
Arhitecturi feed-forward multinivel
Printr-o arhitectura neuronala se intelege: colectia de neuroni cu topologia conexiunilor si organizarea neuronilor. Neuronii sunt organiati in submultimi numite straturi sau nivele (layers) de neuroni. Neuronii din acelasi strat au functiuni similare.
Arhitectura feed-forward (cu propagare numai inainte) contine:
stratul de intrare (FX) ce consta din neuroni nespecializati (nu au memorie locala) ce primeste semnale (informatie) si le distribuie catre neuronii urmatorului strat;
stratul de iesire (FY) este cel ce produce raspunsul;
unul sau mai multe straturi ascunse (hidden layers) FH1, FH2, ., FHn.
In functie de topologia conexiunilor (modul de propagare a informatiei), principalele arhitecturi feedforward multinivel sunt:
arhitectura cu conectivitate standard, in care exista conexiuni doar intre unitatile nivelelor vecine (adica neuronii din acelasi strat nu sunt conectati intre ei), fiecare neuron primind semnale de la toate unitatile aflate pe nivelul imediat anterior si trimitand semnale catre toate unitatile din nivelul imediat urmator;
arhitectura cu conectivitate locala, in care exista conexiuni doar intre neuronii nivelelor vecine, fiecare neuron fiind conectat doar cu o submultime de unitati din nivelul anterior (numit campul receptiv al acestui neuron);
arhitectura cu conectivitate oarecare, in care pot exista conexiuni intre oricare doi neuroni cu conditia ca graful retelei sa nu contina cicluri.
Ideea propagarii inapoi a fost redescoperita de mai multe ori. Primul care a utilizat aceasta tehnica a fost Paul Werbos (1974), insa el nu a exploatat posibilitatile metodei de a genera ponderile de conexiune pentru neuronii straturilor ascunse. Algoritmul a fost redescoperit de David Parker (1982) si popularizat de catre Rumelhart si grupul PDP in cunoscutele volume "Parallel Distributed Processing" (1986); autorii din grupul PDP au sugerat ca algoritmul de propagare inapoi sau regula delta generalizata (dupa cum au numit-o ei) poate depasi limitarile algoritmului perceptronului.
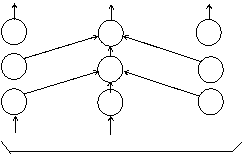
Consideram cazul unei retele feed-forward multinivel cu un strat ascuns si cu conectivitate standard: FX → FH → FY. Diagrama este urmatoarea:
![]()
![]()
![]()
Stratul de iesire FY 1 . j . m
wqj
Stratul ascuns FH 1 . q . p
viq
Stratul de intrare FX 1 . i . n
![]()
![]()
![]()
xk
Notatii:
semnalul de intrare xk are componentele ![]() ,
, ![]() ,.,
,.,![]() si fiecare componenta este primita si
distribuita de fiecare neuron i
din stratul de intrare, i = 1, 2,., n;
si fiecare componenta este primita si
distribuita de fiecare neuron i
din stratul de intrare, i = 1, 2,., n;
viq reprezinta ponderea (weight) conexiunii (memorie sinaptica) de la neuronul i din stratul de intrare la neuronul q din stratul ascuns, i = 1, 2,., n si q = 1, 2,., p;
wqj reprezinta ponderea conexiunii de la neuronul q din stratul ascuns la neuronul j din stratul de iesire, q = 1, 2,., p si j = 1, 2,., m;
Memoria sistemului este data de ponderile (viq)iq si (wqj)qj.
Neuronii artificiali din stratul ascuns si cel de iesire corespund unor filtre neliniare (cu o componenta liniara si una neliniara reprezentata de functia de activare): f(w1x1+ w2x2+.+ wnxn), f = functie (neliniara) de activare. Functia de activare are cel mult un numar finit de puncte de nederivabilitate, este monoton nedescrescatoare si marginita. Exemple de functii de activare:
logistica: f(x)
= ![]() , α > 0 ; pentru α = 1 avem
, α > 0 ; pentru α = 1 avem ![]() .
.
Gaussiana: f(x)
= exp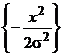
Mai notam cu:
fq functia de activare de la neuronul q din stratul ascuns;
fj functia de activare de la neuronul j din stratul de iesire;
![]() valoarea
actionarii neuronului q din
stratul ascuns indus de intrarea k;
valoarea
actionarii neuronului q din
stratul ascuns indus de intrarea k;
![]() valoarea
actionarii neuronului j din
stratul de iesire indus de componenta k
a intrarii.
valoarea
actionarii neuronului j din
stratul de iesire indus de componenta k
a intrarii.
Din punct de vedere matematic, functionarea retelei consta in compunerea unor transformari, iar din punct de vedere algoritmic, aceasta poate fi implementata printr-un simplu algoritm.
Algoritmul
Back-Propagation are doi pasi pentru
fiecare pereche ![]() , (am considerat multimea formelor de instruire
, (am considerat multimea formelor de instruire ![]() , xk
, xk![]() Rn,
Rn, ![]() Rm):
Rm):
(pasul forward (inainte))
se prezinta xk = (![]() ,
,![]() ,.,
,.,![]() ) la
intrarea in stratul FX
) la
intrarea in stratul FX
se calculeaza
activarile induse in stratul FH:
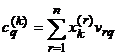 , q=1,2,., p.
, q=1,2,., p.
se calculeaza
iesirile neuronilor din stratul FH:
![]() , pentru q=1,2,., p.
, pentru q=1,2,., p.
se calculeaza
activarile induse in stratul FY:
![]() , j = 1, 2,., m.
, j = 1, 2,., m.
se calculeaza
iesirile neuronilor din stratul FY:
![]() , j = 1, 2,., m.
, j = 1, 2,., m.
se calculeaza
eroarea ![]() =
= ![]() , unde yk
=
, unde yk
= ![]() .
.
(pasul backward (inapoi))
- se reactualizeaza fiecare componentele a memoriei sistemului: wqj si viq.
Instruirea retelei reprezinta o succesiune de epoci, iar o epoca reprezinta partea din procedura de instruire in care exemplele de antrenament sunt aplicate secvential sistemului.
Daca eroarea este acceptabila pentru toate
perechile ![]() (adica eroarea
medie are o valoare acceptabila) atunci invatarea se poate
considera incheiata; altfel, se prezinta toti vectorii de
instruire din nou retelei.
(adica eroarea
medie are o valoare acceptabila) atunci invatarea se poate
considera incheiata; altfel, se prezinta toti vectorii de
instruire din nou retelei.
Pentru stabilirea regulii de corectie se
foloseste o metoda gradient descendent (min f → xk+1 = xk
+ ck hk, pt. k≥0, unde hk =![]() este antigradientul
functiei f) pentru a minimiza
eroarea patratica totala; se presupune ca directia de
coborare la pasul k (cand vectorul aplicat
la intrare este xk si
iesirea dorita corespunzatoare este
este antigradientul
functiei f) pentru a minimiza
eroarea patratica totala; se presupune ca directia de
coborare la pasul k (cand vectorul aplicat
la intrare este xk si
iesirea dorita corespunzatoare este ![]() ) este data de antigradientul erorii
) este data de antigradientul erorii ![]() asociata la acest
pas; in acest fel, la fiecare pas al metodei de instruire functia criteriu
se schimba, obtinandu-se o descrestere a erorii totale. Regula
de modificare a ponderilor din stratul de iesire va fi:
asociata la acest
pas; in acest fel, la fiecare pas al metodei de instruire functia criteriu
se schimba, obtinandu-se o descrestere a erorii totale. Regula
de modificare a ponderilor din stratul de iesire va fi:
![]() , unde
, unde 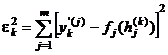 si ck
si ck ![]() (0,1)
(0,1)
Atunci 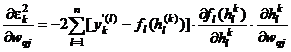 .
.
Considerand ![]() rezulta ca
rezulta ca 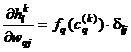 . Rezulta ca:
. Rezulta ca:
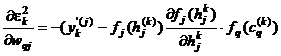
si deci reactualizarea ponderilor wqj se face dupa regula:
![]()
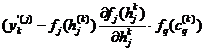 .
.
In mod analog se procedeaza pentru determinarea corectiilor ponderilor corespunzatoare neuronilor ascunsi:
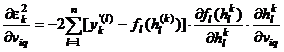 .
.
Pentru ![]() se obtine
se obtine 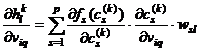 .
.
Considerand ![]() rezulta ca
rezulta ca 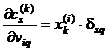 si deci
si deci 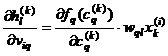 .
.
Atunci regula de corectie a ponderilor corespunzatoare neuronilor ascunsi este:
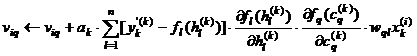 , unde ak
, unde ak
![]() (0,1)
(0,1)
Se observa fiecare corectie a ponderilor corespunzatoare neuronilor ascunsi depinde de toate erorile asociate stratului de iesire. Apare acum ideea de propagare inapoi: erorile cunoscute ale neuronilor din stratul de iesire sunt trimise (propagate) inapoi in stratul ascuns pentru a determina o modificare potrivita a ponderilor neuronilor acestui camp.
Observatii
Convergenta procedurii:
Din punct de vedere algoritmic, propagarea inapoi foloseste pentru instruire o informatie nelocala; uneori algoritmul nu converge sau, daca ajunge la o solutie, aceasta reprezinta un minim local; de asemenea, timpul de instruire este relativ ridicat datorita unui factor de invatare desemnat interactiv.
In cazul ratei de invatare variabile, in general se considera ck=ak pentru fiecare pas al metodei. Pentru a evita oscilatiile ce pot aparea in jurul solutiei optime, este necesar ca ratele de instruire ck sa descreasca in timp; aceasta descrestere nu trebuie sa fie nici prea rapida, nici prea lenta. Admitem ca sirul (ck)k descreste suficient de lent daca seria sumelor partiale este divergenta; am regasit astfel conditia binecunoscuta:
![]() .
.
Cu cat coeficientii ck descresc mai lent, cu atat mai rapid decurge instruirea retelei.
Conditia ca sirul (ck) sa descreasca suficient de rapid se exprima prin cerinta ca seria patratelor acestor coeficienti sa fie convergenta, adica:
![]() .
.
Cu cat coeficientii ck descresc mai repede, cu atat mai rapid vectorul pondere "uita" formele deja invatate.
Daca rata de invatare la pasul k este ck=1/k, atunci cele doua conditii precedente sunt satisfacute.
Conditiile stabilite anterior reprezinta pentru cazul propagarii inapoi o formulare matematica a ceea ce Grossberg numeste dilema stabilitate-plasticitate. Conform acestei dileme, o retea neuronala trebuie sa satisfaca doua cerinte contradictorii:
pe de o parte reteaua trebuie sa fie suficient de stabila pentru a-si aminti formele invatate anterior si
pe de alta parte, reteaua trebuie sa fie suficient de plastica pentru a putea invata noi forme.
Sa notam ca, in cazul algoritmului Widrow-Hoff, conditii analoage cu cele de mai sus garanteaza convergenta algoritmului. In cazul algoritmului BackPropagation, conditiile privind coeficientii nu garanteaza convergenta, ci asigura doar o comportare "rezonabila" a algoritmului.
Alegerea unei topologii: cele mai multe aplicatii ale algoritmului de propagare inapoi utilizeaza o retea cu un singur strat ascuns. Motivul principal al acestei alegeri este acela ca neuronii intermediari care nu-s conectati direct cu neuronii de iesire vor avea variatii foarte mici ale ponderilor si deci vor invata foarte lent; alt motiv este simplitatea ei. Daca se alege aceasta structura ramane ramane de luat o singura decizie privind topologia: cati neuroni ascunsi sunt necesari. Pe de alta parte, folosirea mai multor strate ascunse conduce la rezultate mai bune pentru anumite probleme, de complexitate mai mare.
Sintetizand algoritmul back-propagation:
P0. Initializare
Se initializeaza ponderile retelei (viq)iq si (wqj)qj cu valori mici, generate aleator.
Se initializeaza constantele de invatare ck si ak cu valori din (0,1)
P1. O etapa de instruire
Pentru fiecare exemplu k=1, 2,.,N din multimea de antrenament se executa pasii
P11. Se calculeaza
activarile induse in stratul FH:
, q=1,2,., p.
P12. Se calculeaza
iesirile neuronilor din stratul FH:
![]() , pentru q=1,2,., p.
, pentru q=1,2,., p.
P13. Se calculeaza
activarile induse in stratul FY:
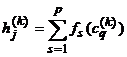 , j = 1, 2,., m.
, j = 1, 2,., m.
P14. Se calculeaza
iesirile neuronilor din stratul FY:
![]() , j = 1, 2,., m.
, j = 1, 2,., m.
P15. Se
calculeaza eroarea ![]() =
= ![]() =
=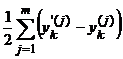 care este o masura a calitatii.
care este o masura a calitatii.
P16. Se actualizeaza ponderile stratului de iesire
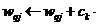
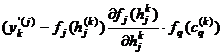
P17. Se actualizeaza ponderile stratului ascuns
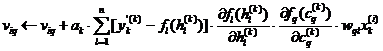
P2. Iterarea
Daca eroarea medie este acceptabila, atunci invatarea este incheiata; altfel se executa un nou ciclu de instruire
Proiect - recunoastere de litere
Implementati algoritmul back-propagation pentru recunoasterea caracterelor A, B, ., H (8 litere), reprezentand literele prin 10*10 pixeli (vector de dim. 100). Exemplele sa contina cate 10 exemple din fiecare litera, iar raspunsul dorit este cate un model de litera. Dupa antrenare sa se faca testarea retelei pe exemple noi din fiecare litera si evaluati performanta in termeni de eroare.
|
Politica de confidentialitate |
| Copyright ©
2025 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |