Exemple de DBMS-uri relationale
1. System R.
System R a inceput sa fie proiectat pe la mijlocul anilor 70' la IBM San Jose Res.Lab si formeaza baza pentru doua produse ale lui IBM, DBMS-urile SQL/DB si DB2. SQL/DB a devenit disponibil in 1982. Se executa pe DOS/VSE pe o varietate de calculatoare IBM de capacitate medie, inclusiv s/370, 3031, 3033, 4311, 4341. Exista utilitare pentru transferul unei baze de date DL/1 (ierarhica) intr-o baza de date SQL, dar ele cer o mica analiza a datelor si, mai ales, reformatarea lor.
DB/2 a devenit disponibil la sfarsitul lui 1984. Se executa pe MVS pe calculatoare IBM medii si mari. Exista utilitare care extrag o structura IMS (ierarhica) intr-una DB2.
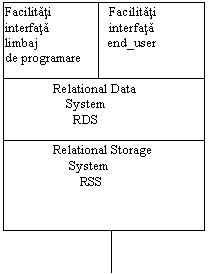
Arhitectura. Arhitectura fundamentala a lui System R este prezentata in fig.11.10. Si include:
Interfete de date relationale (RDI) intre utilizator si RDS.
Sistem de date relationale RDS.
Interfata de memorare relationala (RSI) intre RDS si RSS.
Sistem de memorare relationala (RSS).
RDI poate fi apelata direct dintr-un limbaj de programare (PL/I, COBOL, FORTRAN, asamblor) sau din alta interfata utilizator (SQL, QBE). Programatorul sau utilizatorul foloseste facilitatile limbajului RDI. Utilizatorul interactioneaza cu portiuni (i.e. vederi) ale bazei de date relationale, care sunt de interes pentru aplicatia lui si consistente cu autorizarile de acces. RDS suporta RDI si realizeaza maparea intre relatiile de baza si vederile utilizator. El ofera si verificarea si fortarea autorizarii precum si a restrictiilor de integritate. RSI este o interfata interna care ofera acces la linii unice din relatiile de baza. El trimite cate o linie la un moment dat intre Rss si RDS. RSS gestioneaza aparatele de memorare, alocarea spatiului, consistenta si incuierea tranzactiilor, detectarea de deadlock, etc. El mentine indecsii atat pentru caile de acces rapid pe baza de atribute selectate, cat si pe reuniuni preconstruite.
|
RDI RSI |
||||||||||||||||||||||||||||||||||||||||
Fig.11.10. Arhitectura de baza a lui System R.
Structura de fisiere. System R foloseste abordarea cu N relatii, un fisier. Fiecare relatie de baza este memorata intr-un fisier si mai multe relatii de baza pot fi grupate in acelasi fisier. Un singur buffer poate, astfel, contine linii din mai multe tabele. Daca aceasta grupare fizica se potriveste cu nevoile utilizatorilor, atunci performanta poate fi mai buna decat in cazul in care tabelele se gasesc in fisiere separate. System R face distinctie intre fisierele care pot fi partajate si cele care sunt fisiere cu o regie mai mica, pentru relatii temporare. La fisierele temporare nu este permis accesul parajat si nici nu pot fi refacute.
Structura paginii. Fiecare tuplu este memorat ca o secventa contigua de valori de camp, intr-o singura pagina. Exista doua tipuri de campuri, campuri pentru date memorate si campuri interne (prefix). Campurile pentru date memorate contin date utilizator si pot fi de lungime fixa sau variabila. depinzand de definirea lor. Campurile interne se folosesc pentru gestionarea memoriei si accesul la linii, si includ identificatorul relatiei, campuri pointer inlantuind aceasta linie cu alte linii precum si informatii interne aditionale.
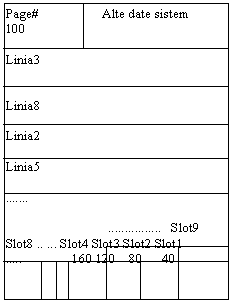
Exista doua tipuri de pagini: pagini de date si pagini rezervate. Paginile de date sunt folosite pentru a memora liniile relatiilor de baza, iar cele rezervate sunt folosite pentru a memora intrari director intern si intrari index. O pagina de date are trei sectiuni: antet, corp si pointer-slot (fig.11.11.). Sectiunea antet contine numarul paginii si alte date sistem; sectiunea corp contine valorile campurilor liniei, iar sectiunea pointer-slot contine pointeri la sectiunea corp. Exista cat un pointer-slot per linie memorata in pagina si valoarea lui este deplasamentul locatiei liniei de la inceputul paginii.
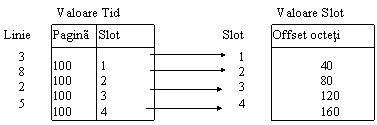
Identificatorul tuplului. La fiecare linie memorata este asociat un identificator de tuplu TID. Acesti identificatori sunt folositi de catre RSS ca un mijloc de a adresa liniile, si nu sunt folositi de aplicatii sau utilizatori. TID-ul unei linii este numarul paginii in care este memorata linia si numarul pointer-slot-ului. Astfel, valorile TID si de pointer-slot pointeaza impreuna la locatia liniei. TID pointeaza la pointer-slot, iar acesta indica inceputul liniei. (fig.11.12.).
TID sunt folositi de catre RSS pentru a referi liniile din structurile de indecsi si din lanturile de pointeri. Sistemul de pointer-slot ii permite lui RSS sa-si reorganizeze spatiul pe pagini dupa cum este nevoie, fara a afecta valorile TID. Cu toate ca valorile lor se pot schimba, slot-urile insasi nu sunt mutate din pozitiile lor. Daca o linie se modifica si devine prea mare pentru a incapea in spatiul disponibil din pagina sa, atunci valoarea TID va pointa spre o inregistrare speciala etichetata, care la randul ei pointeaza la locatia de depasire. Accesul la o linie prin valoarea TID implica intotdeuna accesul la o singura pagina de date si eventual o pagina de depasire.
Cai de acces rapid preconstruite. System R suporta doua tipuri de cai de acces rapid preconstruite: imagini, care suporta accesul prin valori de atribut si inlantuiri binare, care suporta reuniuni preconstruite.
O imagine ofera acces direct si secvential pentru unul sau mai multe atribute si este implementata printr-o structura index multipagina similara cu un B+-arbore. Fiecare intrare in arbore este o pereche:
<valoare atribut, pointer>
si pointerul este orientat spre pagina index continand valorile atributului mai mici sau egale cu cea data. Fiecare frunza este o pereche:
<valoare atribut, TID>
pointand spre linia potrivita a relatiei de baza. Frunzele arborelui index sunt legate intr-o lista dublu inlantuita, astfel ca arborele index suporta atat accesul secvential cat si direct la linii dupa valorile atributului.
|
Antet de pagina Corp pagina Pointeri slot |
|||||||||||||||||||||||
Fig.11.11. Formatul paginii de date in System R.
|
|
Fig.11.12. Valori TID si valori pointer-slot.
O inlantuire binara ofera o cale de acces la liniile unei relatii si liniile legate ale altei relatii.
Sa consideram urmatoarele doua relatii:
DEPT (COD_DEPT, LOC_DEPT, TIP_DEPT).
ANGAJAT(MARCA#, SSN#, COD_DEPT, COD_JOB, NUME_ANGAJAT)
O aplicatie a inlantuirii liniare este de a prestructura reuniunile. De exemplu, o inlantuire binara poate lega fiecare linie din relatia DEPT de multimea de linii din relatia ANGAJAT care au aceasi valoare COD_DEPT. Fiecare linie DEPT are un pointer la una din liniile ANGAJAT potrivite si fiecare linie ANGAJAT are un pointer la o alta linie ANGAJAT cu acelasi COD_DEPT ca si ea. O alta aplicatie a unei inlantuiri binare este ordonarea liniilor dintr-o relatie. De exemplu, o inlantuire binara poate lega fiecare linie din relatia DEPT de linia cu urmatoarea valoare de COD_DEPT in ordinea marimii. Aceste inlantuiri binare se numesc inlantuiri unare deoarece ele inlantuie liniile intr-o relatie si nu intre doua relatii.
2. Ingres.
Proiectul
INGRES (Interactive Graphics and Retrieval System) de la
Structura director. Baza de date relationala este descrisa intr-un catalog sistem care este el insusi o multime de relatii. Exista doua relatii sistem RELATION si ATTRIBUTE pe care le descriem mai pe larg. Relatia RELATION are cate o linie pentru fiecare relatie de baza si sistem din baza de date. Atributele relatiei RELATION includ:
RELID - numele relatiei.
OWNER - identificatorul utilizator al proprietarului relatiei.
SPEC - cod indicand tipul de memorare folosit de relatie.
INDEXD - flag indicand ca exista un index la relatie.
PROTECT - flag indicand setarea protectiei pentru relatie.
INTEG - flag indicand fortarea restrictiilor de integritate pentru relatie.
SAVE - timpul de viata planificat pentru relatie.
TUPLES - numar de linii ale relatiei.
ATTS - numar de atribute ale relatiei.
WIDTH - numar de octeti in linie.
PRIM - numar de pagini in fisierul primar al relatiei.
Relatia ATTRIBUTE descrie coloanele fiecarei relatii de baza si sistem. Exista cate o linie in relatia ATTRIBUTE pentru fiecare atribut din fiecare relatie din baza de date. Atributele relatiei ATTRIBUTE includ.
RELID - numele relatiei.
OWNER - identificatorul utilizator al proprietarului relatiei.
ATT_NAME - numele atributului.
ATT_NO - pozitia ordinala a atibutului in relatie.
OFFSET - numarul de octeti de la inceputul liniei pana la atribut.
TYPE - tipul de data al atributului (antreg, flotant, caracter, etc.)
LENGTH - numarul de octeti alocati atributului.
KEYNO - daca atributul e parte dintr-o cheie, atunci numarul lui in cheie.
Alte relatii din catalogul sistem sunt:
INDEX - avand cate o linie pentru fiecare structura index din baza de date.
PROTECTION - descrie restrictiile de protectie a securitatii.
INTEGRITY - descrie restrictiile de integritate a datelor.
VIEW - descrie relatiile de vederi utilizator (schema externa).
Deoarece directorul este structurat ca un grup de relatii, INGRES poate opera pe directorul sau cu aceleasi facilitati pe care le foloseste pentru datele utilizator.
Structura de fisiere. INGRES foloseste abordarea o relatie de baza - un fisier. Aceasta permite ca structura fiecarui fisier sa fie croita dupa caracteristicile unei relatii specifice. Schema de memorare folosita pentru un fisier poate fi selectata pentru a corespunde tipului de activitate asteptata de la acea relatie de baza.
INGRES suporta o varietate de scheme de memorare fisier: fara chei, hash, hash comprimat, ISAM si ISAM comprimat.
|
deplasament in octeti al liniei in pagina |
Fig.11.13. Formatul paginii de date pentru INGRES.
Ordinea liniilor intr-un fisier fara chei este aceasi cu ordinea lor de intrare in fisier. Fiecare linie noua este adaugata dupa ultima linie din fisier si fiecare linie are un identificator unic (TID), care reprezinta deplasamentul sau, in octeti, in fisier. Un fisier fara chei cere o regie mica si este potrivit pentru relatiile foarte mici. Sa notam ca locatia de memorare a unei linii este independenta de oricare din valorile atributelor sale, Aceasta schema de memorare este folosita de catre INGRES, de asemenea, pentru import si export.
|
|
||||||||||||
|
|
Fig.11.14. Doua fisiere baza de date, unul memorat ca arbore binar de cautare si celalalt ca tablou.
Structurile de memorare cu chei folosesc valoarea cheii primare a unei linii pentru a-i determina pozitia de memorare. Si aici fiecare linie are un TID, care este numarul paginii si numarul liniei. O linie in INGRES este echivalenta cu un slot in System R. Sistemele folosesc in mod esential aceasi structura de pagina (vezi fig.11.11. Si 11.13.). O diferenta este aceea ca INGRES are numai o relatie pe pagina, pe cand System R are mai multe relatii pe o pagina. Alta diferenta este modul de alocare a paginilor de depasire.
In schema de memorare hash, valoarea cheii primare este folosita pentru a calcula numarul paginii in care se memoreaza linia (vezi cap.10.). Schema hash comprimat este la fel ca schema hash, cu exceptia faptului ca se folosesc tehnici de comprimare a memoriei. Ele sunt utile pentru relatiile mari de date text. Schema de memorare ISAM suporta accesul secvential cat si direct bazat pe valori de cheie primara a relatiei (vezi cap.10.). Schema de memorare ISAM comprimat adauga tehnici de comprimare a memoriei la schema ISAM.
Toate cele patru scheme de memorare cu chei, care ofera cai de acces rapid preconstruite prin chei primare, suporta, de asemenea si cai de acces rapid preconstruite prin alte atribute. Aceste cai de acces sunt implementate prin structuri de indecsi si sunt descrise de catre relatia sistem INDEX.
3. RDMS.
Abordarea RDMS (Relational Data Management System) a fost dezvoltata la mijlocul anilor 70 la MIT. RDMS a constituit baza pentru MULTICS de la Honeywell Information Systems, Inc.
Structura de fisier. O baza de date fizica RDMS este compusa din doua tipuri de fisiere: relatii si clase de date. O clasa de date este un domeniu. Asa cum am prezentat in cap. 4. multe atribute pot sa-si ia valorile dintr-un singur domeniu si un domeniu determina o multime de valori permisibile.
Deorece fiecare clasa de date este memorata in propriul sau fisier, structura de memorare a acelui fisier poate fi croita dupa caracteristicile clasei de date. Doua exemple de tipuri de structura de memorare sunt tabloul si arborele binar de cautare. Tablourile sunt potrivite pentru memorarea multimilor relativ mici de valori a caror secventa este neesentiala. Fiecare valoare noua se adauga la sfarsitul tabloului. Arborii de cautare binara (vezi cap. 10.) sunt potriviti pentru memorarea valorilor alfanumerice care trebuie accesate atat direct cat si secvential.
Fiecare clasa de date are un model de strategie de date (DSM) asociat care guverneaza procesul de accesare si gestionare a structurii de memorare pentru fisierul clasei de date. De exemplu, patru din modulele de strategie de date sunt:
dsm_astring, pentru gestionarea arborilor binari.
dsm_table, pentru gestionarea tablourilor.
dsm_integer, pentru gestionarea memorarii intregilor.
dsm_ciph_integer, pentru gestionarea memorarii criptice a intregilor.
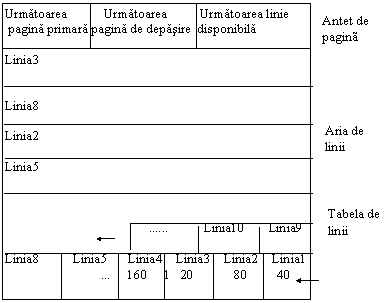
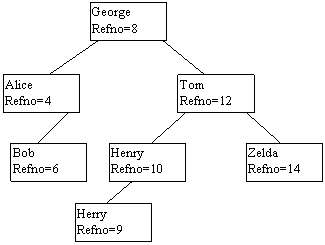
Fig.11.14. ilustreaza doua fisiere clasa de date. Fisierul clasa de date NUMEDEPT este memorat ca un tablou si este gestionat de catre modulul de strategie dsm_table. Fisierul clasa de date NUME_ANGAJAT este memorat ca si un arbore binar de cautare si este gestionat de catre modulul de strategie de date dsm_astring. Sa notam ca fiecarei intrari in fiecare fisier clasa de date ii este asignat un numar de referinta (REFNO), care poate fi folosit oriunde pentru a pointa la intrare.
Fiecare relatie este memorata in propriul sau fisier si este structurata ca o tabela de valori REFNO. Fiecare linie a unei tabele are cate un REFNO pentru fiecare atribut din relatie. REFNO sunt atat pointeri spre fisierele clasa de date potrivite cat si valori intregi pentru un atribut.
Relatie:Angajat

Fig.11.15. Fisier relatie: intrarile sunt REFNO pointand la fisiere clase de date.
Fig.11.15. prezinta un fisier relatie. Relatia are patru atribute: NUME_ANGAJAT, NUME_DEPT_CURENT, NUME_ULTIM_DEPT si PROCENT_ASIGNAT. REFNO-urile din coloana NUME_ANGAJAT sunt pointeri spre fisierul clasa de date NUME_ANGAJAT; REFNO_urile din coloanele NUME_DEPT_CURENT si NUME_ULTIM_DEPT sunt pointeri spre fisierul clasa de date NUME_DEPT. REFNO-urile din coloana PROCENT_ASIGNAT sunt valori actuale.
Cateva din avantajele acestei abordari de implementare sunt urmatoarele:
compactitate: fiecare valoare domeniu (i.e. clasa de date) este memorata numai o data si nu de fiecare data cand este folosita ca valoare de atribut.
uniformitate si simplitate: gestionarea datelor unei relatii inseamna manuirea REFNO-urilor, care sunt valori intregi.
eficienta: operatiile relationale pot fi prelucrate eficient deoarece structurile fisierelor claselor de date sunt proiectate pe masura.
|
|
Fig.11.16. Relatii interfisiere.
Principalul dezavantaj al acestei abordari este ca ea cere un volum mare de manipulare de fisiere pentru a opera pe relatii si pentru a afisa valori de atribute. Implementarea acestei versiuni pe un sistem de operare cu un SGF ineficient poate duce la un sistem foarte lent, in ciuda proiectarii structurilor de clase de date.
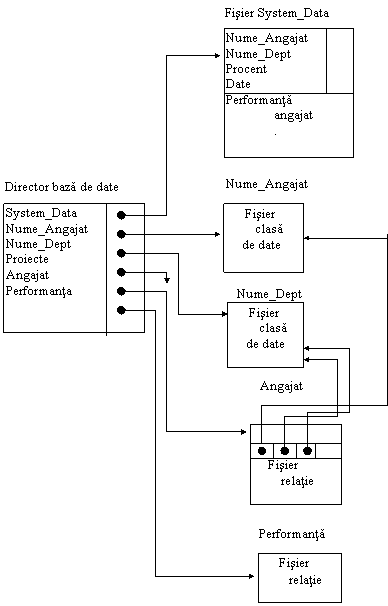
Structura director. Directorul pentru o baza de date RDMS este o tabela cu trei tipuri de intrari (fig.11.16.): pointeri la fisierul de date sistem, pointeri la fisierele clase de date si pointeri la fisierele relatii.
Fisierul de date sistem include numele tuturor relatiilor si tuturor claselor de date precum si modulele de strategie de date asociate lor. Fisierele clasa de date si relatie sunt structurate asa cum se indica in figuri.
4. Masini baza de date.
O alternativa pentru a implementa o baza de date relationala este de a folosi o masina baza de date, care este un calculator cu hardware specializat pentru functiile DBMS-ului. Obiectivul unei masini baza de date este de a oferi functiile DBMS-ului fara a mari resursele unui calculator de scop general si de a inbunatati performanta sistemului baza de date in proces. Inbunatatirea poate fi o combinatie intre timp de acces mai rapid, cost hardware mai mic, intretinere usoara a herdware-ului si software-ului, functionalitate crescuta, etc.
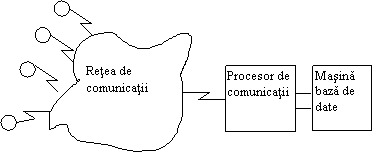
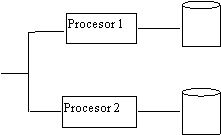
Exista multe modalitati de a configura un sistem de masini de baze de date si calculatoare cu scop general. O configuratie simpla este prezentata in fig.11.17.: o singura gazda de tip general si o singura masina baza de date. Obiectivul acestei configuratii este de a descarca prelucrarea bazei de date din gazda, un obiectiv care este aproape acelasi cu cel a unui procesor de comunicatii frontend (fig.11.18.) care descarca prelucrarea comunicatiilor de date.
Un procesor de comunicatii poate fi responsabil pentru oricare din urmatoarele sarcini legate de comunicatii:
controlul fluxului traficului de mesaje inauntru si in afara gazdei.
potrivirea diferitelor viteze de transmisie.
potrivirea diferitelor scheme de codare a mesajelor.
detectarea si controlarea erorilor mesajelor.
sondarea terminalelor pentru traficul de mesaje.
rutarea mesajelor in afara gazdei.
Dand aceste responsabilitati unui procesor de comunicatii se elibereaza resursele gazdei pentru prelucrari. Similar, o masina baza de date poate fi responsabila pentru oricare din urmatoarele sarcini legate de baze de date:
analiza si interpretarea cererilor utilizatorilor pentru regasirea sau actualizarea datelor.
selectarea cailor de acces la date.
gestionarea memorarii fizice.
accesarea datelor.
pregatirea rezultatelor pentru livrare catre utilizatori.
oferirea refacerii datelor si a protectiei de securitate.
fortarea restrictiilor de integritate de date.
|
Memorarea bazei de date |
|||||||||||||||||||
Fig.11.17. O configuratie cu masina baza de date ca si backend la un calculator gazda de scop general.
|
Memorare de date |
|||||||||||||||||||
Fig.11.18. Folosirea unui procesor de comunicatii frontend pentru a descarca calculatorul gazda de scop general.
Dand aceste responsabilitati unei masini baza de date se elibereaza, de asemenea, resursele gazdei pentru prelucrari.
O masina baza de date cere, in mod uzual, un software specializat pe calculatorul gazda. Software-ul acesta este parte a interfetei dintre gazda si masina baza de date. El poate ajuta analiza si planifica executia cererilor utilizator sau poate numai minimiza prelucrarea cererilor.
Masina baza de date ideala:
va face cereri minime de prelucrare catre gazda. Un apel baza de date va fi pasat cat mai simplu posibil de la gazda la masina baza de date intr-o forma cat mai apropiata de primita de catre gazda de la utilizator.
va trimite inapoi date relevante catre masina gazda pentru a minimiza timpul si costul comunicatiilor intermasini si volumul datelor manuite de gazda.
se va bizui cat mai mult pe protocoalele de comunicatii standard, pentru a nu mai adauga software le gazda.
O masina baza de date ideala nu se bizuie pe serviciile gazdei. Un mediu intensiv baze de date poate fi suportat chiar si de o configuratie in care nu exista nici o dependenta fata de un calculator gazda de scop general (fig.11.19). O retea de terminale, calculatoare personale sau calculatoare gazda acceseaza direct masina baza de date prin comunicatii frontend. Masina baza de date serveste aici ca si server baza de date pentru retea.
|
|
Fig.11.19. Masina baza de date fara dependenta de gazda.
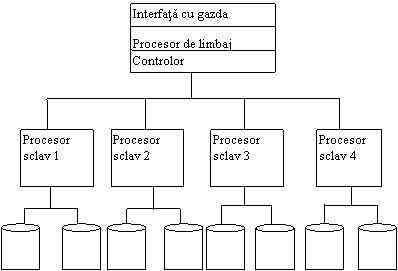
Arhitectura. O arhitectura reprezentativa pentru o masina baza de date este prezentata in fig.11.20. Controllerul masinii baza de date comunica cu mai multe procesoare sclav si aparate de memorare prin unul sau mai multe canale de comunicatii. Datele sunt distribuite pe aparatele de memorare, asa ca ele pot fi localizate si prelucrate paralel. In general, paralelismul poate inbunatati performanta. De fapt, extinderea la cautarea si prelucrarea paralela este una din cele mai clare diferente intre abordarile folosite de masinile baza de date si cele ale calculatoarelor de scop general. O masina baza de date incearca sa localizeze datele mult mai eficient aducand asociatia dintre valorile datelor si adresele aparatelor mult mai aproape de nivelul hardware. Sistemele DBMS soft mapeaza valorile pe adrese folosind tehnici cu structuri de index, ca cele prezentate in cap.10. Masinile baza de date fie folosesc tehnici bazate pe continutul memoriei adresabile (aparate al caror controllere cunt in stare sa gaseasca inregistrarile direct prin examinarea continutului lor, si nu urmand pointeri si adrese) fie isi maresc viteza procesului de gestionare a indecsilor codificandu-i hard si nu soft.
|
|
Fig.11.20. O arhitectura reprezentativa pentru o masina baza de date.
Tehnici de distribuire a datelor. Pentru prelucrarea in paralel datele trebuie sa fie partitionate cu grija pentru accesul de la mai multe procesoare. Masinile baza de date folosesc diferite tehnici pentru partitionarea datelor intre aparate. Pentru a simplifica discutia asupra anumitor tehnici, sa presupunem ca exista numai doua procesoare si numai doua relatii de baza: DEPT si ANGAJAT. Un mod de a distribui datele este de a memora liniile DEPT pe un procesor si liniile ANGAJAT pe celalalt procesor (fig.11.21.).
Aceasta alternativa nu ofera multe oportunitati pentru paralelism, accesele fiind fie la o relatie, fie la cealalta.
O alta alternativa este de a folosi cat de multe aparate se poate pentru a memora liniile oricarei relatii, folosind mai multe fisiere pentru a memora o relatie. De exemplu, memorand jumatate din liniile lui DEPT si jumatate din liniile lui ANGAJAT pe un procesor si celelalte jumatati pe celalalt procesor, asa cum se prezinta in fig.11.22. Exista acum un potential pentru paralelism intr-un acces la relatia DEPT sau la relatia ANGAJAT, si chiar la reuniunea celor doua relatii.
|
Angajat Dept |
|||||||||||||||||||||||||||||||||||||
Fig.11.21. Distribuirea intregilor relatii pe procesoare.
|
Angajat Dept |
||||||||||||||||||||||||||||||||||||||||||||||||||
Fig.11.22. Distribuirea de partitii de relatii pe procesoare.
Partitionarea unei relatii intre aparate poate fi orizontala (anumite linii accesate de un procesor, alte linii de alt procesor), verticala (anumite coloane accesate de un procesor, alte coloane de alt procesor) sau o combinatie de partitionare orizontala si verticala. Partitionarea orizontala este cea mai frecvent utilizata. Partitiile pot fi distribuite pe aparate astfel incat incarcarea sa fie echilibrata intre procesoare. Daca un procesor devine excesiv solicitat, avand mai multe date de accesat decat celelalte procesoare, atunci oportunitatile pentru paralelism vor fi diminuate.
O modalitate de a distribui liniile este de a folosi hashing pe blocuri (vezi cap.10.) pe aparatele de memorare. Fiecare aparat este tratat ca si un bloc si apoi trebuie folosit un al doilea hash pentru a determina adresa de memorare in bloc.
Structura director. Directorul sistem pentru o masina baza de date trebuie sa contina nu numai corespondenta dintre relatii si aparatele pe care sunt memorate, ci si localizarea de memorare a partitiilor acestora.
Directoarele masinii baza de date includ indecsi pentru a facilita localizarea partitiilor si acesti indecsi pot fi implementati:
soft sau hard la nivelul controllerului pentru a reduce volumul datelor accesate si numarul de procesoare care servesc o cerere.
hard la nivelul bus-ului de comunicatii pentru a reduce volumul datelor accesate si numarul de procesoare care servesc o cerere.
Liniile unei partitii pot fi cautate secevntial, folosind un index local disponibil procesorului sau folosind o memorare adresabila dupa continut.
Prelucrarea interogatiilor. Probabil partea cea mai dificila in implementarea unei masini baza de date este dezvoltarea strategiilor de control necesare pentru a coordona actiunile multor procesoare. Cu procesoare paralele, masina baza de date trebuie sa fie capabila sa refaca o cerere care se distribuie intre procesoare si trebuie sa fie capabila sa previna interferente atunci cand mai multe cereri actualizeaza date in partitii implicand mai multe procesoare. Aceste strategii de control sunt similare cu acelea cerute pentru gestionarea bazelor de date distribuite implementate pe retele de calculatoare.
Vederea utilizator. Din punctul de vedere al utilizatorului, interactiunea cu o masina baza de date nu ar trebui sa fie diferita de folosirea unui DBMS pe un calculator gazda cu scop general. Limbajele si facilitatile ar trebui sa fie aceleasi si activitatea de modelare logica a datelor este aceasi. Nu exista un consens asupra necesitatii masinilor baza de date. Anumiti experti considera ca costurile mici si performanta inbunatatinta a hardului conventional cuplat cu inbunatatirile din softul DBMS au eclipsat avantajele revendicate de catre furnizorii de masini baza de date. Alti experti sustin ca performantele si costurile oferite de masinile baza de date sunt esentiale in gestionarea eficienta a volumelor mereu in crestere de date pe care societatea le colecteaza.
Masini baza de date comerciale. Masinile baza de
date au devenit disponibile comercial mai de curand. Radacinile lor
se gasesc in sistemele de cercetare dezvoltate la diferite
universitati (
Masinile baza de date comerciale includ:
DBC/1012 - Teradata Corp.
IDM (Intelligent Database Machine) - Britton-Lee.
iDBP Data Processor si iDIS Database Information System - Intel.
DBC/1012 ofera suport baza de date backend pentru calculatoare IBM mari si include subsisteme bazate pe microprocesor interconectate de un subsistem de comunicatii inteligent. Masina baza de date poate fi expendata modular adaugand subsisteme disc si procesor. DBC/1012 a devenit disponibila in 1984.
IDM ofera suport baza de date backend pentru o varietate de calculatoare medii si mari, incluzand aici VAX, PDP - 11, IBM 43xx, 30xx si 370. IDM poate fi de asemenea interfatata, fara o gazda de scop general, cu o retea de unul sau mai multe IBM PC. A devenit disponibil in 1981.
iDBP este in intentia lui Intel un integrator de posibilitati gestiune baze de date pentru afaceri mici sau sisteme de birou. El foloseste comunicatii si interfata soft intr-un mini sau microsistem.
iDIS este o masina baza de date frontend care ofera o interfata intre calculatoare sau terminale distribuite si o baza de date de pe un calculator gazda. El suporta si dezvoltarea unei baze de date locale servind calculatoare personale.
|
Politica de confidentialitate |
| Copyright ©
2024 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |