Implementarea directoarelor
Inainte ca un fisier sa poata fi citit, el trebuie deschis. La deschiderea sa, SO utilizeaza numele de cale furnizat de utilizator pentru a localiza intrarea de director (vom utiliza prescurtarea ID) corespunzatoare. Aceasta intrare furnizeaza informatiile necesare pentru a regasi blocurile de pe disc in care s-a memorat fisierul. In functie de SO, aceste informatii se mentin ca: adresa disc de la care incepe memorarea intregului fisier (cazul alocarii contigue), numarul primului bloc in care se memoreaza fisierul (la alocarea inlantuita) sau numarul inod-ului corespunzator fisierului (in familia de SO UNIX si Linux, un i-nod este structura de date - cate una pentru fiecare fisier - care memoreaza atributele fisierului si adresele blocurilor disc in care este memorat acesta).
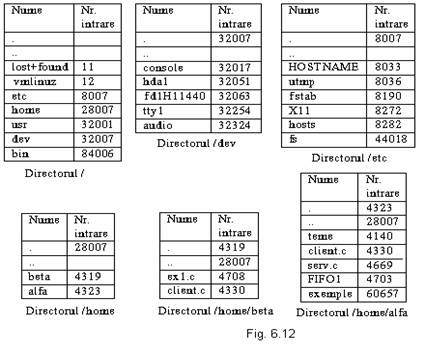
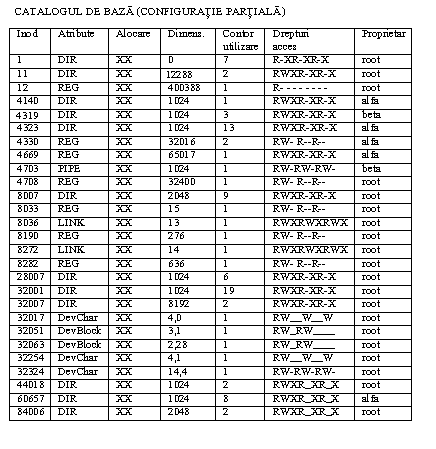 Sistemele
UNIX si LINUX separa directorul (catalogul) de baza de
fisierele director. Aceasta separare are drept scop gasirea mai
rapida a fisierelor, partajarea lor in sisteme multiuser si
evitarea conflictelor de nume de fisier. O intrare intr-un fisier
director este simpla: contine numai numele fisierului si
numarul intrarii sale corespunzatoare din catalogul de baza
(inod-ul). Catalogul de baza si directorul
radacina se gasesc la adrese fixe. Campul contor
utilizare se foloseste pentru contorizarea fisierelor partajate
de utilizatori, iar valorile afisate de campul atribute din fig. 6.12 furnizeaza informatii
asupra tipului fisierului: DIR - fisier director, REG - fisier
obisnuit, PIPE - fisier conducta, LINK - fisier
legatura simbolica, DevChar - fisier special aferent unui dispozitiv periferic orientat pe
caracter, DevBlock - fisier special aferent unui dispozitiv periferic
orientat pe bloc.
Sistemele
UNIX si LINUX separa directorul (catalogul) de baza de
fisierele director. Aceasta separare are drept scop gasirea mai
rapida a fisierelor, partajarea lor in sisteme multiuser si
evitarea conflictelor de nume de fisier. O intrare intr-un fisier
director este simpla: contine numai numele fisierului si
numarul intrarii sale corespunzatoare din catalogul de baza
(inod-ul). Catalogul de baza si directorul
radacina se gasesc la adrese fixe. Campul contor
utilizare se foloseste pentru contorizarea fisierelor partajate
de utilizatori, iar valorile afisate de campul atribute din fig. 6.12 furnizeaza informatii
asupra tipului fisierului: DIR - fisier director, REG - fisier
obisnuit, PIPE - fisier conducta, LINK - fisier
legatura simbolica, DevChar - fisier special aferent unui dispozitiv periferic orientat pe
caracter, DevBlock - fisier special aferent unui dispozitiv periferic
orientat pe bloc.
In fig. 6.12 este redata legatura dintre catalogul de baza si fisierele director pentru UNIX. In acest exemplu, pentru a cauta fisierul /home/alfa/serv.c:
- se citeste fisierul director corespunzator directorului radacina pentru a gasi inodul corespunzator fisierului director /home, gasindu-se valoarea 28007 ;
- se citesc blocurile alocate fisierului director /home pana la gasirea intrarii /alfa si se determina inodul corespunzator fisierului /home/alfa (acesta este 4323);
- se citesc blocurile fisierului director /home/alfa pana la gasirea intrarii serv.c si se determina inodul corespunzator (4669) . Se citeste acest i-nod in MI, unde ramane (in tabela fisierelor deschise) pana la inchiderea fisierului.
In toate cazurile, functia principala a sistemului de directoare este aceea de a mapa numele ASCII al fisierului in informatiile necesare pentru a-i localiza datele.
O alta problema care apare in acest context se refera la modalitatea in care se memoreaza atributele fisierului. O posibilitate este memorarea acestora direct in ID, si multe SO procedeaza astfel. O solutie simpla pentru acest tip de implementare este urmatoarea: un director consta dintr-o lista de ID de lungime fixa, cate una pentru fiecare fisier. O astfel de ID contine numele fisierului (de lungime fixa), o structura care memoreaza atributele fisierului si respectiv una sau mai multe adrese disc (se impune un numar maxim de adrese) care localizeaza blocurile in care se memoreaza fisierul. Aceasta solutie este utilizata de MS-DOS/Windows.
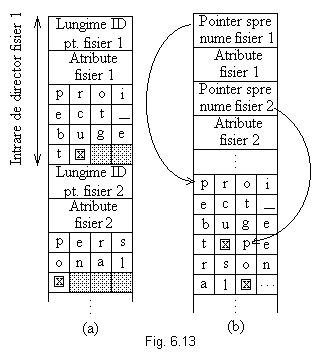 La
sistemele care utilizeaza inod-uri, atributele pot fi memorate in inoduri
si nu in ID. In acest caz, ID poate fi mai scurta , fiind
formata numai dintr-un nume de fisier si un numar de inod.
La
sistemele care utilizeaza inod-uri, atributele pot fi memorate in inoduri
si nu in ID. In acest caz, ID poate fi mai scurta , fiind
formata numai dintr-un nume de fisier si un numar de inod.
In cele de mai sus s-a presupus ca fisierele au nume scurte, de lungime fixa. SO moderne permit insa utilizarea de nume lungi, de dimensiune variabila. O solutie simpla ar fi limitarea lungimii numelui fisierelor la 255 de caractere, dar solutia este neconvenabila deoarece s-ar irosi inutil mult din spatiul afectat memorarii directoarelor, pentru ca doar cateva fisiere au nume lungi.
In consecinta, se utilizeaza alta solutie, in care nu se mai impune ca ID sa aiba lungime fixa. In aceasta implementare, fiecare ID contine o portiune fixa (fixed-length header). Aceasta portiune memoreaza uzual la inceput lungimea ID-ului, apoi datele cu format fix, cum sunt: proprietarul fisierului, momentul la care a fost creat fisierul, informatii de protectie si alte atribute. In continuarea portiunii fixe se memoreaza numele fisierului (oricat de lung), asa cum se exemplifica in fig. 6.13 (a) (formatul big-endian, utilizat de sistemul SPARC). Terminarea fiecarui nume de fisier este semnalata printr-un caracter special (in mod obisnuit 0), reprezentat in fig. printr-o casuta cu X. Pentru ca fiecare ID sa inceapa de la o adresa multiplu de dimensiunea unui cuvant, fiecare nume de fisier este completat pana se ajunge la numarul de octeti aferenti unui cuvant (zonele hasurate). Metoda prezinta dezavantajul ca, atunci cand se sterge un fisier, este introdus un spatiu nefolosit de dimensiune variabila in director, spatiu care s-ar putea sa fie insuficient pentru ID-ului aferent urmatorului fisier care se va memora in acelasi director (apare deci fragmentarea externa). Aceasta problema se intalneste si la alocarea contigua a spatiului disc, cu deosebirea ca in cazul directoarelor compactarea este posibila, directorul fiind memorat integral in MI. O alta problema este urmatoarea: o ID poate fi memorata de mai multe pagini, a.i. se poate genera o deviere de paginare atunci cand se citeste un nume de fisier.
O alta posibilitate de implementare a directoarelor care contin fisiere cu nume variabile este cea in care ID-urile insele au lungimi fixe, iar numele de fisiere sunt memorate intr-o zona heap la sfarsitul directorului, ca in fig. 6.13 (b). Avantajul acestei metode consta in faptul ca, atunci cand se elimina un ID, ID-ul urmatorului fisier care se va memora in directorul respectiv va incape exact in spatiul eliberat. Apar operatii suplimentare aferente gestionarii heap-ului si nu se elimina posibilitatea aparitiei devierilor de paginare. In aceasta implementare nu se mai impune ca numele de fisiere sa inceapa la adrese multiplu de dimensiunea unui cuvant, a.i. nu mai sunt necesare 'caractere de umplutura', ca in fig. 6.13 (a).
In toate implementarile prezentate pana acum, atunci cand se cauta ID-ul aferent unui anumit fisier, trebuie executata o cautare liniara in director, incepand mereu de la inceputul zonei disc de unde incepe memorarea directorului, liniar catre sfarsitul acestei zone. Pentru directoare f. mari, cautarea liniara este lenta. Pentru a mari viteza regasirii informatiei, se poate utiliza o tabela hash in fiecare director. Utilizarea unei astfel de tabele imbunatateste viteza de regasire dar creste complexitatea administrarii directoarelor. Utilizarea sa se justifica doar la sisteme unde directoarele memoreaza in mod obisnuit sute sau mii de fisiere.
O modalitate total diferita de marire a vitezei regasirii informatiei este memorarea (cache) rezultatelor cautarilor. Inainte de a demara o cautare, se verifica intai daca numele de fisier nu se afla deja in cache si in caz afirmativ se ia de acolo, evitand operatiile de cautare in director. Evident cacheing-ul este avantajos daca se lucreaza frecvent aceleasi fisiere si acestea sunt in numar mic.
Incepand cu
Windows 95, Microsoft a introdus sistemul de fisiere VFAT, care
suporta nume de fisiere de pana la 255 de caractere, dar si
nume scurte, compatibile MS-DOS. Fiecarui director sau fisier i se
rezerva o intrare de director memorata pe 32 de octeti. 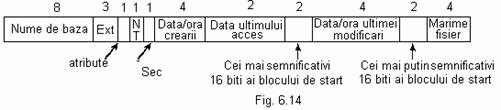 Pentru
compatibilitate cu vechiul sistem, utilizat de MS-DOS (8.3, adica maxim 8
caractere pentru nume si 3 pentru extensie), in Windows 98 se
utilizeaza o structura pentru intrari de director MS-DOS extinse ca cea din fig. 6.14.
Pentru
compatibilitate cu vechiul sistem, utilizat de MS-DOS (8.3, adica maxim 8
caractere pentru nume si 3 pentru extensie), in Windows 98 se
utilizeaza o structura pentru intrari de director MS-DOS extinse ca cea din fig. 6.14.
Campul NT realizeaza o compatibilitate cu NT, in sensul ca se afiseaza numele de fisiere respectand majuscule/minuscule (in MS-DOS se folosesc doar majuscule). Sec(Seconds) rezolva problema aferenta imposibilitatii memorarii momentului de timp curent intr-un camp de 16 biti. Sec furnizeaza biti suplimentari a.i. campul Data/ora crearii retine informatii cu precizia de 10 msec.
Cum se reprezinta numele lungi pentru a se oferi compatibilitate cu formatul 8.3? Fiecarui fisier i se atribuie doua nume: un nume lung , in Unicode, pentru compatibilitate cu Windows NT, si unul in format 8.3. Fisierele pot fi accesate utilizand oricare dintre cele doua nume. Atunci cand se creeaza un fisier al carui nume nu respecta formatul 8.3, Windows-ul inventeaza un nume care respecta acest format. Ideea de baza utilizata la generarea unui astfel de nume este: se iau primele 6 caractere din nume, se convertesc la majuscule si se adauga ~1 pentru a forma numele de baza. Daca numele astfel format exista deja, se foloseste sufixul ~2, s.am.d.
Ex: numele de fisier 'Ala Bala Portocala' devine 'ALABAL~1'.
 Pentru
fiecare fisier exista o intrare de director in formatul din fig.
6.14. Daca fisierul are si un nume lung, acesta este memorat in
una sau mai multe intrari de director plasate imediat inaintea celei
aferente numelui MS-DOS. Un nume lung de fisier necesita o
succesiune de intrari director
memorate pe cate 32 de octeti, prima intrare fiind reprodusa in fig.
6.15. Vom nota o astfel de intrare director prin IDL. Ïntr-o IDL se pot
retine maxim 13 caractere Unicode (numarul total de octeti
pentru campurile Nume este: 10+12+4=26, iar un caracter Unicode se
memoreaza pe cate 2 octeti). IDL-urile
sunt memorate in ordine inversa, cea aferenta inceputului numelui
fisierului fiind plasata chiar inaintea intrarii de director
aferente numelui MS-DOS, IDL-urile urmatoare fiind plasate inaintea sa.
Formatul corespunzator fiecarei IDL este reprezentat in fig. 6.15.
Pentru
fiecare fisier exista o intrare de director in formatul din fig.
6.14. Daca fisierul are si un nume lung, acesta este memorat in
una sau mai multe intrari de director plasate imediat inaintea celei
aferente numelui MS-DOS. Un nume lung de fisier necesita o
succesiune de intrari director
memorate pe cate 32 de octeti, prima intrare fiind reprodusa in fig.
6.15. Vom nota o astfel de intrare director prin IDL. Ïntr-o IDL se pot
retine maxim 13 caractere Unicode (numarul total de octeti
pentru campurile Nume este: 10+12+4=26, iar un caracter Unicode se
memoreaza pe cate 2 octeti). IDL-urile
sunt memorate in ordine inversa, cea aferenta inceputului numelui
fisierului fiind plasata chiar inaintea intrarii de director
aferente numelui MS-DOS, IDL-urile urmatoare fiind plasate inaintea sa.
Formatul corespunzator fiecarei IDL este reprezentat in fig. 6.15.
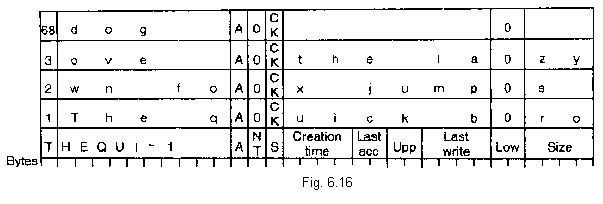
Distinctia intre o intrare de director compatibila MS-DOS si una de tip IDL se face prin intermediul campului Attribute. Pentru IDL-uri, acesta are o valoare imposibila: 0 X 0F. IDL-urile consecutive aferente aceluiasi fisier au numere de secventa consecutive (campul secventa). Ultimul IDL corespunzator unui fisier este marcat intr-un mod particular: se adauga 64 la numarul de secventa. Ïn fig. 6.16 este reprodus un exemplu succesiune de IDL-uri folosite pentru memorarea informatiilor despre fisierul cu numele 'The quick brown fox jumps over the lazy dog'.
|
Politica de confidentialitate |
| Copyright ©
2024 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |
