
Am vazut in lectia anterioara ca , in anumite ipoteze, o aproximare a modului in care experienta afecteaza credinta noastra asupra primei brute a unui contract de asigurare C Q, X) este
h(X) = (1- z)m + zM
unde m
este prima bruta teoretica EXr
= Em Q) cu m Q) = E(Xr Q) , M = ![]() este media
istorica a platilor iar z
este factorul de credibilitate Bühlmann, calculat dupa formula
este media
istorica a platilor iar z
este factorul de credibilitate Bühlmann, calculat dupa formula
z = ![]()
unde
a = Var(m Q)) = Em Q) - E2m Q) = Em Q) - m2
iar
s = E(Var(Xr Q)) = E(Xr2 - m Q)) = EXr2 - Em Q
Problema este ca h nu este o statistica, adica nu depinde numai de rezultatele observatiilor. Mai depinde de modelul Bayesian acceptat de asigurator.
Pentru a fi aplicabil, ar fi de dorit ca cei trei parametri de care depinde (1.1) - adica m,a si s2 sa poata fi estimati din observatii.
Ideea lui Bühlmann a fost sa se apeleze la contracte independente.
Presupunem ca
a. Dispunem de k contracte independente (Cj j k in care factorii de risc Qj sunt identic repartizati. Notam Cj = (Qj , Xj) . Presupunem in prima etapa ca toate contractele pe care ne bazam au aceeasi intindere in timp, deci Xj = (Xj,1, Xj,2, ., Xj,t). Vom nota cu X matricea (Xj)1 j k
b. Repartitia PoQj = u t nu depinde de j.
c. Modelul este acelasi in cadrul fiecarui contract. Mai mult, presupunem ca, la fel ca in cursurile anterioare, in cadrul fiecarui contract variabilele Xj,r sunt conditionat independente si identic repartizate.
In aceste conditii toate variabilele aleatoare (Xj,r)1 j k , r t vor fi identic repartizate. Mai mult, vectorii Xj vor fi identic repartizati, deoarece PoXj = UQt unde Q(Q) este repartitia lui X1,1 conditionata de Q
Sa
notam cu ![]() estimatorul Bayesian
liniar optim al variabilei aleatoare m Qj) dat de observatiile X = (Xj,r)j,r . Mai precis,
estimatorul Bayesian
liniar optim al variabilei aleatoare m Qj) dat de observatiile X = (Xj,r)j,r . Mai precis, ![]() este o functie hj(X) de forma
este o functie hj(X) de forma
hj(x) = cj
+ ![]()
cu proprietatea ca
E(m Qj) - h(X))2 E(m Qj) - b0 - ![]() )2 b0 , bi,r I A i k , 1 r t
)2 b0 , bi,r I A i k , 1 r t
Mai intai vom demonstra un analog al Corolarului 1.5 din lectia anterioara. De fapt pe noi ne intereseaza sa dam o predictie asupra variabilei aleatoate Xj,t+1, si nu sa aproximam pe m Qj
LEMA 3.1. Fie X o variabila aleatoare din L1 . Fie F G doua s-algebre. Presupunem ca G este independent de G si de X. Atunci E(X F G) = E(X F
Demonstratie. Cum E(X F ) este F G - masurabila, trebuie aratat numai ca pentru orice multime C I F G este adevarata egalitatea E(E(X F)1C) = E(X1C) . Daca C = A B cu A IF , B I G atunci egalitatea este adevarata deoarece E(E(X F)1A B) = E(E(X F)1A1B) = E(E(X1A F)1B) = E(E(X1A F))P(B) (caci E(X1A F) este independenta de 1B) = E(X1A)P(B) = E(X1A)E(1B) = E(X1A1B) (deoarece 1B este independenta de X1A) = E(X1C). Apoi urmeaza un rationament standard : multimile de forma C = A B cu A IF , B I G formeaza un sistem de generatori inchis la intersectii finite pentru F G iar multimile C cu proprietatea ca E(E(X F)1C) = E(X1C) formeaza un p-sistem, etc.
COROLAR 3.2. (i). E(Xj,t+1 Ci i k) = E(Xj,t+1 Cj) = E(m Qj Xj
(ii). E(Xj,t+1 X) = E(m Qj Xj) = E(Xj,t+1 Xj
Demonstratie. Am presupus ca toate contractele sunt independente. Aplicam lema de mai sus cu Xj,t+1 in loc de X, s Cj) in loc de F si s Ci i k, i j) in loc de G: deci E(Xj,t+1 Ci i k) = E(Xj,t+1 Cj). A doua relatie este corolarul 1.5 din lectia anterioara. A doua relatie rezulta din faptul ca E(Xj,t+1 X) = E(E(Xj,t+1 Ci i k X) = E(E(m Qj Xj X) = E(m Qj Xj) ; ultima egalitate este de fapt chiar corolarul 1.5 din lectia anterioara.
Se poate demonstra mai mult.
Revenim
pentru moment la Corolarul 1.5. din lectia anterioara. Se stie
ca media conditionata de o s-algebra F este proiectorul ortogonal pe
subspatiul Hilbert L2(F). Mai
precis, daca X I L2(W K,P) , atunci E(X F) = ![]() . Cu riscul plictisirii cititorului, explicam putin
ce inseamna aceasta.
. Cu riscul plictisirii cititorului, explicam putin
ce inseamna aceasta.
Sa spunem ca V este un spatiu Hilbert Deci pe acest spatiu avem un produs scalar iar norma este definita prin x <x,x> Fie H V un subspatiu inchis si H ortogonalul sau. H este de asemenea un subspatiu inchis al lui V. Spatiile Hilbert au o proprietate cruciala numita « Teorema proiectiei ortogonale » : orice x I V se scrie in mod unic ca x = xH + xH* unde xH I H iar xH* I H Aplicatia x a xH se numeste proiectia ortogonala a lui x pe H. I se spune asa deoarece x - xH xH . Vom nota proiectia ortogonala PrH . Proiectia ortogonala are urmatoarele proprietati:
(i). este un operator liniar (adica PrH (ax+by) = aPrH (x) + bPrH (y) a,b I A, x,y I V)
(ii). care este proiector (adica PrH (PrH(x)) = PrH (x) x)
(iii). continuu (de fapt de norma 1)
(iv). Daca H K V atunci PrH o PrK = PrH .
(v). Daca H K atunci PrH + K = PrH + PrK (intr-adevar, scriem unic x = xH + xK+y cu xH I H, xK I K si y I (H+K) = H K
(vi) Daca x H atunci PrH(x) = 0 (caci daca x = xH + y cu xH I H, y I H atunci 0 = <x,xH> <xH,xH> <y,xH> = ║xH║2 + 0 )
(vii). Daca x K si H K atunci PrH + K (x) = PrH (x) (se aplica (v). si (vi).)
Aici se subintelege ca H si K sunt subspatii inchise ale lui V.
Ceea ce este mai important pentru cazul nostru, proiectia ortogonala pe H coincide cu proiectia metrica pe H.
Proiectia metrica se defineste altfel (definitia are sens pentru o clasa mai larga de spatii Banach!) . Anume sa consideram functia fx : H ) data prin fx(u) = x - u . Aceasta functie este convexa si limt fx(tu) = . Nu inseamna neaparat ca are un punct de minim (pentru cultura generala : daca spatiul Banach V are proprietatea ca functia fx are cel putin un punct de minim pentru orice subspatiu inchis H V , atunci el este reflexiv - teorema Eberlein !) . Spatiile Hilbert sunt reflexive, deci in cazul nostru un asemenea punct de minim y exista. El se numeste element de cea mai buna aproximare a lui x in H. Uneori se intimpla ca acest element de cea mai buna aproximare sa fie si unic. (Pentru cultura generala : daca elementul de cea mai buna aproximare este unic, atunci spatiul V este reflexiv si strict convex . Reflexiv = V coincide cu bidualul sau V'' iar strict convex inseamna ca daca x,y I V sunt liniar independenti, atunci x + y < x y ). Spatiile Hilbert sunt strict convexe deoarece ( x y x + y x y <x,y> T x = ty , t I A, deci x si y sunt coliniari , dupa cum rezulta din inegalitatea Schwartz - Cauchy - Buniakowski.
Deci daca V este reflexiv si strict convex atunci oricarui x i se ataseaza un element din H unic care sa fie element de cea mai buna aproximare a lui. Acest element se numeste proiectia metrica a lui x pe H. Sa il notam , de exemplu, PmH(x).
Se stie ca in spatiile Hilbert cele doua proiectii coincid. Intr-adevar, nu este complicat. Daca xH = PrH( x) si y I H, atunci x-y x - xH) + (xH - y) x - xH xH - y < x - xH, xH - y > . Dar x - xH este ortogonal pe H iar xH - y I H - deei produsul scalar este egal cu 0. Rezulta x-y x - xH xH - y x - xH y I H deci proiectia ortogonala coincide cu proiectia metrica. Vom numi « proiectia pe H » proiectia ortogonala = metrica pe H..
Revenind la contextul
din corolarul 1.5, lectia precedenta, , g(X) este
proiectia lui Xt+1
pe L2(X) iar
estimatorul Buhlman h(X) este proiectia lui Xt +1 pe
spatiul inchis generat de X
in L2. Sa notam acest spatiu cu sp(X). Fie H spatiul generat de 1 si X. Paragraful 2 din
lectia precedenta ne spune ca h(X) = PrH(Xt+1). Am
vazut ca g(X) = ![]() =
= ![]() (Corolarul 1.5 din lectia precedenta). De aceea si h(X) = PrH(m Q)). Motivul este foarte general, si anume :
(Corolarul 1.5 din lectia precedenta). De aceea si h(X) = PrH(m Q)). Motivul este foarte general, si anume :
LEMA 3.3. Fie V un spatiu Hilbert si H K doua subspatii inchise. Fie x,y I V ca PrK x = PrK y. Atunci PrH x = PrH y.
Demonstratie. Evident: PrH x = PrH PrK (x) = PrH PrK (y) = PrH y.
Corolar. 3.4. Fie H un spatiu inchis din L2 astfel ca sp(X) H L2(W s(X),P). Atunci
PrH (Xt+1) = PrH (m Q
Demonstratie. Este Lema 1.3 aplicata in urmatorul context: K este L2(s(X)) , x este m Q) si y este Xt+1.
Revenind la corolarul
1.2 (ii), stim ca E(Xj,t+1 X) = E(m Qj Xj) = E(Xj,t+1 Xj). Atunci pentru orice subspatiu H din L2(W s(X),P) avem ca PrH (Xj,t+1) = PrH (m Qj)). In particular, daca H =
sp(1,X) , atunci ![]() - proiectia
metrica pe H a variabilei
aleatoare Qj - coincide si cu PrH (Xj,t+1).
- proiectia
metrica pe H a variabilei
aleatoare Qj - coincide si cu PrH (Xj,t+1).
Fie Hj = sp(1,Xj) L2(s(Xj)) L2(s(X)) . Egalitatea E(m Qj Xj) = E(Xj,t+1 Xj) implica atunci
TEOREMA 3.5. In ipotezele a., b., c. de mai sus
![]() = (1- z)m + zMj
= (1- z)m + zMj
unde Mj = (Xj,1 + Xj,2 + . + Xj,t) / t
Demonstratie. Fie Yi,r = Xi,r - EXi,r = Xi,r - m. Fie Yi = (Yi,r)1 r t si Y = (Yi)1 i k Sa observam ca spatiile Hi pot fi caracterizate si prin Hi = sp(1,Yi), H = sp(1,Y) .
Atunci ![]() = PrH (Xj,t+1) = PrH
(Yj,t+1) + m (caci H
contine constantele) = PrH
(E(Yj,t+1 X)) + m
= PrH (Xj,t+1) = PrH
(Yj,t+1) + m (caci H
contine constantele) = PrH
(E(Yj,t+1 X)) + m
= PrH (E(Yj,t+1 Yj)) + m . Fie Zj = E(Yj,t+1 Xj) Dar Zj este independenta de Xi daca i j. Avand media egala cu 0, Zj Yi,r pentru orice i j si 1 r t. Sa scriem H = Hj Kj unde Kj = sp(Yi,r i k , i j, 1 r t). Cum Zj Kj , proprietatea (vii) a proiectiei ortogonale
implica PrH (Zj) = ![]() (Zj) .
Deci in definitiv
(Zj) .
Deci in definitiv
![]() =
= ![]() (E(Yj,t+1 Yj)) + m =
(E(Yj,t+1 Yj)) + m = ![]() (E(Yj,t+1 + m Xj)) =
(E(Yj,t+1 + m Xj)) = ![]() (E(Xj,t+1 Xj)) =
(E(Xj,t+1 Xj)) = ![]() (Xj,t+1)
(aplicam proprietatea (iv). a proiectiei ortogonale cu Hj in loc de H si L2(Xj) in loc de K ). Dar teorema Buhlman spune ca
(Xj,t+1)
(aplicam proprietatea (iv). a proiectiei ortogonale cu Hj in loc de H si L2(Xj) in loc de K ). Dar teorema Buhlman spune ca ![]() (Xj,t+1) = (1- z)m
+ zMj .
(Xj,t+1) = (1- z)m
+ zMj .
Dar daca schimbam spatiul de proiectie ?
In
statistica apar si alte tipuri de estimatori, care nu mai corespund
intotdeauna proiectiei pe un subspatiu. Spre exemplu, estimatorul ![]() = (X1 + X2 + .+ Xt)/t , notat
de noi cu M , nu este un proiector pe
un subspatiu al lui L2 . Intr-adevar, daca presupunem
ca variabilele Xj
sunt din L2 si EXiXj = a (daca i j) sau a + b (daca i = j)
atunci <Xt+ -
= (X1 + X2 + .+ Xt)/t , notat
de noi cu M , nu este un proiector pe
un subspatiu al lui L2 . Intr-adevar, daca presupunem
ca variabilele Xj
sunt din L2 si EXiXj = a (daca i j) sau a + b (daca i = j)
atunci <Xt+ - ![]() , Xj > = a - (ta+b)/t = b/t = 0 b = 0 EX12 = EX1X2 = EX22
T E(X1-X2)2 = 0 T Xj = X1 a.s. j . Deci, daca nu suntem in
cazul trivial,
, Xj > = a - (ta+b)/t = b/t = 0 b = 0 EX12 = EX1X2 = EX22
T E(X1-X2)2 = 0 T Xj = X1 a.s. j . Deci, daca nu suntem in
cazul trivial, ![]() nu poate fi proiector ortogonal pe nici un spatiu care
contine variabilele (Xj)1 j t
nu poate fi proiector ortogonal pe nici un spatiu care
contine variabilele (Xj)1 j t
Si
totusi, ![]() este un proiector, dar nu pe un subspatiu al lui L2,
ci pe o varietate afina.
este un proiector, dar nu pe un subspatiu al lui L2,
ci pe o varietate afina.
Definitie. Fie V un spatiu Hilbert si D V . Atunci D se numeste varietate afina daca x,y I D, a,b I A ca a+ b = 1 T ax + by I D.
LEMA 3.6.
(i). D este varietate afina D = u + H unde H V este un subspatiu. D este inchisa H este inchis.
(ii). Fie D o varietate afina, n 2 si (ai)1 i n I An astfel ca a1 + a2 + . + an = 1. (Numerele ai formeaza o combinatie afina!). Fie x1,x2,.,xn I D. Atunci a1x1 + . + anxn I D.
(iii). H nu depinde de u I D. Deci H = D - D.
(iv). Daca D este o varietate afina atunci exista un unic u I D ca D = u + H cu H un subspatiu si u H. Sa numim acest vector u proiectia lui 0 pe D. El are proprietatea ca ║u║ = d(0,D) = inf . Numim scrierea D = u + H, u H reprezentarea normala a varietatii afine D.
(v). Fie D = u + H o varietate afina inchisa scrisa normal. Atunci definim
PrDx := u + PrH x = PrD(0) + PrH x
si numim functia PrD : V D proiectia pe D. Atunci PrD este proiectia metrica pe D in sensul definit mai sus: ║x - PrD(x)║ = inf
Demonstratie.
(i). Sa
presupunem ca D este varietate
afina. Fie u I D oarecare si fie H = D
- u = . Atunci H este un
subspatiu vectorial. Intr-adevar, daca x I D si t I A atunci tx + (1-t)u
= u + t(x - u ) I D. Altfel spus, u + tH
D t I A tH H t I A. Deci x I H , t I A T tx I H. Pe de alta parte,
daca x,y I H x', y' I D ca x = x' - u, y = y' - u T (x + y)/2 = ½ x'+ y' - u I H (caci ½ x'+ y' I D!) de unde x+y = 2 ![]() I H sau H + H H. Deci
I H sau H + H H. Deci
tH H , H + H H
adica H este un subspatiu. Reciproc, daca H este un subspatiu , u I V atunci D = u + H este evident o varietate afina caci x,y I D x = u + x', y = u + y' cu x', y' I H T ax + by = (a+b)u + (ax' + by') = u + ax' + by' (daca a+b = 1) I D. A doua afirmatie rezulta din faptul ca translatia x a x + u este o izometrie in orice spatiu Banach.
(ii). Inductie.
Presupunem afirmatia adevarata pentru n si o
verificam pentru n+1. Fie (ai)1 i n+1 ca a1+.+an+1 = 1.
Exista o submultime de n
numere ai a caror
suma sa fie nenula (caci ai nu pot fi toti egali cu 1!). Sa presupunem
ca a* := a1 + .+ an
0. Deci an+1
= 1 - a*. Atunci scriem a1x1 + . + anxn
+ an+1xn+1
= a* ![]() + (1-a*)xn+1 . Vectorul
din paranteza aparttine lui D
prin ipoteza de inductie iar combinatia totala este in D prin definitie.
+ (1-a*)xn+1 . Vectorul
din paranteza aparttine lui D
prin ipoteza de inductie iar combinatia totala este in D prin definitie.
(iii). Trebuie aratat ca daca u,v I D atunci D - u = D - v . Fie x I D. Atunci x - u = (x + v - u) - v I D - v deoarece x + v - u I D (aplicam punctul precedent cu n = 3, (ai) = (1,1,-1) si (xi) = (x,v,u)! ) deci D - u D - v. Analog si D - v D - u.
(iv). Fie v I D oarecare si H = D - v. Stim ca H este subspatiu si ca D = u + H u I D. Fie atunci u I D H . Insemna ca D = u + H , u I H . Unicitatea : v = u + (v-u) Din (iii) avem ca v - u I H . Cum u I H avem ca u (v-u). Analog si v (v-u) T (u-v) (u-v) T u = v. Fie acum x I D oarecare. Atunci x-u I H T u (x-u) T ║x║2 = ║u║2 + ║x-u║2 (teorema lui Pitagora!) ║u║2.
(v). Fie x I V, y = PrH x , z I D. Deci z = u + z', z' I H. Atunci x - z = (x - y - u ) - ( z' - y). Primul vector este in H (caci x - y I H din definitia proiectiei ortogonale iar u I H din reprezentarea canonica; iar H este un subspatiu inchis al lui V) iar al doilea este in H .
Din teorema lui Pitagora ║x - z║2 = ║x - y - u ║2 + ║z' - y ║2 = ║x -PrD x║2 + ║z - PrD x ║2 ║x -PrD x║2 ceea ce incheie demonstratia.
Concluzia este ca proiectia pe o varietate afina inchisa este de fapt proiectia pe un subspatiu translatata cu un vector.
Sa notam cu aff(C) varieatea afina inchisa generata de C V. Este usor de vazut ca
aff(C) = cl
unde prin cl am notat inchiderea multimii.
COROLAR 3.7. Fie (Xj)j un sir de variabile aleatoare din L2 cu proprietatea ca EXj = m j si Cov(Xi,Xj) = a + s2di,j. Fie t 2 si M = (X1 + X2 + .+ Xt)/t . Atunci
M = Praff(X)(Xt+1) = Praff(X)(0)
Demonstratie. Se poate face in mai multe feluri. Noi vom aplica formula (3.9). Fie D = aff(X). Deci Z I D Z este de forma Z = c1X1 + c2X2 + . + ctXt unde c1 + . + ct = 1. Fie Y = Praff(X)(0). Inseamna ca 0 - Y H Y H . Ramane sa calculam H = D - D. Este usor de vazut ca
H = = sp
Ca atare Y H Y (Xi - Xj) i,j t sau
< c1X1 + c2X2 + . + ctXt , Xi-Xj > i,j t
Efectuind calculele vedem ca < Xr,Xi-Xj> = Cov(Xr,Xi) - Cov(Xr,Xj) poate lua trei valori: daca r este 0, daca r = i este s2 iar daca r = j este - s2. Deci (3.14) devine s2(ci - cj) = 0 T ci = cj i,j . (Cazul s2 = 0 ar implica Xi = Xj i,j , deci nu ar fi interesant! ) Cum suma coeficientilor ci este egala cu 1 rezulta ca ci = 1/t i deci Y = (X1 + .+ Xt)/t = M.
Pe de alta parte < Xt+1,Xi - Xj> = a - a = 0 i j T Xt H T PrH(Xt+1) = 0.
Ne punem acum problema proiectiei variabilei Xj,t+1 pe aff(X) daca suntem in situatia celor k contracte independente care satisfac conditiile a,b,cde mai sus.
Atunci obtinem ceva care se numeste estimatorul liniar omogen al lui m Qj) (sau al lui Xj,t+1, dupa cum rezulta din Corolarul 3.2 combinat cu proprietatea (iv) a proiectiei ortogonale ).
PROPOZITIA 3.8.Fie D = aff(X) si H = D - D. Atunci
PrD(Xj,t+1) = zMj + (1-z)M0 = PrD(m Qj
unde M0
este media generala : M0
= (M1 + M2 + . + Mk)/k iar z = ![]() este coeficientul de
credibilitate.
este coeficientul de
credibilitate.
Mai mult, PrD(0) = M0 si , PrH(Xj,t+1) = z( Mj - M0) .
Demonstratie. Sa observam ca
D = aff(X) =
H =sp
Din ipotezele a,b,c rezulta ca
< Xj,r , Xi,p > = m2 + adj,i + s2dj,idr,p
Deci
< ![]() cj,rXj,r
,Xi,p-Xi',p' > = aSi
+ s2ci,p - (aSi'
+ s2ci',p') = a(Si - Si') + s2(ci,p - ci',p')
cj,rXj,r
,Xi,p-Xi',p' > = aSi
+ s2ci,p - (aSi'
+ s2ci',p') = a(Si - Si') + s2(ci,p - ci',p')
Am notat cu Si suma ci,1 + ci,2 + . + ci,t .
Fie Y = PrD(0). Deci Y I D si Y H . Din (3.16), conditia care trebuie indeplinita este ca
Y (Xi,p-Xi',p') 1 i,i' k, 1 p,p' t
Inlocuind in (3.18) rezulta conditiile
a(Si - Si') + s2(ci,p - ci',p') = 0 , 1 i,i' k, 1 p,p' t
Daca
punem i = i' deducem ca ci,1 = ci,2 = . = ci,t = S i/t
deci Si = tci,1; inlocuind
in (3.20) pentru i i'
deducem ca (ta + s2)(ci,1 - ci',1)
= 0 i i' T c1,1 = c2,1
= . = ck,1 adica toti coeficientii cj,r sunt egali. Din (3.15)
urmeaza imediat ca cj,r
= ![]() deci Y =
deci Y = 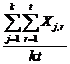 =
= ![]() - cu notatiile de
la (3.8). Adica proiectia originii pe D este media aritmetica a tuturor observatiilor,
notata cu M0.
- cu notatiile de
la (3.8). Adica proiectia originii pe D este media aritmetica a tuturor observatiilor,
notata cu M0.
Calculam acum Z = PrH(Xj,t+1). De data aceasta vom apela la metoda multiplicatorilor lui Lagrange, desi s-ar putea proceda analog, impunind conditia ca Z I H si Z (Xi,p-Xi',p') i,i',p,p'.
Avem de
minimizat functia convexa f(c) = E[(Xm,t+1 - ![]() cj,rXj,r)2]
cu restrictia
cj,rXj,r)2]
cu restrictia ![]() cj,r =
0. Atasam functia
cj,r =
0. Atasam functia
F(c,l) = E[(Xm,t+1
- ![]() cj,rXj,r)2]
- 2l(
cj,rXj,r)2]
- 2l(![]() cj,r)
cj,r)
Derivata partiala fata de ci,p este ![]() (c,l) = - 2E[Xi,p(Xm,t+1 -
(c,l) = - 2E[Xi,p(Xm,t+1 - ![]() cj,rXj,r)]
- 2l
cj,rXj,r)]
- 2l
Impunand conditia ca ![]() (c,l) = 0 gasim sistemul
(c,l) = 0 gasim sistemul
![]() cj,r E(Xi,pXj,r) = E[Xi,p(Xm,t+1)] + l 1 i k , 1 p t
cj,r E(Xi,pXj,r) = E[Xi,p(Xm,t+1)] + l 1 i k , 1 p t
Folosind (3.17) sistemul devine
m ![]() cj,r + a
cj,r + a![]() ci,r + s2ci,p = m2
+ adm,i l
ci,r + s2ci,p = m2
+ adm,i l
sau, folosind conditia ![]() cj,r = 0
si notatia Si de
mai sus
cj,r = 0
si notatia Si de
mai sus
aSi + s2ci,p = m2 + adm,i l , 1 i k , 1 p t
Daca i m este fixat , egalitatea de mai sus devine
aSi + s2ci,p = m2 + l p t T ci,1 = ci,2 = . = ci,t = ![]()
daca i = m atunci rezulta
aSi + s2ci,p
= m2 + a + l p t T cm,1 = cm,2 = . = cm,t = ![]()
Punem conditia ca ![]() cj,r = 0
si determinam astfel pe l = - m2 -
cj,r = 0
si determinam astfel pe l = - m2 - ![]() de unde gasim
de unde gasim
cj,r = 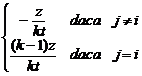 =
= ![]()
Deci Z = ![]() cj,rXj,r
=
cj,rXj,r
= ![]() = z(Mj - M0).
= z(Mj - M0).
Faptul ca m Qj) are aceleasi proiectii rezulta imediat din faptul ca <Xi,p,Xj,t+ > = <Xi,p,m Qj > i,p.
Sa notam estimatorul liniar omogen al lui m Qj) cu ![]() (Qj). El depinde de doi parametri necunoscuti,
de a si s2
. Deci nici el nu este o statistica. Este un estimator bayesian nedeplasat
aentru m.
(Qj). El depinde de doi parametri necunoscuti,
de a si s2
. Deci nici el nu este o statistica. Este un estimator bayesian nedeplasat
aentru m.
Ne punem acum problema de a estima pe baza datelor de observatie X cei trei parametri m, a si s2. Acum este o problema de statistica obisnuita: cautam trei estimatori nedeplasati pentru aceste cantitati.
Unul din ei l-am gasit deja: M0 este un estimator pentru m.
PROPOZITIA 4.1. In ipotezele a,b,c de la paragraful 3 statistica
![]() =
= ![]() ,
, ![]() =
= 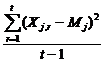 =
= 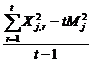
este un estimator nedeplasat pentru s2. Varianta lui este
Var(![]() ) =
) = ![]()
Demonstratie. Conditionat de Qj, variabilele aleatoare Xj,r sunt independente
si identic repartizate. Inseamna ca E(![]() Qj) = Var(Xj,r Qj) - caci stim ca
pentru variabile aleatoare i.i.d.
Qj) = Var(Xj,r Qj) - caci stim ca
pentru variabile aleatoare i.i.d. ![]() este intr-adevar un estimator nedeplasat pentru
varianta.
este intr-adevar un estimator nedeplasat pentru
varianta.
In concluzie E(![]() ) = E(Var(Xj,r Qj)) = s2 (din 3.4).
) = E(Var(Xj,r Qj)) = s2 (din 3.4).
Pe de alta parte variabilele aleatoare ![]() sunt independente si identic repartizate , de unde
rezulta imediat (4.2).
sunt independente si identic repartizate , de unde
rezulta imediat (4.2).
Este
complicat de a calcula varianta estimatorului ![]() . Observam ca decisiv pentru minimizarea lui este
cresterea numarului de contracte independente, k.
. Observam ca decisiv pentru minimizarea lui este
cresterea numarului de contracte independente, k.
Totusi, putem calcula variantele estimatorilor Mj si M. Apare o evidenta deosebire fata de cazul i.i.d., cind aceste variante tind la 0 o data cu cresterea numarului de observatii, t :
PROPOZITIA 4.2. In ipotezele a,b,c de la paragraful 3 avem
Var(Mj)
= a + ![]() , Var(M0) =
, Var(M0) = ![]()
Demonstratie. Fie Sj = Xj,1 + Xj,2 + . + Xj,t . Atunci Var(Mj)
= ![]() iar Var(Sj)
=
iar Var(Sj)
= ![]() Cov(Xj,p,Xj,q)
=
Cov(Xj,p,Xj,q)
= ![]() (a + dp,qs ) = t2a + ts2 . A doua
afirmatie rezulta imediat din faptul ca variabilele aleatoare Mj sunt independente.
(a + dp,qs ) = t2a + ts2 . A doua
afirmatie rezulta imediat din faptul ca variabilele aleatoare Mj sunt independente.
PROPOZITIA 4.3. In ipotezele a,b,c de la paragraful 3 variabila aleatoare
![]() =
= 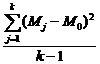 -
- ![]()
este un estimator nedeplasat pentru a.
Demonstratie. Se stie ca daca Mj
sunt variabile aleatoare i.i.d. atunci este un estimator
nedeplasat pentru Var(Mj). Din propozitia
anterioara stim ca Var(Mj) = a + ![]() .
.
Inseamna ca E(![]() )= a +
)= a + ![]() - E(
- E(![]() ) iar din propozitia 4.1 stim ca
) iar din propozitia 4.1 stim ca ![]() este un estimator
nedeplasat pentru s2.
Inseamna ca E(
este un estimator
nedeplasat pentru s2.
Inseamna ca E(![]() ) =
) = ![]() deci E(
deci E(![]() )= a.
)= a.
Observatie. Precizia estimatorilor este data de varianta lor. Pentru ca sa aiba sens, ar trebui adaugata ipoteza ca in modelul nostru bayesian , variabilele aleatoare Xj,r au moment de ordin 4. De asemenea vedem ca nu conteaza asa de mult t (= istoricul ) cit conteaza k - numarul de contracte independente.
COROLAR 4.4. Variabila aleatoare
![]() =
= ![]()
este un estimator pentru
coeficientul de credibilitate z care
este consistent in k : adica k T ![]() z .
z .
Demonstratie. Din legea nunmerelor mari aplicata variabilelor aleatoare i.i.d. (Mj)j stim
ca limita aproape sigura a.s.limk = Var(Mj) = a + ![]() . Pe de alta parte variabilele aleatoare (
. Pe de alta parte variabilele aleatoare (![]() )j sunt si ele i.i.d. deci a.s.limk
)j sunt si ele i.i.d. deci a.s.limk ![]() = E
= E![]() = s2 .
Deci daca k , atunci
= s2 .
Deci daca k , atunci ![]() converge a.s. la s2
si
converge a.s. la s2
si ![]() converge a.s. la a.
Inseamna ca si
converge a.s. la a.
Inseamna ca si ![]() z .
z .
Observatie.
In general
estimatorul ![]() nu este nedeplasat, caci nu avem motive sa credem
ca o formula de tipul E
nu este nedeplasat, caci nu avem motive sa credem
ca o formula de tipul E![]() =
=![]() ar putea fi adevarata, chiar in ipoteze
restrictive. Daca X si Y sunt independente, de exemplu, atunci E
ar putea fi adevarata, chiar in ipoteze
restrictive. Daca X si Y sunt independente, de exemplu, atunci E![]() se poate calcula, este diferit de
se poate calcula, este diferit de ![]() . Ca amuzament, daca X
si Y sunt i.i.d. atunci
egalitatea este adevarata!
. Ca amuzament, daca X
si Y sunt i.i.d. atunci
egalitatea este adevarata!
Revenim in contextul din capitolul II: avem observatiile X = (X1,.,Xt) si modelul Bayesian
P(X1 I B1,..,Xt I Bt Q) = Q(Q,B1)..Q(Q,Bt) Br I B(A r t
Q q) = fX Q q n
PoQ = u t
Reamintim ca m Q) = E(Xr Q). In aceste conditii media aposteriori este
g(X) = E(m Q X) = 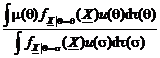 = E(Xt+1 X
= E(Xt+1 X
iar estimatorul Buhlman
h(X) = Prsp(1,X)(Xt+1) = Mz + (1-z)m cu
m = EXr, M = (X1
+ . + Xt)/t, z = ![]() , a = Var m Q), s2 = E(Var(X1 Q
, a = Var m Q), s2 = E(Var(X1 Q
Tot demersul de pina acum ar fi inutil daca nu ar exista cazuri intilnite in statistica care estimatorul Buhlman h(X) ar coincide cu g(X) . Un exemplu in care chiar asa se intimpla s-a dat in capitolul I.
Dam acum o generalizare a lui.
fX Q q(x) = p(x)e-qx/q q
unde se subintelege ca spatiul parametrilor E = [0, ). Se presupune ca functia q(q) este derivabila.
In acest caz densitatea vectorului X este
fX Q q(x) = ![]() unde S = x1 + . + xt
unde S = x1 + . + xt
Sa presupunem ca densitatea u a variabilei aleatoare Q este de forma
u(q) = ![]() unde a b I ) iar C(a b) este o constanta de normare.
unde a b I ) iar C(a b) este o constanta de normare.
In aceste conditii densitatea aposteriori este
fQ X = x q)= 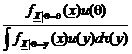 = A(a b,x)e-q a+S) / qt+b q
= A(a b,x)e-q a+S) / qt+b q
adica este de acelasi tip ca si densitatea apriori. Spunem ca familia aceasta de densitati este o familie conjugata..
PROPOZITIA 5.1. Daca modelul bayesian este exponential, densitatea apriori este de forma (5.7) si u(0) = u( ) = 0 atunci g si h , definiti prin (5.4) si (5.5) coincid.
Demonstratie. Ideea este sa aratam ca g(X) este de forma c0 + < c, x>. Stim ca estimatorul Buhlman este cel mai bun de acest tip. Fie fq(x) = fX Q q(x)
Din faptul ca fq este o densitate deducem ca q(q) = ![]() dn(x) . Derivind (putem deriva sub
integrala caci putem aplica teorema Lebesgue de convergenta
dominata!) gasim q'(q -
dn(x) . Derivind (putem deriva sub
integrala caci putem aplica teorema Lebesgue de convergenta
dominata!) gasim q'(q - ![]() dn(x) = - q(q)
dn(x) = - q(q)![]() dn(x) = - q(q)
dn(x) = - q(q)![]() fq(x)dn(x) = - q(q)E(Xr Q q) = - q(q m q) de unde
fq(x)dn(x) = - q(q)E(Xr Q q) = - q(q m q) de unde
m q) = - ![]() (q
(q
Pe de alta parte , derivand u(q) si folosind (5.9) gasim
u' q bm q a)u(q
Integrind si folosind conditiile u(0) = u( ) = 0 rezulta
0 = ![]() dq =
dq = 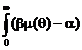 u(q) dq b
u(q) dq b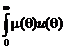 dq a . Deci =
dq a . Deci = ![]()
Dar integrala din stinga este Em Q) = EXr = m= ![]() .
.
Acum facem exact aceleasi calcule folosind densitatea aposteriori (5.8). Avem
g(X) = E(m Q X) = 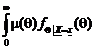 dq . Dar fQ X=x q) este de acelasi tip ca u, numai
ca s+au schimbat parametrii: in loc de a avem a + S iar in loc de b avem b + t.
dq . Dar fQ X=x q) este de acelasi tip ca u, numai
ca s+au schimbat parametrii: in loc de a avem a + S iar in loc de b avem b + t.
Rezulta atunci ca g(X)
= ![]() . Ori, aceasta este de forma c0 + < c, x>., ceea ce incheie demonstratia.
. Ori, aceasta este de forma c0 + < c, x>., ceea ce incheie demonstratia.
Un caz particular este daca modelul este Poisson: repartitia Poisson este de forma (5.5). Aici masura n este masura cardinal pe multimea numerelor naturale..
|
Politica de confidentialitate |
| Copyright ©
2025 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |