tabela istoriei este schimbat.
Exista mai multe moduri de organizare a tabelei istoriei. De fapt acestea sunt exact aceleasi moduri ca si cele utilizate pentru organizarea unui memorie intermediara. Considerand o masina cu instructiuni de 32 de biti cu aliniere la cuvant, astfel incat cel mai putin semnificativi doi biti ai fiecarei adrese de memorie sunt 00, deci nu sunt practic utilizati. Daca se utilizeaza o tabela a istoriei cu corespondenta directa continand 2 intrari, cei mai putin semnificativi n+2 biti ai unei instructiuni de ramificatie pot fi extrasi si deplasati dreapta cu 2 biti. Se elimina astfel bitii 00 cei mai putin semnificativi ai adresei. Rezulta un numar de n biti poate fi utilizat ca un index in tabela istoriei verificandu-se daca adresa memorata acolo coincide cu adresa ramificatiei. La fel ca la memoria intermediara, nu este necesar sa se memoreze cei mai putin semnificativi n+2 biti, astfel ca ei pot fi omisi , adica numai bitii superiori de adresa - tag-ul - sunt memorati. Chestiunile legate proiectarea memoriei intermediare se gasesc in subcapitolul 6.6.
Daca apare o coincidenta intre adresa memorata si adresa ramificatiei, bitul de predictie este utilizat pentru predictia ramificatiei. Daca este prezenta eticheta gresita sau intrarea este invalida, se produce ceea ce se numesteo ratare, la fel ca la memoria intermediara. In acest caz, poate fi utilizata regula ramificatiei inainte/inapoi.
|
|
Figua 5. (a) Istorie de 1 bit a ramificatiilor (b). Istorie pe 2 biti a ramificatiilor. (c) corespondenta intre adresa instructiunii de ramificatie si adresa tinta.
Daca presupunem ca tabela istoriei ramificatiilor are 4096 de intrari, ceea ce este un caz realist, atunci ramificatiile de la adresele 0, 16384, 32768, vor fi in conflict, analog cu problema similara de la memoria intermediara (vezi subcapitolul 6.6.). Aceeasi solutie este posibila: o intrare asociativa cu doua cai, patru cai sau n cai. La fel cu la memoria intermediara, cazul limita este o singura intrare asociativa de n cai, care necesita asociativitate completa.
In majoritatea situatiilor aceasta schema lucreaza bine pentru o dimensiune de tabela suficient de mare si suficienta asociativitate. Apare intotdeauna o problema sistematica. Cand o bucla este in sfarsit incheiata predictia ramificatiei de la sfarsit va fi intotdeauna gresita. Si mai rau decat atat, predictia gresita va schimba bitul din tabela istoriei astfel incat sa indice in viitor "non ramificatie". Data ormatoare cand bucla este accesata, predictia ramificatiei de la sfarsitul primei iteratii va fi inevitabil gresita. Daca bucla este interiorul altei bucle sau intr-o procedura apelata frecvent, aceasta eroare poate sa apara foarte des. Daca se doreste eliminarea acestei predictii eronate se poate incerca acordarea unei a doua sanse intrarii respective din tabela istoriei ramificatiilor. Conform acestei metode, predictia este modificata numai dupa doua predictii incorecte consecutive. Aceasta noua metoda necesita insa doi biti de predictie in tabela istoriei, unul pentru ceea ce se presupune ca va face ramificatia si al doilea pentru ceea ce a facut ultima data, asa cum se arata in Fig. 5(b).
Un alt mod de a privi acest algoritm este sa il vedem ca o masina cu stari finite (FSM) cu patru stari, asa cum se arata in Fig. 6. Dupa o serie de predictii corecte "non ramificatie", FSM va fi in starea 00 si va prezice "non ramificatie" data viitoare. Daca aceasta predictie este gresita ea se va muta in starea 10, dar prezicand de asemenea "non ramificatie" data viitoare. Numai daca o predictie este gresita se va muta in starea 11 si va prezice ramificatie de fiecare data. De fapt, bitul din stanga al starii este predictia si bitul din dreapta reprezinta ce a facut ramificatia ultima data. Aceasta solutie utilizeaza numai doi biti de istorie, dar sunt posibile variante care sa pastreze cu patru sau opt biti de istorie. De fapt, toate microprogramele pot fi vazute ca FSM-uri, caci fiecare linie reprezinta o stare specifica in care se poate gasi masina, cu tranzitii bine definite spre un set finit de alte stari. FSM-unile sunt larg utilizate in toate domeniile proiectarii hardware.
|
|
Figura 6. Masina cu stari finite pe 2 biti pentru predictia ramificatiilor.
Pana in acest punct s-a presupus ca tinta fiecarei ramificatii conditionate era cunoscuta, fie ca o adresa explicita de ramificatie (continuta chiar in instructiune), fie ca o deplasare relativa la instructiunea curenta (adica, un numar cu semn de adunat la contorul de program). Adeseori aceasta presupunere este valida , dar anumite instructiuni de ramificatie conditionata calculeaza adresa tinta prin operatii aritmetice asupra registrelor si apoi fac saltul acolo. Chiar daca FSM din figura 6 prezice corect ramificatiile de efectuat, o astfel de predictie nu este utila in cazul in care adresa tinta nu este cunoscuta. O modalitate de a aborda aceasta situatie este sa se memoreze adresa concreta din ramificatia efectuata ultima data in tabela istoriei, asa cum rezulta din Fig. 5(c). Astfel, daca tabela spune ca ultima data ramificatia de la adresa 846 a facut salt la adresa 6000, daca predictia acum este "ramificatie", presupunerea de lucru va fi salt din nou la 6000, ceea ce ar insemna un salt neconditionat sau un salt conditionat in aceleasi conditii.
O alta abordare a predictiei ramificatiilor este pastrarea informatiei referitoare la efectuarea ultimelor k ramificatii conditionate fara sa se tina seama ce instructiuni au fost. Acest numar de k biti, pastrat in registrul de deplasare al istoriei ramificatiilor (branch histoiy shift register), este comparat apoi in paralel cu toate intrarile unei tabele a istoriei cu o cheie de k biti si, daca este gasit, se utilizeaza predictia gasita acolo. Aceasta tehnica, desi nu pare la prima vedere, conduce la o rata de secces destul de mare.
Predictia statica a ramificatiilor
Tehnicile de predictie a ramificatiilor discutate pana acum sunt generate in timpul rularii programului, adica sunt tehnici de predictie dinamice a ramificatiilor. Ele se adapteaza de asemenea la comportarea curenta a programului. Dezavantajul acestor tehnici este ca necesita hardware special si costisitor. In lipsa acestui hardware suplimentar nu pot fi folosite.
Un alt set de tehnici de predictie se bazeaza pe ajutorul compilatorului. Cand compilatorul ajunge la o instructiune ca
for (i=0; i<1000000; i++) ,
el stie foarte bine ca ramificatia de a sfarsitul buclei se va efectua aproape tot timpul. Daca ar exista o cale de a comunica hardware-ului acest lucru, s-ar putea economisi un mare efort. Aceasta implica insa o modificare arhitecturala, nefiind doar o solutie de implementare. Unele masini, ca UltraSPARC II, au un al doilea set de instructiuni de ramificatie conditionata, in plus fata de cele obisnuite care sunt necesare pentru compatibilitate cu sistemele mai vechi. Masinile mai noi contin un bit in care compilatorul poate specifica daca presupune ca ramificatia va fi executata sau nu. Cand apare o ramificatie in program, unitatea de fetch face exact ce i s-a spus de catre compilator. Mai mult, nu e nevoie sa se piarda spatiu pretios in tabela de istorie a ramificatiilor pentru aceste instructiuni, reducand astfel conflictele.
Profiling
Ultima tehnica de predictie a ramificatiilor amintita este bazata pe realizarea profilului (profiling) [6]. Aceasta este de asemenea o tehnica statica. Deosebirea consta in faptul ca nu ii este permis compilatorului sa estimeze care ramificatii vor fi efectuate si care nu. Programul este de fapt executat, de obicei pe un simulator, si se captureaza comportarea ramificatiilor. Aceasta informatie este introdusa in compilator, care utilizeaza apoi instructiunile speciale de ramificatie conditionata pentru a spune hardwre-ului ce sa faca.
|
Politica de confidentialitate |
| Copyright ©
2024 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |