
implementarea sistemelor concurente
Notiunea de program in acceptiunea lui obisnuita se refera in special la aplicatii simple, didactice. Cand programam probleme mai complexe, de multe ori folosim termenul de produs program. Dar, chiar si aceasta terminologie este insuficienta in situatiile in care se impun detalii de implementare la nivel low-level.
De exemplu, daca se doreste proiectarea unui sistem de operare, trebuie tinut cont de faptul ca in functionarea SO apare un anumit grad de nedeterminism. Acesta se refera mai ales la situatiile in care sunt solicitate raspunsuri la evenimente care apar la momente de timp imprevizibile si cu o frecventa, de asemenea, imprevizibila. Avem trei nivele de astfel de evenimente, in functie de frecventa lor de aparitie:
cereri de schimb intre memoria interna si suporturi de memorare externa (de care raspunde UCP);
cereri de ocupare, pentru o perioada de timp nedeterminata, a unor periferice fizice sau a unor blocuri de memorie;
servicii oferite de sistemul de operare utilizatorilor de la terminale in cazul aparitiei unor erori hardware sau software.
Repetam ca, pentru a se putea satisface cererile de mai sus, nu este suficient conceptul de program in analiza proiectului. Este nevoie si de un alt concept, acela de proces, pe care il vom prezenta in continuare.
Un proces sau task reprezinta o entitate dinamica ce corespunde unui program in executie, fiind o abstractizare a activitatii procesorului. Aceasta definitie va fi extinsa in paragrafele urmatoare.
Din alt punct de vedere, un proces este un calcul care poate fi executat concurent sau paralel cu alte calcule. Inca, aceste definitii vor fi completate in paragrafele urmatoare.
In acest paragraf detaliem prima definitie, insistand asupra caracterului dinamic al unui proces si precizand care este legatura proces - procesor.
Existenta unui proces este conditionata de existenta a trei factori:
procedura - un cod sursa, un set de instructiuni - care trebuie executata;
un procesor care sa poata executa aceste instructiuni;
un mediu (memorie, periferice) asupra caruia sa actioneze procesorul conform instructiunilor din procedura.
Trebuie deci facuta diferenta dintre un proces si un program. Procesul are caracter dinamic deoarece precizeaza (se refera la) o secventa de activitati aflate in curs de executie, iar programul are un caracter static deoarece el numai descrie secventa de activitati respectiva. Un proces "exista", un program "se executa".
Un proces dureaza atat timp cat executia programului a fost inceputa si nu este incheiata.
Un proces este format din: (1) codul programului, (2) stiva cu datele temporare necesare procesului (parametrii programului, variabilele locale, adresele de revenire) si (3) o sectiune de date.
Legatura logica pe care o putem stabili intre un proces si un procesor consta in faptul ca fiecare proces are un procesor virtual propriu, care ii este asociat pe durata existentei sale. Procesorul real (fizic) comuta de la un proces la altul. Cand un proces este in executie se spune ca a primit controlul procesorului.
Pentru a memora informatiilor legate de toate procesele pe care le are de gestionat, sistemul de operare isi creeaza o structura de date numita tabela de procese. Pozitia unui proces in tabela de procese va fi identificatorul procesului deoarece il determina in mod unic.
Din punct de vedere practic, un proces consta dintr-un program (un set de activitati de executat) si din contextul programului (sau parametrii sistem care trebuie cunoscuti procesului pentru executia sa).
Componentele programului unui proces pot sa fie activitati ale SO sau ale utilizatorului. Daca procesul este asociat unor module ale sistemului de operare atunci avem procese sistem. Daca procesul este asociat unui program utilizator atunci avem procese utilizator. Procesele pot sa creeze, la randul lor, alte procese utilizator sau sa lanseze in executie module sistem. In paragrafele urmatoare se va introduce si notiunea de fir de executie, care va detalia aceste aspecte.
Informatiile continute in contextul programului procesului sunt memorate intr‑o structura, numita teoretic vector de stare al procesului si practic, bloc de control al procesului. Acesta se refera la: identificatorul procesului, starea procesorului cand procesul nu este activ, pentru a se putea controla continuarea executiei procesului, starea procesului, prioritatea procesului, prioritatea procesului la obtinerea resurselor, informatii despre resursele alocate procesului.
Din punctul de vedere al legaturilor care se pot stabili intre activitatile a doua procese, acestea pot fi: procese independente, daca nu sunt influentate unul de executia celuilat sau procese cooperante, in caz contrar.
Caracterizarea proceselor independente poate fi facuta astfel:
nu pot partaja aceleasi resurse;
executia lor este determinista, adica consta dintr-o aceeasi succesiune de pasi la fiecare initiere;
executia depinde numai de datele de intrare, nu si de date sau evenimente care pot surveni pe parcurs;
executia este reproductibila, adica cu aceleasi date de intrare se obtin aceleasi rezultate;
executia poate fi intrerupta si reluata fara efecte negative.
Caracterizarea proceselor cooperante se obtine prin negarea proprietatilor proceselor independente. In cele ce urmeaza se va vedea ca particularitatile sistemelor concurente conduc indeosebi spre programarea proceselor cooperante si mai putin spre procesele independente. Astfel, procesele independente se dovedesc nespecifice sistemelor concurente.
Sa consideram un exemplu simplu pentru legatura dintre conceptele de proces, program, procesor. Daca cineva citeste o carte, aceasta activitate este comparabila cu executia unui program de catre un proces. Daca o persoana x citeste cartea si in timp ce acest proces este intrerupt, o alta persoana y citeste aceeasi carte atunci situatia rezultata este comparabila cu executia aceluiasi program de catre doua procese diferite. Intre aceste procese pot aparea relatii de cooperare (cele doua persoane schimba impresii despre carte) sau de competitie (cele doua persoane ajung sa doreasca sa citeasca in acelasti timp, deci sa-si partajeze resursa fizica, care este cartea). Mai mult, deoarece cartea este una singura, suntem in situatia in care se impune restrictia ca numai un proces sa aiba acces la resursa la un moment dat. O solutie ar putea fi copierea cartii si astfel ambele persoane pot citi simultan (duplicarea datelor).
Spre deosebire de "resursa" carte, daca consideram cazul a doi muzicieni care interpreteaza simultan aceeasi partitura atunci situatia rezultata este comparabila cu doua procese care executa acelasi program pe procesoare distincte. In plus, aici apare si conditia de sincronizare intre procesele "interpretate
Daca in timp ce persoana x citeste sa consideram ca suna telefonul. Atunci procesul "citire" va fi intrerupt, controlul va fi cedat procesului "convorbire telefonica" si dupa ce acesta se va incheia, va fi reluat procesul "citire" de unde a fost abandonat.
Pentru a se executa, un proces isi aloca resurse fizice necesare desfasurarii activitatilor sale. Cum resursele unui SC sunt adesea in cantitati limitate, nu este recomandat ca un proces sa-si rezerve la creare toate resursele necesare. In acest caz, se poate ca atunci cand procesul ajunge sa aiba nevoie de o anumita resursa fizica (memorie, dispozitiv periferic), aceasta sa fie ocupata de alt proces. Astfel, procesul nu mai poate sa-si continue executia.
De asemenea, un proces intra intr‑o stare in care nu se mai poate derula daca continuarea executiei lui depinde de producerea unui eveniment. De exemplu, daca un proces trebuie sa furnizeze date altui proces atunci acesta din urma trebuie sa astepte pana cand primeste datele respective.
Un proces care se afla in imposibilitatea de a-si continua executia deoarece nu dispune de resursele si/sau datele necesare, se spune ca este in starea blocat.
Ordinea in care procesorul sistemului de calcul se dedica executiei proceselor depinde de o anumita prioritate a proceselor. Aceasta se asociaza fiecarui proces la creare. Cu cat prioritatea unui proces este mai mare, cu atat acel proces va intra in executie mai repede.
Daca un proces P1 poate sa se execute (adica dispune de toate resursele si datele necesare), dar procesorul a decis executarea unui alt proces, P2, de prioritate mai mare, atunci spunem despre procesul P1 ca este in starea intrerupt.
Desi in ambele stari anterioare, blocat sau intrerupt, procesul nu-si mai poate continua executia, exista o deosebire esentiala intre ele. Starea blocat intervine din motive ce tin de logica dupa care se succed activitatile proceselor dependente, in timp ce starea intrerupt apare din motive fizice legate de imposibilitatea procesorului unic de a se dedica (de a ceda controlul) simultan executiei mai multor procese.
Daca procesul este in curs de executie atunci se spune ca procesul se afla in starea activ.
Daca sistemul de calcul are un singur procesor atunci, in orice moment, un singur proces poate fi activ. Daca avem mai multe procesoare atunci, la un moment dat, pot fi active cel mult atatea procese cate procesoare avem.
Executia unui proces dureaza intre crearea procesului si distrugerea (eliminarea) lui.
Crearea unui proces consta din:
alocarea unui vector de stare;
initializarea componentelor vectorului de stare;
inregistrarea procesului in tabela de procese.
Odata cu memorarea in tabela, se fixeaza si identificatorul procesului (pozitia din tabela). Prin intermediul acestuia, sistemul de operare si orice alt proces vor putea referi procesul creat, pe toata durata existentei lui.
Un proces, Pt, (utilizator sau sistem) poate cere crearea unui proces, Pf. In acest caz spunem ca Pt este proces tata, iar Pf este proces fiu sau descendent al lui Pt. Daca doua sau mai multe procese sunt descendenti ai aceluiasi tata atunci ele se numesc procese frati.
Multimea tuturor proceselor create de un proces A si de descendentii acestuia formeaza descendenta procesului A.
Cu aceste definitii putem spune ca toate procesele sistemului alcatuiesc o structura arborescenta.
Distrugerea unui proces consta din:
eliberarea resurselor ce i-au fost alocate;
eliberarea memoriei corespunzatoare vectorului de stare;
eliminarea procesului din tabela proceselor.
Un proces se poate autodistruge atunci cand ajunge la sfarsitul executiei sale sau poate fi distrus la cererea unui alt proces sistem sau utilizator.
Alte operatii care se pot efectua asupra proceselor sunt: intarzierea, semnalizarea, planificarea, schimbarea prioritatii, suspendarea si reluarea. In urma aplicarii uneia sau unora dintre aceste operatii, un proces poate fi in diferite stari. Aceasta dependenta este prezentata in figura urmatoare.
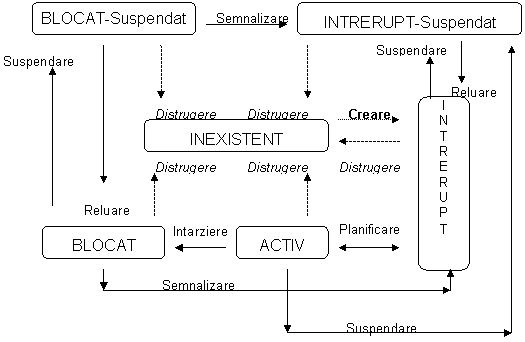
Figura 3. Operatii cu procese
Observatie. Trebuie precizat ca la creare, procesul trece automat in starea intrerupt, iar prin operatia de distrugere, procesul trece din starea curenta (activ, intrerupt, blocat, intrerupt-suspendat sau blocat-suspendat) intr‑o stare generic numita inexistent.
Operatia de intarziere (WAIT) apare cand un proces nu-si poate continua executia si asteapta aparitia unui eveniment. Prin operatia de semnalizare (SIGNAL), un proces este informat ca s-a produs un eveniment (de obicei, este vorba de evenimente pe care procesul le asteapta pentru a-si putea continua executia).
Planificarea este operatia prin care se stabileste ordinea in care procesele primesc controlul procesorului pentru executie. Schimbarea prioritatii unui proces influenteaza modul de alocare a resurselor necesare procesului.
Cronologic vorbind, notiunea abstraca de proces a fost introdusa pentru a numi executia dinamica a unei entitati de calcul pe un procesor. Incepand cu interfetele bazate pe ferestre, sistemele moderne trebuie sa detalieze aceasta definitie a notiunii de proces. De multe ori, la nivelul unui program, este nevoie ca mai multe activitati sa se execute simultan. In timp, acest aspect a fost legat prima data de posibilitatile de lucru multitasking.
Cand se impune o precizie la nivelul notiunilor folosite atunci se foloseste termenul de proces pentru activitatea care initializeaza un program. Resursele necesare executiei acelui program vor fi asociate logic procesului respectiv. Vom folosi termenul de thread, fir sau fir de executie pentru a denumi fiecare dintre activitatile individuale din interiorul programului. Mai mult, termenul de thread va identifica entitatea care se executa pe un procesor.
Sistemele care recunosc lucrul cu fire de executie creeaza automat un proces cu un singur thread atunci cand se initializeaza executia unui program. Acest thread principal poate crea alte thread-uri copil (fiu). Toate threadurile curente partajeaza resursele procesului care le-a creat.
Daca un sistem de operare trebuie sa deserveasca un sistem multiprocesor cu memorie partajata, este important ca acel sistem sa recunoasca procesele cu mai multe fire de executie (multi-threaded processes). In acest caz, threadurile distincte ale aceluiasi proces pot fi planificate sa se execute simultan pe procesoare distincte.
Sistemele de operare traditionale, inchise (closed OS) nu au facilitati de lucru multiprocesor, in timp sistemele dezvoltate recent recunosc aceasta facilitate. Notiunile de proces si thread sunt specifice sistemelor de operare UNIX si Windows, in timp ce alte sisteme folosesc pentru aceleasi concepte o alta terminologie. Astfel, procesul - ca entitate elementara la nivelul unui sistem de operare - este echivalent, pentru alte sisteme, cu un spatiu de adresa cu un thread sau cu un task cu un thread sau cu un proces cu un thread. Pentru exemplificare, preluam din [Bacon, 1998] urmatoarea tabela.
Intentionam ca modelarea aplicatiilor concurente folosind diverse mecanisme de tip ACTOR, TEAM, CLUSTER etc., sa se regaseasca in tematica referatului urmator.
|
Nucleul SO |
Unitatea de executie |
Unitatea de alocare a resurselor |
|
Mach |
Thread |
Task |
|
Chorus |
Thread |
Actor |
|
V |
Thread |
Team |
|
Amoeba |
Thread |
Cluster |
|
Windows NT |
Thread |
Proces |
|
Sun OS |
LWP (LightWeight Process) |
Spatiu de adresa |
Tabel 3. Conceptul de proces sub diverse sisteme de operare
Procesele din acelasi spatiu de adrese sunt adesea numite lightweight threads, LWThreads. Termenul de thread arata ca fiecare proces are un fir de executie diferit. Caracteristica lightweight arata ca, la schimbarea procesului in executie, este necesar sa se salveze informatii putine despre contextul curent. Aceasta este situatia opusa proceselor heavyweight care au propriul spatiu de adresa. Contextul de schimbare intre procesele heavyweight cere atat salvarea si incarcarea tabelelor de gestionare a memoriei cat si a registrelor.
[Andrews, 1991] Cand se executa un program secvential, exista un singur thread de control: PC (Program Counter) incepe la prima actiune atomica a procesului si se muta "prin proces" pe masura ce sunt executate actiuni atomice. Executarea unui program concurent consta in mai multe threaduri de control, cate unul pentru fiecare proces constituent.
In general, aplicatiile concurente sunt scrise in limbaje de programare de nivel foarte inalt. La nivelul unui limbaj de programare secvential, fiecare proces de limbaj este gestionat de un proces al sistemului de operare. Fata de aceasta situatie, cand se scrie un program concurent, programatorul trebuie sa aiba la indemana mecanisme prin care sa defineasca explicit sau implicit procesele concurente. Daca aceste procese sunt aduse la cunostinta sistemului de operare printr-un apel de sistem, atunci suntem in situatia in care sistemul de operare recunoaste si intretine executia proceselor respective.
Dupa Andrews [1991], executarea unui program concurent poate fi privita ca o interpatrundere (interleaving) de actiuni atomice executate de procese individuale. Cand procesele interactioneza, nu sunt acceptabile toate interschimbarile. Rolul sincronizarii este de a preveni interschimburile nepermise.
Daca consideram procesul ca fiind unitatea de alocare a resurselor atunci threadurile lui devin unitatile de planificare. Din acest punct de vedere, un thread este un subproces la nivel de limbaj de programare. Daca astfel de subprocese sunt cunoscute sistemului de operare atunci ele pot fi planificate de SO independent unele de altele. Avantajele cresc atunci cand sistemul este multiprocesor deoarece aceasta configuratie permite ca executia concurenta planificata pe procesoare distincte sa fie una efectiva.
Pentru ca un sistem in timp real sa asigure respectarea restrictiilor temporale impuse de natura sistemului este imperios necesar ca planificarea threadurilor sa se faca á-priori. Mai mult, sunt situatii in care se impune ca planificarea sa se bazeze pe un grafic de prioritati ale proceselor sau pe un grafic de termene limita.
Cand se implementeaza un sistem concurent intr‑un limbaj de programare concurent, programatorul trebuie sa detina informatii despre structura hardware a sistemului concurent, precum si despre sistemul de operare gazda.
Suportul sistemului de operare pentru gestionarea proceselor trebuie sa includa operatii de tip WAIT si SIGNAL care sa asigure sincronizarea proceselor echipamentelor hardware ale sistemului de calcul. In acest context, vom folosi termenul de eveniment pentru a desemna aparitia unui semnal de intrerupere de la o resursa fizica. Tratarea intreruperii pentru interactiunea hardware care tocmai a aparut revine unui proces al sistemului de operare. Executia rutinei de tratare a intreruperii da totodata si raspunsul sistemului la cererea adresata de procesul utilizator prin intreruperea respectiva. In plus, intr‑un sistem concurent, este necesar sa se aiba in vedere ca procesele utilizator pot sa interschimbe informatii, deci trebuiesc corect sincronizate, conform cu logica lor interna.
Concret, o varianta de implementare a aplicatiilor concurente ar putea consta in programarea fiecarei unitati a sistemului concurent ca un proces secvential. In acest caz, sistemul de operare va comunica prin apeluri sistem pentru a permite interactiunea intre procese si pentru furnizarea serviciilor solicitate la nivelul sau. Aceasta solutie este potrivita pentru sistemele cu granularitate mare, slab cuplate ( sau cu conectare slaba, cum sunt sistemele distribuite), in care probabilitatea de interschimb de informatii intre procesele concurente este mica.
O problema suplimentara in proiectarea si implementarea sistemelor concurente este portabilitatea. In majoritatea cazurilor, pentru a coordona interactiunile dintre procese, codurile sursa folosesc resurse ale interfetei sistemului de operare gazda (cum sunt si apelurile sistem). Daca se schimba configuratia sistemului concurent atunci aplicatia ramane dependenta de platforma (interfata) anterioara. De aceea, problema portabilitatii aplicatiilor este una importanta, care trebuie luata in considerare inca din faza de proiectare a sistemului si a aplicatiilor lui.
Multe dintre sistemele concurente functioneaza pe baza unor aplicatii scrise in limbaje de programare secventiale (C, C++) care au facilitati de implementare a concurentei.
Fata de acest "compromis", programatorii au la dispozitie si o serie de limbaje de programare pur concurente. Acestea permit ca intregul sistem sa functioneze pe baza unei aplicatii concurente descrisa intr‑un singur program sursa. Astfel de sisteme sunt de obicei sisteme dedicate (special‑purpose system) care, fie au integrate, fie numai folosesc un set minimal de functii ale sistemului de operare.
Implementarea proceselor dezvoltate la nivelul sistemului de operare sau la nivelul sistemelor de limbaje de programare poate fi extinsa prin facilitatile oferite de comunicarea intre procese, IPC - inter-process communication.
Un limbaj de programare secvential care recunoaste apelurile imbricate si recursive permite implicit ca mai multe proceduri sa fie active simultan. Cu toate acestea, exista un singur thread de control, o singura stiva si o singura zona heap pentru gestionarea executiei programului secvential.
De aceea, este dificil si nenatural ca un acelasi program sursa sa descrie codurile mai multor subsisteme independente (subsistem = colectie de proceduri dependente sau module) sau sa se gestioneze accesul simultan al mai multor clienti la acest cod unic.
Deoarece exista un singur thread de control si sistemul de operare lucreaza cu un singur proces la un moment dat, este exclusa din start posibilitatea ca astfel de sisteme sa poata raspunde rapid si promt tuturor evenimentelor din sistem. Daca in sistemul secvential apare o intrerupere, se salveaza starea procesului (singurul existent), se inregistreaza producerea unui eveniment si procesul curent este suspendat. Deci nu exista posibilitatea de a transfera controlul programului unui alt proces, oricare ar fi efectele asupra sistemului concurent in ansamblu.
Mai mult, intr‑un limbaj secvential nu exista suport pentru implementarea unui subsistem care sa poata astepta intr‑un punct producerea unui eveniment. In orice punct in care se impune o asteptare, cade in sarcina programatorului sa salveze contextul curent si sa-l incarce corect ulterior, pentru reluarea executiei. In particular, nu exista posibilitatea de a "ingheta" stiva de executie pentru a putea relua executia ulterior, din acelasi punct. Exista o singura stiva de executie care oglindeste toate calculele din sistem, chiar daca unele sunt blocate si nu se pot debloca.
O varianta de reducere a acestor inconveniente ar putea consta in aplicarea tehnicii polling la nivelul programului secvential al aplicatiei concurente. Pentru aceasta programatorul trebuie sa dezvolte codul sursa astfel incat programul sa testeze periodic aparitia in sistem a unui eveniment si sa interpreteze diferentiat evenimentele recunoscute.
Din aceste considerente se poate vedea ca o aplicatie concurenta scrisa intr‑un limbaj secvential nu poate valorifica facilitatile unui sistem multiprocesor, existenta unui unic procesor fiind necesara si suficienta pentru executia aplicatiei respective.
Unele limbaje de programare, cum ar fi: Modula-2 sau BCPL, folosesc entitati elementare numite corutine cu ajutorul carora se realizeaza descrierea subprogramelor independente ale aceluiasi program. Deci un astfel de program poate avea mai multe corutine si fiecare corutina are propria stiva de executie. Un astfel de limbaj are instructiuni elementare pentru crearea si stergerea unei corutine, dar si instructiuni speciale, de exemplu cele care intrerup temporar executia unei corutine sau cele care permit programului sa reia executia corutinei exact din starea in care a fost intrerupta. Cand o corutina este intrerupta controlul programului trebuie cedat explicit altei corutine.
[Braunl, 1993] Corutinele sunt o forma restrictiva de paralelism implementata in Modula‑2. Modelul fundamental, caracteristic de arhitectura este cel uniprocesor. Exista un singur flux de instructiuni cu flux de control secvential. Totusi, resursa "procesor" poate fi ocupata si eliberata de o multime de corutine, de o maniera ordonata.
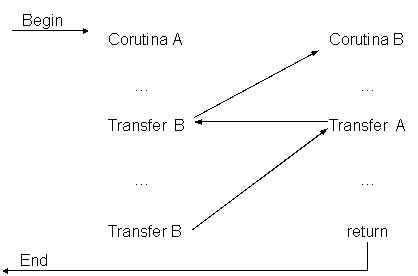
Figura 4. Mecanismul de lucru cu corutine
In aceasta reprezentare se observa o executie pseudo-paralela intre corutine. Ele pot fi vazute ca un caz particular de proceduri (subrutine) ale caror date locale nu sunt pierdute intre apeluri.
Executia incepe cu apelul uneia dintre corutine. Fiecare corutina poate contine oricate propozitii (intructiuni) de TRANSFER care COMUTA fluxul de control intre corutine. Un transfer NU este un apel de procedura deoarece nu presupune implicit ca urmeaza un moment in care controlul programului sa se transfere implicit procedurii (corutinei) apelante; la fiecare operatie de TRANSFER se vor preciza explicit corutinele sursa si destinatie ale schimbarii fluxului de control.
Deoarece lucrul cu corutine este bazat pe existensa unui singur procesor si nu se poate extinde la mai multe, se evita problematica prelucrarilor multitasking. Ramificarea fluxului de control trebuie sa fie definita explicit de programatorul aplicatiei cu corutine.
[Braunl, 1993] Constructiile Fork si Join sunt unele dintre primele unelte ale paralelismului la nivelul limbajului de programare. In Unix este posibil sa se declanseze procese paralele prin operatia Fork si sa se impuna asteptarea incheierii lor prin Wait (operatia de tip Join de sub Unix).
Fata de corutine, acesta este un exemplu de prelucrare paralela efectiva. Executia paralela poate fi asigurata prin multitasking in cuante de timp pe un procesor (time-sharing), daca nu sunt disponibile mai multe procesoare.
In acest tip de programare paralela sunt importante doua concepte fundamentale si anume:
declararea proceselor paralele si
sincronizarea proceselor.
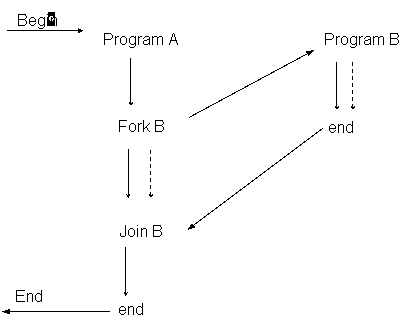
Figura 5. Mecanismul Fork - Join
Din exemplul anterior se observa ca exista un interval de timp in care procesele A si B se executa in paralel.
O alta constructie specifica calculului paralel este ParBegin - ParEnd (sau CoBegin - CoEnd). Aceasta lucreaza de o maniera similara cu parantezele Begin - End specifice programarii secventiale. Diferenta esentiala este faptul ca in interiorul blocului ParBegin - ParEnd instructiunile sunt executate simultan. Limbajele de programare (AL, Algol 68) care au implementat acest mecanism folosesc pentru sincronizare semafoare.
Fata de limbajele
cu corutine, alte limbaje de programare creeaza aplicatii concurente
folosind suportul oferit de procese. Din aceasta categorie amintim:
Ca si in cazul corutinelor, un program poate contine mai multe subprograme, dar aici fiecare subprogram este executat de un proces separat care este definit prin limbajul de programare. O alta asemanare cu corutinele consta in faptul ca si procesele au fiecare propria stiva de executie, dar, exista o mare deosebire in ceea ce priveste controlul programului. Controlul proceselor este asigurat un "agent extern", care nu este programat explicit printr-un subprogram al aplicatiei.
Un astfel de agent este un modul de gestionare a proceselor care face parte din mediul de programare respectiv, asa cum rezulta din figura urmatoare.
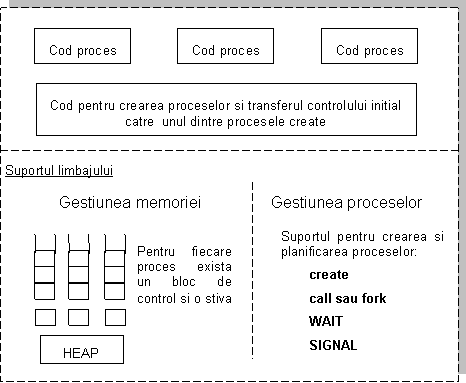
Figura 6. Suportul de limbaj pentru gestionarea proceselor
Un proces poate fi nevoit sa astepte eliberarea unei resurse partajate la nivelul limbajului de programare sau poate fi nevoit sa astepte ca alt proces sa incheie o activitate de care depinde continuarea sa. In astfel de limbaje, o operatie de intarziere de tip WAIT se regaseste ca un apel de procedura. Cand un proces este suspendat in urma unei decizii de asteptare, agentul de control trebuie sa selecteze un alt proces care sa treaca in starea activ.
O problema majora in proiectarea sistemelor concurente bazate pe suportul proceselor de limbaj este stabilirea relatiilor dintre procesele de la nivelul limbajului de programare si procesele cunoscute de sistemul de operare. Se poate impune ca sistemul de operare sa suporte numai cate un proces pentru fiecare program. In acest caz, procesul definit intr‑un limbaj de programare concurent, nu este un proces deplin (matur, fledged) al sistemului de operare. Subprocesele unui program sunt gestionate intern de limbaj prin planificarea proceselor, rezultand o dublura pentru planificarea proceselor facuta de gestionarul de procese de la nivelul sistemului de operare. Mediul limbajului de programare poate multiplexa un proces al sistemului de operare in mai multe subprocese cunoscute numai la nivelul sau.
Scenariul de implementare este asemanator cu cel al corutinelor, dar aici programatorul nu trebuie sa se ocupe de transferul controlului intre procesele de la nivelul limbajului. Planificarea proceselor este asigurata de sistemul de executie a programelor scrise in limbajul respectiv.
Exista cel putin un inconvenient al acestei abordari si anume faptul ca interdependenta proceselor coroborata cu blocarea procesului apelat poate bloca intreg sistemul. De exemplu, daca un subproces creat de program cere sistemului de operare sa execute o operatie de intrare/iesire si se blocheaza (dintr-un motiv oarecare) atunci nici un alt subproces al programului nu-si mai poate continua executia. Aici am presupus un sistem de operare care executa toate operatiile I/O de o maniera sincronizata, de exemplu UNIX (Windows NT este un sistem de operare care poate prelua cererile atat sincron cat si asincron). Un alt exemplu pentru aceeasi idee a blocarii globale ar fi urmatorul: daca un subproces foloseste procesul de gestionare a proceselor limbajului (chiar si numai ca intermediar in intentia de a cere un apel de sistem) si acest proces manager se blocheaza, atunci se va bloca si procesul programului.
Toate aceste probleme sunt rezultatul ipotezei ca sistemul de operare vede numai un proces la un moment dat. Daca programul ar putea sa faca cunoscute sistemului de operare toate subprocesele sale atunci ele ar deveni chiar procese ale sistemului de operare, adica threaduri. Mai mult, pentru accesul la procesoare, aceste threaduri ar fi planificate tot de sistemul de operare si astfel ar putea sa se execute concurent cu alte procese pe procesoarele unui sistem multiprocesor. Fiecare dintre threaduri poate executa un apel sistem catre sistemul de operare si blocarea lui nu va conduce la blocari in lant. Sistemul de operare poate grupa aceste procese de limbaj prin atribuirea unui spatiu de adrese pentru un astfel de grup.
Din considerentele anterioare rezulta doua variante de recunoastere a proceselor la nivelul sistemului de operare: [Bacon, 1998]
sistemul de operare poate vedea un thread pentru un spatiu de adrese - aceasta varianta lucreaza cu threaduri de nivel utilizator (user- level threads); exemple de sisteme care recunosc threaduri utilizator: DEC (Distributed Computing Environment) CMA, OSF, sistemul PCR (Portable Common Runtime) din Xerox PARC; la acest nivel programarea concurenta se face fara suportul sistemului de operare.
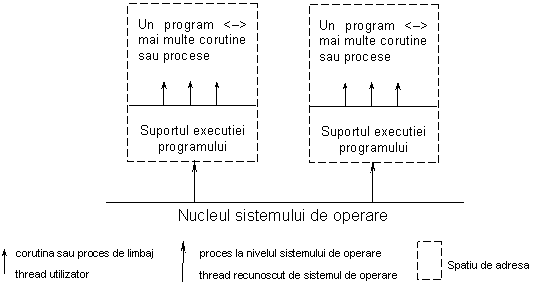
Figura 7. Implementarea proceselor concurente fara suportul sistemului de operare
sistemul de operare recunoaste mai multe threaduri - aici fiecare thread de limbaj va fi atribuit (asignat, asociat) surjectiv unui thread al sistemului de operare; aceasta varianta lucreaza cu threaduri de nucleu al sistemului de operare (kernel- level threads); exemple de sisteme care recunosc threaduri de nucleu: Windows NT, Mach, Chorus, OS/2; la acest nivel programarea concurenta se face cu suportul sistemului de operare pentru procesele interne (Figura 8).
Se poate prevedea o a treia varianta care sa combine caracteristicile primelor doua astfel incat sa se mareasca gradele de libertate ale programatorului pentru cresterea performantei aplicatiilor. Aceasta optiune consta in posibilitatea ca un thread utilizator sa se execute intr-unul din mai multe threaduri de nucleu. In figura urmatoare, in aceasta situatie sunt threadurilor utilizator u4 - u7 fata de threadurile de nucleu k3 si k4 (Figura 9).
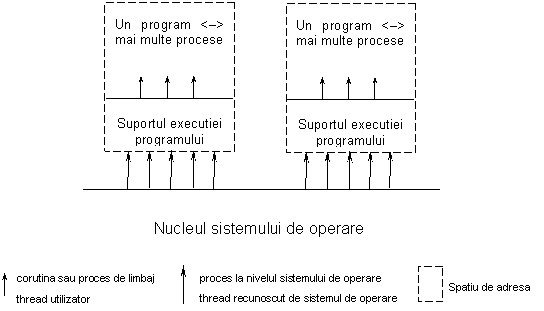
Figura 8 Implementarea proceselor interne bazata pe suportul sistemului de operare
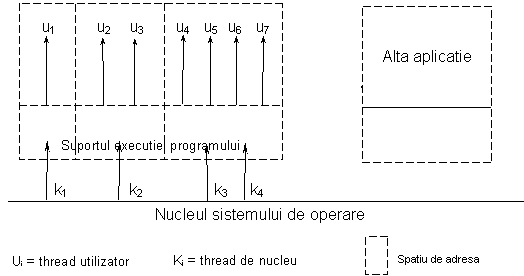
Figura 9 Combinarea threadurilor utilizator si de nivel nucleu
Atunci cand asigneaza threadurile utilizator la threaduri de nucleu, programatorul trebuie sa tina cont de mai multi factori, de exemplu: cate si care sunt procesoarele disponibile in sistem, care procese se pot desfasura in paralel pe procesoare distincte, care threaduri pot eventual sa blocheze apelurile sistem si care sunt directiile in care pot fi exploatate fiecare dintre cele doua tipuri de threaduri (utilizator si de nucleu). De asemenea, trebuie sa tina cont de anumite situatii conflictuale, cum ar fi: (a) cand se blocheaza un thread de nucleu, nici unul dintre threadurile sale de tip utilizator nu mai poate continua sau (b) threadurile utilizator care se executa pe procesoare distincte trebuie sa fi fost asignate la threaduri de nucleu diferite.
Exemplu de sistem care a adoptat aceasta schema este SunOS, care numeste threadurile de nucleu LWP (lightweight process, procese usoare) si threadurile utilizator chiar thread.
Ideal ar fi ca programatorul sa poata folosi threadurile fara sa faca distinctia intre threaduri utilizator si threaduri de nucleu.
Un program concurent poate fi privit ca un ansamblu de componente care pot fi executate simultan. La o prima abordare, aceste componente sunt procesele care comunica intre ele. In acest context sunt corecte ambele definitii ale conceptului de proces si anume: un proces este un calcul care se poate executa paralel sau concurent cu alte calcule, respectiv un proces este o secventa de program in executie.
O conditie fundamentala a executiei concurente a programelor se poate enunta astfel: pentru fiecare proces si pentru fiecare doua instructiuni masina consecutive ale sale, intervalul de timp intre executarea lor este neprecizat, dar finit.
Executia concurenta a proceselor poate crea o serie de surprize celui obisnuit cu programarea secventiala. Dintre acestea, poate cea mai mare surpriza este legata de caracterul nedeterminist al executiei concurente. Comportarea nedeterminista consta in faptul ca un acelasi program concurent, pe un acelasi set de date de intrare poate furniza la iesire "rezultate" diferite. De cele mai multe ori, diferenta dintre iesiri rezulta din ordinea in care intra in executie procesele active, din diferentele care pot aparea intre vitezele de executie ale diferitelor entitati fizice implicate in executia programului curent.
De asemenea, un program concurent poate fi privit ca un program care, in timpul executiei sale, creeaza mai multe procese care se executa intr‑un paralelism abstract (nu neaparat pe procesoare distincte). Existenta unui singur procesor fizic impune ca acesta sa aloce cuante de timp pentru fiecare proces activ. Politica de alocare poate fi aleatoare sau poate respecta disciplina unei anumite structuri de date (coada, coada de prioritati etc.).
Intre procesele unui program concurent apar interactiuni determinate in special de nevoia proceselor de cooperare. Aceste interactiuni sunt de tip comunicare si/sau sincronizare. In paragrafele care urmeaza se va vedea ca cele doua concepte, comunicare si sincronizare, sunt inter-dependente.
Interactiunea proceselor depinde pe de o parte de aspecte legate de cooperarea si/sau competitia intre procesele respective si, pe de alta parte, depinde de deosebirea arhitecturala, structurala intre sistemele cu partajare de date si cele fara partajare de date. De aici se vede ca interactiunea proceselor este un subiect deosebit de important in tematica sistemelor concurente si, de aceea, el se va regasi atat in paragrafele imediat urmatoare, cat si in tratarea comunicarii si sincronizarii proceselor concurente.
Asa cum anticipam in finalul Capitolului 3. O definitie a sistemului concurent, pentru intelegerea contextului de lucru concurent este importanta structura modulara a softului sistemului gazda.
Putem prezenta aceasta structura soft tinand cont de proprietatile zonelor de memorie in care se executa procesele curente. Din acest punct de vedere se deosebesc urmatoarele situatii:
procesele pot partaja spatiu de adresa sau
procesele se pot executa in spatii de adresa separate, distincte si complet disjuncte de spatiile de adresa ale altor procese.
(1) Daca procesele pot partaja spatiu de adresa atunci avem mai multe variante de organizare a executiei proceselor, in functie de necesitatea cooperarii intre procesele curente si de interactiunea intre procesele care pot partaja simultan, prin acces direct, un spatiu de adresa. Astfel, se deosebesc doua variante principale:
(1a) toate procesele partajeaza un acelasi spatiu de adresa si, de aici, rezulta ca se vor executa cu partajare de date sau
(1b) procesele se executa in spatii de adresa diferite (fiecare proces poate avea spatiu de adresa propriu), dar este permisa partajarea unora dintre segmentele codurilor proceselor (segmentul de cod si/sau segmentul de date). Daca segmentul de date este unul care nu poate fi partajat, atunci procesele cooperante urmeaza sa stabileasca alt protocol de comunicare, nu prin partajarea datelor. Dupa localizarea fizica a spatiilor de adresa proprii proceselor, varianta (1b) poate deosebi procesele care se executa pe aceeasi masina de cele care se executa pe masini distincte.
Un exemplu de sistem care implementeaza aceste variante de gestiune a proceselor este un sistem multi-user in care se impun cerinte de protectie a memoriei cand unul dintre utilizatori are restrictii de scriere sau de citire la nivelul zonelor de memorie ale altui utilizator. De asemenea, intr‑un sistem multi-user trebuie impuse restrictii legate de protectia asupra segmentelor de cod comun ale softului sistemului, de exemplu la partajarea compilatorului unui limbaj.
Un alt exemplu il constituie procesele distribuite care partajeaza date sau cod cu alte procese din sistem. Acestea sunt procese care ocupa spatii de adresa distincte, chiar situate pe masini diferite. Orice comunicare intre procesele distribuite foloseste mijloacele de comunicare din reteaua masinilor din sistem, prin intermediul interfetelor hardware si pe baza protocoalelor de comunicare recunoscute in sistemul distribuit respectiv.
Figurile urmatoare reprezinta trei variante de localizare a proceselor in interiorul unui sistem.
Prima dintre ele corespunde variantei anterioare (1a) in care procesele, adesea numite threaduri in acest context, pot partaja acelasi spatiu de adresa. Pentru aceasta situatie sunt potrivite procesele multi-thread, in care procesul este unitatea de alocare a resurselor si threadurile sunt atat unitatile de executie si planificare, cat si entitatile active care trebuie sa comunice. O restrictie suplimentara care trebuie impusa in acest caz se refera la faptul ca un thread al unui proces multi-thread nu trebuie sa interactioneze cu un thread al altui proces multi-thread.
Figura 10. Localizarea proceselor: mai multe procese in acelasi spatiu de adresa
A doua figura corespunde variantei anterioare (1b) in care procesele se pot executa in spatii de adresa diferite, dar pe aceeasi masina. In acest caz gestionarea se face la nivelul procesului si nu prin threadurile componente (heavyweight process model). Procesul devine atat unitate de alocare a resurselor, cat si unitate de planificare si executie.
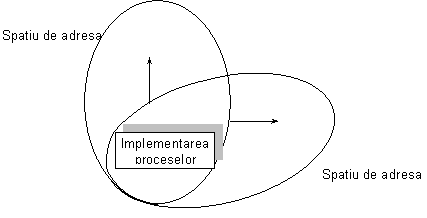
Figura 11. Localizarea proceselor: un proces - un spatiu de adresa, aceeasi masina
A treia figura corespunde tot variantei anterioare (1b), dar pentru sisteme in care procesele se pot executa in spatii de adresa diferite, pe masini distincte.
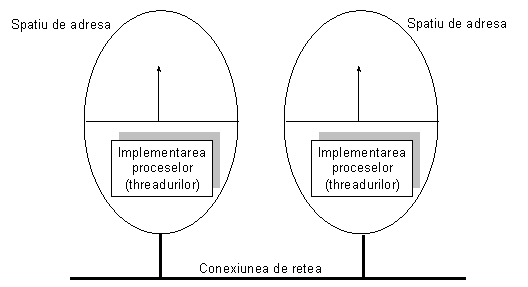
Figura 12. Localizarea proceselor: un proces - un spatiu de adresa, pe masini diferite
(2) Daca procesele se pot executa in spatii de adresa separate, distincte si complet disjuncte de spatiile de adresa ale altor procese atunci putem deosebi doua variante specifice si anume:
(2a) toate procesele se executa in spatii disjuncte sau
(2b) sunt procese care se executa in spatii disjuncte.
Cazul (2a) este in contradictie cu definitia concurentei, deci nu poate fi considerat pentru implementarea unui sistem concurent.
Detaliind cazul (2b), un proces care se executa intr‑un spatiu de adresa disjunct de cel al oricarui alt proces este un proces care nu va partaja nici segment de date, nici segment de cod cu alte procese din sistem. Un astfel de proces poate doar sa intermedieze executia unei instructiuni prin scrierea sau citirea unui operand din propriul spatiu de adresa. Acesta este cazul proceselor distribuite care se executa pe masini diferite intr‑un sistem distribuit.
Toate aceste variante de comunicare intre procese, grupate in situatiile (1) si (2), fac obiectul mecanismelor IPC, Inter Process Communication. In sistemele in care unitatile active sunt threadurile si sunt planificate de sistemul de operare, este mai corect sa folosim terminologia de ITC, Inter Thread Communication.
Cerintele pentru interactiunea proceselor rezulta, pe de o parte, din necesitatea ca procesele sa interactioneze intre ele si, pe de alta parte, din felul in care aceste interactiuni pot fi suportate de sistemul gazda.
Procesele pot coopera pentru indeplinirea unei sarcini comune. Concret, un proces se poate afla in pozitia de a cere altui proces furnizarea unui serviciu si eventual, poate ca trebuie chiar sa astepte sa primeasca acel serviciu. Exemple pentru aceasta situatie ar putea fi: (1) aspectele cooperative care reies din diferite variante de implementare a localizarii unui proces asociat unui anumit modul furnizor de servicii; (2) cazul in care procesul de gestionare a discurilor trebuie sa se sincronizeze cu procesele discurilor respective; (3) prelucrarea proceselor in pipeline in care fiecare proces de faza trebuie sa astepte pana cand procesul fazei anterioare isi incheie executia.
Din aceste aspecte se vede ca cooperarea intre procese presupune sincronizarea lor. Cu alte cuvinte, un proces poate fi nevoit sa execute o operatie WAIT(PROCES) pentru a se sincroniza cu alte procese. Sincronizarea intre procese poate fi privita ca o extindere a sincronizarii proceselor cu functionarea componentele hardware ale sistemului.
Comunicarea intre procesele cooperante se realizeaza de obicei prin operatii SIGNAL(PROCES), deci prin semnale sau intreruperi.
Procesele pot concura pentru acces exclusiv la servicii sau la resurse. Din acest punct de vedere se disting doua aspecte diferite si anume: (a) mai multi clienti adreseaza simultan cereri pentru anumite servicii sau (b) mai multe procese incearca sa acceseze simultan o resursa. Implementarea sistemului concurent trebuie sa prevada si sa gestioneze astfel de situatii conflictuale prin stabilirea unei ordini predefinite, prin intarzierea executiei unora dintre procese, prin stabilirea unor prioritati de acces la resursele care pot deservi numai serial cererile pe care le primesc.
Procesele concurente pot sa fie nevoite sa execute operatii WAIT(PROCES) pana sa acceseze o resursa partajata si trebuie sa poata transmite semnale prin operatii SIGNAL(PROCES) pentru a indica momentul in care au parasit resursa partajata in sistem.
Procesele care se executa in spatii de adrese distincte vor fi cunoscute sistemului de operare. De cele mai multe ori, codul acestor procese provine dintr‑o sursa scrisa intr‑un limbaj de programare secvential. In acest caz, operatiile WAIT si SIGNAL sunt recunoscute ca apeluri sistem.
Procesele care partajeaza spatii de adrese de memorie devin parti ale aceluiasi program concurent si pot sa fie sau nu cunoscute la nivelul sistemului de operare. Daca nu sunt cunoscute de sistemul de operare atunci operatiile WAIT(PROCES) si SIGNAL(PROCES) vor putea fi lansate numai de la nivelul limbajului de programare.
Daca procesele coopereaza atunci se pot dezvolta mecanisme bazate pe operatiile WAIT(PROCES) si SIGNAL(PROCES) care sa asigure comunicarea si sincronizarea intre procesele cooperante. Aceste tehnici pot fi elementare sau pot fi constructii specifice pentru dezvoltarea aplicatiilor concurente in limbaje de programare de nivel inalt.
In cele ce urmeaza se va vedea ca numai aceste doua operatii elementare de tip WAIT(PROCES) si SIGNAL(PROCES) nu sunt suficiente pentru descrierea completa a unei scheme reale de comunicare intre procese de tip IPC.
Fiecare limbaj paralel trebuie sa adreseze (sa recunoasca) elemente specifice paralelismului, sau explicit sau implicit. [Quinn, 1994] Practic, sunt mai accesibile limbajele de programare care nu cer constructii de limbaj pentru paralelism, dar permit procesarea paralela printr-un paralelism implicit. Aceasta situatie este mai usor de realizat nu in limbajele procedurale ci in cele declarative, adica logice (Prolog) sau functionale (Lisp), deoarece informatia procedurala minimala (baza de cunostinte, knowledge) trebuie paralelizata de un compilator "inteligent care functioneaza pe baza de reguli de deducere, cu o interactiune foarte limitata cu programatorul. Reprezentarea declarativa a cunostintelor sau a problemei de rezolvat poate specifica fara echivoc o solutie. Totusi, poate fi destul de dificil sa se converteasca aceste cunostinte intr-un program paralel imperativ (nu declarativ). [Braunl, 1993]
Indiferent daca paralelismul este implicit sau explicit, trebuie sa existe o cale de a crea procese paralele si o cale de a coordona activitatea acestor procese. Uneori, procesele lucreaza asupra datelor proprii si nu interactioneaza. Dar, atunci cand procesele interschimba rezultate, ele trebuie sa comunice si sa se sincronizeze intre ele. Comunicarea si sincronizarea pot fi realizate prin variabile partajate sau prin transfer de mesaje.
Comunicarea consta in schimbul de date (informatii) intre procesele care coopereaza. Comunicarea se poate identifica cu transmiterea de mesaje intre procesele concurente.
Se pot identifica trei criterii de clasificare a tipurilor de comunicare:
dupa mijlocul de comunicare;
dupa gradul de sincronizare;
dupa modul de precizare a sursei si destinatiei comunicarii.
In continuare detaliem aceste clasificari.
dupa mijlocul de comunicare avem:
(a) comunicare prin memorie comuna;
(b) comunicare prin mecanisme specifice de tip monitor, semafor, resursa, canal;
Observatie Deoarece o zona de memorie utilizata in comun este o resursa critica, rezulta ca, in acest caz, se impune programarea de sectiuni critice si implicit rezolvarea problemei excluderii mutuale.
dupa gradul de sincronizare avem cele doua clase naturale de comunicare si anume:
(a) comunicarea fara sincronizare, care se poate identifica cu transmiterea asincrona de mesaje, deci comunicare fara semnal de receptie si
(b) comunicarea cu sincronizare, care se poate identifica cu transmiterea sincrona de mesaje. La randul ei, comunicarea cu sincronizare poate fi facuta:
(i) cu sincronizare simpla sau
(ii) prin invocare la distanta.
In categoria comunicare prin sincronizare simpla putem incadra emiterea mesajului cu semnal de receptie, comunicarea prin canale sau cu punct de intalnire de tip rendez-vous.
In cazul invocarii la distanta receptia mesajului inseamna si semnal de receptie si un raspuns de la destinatar la expeditor. Chiar si in sintaxa unor limbaje de programare concurente, invocarea la distanta apare ca si generalizare a comunicarii prin canale sau ca un rendez-vous extins. Pe de alta parte, invocarea la distanta reprezinta mecanismul RPC, Remote Procedure Call, de implementare a modelului Client-Server de interactiune intre procese: mai multe procese (active) actioneaza in calitate de clienti asupra unui proces server (pasiv) ce urmareste in principal satisfacerea cererilor clientilor.
dupa modul de precizare a sursei si destinatiei, comunicarea se poate face prin precizarea
(a) explicita sau
(b) indirecta a partenerilor implicati in comunicare.
Prin precizare indirecta se va intelege ca se foloseste un intermediar intre procesele care comunica. De exemplu, un astfel de intermediar ar putea fi un canal de comunicare care preia mesajul de la procesul sursa, in timp ce procesul destinatie asteapta sa preia mesajul de pe acel canal.
Toate aceste elemente vor fi reluate in paragrafele urmatoare.
Sincronizarea este o restrictie impusa in evolutia in timp a proceselor.
Sincronizarea consta in planificarea a doua procese, daca continuarea unuia depinde de executia celuilalt.
Pe de alta parte, conform [Ionescu, 1999], sincronizarea proceselor consta in serializarea accesului proceselor concurente la resursele partajate.
Reluand o idee din descrierea comunicarii, avem ca sincronizarea poate fi: (a) cu transmitere de mesaje, deci cu comunicare sau (b) fara transmitere de mesaje, adica fara comunicare. In situatia (b) sincronizarea se realizeaza la nivelul zonelor de memorie comune proceselor concurente.
Modalitatea naturala pentru rezolvarea sincronizarii se dovedeste a fi cooperarea logica prin diverse structuri de date. Limbajele de programare ofera programatorului posibilitatea de a opta intre utilizarea diverselor TAD-uri pentru sincronizare, cu sau fara comunicare.
Din punctul de vedere al nivelului de sincronizare, programatorul poate opta pentru: (a) sincronizare pe generatie sau (b) sincronizare pe conditie.
Sincronizarea pe generatie consta in intarzierea unui proces pana cand toate procesele din aceeasi generatie cu el si-au incheiat activitatea. Acest model se regaseste in rezolvarea problemei jocul vietii sau in solutiile paralele/ concurente pentru calculul unopr valori numerice date de expresii suma.
Sincronizarea pe conditie consta in intarzierea unui proces pana cand este indeplinita o anumita conditie. Aceasta varianta este mult mai des folosita in aplicatiile practice si datorita faptului ca mecanismele de implementare a sincronizarii pe conditie sunt mai bine reprezentate in majoritatea limbajelor de programare cu facilitati pentru concurenta.
Dupa Quinn [1994], exista doua metode de sincronizare: (1) sincronizarea (pentru) de precedenta si (2) sincronizarea pentru excludere mutuala. Sincronizarea de precedenta asigura ca un eveniment nu incepe pana cand un altul nu s-a incheiat. Sincronizarea pentru excludere mutuala asigura ca, la un moment dat, numai un proces intra in sectiunea critica a codului cu care se prelucreaza datele partajate.
Din considerente practice s-a ajuns la necesitatea ca, in contexte concrete, o secventa de instructiuni din programul de cod al unui proces sa poata fi considerata ca fiind indivizibila. Prin proprietatea de a fi indivizibila intelegem ca odata inceputa executia instructiunilor din aceasta secventa, nu se va mai executa vreo actiune, dintr-un alt proces, pana la terminarea executiei instructiunilor din acea secventa. Aici trebuie sa subliniem un aspect fundamental si anume ca aceasta secventa de instructiuni este o entitate logica care este accesata exclusiv de unul dintre procesele curente. O astfel de secventa de instructiuni este o sectiune critica logica. Deoarece procesul care a intrat in sectiunea sa critica exclude de la executie orice alt proces curent, rezulta ca are loc o excludere reciproca (mutuala) a proceselor intre ele. Daca executia sectiunii critice a unui proces impune existenta unei zone de memorie pe care acel proces sa o monopolizeze pe durata executiei sectiunii sale critice atunci acea zona de memorie devine o sectiune critica fizica sau resursa critica. De cele mai multe ori, o astfel de sectiune critica fizica este o zona comuna de date partajate de mai multe procese.
Problema excluderii mutuale este legata de proprietatea sectiunii critice de a fi atomica, indivizibila la nivelul de baza al executiei unui proces. Aceasta atomicitate se poate atinge fie valorificand facilitatile primitivelor limbajului de programare gazda, fie prin mecanisme controlate direct de programator (din aceasta a doua categorie fac parte algoritmii specifici scrisi pentru rezolvarea anumitor probleme concurente).
Problema excluderii mutuale apare deoarece in fiecare moment cel mult un proces poate sa se afle in sectiunea lui critica. Dupa Andrews [1991], excluderea mutuala este o prima forma de sincronizare, ca o alternativa pentru sincronizarea pe conditie.
Problema excluderii mutuale este una centrala in contextul programarii concurente. Rezolvarea problemei excluderii mutuale depinde de indeplinirea a trei cerinte fundamentale si anume:
excluderea reciproca propriu-zisa - care consta in faptul ca la fiecare moment de timp cel mult un proces se afla in sectiunea sa critica;
competitia constructiva, neantagonista - care se exprima astfel: daca nici un proces nu este in sectiunea critica si daca exista procese care doresc sa intre in sectiunile lor critice atunci unul dintre acestea va intra efectiv;
conexiunea libera intre procese - care se exprima astfel: daca un proces "intarzie" in sectiunea sa necritica atunci aceasta situatie nu trebuie sa impiedice alt proces sa intre in sectiunea sa critica (daca doreste acest lucru).
Indeplinirea conditiei a doua asigura ca procesele nu se impiedica unul pe altul sa intre in sectiunea critica si nici nu se invita la nesfarsit unul pe altul sa intre in sectiunile critice. In conditia a treia, daca "intarzierea" este definitiva, aceasta nu trebuie sa blocheze intregul sistem (cu alte cuvinte, blocarea locala nu trebuie sa antreneze automat blocarea globala a sistemului).
Excluderea reciproca (mutuala) fiind o un concept central, esential al concurentei, in paragrafele urmatoare vom reveni asupra rezolvarii acestei probleme la diferite nivele de abstractizare si folosind diferite primitive. Principalele abordari sunt:
folosind suportul hardware al sistemului gazda: rezolvarea excluderii mutuale se face cu TAS-uri; aceste primitive testeaza si seteaza variabile booleene (o astfel de variabila este asociata unei resurse critice); un TAS nu este o operatie atomica;
folosind arbitrajul memoriei comune: solutia vizeaza sectiunile critice si nu resursele critice (cum s-a lucrat la nivelul TAS-urilor); la acest nivel aplicatiile folosesc semafoare;
folosind suportul software: rezolvarea excluderii mutuale se bazeaza pe facilitatile oferite de limbajele de programare pentru comunicarea si sincronizarea proceselor executate nesecvential.
Un grup de procese concurente se spune ca sunt interblocate daca fiecare detine resurse comune care trebuie sa fie alocate de alte procese pentru a-si continua executia. [Quinn, 1994]
Interblocarea poate aparea ori de cate ori mai multe procese partajeaza resurse intr-o maniera nesupervizata. De aici rezulta ca interblocarea poate sa apara atat in sisteme care opereaza in multiprogramare, cat si in sistemele multicalculator si multiprocesor.
Cand un proces isi aloca o resursa se spune ca blocheaza acea resursa. Operatiile LOCK si UNLOCK corespund operatorilor P si V definiti de Dijkstra pentru semafoarele binare [Dijkstra, 1968].
Exemplul 1. Intr-un sistem multiprocesor poate aparea urmatoarea situatie de interblocare in care sunt implicate doua procese, Proces 1 si Proces 2 si doua resurse, A si B:
|
Proces 1 LOCK (A) LOCK (B) |
Proces 2 LOCK (B) LOCK (A) |
Atat timp cat fiecare proces are acces exclusiv la o resursa ceruta (solicitata) de celalalt proces, nici unul nu-si poate continua activitatea. |
Exemplul 2. Intr-un sistem multicalculator poate sa apara un caz particular de interblocare si anume cea de tip buffer deadlock. Sa consideram un sistem multicalculator in care procesele comunica sincron. Aceasta inseamna ca atunci cand un proces E trimite un mesaj catre un alt proces, D, expeditorul E se blocheaza in asteptarea confirmarii de la destinatarul D. In aceasta situatie, la expediere, mesajul este depus intr-un buffer de mesaje ale destinatarului. Presupunem ca mai multe procese au trimis mesaje catre D, acesta nu le‑a preluat la timp si bufferul este plin. Cat timp D nu citeste mesaje (deci nu‑si descarca bufferul), nici un mesaj trimis catre D nu va mai putea fi receptionat si toate procesele expeditor sunt blocate in asteptarea confirmarii. Fie I un proces care incearca sa trimita mesaje catre D cat timp bufferul este plin. Daca D asteapta sa citeasca CU PRIORITATE mesaj de la I atunci procesul D se va bloca in asteptarea mesajului de la I. La randul lui, procesul I este deja blocat in asteptarea confirmarii de la D. Rezulta ca cele doua procese sunt interblocate datorita umplerii bufferului de receptionare a mesajelor.
In general, interblocarea poate aparea daca:
sistemul trebuie sa asigure excludere mutuala a proceselor la accesul pe resurse comune;
sistemul nu respecta conditia de preemption (previziune, prioritate): un proces nu elibereaza resursele pe care le detine pana cand nu le-a utilizat pe toate;
sistemul trebuie sa respecte conditia de resource waiting: fiecare proces detine resursele cat timp asteapta ca alte procese sa le elibereze pe ale lor;
exista un lant de procese in asteptare: fiecare proces asteapta sa se elibereze resursele pe care le detine un alt proces din lant.
Indiferent de tipul de sistem nesecvential, acesta trebuie sa fie prevazut cu mecanisme specifice pentru detectarea interblocarii. Cu alte cuvinte, interblocarea este o stare curenta a sistemului care trebuie evitata.
Rezolvarea problemei interblocarii poate fi privita in trei moduri:
prima abordare este sa se detecteze aparitia interblocarii si sa se incerce refacerea contextului anterior interblocarii;
a doua abordare este sa se evite interblocarea prin utilizarea IN AVANS a informatiilor referitoare la cererile de resurse, astfel incat sa se realizeze un control al alocarii resurselor care sa PREINTAMPINE aparitia interblocarii;
a treia abordare este sa se previna interblocarea prin a interzice aparitia situatiilor 2, 3 sau 4 anterioare.
Diversitatea sistemelor concurente a impus dezvoltarea mecanismelor de lucru in astfel de sisteme, astfel incat fiecare sistem sa-si poata impune si valorifica propriile caracteristici legate de comunicarea si sincronizarea elementelor componente.
Astfel, se pot deosebi o serie de sisteme potrivite din punct de vedere practic pentru a comunica prin memorie partajata, in timp ce altele, din contra, nu-si respecta caracteristicile daca ar adopta comunicarea prin memorie partajata. Iata cateva exemple.
Aplicatii care accepta comunicarea prin memorie partajata:
a) aplicatii pentru un sistem neprotejat, cum sunt cele dezvoltate pentru un grup de calculatoare distincte; aici toate procesele si sistemul de operare ruleaza intr-un acelasi spatiu de adresa sau folosesc adrese fizice, nemapate ale masinilor;
b) un program care sa ruleze intr-un spatiu de adresa separat, peste un sistem de operare, in care (1) mecanismele de multi-thread sunt furnizate numai de limbaj sau (2) procesele multi-thread sunt cunoscute la nivelul sistemului de operare; un exemplu pentru aceasta situatie este un server care deserveste mai multi clienti;
c) un program care implementeaza un modul al sistemului de operare; aici exemplele frecvente sunt pentru UNIX.
O aplicatie care recunoaste comunicarea prin memorie partajata va rula pe un sistem uniprocesor sau pe unul multiprocesor cu memorie partajata, dar este de asteptat sa aiba diverse comportari si performante pe medii de lucru diferite.
Aplicatii care sunt mai potrivite in sisteme fara memorie partajata:
a) aplicatii pentru un sistem protejat, de exemplu un sistem multiutilizator, in care procesele se executa in spatii de adresa distincte; aici sunt incluse sistemele cu comunicare client-server peste un micronucleu;
b) aplicatiile de comunicare intre procese situate pe masini distincte, de exemplu in sistemele de control la nivel de proces;
c) aplicatii pentru sisteme in care este importanta mentinerea flexibilitatii asupra locului in care se incarca procesele. Procesele care folosesc mecanisme IPC cu memorie partajata sunt restrictionate sa se incarce pe aceeasi masina, in timp ce cele care folosesc mecanisme IPC nespecifice memoriei partajate se pot incarca atat pe masina gazda cat si pe masini la distanta;
d) aplicatii pentru sisteme care au facilitati de migrare a proceselor pentru a asigura o incarcare echilibrata si corecta a proceselor pe diverse masini.
Pentru programarea acestor clase de sisteme vom lua in discutie in paragrafele urmatoare o serie de mecanisme de implementare a concurentei la nivel low-level sau la nivelul limbajelor de programare de nivel inalt. Elementele discutate se vor axa pe prezentarea mecanismelor de comunicare intre procese (IPC, Inter Process Communications), la diferite nivele de abordare.
In Figura 13 este reprezentata evolutia mecanismelor si primitivelor IPC.
Variantele IPC cu sau fara memorie partajata se regasesc in doua modalitati duale de abordare a comunicarii si anume: procesul activ fie apeleaza o procedura de interfata a unui modul pasiv (monitor), fie trimite un mesaj in care formuleaza o cerere specifica. Aceste alternative se incadreaza intr-o clasificare mai generala a mecanismelor IPC de nivel inalt care deosebeste:
mecanisme IPC pentru transmiterea de mesaje (message passing)
a) transmitere asincrona sau cu zone tampon;
b) transmitere sincrona sau fara zone tampon;
mecanisme IPC procedurale
a) apel de procedura pentru obiecte pasive, lucrul cu monitoare;
b) apel de procedura pentru obiecte active, mecanismul cu rendez-vous.
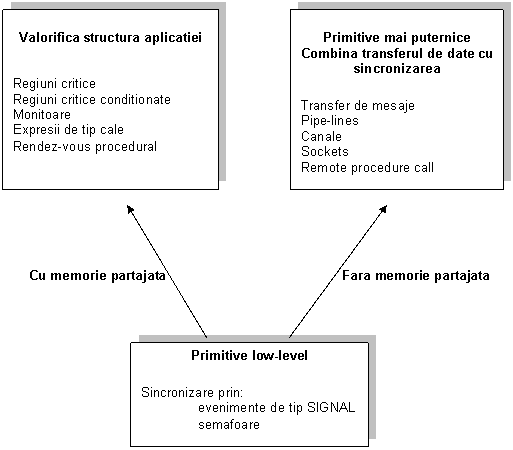
Figura 13 Evolutia primitivelor IPC
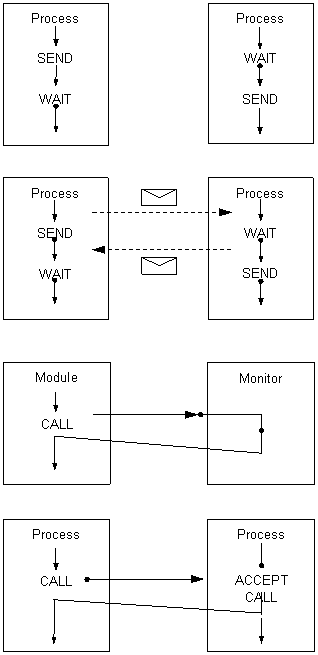
In Figura 14 sunt descrise cele mai reprezentative mecanisme IPC de nivel inalt.
O clasa superioara de mecanisme IPC este data de modalitatile de comunicare distribuita intre procese (Distributed IPC). Acestea apar ca necesare in sistemele hard si/sau soft distribute si, implicit, trebuiesc privite si analizate prin prisma structurilor sistemelor pe care le deservesc. Din acest punct de vedere este de remarcat modelul client-server de implementare a aplicatiilor distribuite, care este in stransa legatura atat cu suportul fizic si logic de comunicare disponibil in sistem, cat si cu limbajul pe care sistemul respectiv il suporta. O alternativa la abordarea client-server este modelarea obiectuala a sistemelor. Aceasta aplica tehnologia programarii orientate obiect, OOP, la nivelul sistemelor prin interpretarea fiecarei resurse partajate ca un obiect [Coulouris, 1999].
Transmitere de mesaje
asincrona sau cu buffer
![]() mesaj
mesaj
posibila intarziere
Transmitere de mesaje
sincrona sau fara buffer
Structura procedurala
pasiva de tip monitor
Structura procedurala
activa de tip rendez-vous
Figura 14 Mecanisme IPC de nivel inalt
In cele ce urmeaza vom lua in discutie unele primitive low‑level (de nivel de baza) utile pentru implementarea sistemelor concurente. Conform reprezentarii din Figura 13, la acest nivel vom aborda sincronizarea prin evenimente si sincronizarea bazata pe semafoare.
Odata cu descrierea rolului proceselor in implementarea sistemelor concurente, am adus in discutie un mecanism de implementare care permite unui proces cunoscut de sistemul de operare sa se sincronizeze cu un eveniment hardware, de obicei recunoscut printr-un semnal de intrerupere. Ulterior, cerintele pentru interactiunea proceselor au completat aceasta necesitate de sincronizare a proceselor cu componentele hard cu oportunitatea de a considera cerinta ca un proces sa se sincronizeze cu un alt proces.
Coroborand cele doua aspecte, se poate extinde sincronizarea intre procese la sincronizarea la nivel de eveniment, pornind de la urmatoarele doua solutii: (1) fiecarui eveniment hardware ii este asociat cate un proces dedicat; mai mult, se poate impune ca un proces sa astepte (sa receptioneze) mai multe evenimente, dar unui eveniment sa ii corespunda un proces unic; (2) un acelasi eveniment hardware poate fi preluat spre interpretare de catre mai multe procese.
In aceste cazuri operatiile WAIT si SIGNAL se vor aplica pe evenimente si nu pe procese. Astfel, un proces care incearca alocarea pentru sine a unei resurse hardware trebuie sa execute o operatie WAIT(EVENT) prin care asteapta producerea evenimentului EVENT pe care il recunoaste ca reprezinta disponibilizarea resursei solicitate. Procesul respectiv va fi blocat pana la producerea evenimentului. Concret, disponibilizarea resursei consta in executarea unei operatii SIGNAL(EVENT), in urma careia, toate procesele care asteptau producerea evenimentului EVENT se vor debloca. Dintre toate procesele din lista de asteptare, numai unele isi vor continua executia prin alocarea resursei eliberate. Alegerea acestor procese cade in sarcina sistemului de planificare a proceselor.
Deoarece operatiile fundamentale WAIT si SIGNAL se executa pe evenimente, vom spune ca in acest caz sincronizarea proceselor implicate este bazata pe evenimente.
O solutie primara, elementara pentru rezolvarea problemei excluderii mutuale ar putea consta in a asocia fiecarei resurse critice o variabila booleana. Cele doua stari posibile ale acestei variabile vor corespunde starilor FREE, respectiv BUSY ale resursei critice. La intrarea in sectiunea sa critica, un proces care intentioneaza alocarea resursei va testa starea variabilei booleene asociate resursei si va intra in sectiunea critica numai daca a gasit resursa FREE. Un astfel de mecanism este unul de tip Test And Set si consta intr‑o operatie
TAS (BOOLEAN) == if BOOLEAN arata ca regiunea este FREE
then SET regiunea pentru a arata ca este ocupata si executa prima instructiune din sectiunea critica
else executa instructiunea urmatoare sectiunii critice.
Cu acest mecanism se face un pas inainte de la sincronizarea proceselor cu componentele hardware la sincronizarea intre procese, dar inca se apeleaza la elemente hard de tipul resurselor critice pentru realizarea sincronizarii.
Deoarece un TAS( ) nu este o operatie atomica, acest protocol poate conduce la situatii incorecte. De exemplu, un proces A citeste variabila booleana, o gaseste FREE, o seteaza la valoarea corespunzatoare starii BUSY a resursei si intra in sectiunea lui critica. Un proces B poate sa citeasca variabila booleana a aceleiasi resurse intre momentul in care A a citit si el variabila si cel in care A a apucat sa modifice valoarea la BUSY. Atunci B gaseste si el resursa FREE si poate intra in sectiunea lui critica. Astfel, atat A cat si B sunt simultan in executia sectiunilor critice la nivelul resursei comune, ceea ce este incorect, conform cu definitia sectiunii critice (la un moment dat, cel mult un proces este in sectiunea sa critica).
Rezulta ca simpla asociere a unei variabile booleene unei resurse partajate este inca insuficienta pentru rezolvarea problemei excluderii mutuale.
In cele ce urmeaza admitem ca componentele hardware ale sistemului nu ofera nici un suport pentru realizarea sincronizarii proceselor, deci nu se mai poate vorbi de testarea starii unei resurse critice partajata de procesele care trebuie sa se sincronizeze.
Specificul mecanismelor de sincronizare prezentate in continuare este faptul ca se pune accentul pe sectiunea critica (secventa de cod care poate fi accesata in mod unic) si nu pe resursa critica partajata. Astfel, pentru executia unui proces oarecare putem pune in evidenta sectiunea sa critica enumerand etapele executiei dupa cum urmeaza:
executa sectiune ne-critica
executa un protocol de intrare in sectiunea critica
executa sectiunea critica
executa un protocol de iesire din sectiunea critica
executa sectiune ne-critica.
In acest mecanism, sincronizarea se face la nivelul protocoalelor de intrare si iesire din sectiunea critica. Este o sincronizare bazata pe partajarea memoriei comune deoarece, in general, protocoalele de intrare/iesire sunt secvente de instructiuni care gestioneaza memoria comuna pentru indeplinirea conditiilor fundamentale care asigura excluderea mutuala (excluderea mutuala propriu-zisa, competitia constructiva si conexiunea libera a proceselor).
Pe baza acestui mecanism s-au dezvoltat o serie de algoritmi fundamentali pentru sincronizarea proceselor si, implicit, pentru rezolvarea problemei excluderii mutuale intre procese. Cativa dintre acesti algoritmi se datoreaza lui Dijkstra, Dekker, Eisenberg si McGuire, Peterson, Lamport [Georgescu, 1996], [Bacon, 1998], [Andrews, 1991].
In general, protocoalele de intrare/iesire din sectiunea critica introduc variabile de control cu diverse semnificatii: (a) variabile globale intregului sistem, deci accesate de toate procesele active, (b) variabile asociate cate una pentru un proces, deci valoarea unei variabile poate fi modificata numai de procesul asociat ei, dar poate fi citita si interpretata si de alte procese, (c) situatii combinate.
Aceste solutii bazate pe memoria comuna au unele inconveniente care pot chiar sa elimine posibilitatea folosirii unor astfel de algoritmi in sisteme concurente particulare. Astfel, solutiile sunt complicate datorita faptului ca presupun ca programatorul sa gestioneze cu mare atentie valorile curente ale variabilelor de control, iar o utilizare incorecta poate conduce chiar la blocarea intregului sistem (deadlock). Mai mult, algoritmii care folosesc variabile comune ale caror valori pot fi actualizate de catre mai multe procese devin inutilizabili in sistemele distribuite deoarece aici nu exista o zona de memorie comuna tuturor nodurilor, zona de memorie care sa stocheze astfel de variabile.
Fata de aceasta modalitate de sincronizare prin memoria comuna, in cele ce urmeaza se vor descrie mecanisme care folosesc facilitatile limbajelor de programare scrise tocmai pentru eliminarea acestor neajunsuri.
Notiunea de semafor a fost introdusa in 1968 de Dijkstra [Dijkstra, 1968] o data cu descrierea proiectului de sistem de operare numit THE (Technische Hogeschool Eindhoven). Sistemul THE proiecteaza o ierarhie de resurse virtuale gestionata de un sistem de procese strict organizate pe nivele. Sistemul THE este impartit pe sapte nivele, fiecare nivel fiind compus dintr-o colectie de obiecte abstracte si o multime de reguli care le guverneaza. Regulile sunt materializate in proceduri numite operatii primitive. Structura interna a unui obiect la un nivel dat este invizibila la alt nivel, dar poate fi exprimata folosind obiectele si operatiile de la nivelele inferioare.
Asa cum a fost introdus de Dijkstra, un semafor este un tip de date. Asupra unei variabile de tip semafor se pot executa operatiile WAIT(SEMAFOR) si SIGNAL(SEMAFOR) numite in acest context si primitive. Aceasta denumire este justificata si de faptul ca aceste operatii sunt atomice la nivelul semafoarelor pe care sunt apelate. Mai mult, aceasta proprietate permite semafoarelor sa fie utilizate cu succes in rezolvarea problemei excluderii mutuale.
Se observa extinderea aplicarii operatiilor elementare pentru sincronizare, WAIT si SIGNAL, de la nivelul proceselor si al evenimentelor la nivelul variabilelor semafor. Aplicarea acestor operatii la nivel de proces presupune identificarea proceselor printr-un nume unic si, de aceea, apelurile WAIT si SIGNAL permit numai sincronizarea unor procese organizate de o maniera statica, in care comunicarea se face numai unu-la-unu. Aceste inconveniente sunt depasite de apelurile WAIT si SIGNAL pe semafoare deoarece un apel WAIT(SEMAFOR) poate fi executat de mai multe procese pentru a astepta dupa unul sau mai multe procese de semnalizare, in timp ce un apel SIGNAL(SEMAFOR) poate fi executat de mai multe procese pentru a semnaliza un proces in asteptare.
Reprezentarea specifica a tipului semafor este data printr-un numar natural (intreg pozitiv) si o coada atasata operatiei WAIT(SEMAFOR), dar despre disciplina de coada nu se precizeaza nimic [Georgescu, 1996]. Daca valorile pe care le poate lua o variabila semafor sunt numai 0 si 1 atunci semaforul este unul binar. Cele doua tipuri de date, semafoarele generale si semafoarele binare, sunt echivalente [Georgescu, 1996].
Definitiile operatiilor cu semafoare sunt urmatoarele:
WAIT(SEMAFOR == if valoarea lui SEMAFOR este nenula (pozitiva)
then se micsoreaza cu o unitate aceasta valoare si se trece la executarea instructiunii urmatoare
else procesul care executa aceasta operatie este blocat la semaforul SEMAFOR.
SIGNAL(SEMAFOR) == if exista procese blocate la semaforul SEMAFOR
then se deblocheaza unul dintre ele
else se mareste valoarea lui SEMAFOR cu o unitate.
Atomicitatea primitivelor WAIT() si SIGNAL() consta in faptul ca operatiile interne corespunzatoare acestor primitive sunt indivizibile. Astfel, pentru un apel WAIT(), succesiunea comparare + decrementare este indivizibila, iar pentru un apel SIGNAL(), succesiunea comparare + deblocare sau comparare + incrementare sunt, de asemenea, indivizibile.
Este foarte important de subliniat ca in timp ce doua operatii asupra aceluiasi semafor se executa prin excludere mutuala, pentru doua operatii asupra unor semafoare distincte este posibila suprapunerea executarii lor.
Putem privi un modul de gestiune a semafoarelor ca un TAD manager care poate fi localizat la nivelul sistemului de operare - pentru semafoarele raspunzatoare de procesele sistem - sau la nivelul limbajului de programare - pentru celelalte semafoare.
Utilizarea semafoarelor este o modalitate de lucru folosita cu succes in rezolvarea excluderii mutuale a proceselor concurente, in sincronizarea proceselor cooperative, in instantierea multipla a unei resurse partajate.
In capitolele urmatoare vom reveni cu exemple pentru utilizarea semafoarelor.
Implementarea operatiilor cu semafoare trebuie sa rezolve probleme legate de concurenta la nivelul semafoarelor, planificarea cozii asociate operatiei WAIT prin metode specifice (inversarea prioritatii, mostenire).
Este de remarcat rolul semafoarelor in realizarea comunicarii intre procese. Astfel, semafoarele devin un mijloc real de implementare a mecanismelor IPC. Totusi, daca consideram ca semaforul este singurul mecanism de tip IPC al unui limbaj de programare, atunci inca pot apare o serie de probleme specifice care pun in evidenta dezavantaje ale folosirii semafoarelor, cum ar fi:
se poate gresi usor in programarea semafoarelor: daca programatorul uita sa foloseasca apelul WAIT atunci, accidental, poate sa acceseze date partajate neprotejate; sau daca programatorul uita sa execute un apel SIGNAL atunci poate sa lase o structura de date blocata indefinit;
nu este posibil sa avem o lista de semafoare ca argument pentru WAIT; daca aceasta ar fi acceptata atunci ar putea fi programate diferite variante de ordonare a actiunilor, conform cu starea curenta a sosirii semnalelor de tip SIGNAL.
timpul cat un proces este blocat la un semafor nu este limitat;
nu exista nici un mijloc prin care un proces sa poata controla un alt proces;
daca semafoarele sunt singurul mecanism IPC din sistem si este necesar sa se transmita informatii intre procese atunci, pe langa sincronizarea simpla, procesele ar trebui sa partajeze macar o parte a spatiului de adresa pentru a accesa direct zona de date partajate care poate fi scrisa; valoarea unui semafor poate fi folosita pentru a transmite informatii primare, dar aceste informatii nu sunt accesibile proceselor;
operatiile cu semafoare au un nivel foarte scazut de abstractizare (primitive low-level) si este evidenta lipsa structurarii, conditie obligatorie in programarea moderna;
valoarea semafoarelor nu poate fi controlata decat prin primitivele WAIT() si SIGNAL(). Astfel un semafor nu poate aparea in expresii logice.
Tinand cont de toate aceste probleme, se vede ca un limbaj de programare destinat aplicatiilor concurente trebuie sa detina si mecanisme de tip IPC care sa completeze facilitatile oferite de semafoare. Multe dintre aceste inconveniente se elimina daca situatiile de blocare in asteptare sunt asociate cu posibilitatea de a crea procese-fii care sa continue executia in timp ce parintele ramane in asteptare. Dupa Bacon [1998], alternativele pentru semafoare sunt tipurile de date EVENTCOUNT si SEQUENCER, introduse in [Reed, Kanodia, 1979], precum si bibliotecile de lucru cu threaduri cum ar fi threadurile POSIX [IEEE, 1988]. In plus, putem aminti si tipurile abstracte de date mai evoluate cum este MONITORul (care va fi tratat in paragraful urmator). Tipul monitor a fost introdus in [Hoare, 1974].
O variabila de tip EVENTCOUNT numara aparitiile unui eveniment prin incrementarea indefinita a valorii sale. O astfel de variabila este initializata implicit la pornirea sistemului. Prin operatii specifice, acest tip de date devine disponibil proceselor active din sistem. De exemplu, procesele pot dicta actiuni de executat asupra variabilelor EVENTCOUNT.
O variabila de tip SEQUENCER este folosita pentru a ordona actiunile proceselor concurente. Tipul acesta de date recunoaste o singura operatie specifica.
De-a lungul anilor, UNIX a fost subiectul mai multor incercari de standardizare, cea mai remarcabila fiind cea a comitetului IEEE, POSIX. Acestia au creat standardul IEEE 1003.1 pentru apelurile de sistem UNIX (biblioteca de functii). Standardul POSIX a fost larg raspandit si adoptat. Pentru subiectul acestui material este important pachetul de lucru cu threaduri si suportul threadurilor POSIX pentru sincronizare. Detaliile acestea se gasesc in standardul POSIX 1003.4a despre pthreads [IEEE, 1988]. Threadurile POSIX se executa intr‑un singur spatiu de adresa, prin partajarea acestuia. Pentru sincronizare, sunt furnizate mecanisme bazate pe mutex-uri (mecanisme software de sincronizare a proceselor pentru excluderea mutuala a accesului la resurse partajate) si pe variabile de conditie. Un mutex poate fi privit ca un caz particular de semafor binar. O variabila de conditie permite unui thread sa‑si blocheze propria executie pana cand anumite date partajate intra intr‑o anumita stare.
Un MONITOR are structura unui obiect abstract de date. Datele incapsulate intr‑un monitor sunt partajate si fiecare operatie este executata sub excludere mutuala. Implementarea monitoarelor trebuie sa asigure ca, in fiecare moment, numai un proces este activ in monitorul respectiv. Monitoarele au avantajul de a asigura excluderea mutuala la nivelul operatiilor interne, dar, acolo unde se impune sincronizarea pe conditie, monitoarele pot folosi si variabile de conditie. Asupra notiunii de monitor vom reveni in paragrafele urmatoare.
Operatiile cu primitive low‑level descrise anterior se pot regasi si in limbaje de nivel inalt care isi propun sa suporte aplicatii concurente. Totusi, din limitele semafoarelor (enumerate mai sus) se poate vedea ca numai aceste tipuri de operatii elementare nu pot asigura corectitudinea programelor concurente. Un nivel superior de asistenta ar putea fi asigurat daca programatorul ar putea preciza compilatorului:
a) care sunt datele partajate de procese;
b) care primitiva (semafor, de exemplu) se asociaza cu care date partajate;
c) unde sunt localizate in program zonele critice de acces la datele partajate.
In acest caz, compilatorul ar trebui sa poata sa verifice si sa asigure ca datele partajate sunt accesibile numai intr‑o anumita zona critica, ca zonele critice sunt accesate si parasite de procese de o maniera corecta.
Principalele mecanisme IPC care valorifica proprietatea aplicatiei de a folosi memoria partajat sunt: sectiunile critice, expresiile de tip cale si mecanismele procedurale de tip monitor (obiect pasiv) sau rendez-vous procedural (entitate activa).
Pentru cazul memoriei partajate sunt necesare restrictii suplimentare asupra limbajului de programare, de exemplu:
orice tip de data sa recunoasca atributul shared (partajat);
limbajul sa recunoasca o declaratie de sectiune, region¸ de forma:
region <shared_data> begin
end
Se delimiteaza astfel sectiunile critice la nivel logic, adica la nivelul limbajului de programare.
De exemplu, folosind aceasta structura, compilatorul poate crea cate un semafor pentru fiecare declaratie de date partajate si poate insera o operatie WAIT SEMAFOR) la inceputul regiunii critice si o operatie SIGNAL(SEMAFOR) la sfarsitul regiunii critice.
Pentru gestionarea proceselor care concura la alocarea unei resurse sau a proceselor care coopereaza pentru indeplinirea unei sarcini comune, limbajul concurent trebuie sa beneficieze de operatii suplimentare, cum ar fi accesul gardat (conditionat) la resursa partajata sau utilizarea sectiunilor critice conditionate. De exemplu, pentru sincronizare cu sectiuni critice conditionate, fiecarei sectiuni critice conditionate i se asociaza logic o operatie de tip AWAIT(CONDITIE
Concret, primitivele de al nivelul limbajului de programare destinate sincronizarii accesului la datele partajate sunt monitoarele si extinderile acestora.
Asa cum am aratat si anterior, un monitor are structura unui obiect de date abstract, care incapsuleaza date si operatii [Hoare, 1974]. Datele incapsulate intr‑un monitor sunt partajabile, iar fiecare operatie este executata sub excludere mutuala. Din aceste considerente rezulta imediat trei avantaje importante ale monitoarelor si anume: (1) monitoarele introduc posibilitatea modularizarii aplicatiilor concurente, (2) executarea unei sectiuni critice la nivelul unui proces se poate lansa prin apelul unei metode a unui monitor si (3) monitoarele rezolva prin definitia lor problema excluderii mutuale a accesului la sectiunile critice.
Pe langa asigurarea excluderii mutuale, pentru rezolvarea problemelor ce apar in aplicatiile concurente mai trebuie completate mecanisme pentru sincronizarea pe conditie (sau conditionata). In limbajele cu monitoare aceasta problema este rezolvata prin introducerea unui tip de date special pentru variabilele de conditie. Programatorul declara o variabila de conditie necesara aplicatiei si modulul de gestionare a monitoarelor va defini o coada asociata variabilei respective. Mai mult, gestionarea monitoarelor se refera implicit si la gestionarea acestor cozi astfel incat, impreuna cu protocolul de organizare a proceselor care solicita accesul la monitor, sa se asigure sincronizarea proceselor intre ele cu respectarea conditiilor asociate variabilelor de conditie definite.
Asupra variabilelor de conditie sunt recunoscute operatiile WAIT si SIGNAL cu urmatoarele semnificatii: WAIT determina autointarzierea procesului care apeleaza WAIT(VAR_COND) prin depunerea lui in coada asociata lui VAR_COND; ulterior, acest proces este eliberat de catre un alt proces care executa o operatie SIGNAL(VAR_COND) asupra aceleiasi variabile de conditie. Daca exista mai multe procese care asteapta la VAR_COND atunci sigur unul este eliberat. Implicit, SIGNAL nu are efect daca coada lui VAR_COND este vida.
Observatie. Un semafor se reprezinta printr‑un intreg si o coada, in timp ce o variabila de conditie se reprezinta numai printr‑o coada de asteptare. De aici rezulta doua imbunatatiri ale limitelor semafoarelor: (1) nu se pune problema semnalelor SIGNAL de tip "wake‑up waiting" si (2) procesul care executa WAIT este depus neconditionat in coada de asteptare a variabilei de conditie.
Monitoarele sunt structuri pasive care permit proceselor active care le apeleaza metodele sa se succeada pentru a obtine cooperarea si/sau competitia cu alte procese. Prin mecanisme specifice, monitoarele organizeaza cozi pentru resursele partajate si gestioneaza buffere de comunicare intre diferite tipuri particulare de procese active (de exemplu, producator - consumator, cititor - scriitor).
Monitoarele sunt modelul de sincronizare folosit in Java. Vom reveni asupra acestui aspect in paragraful Suportul Java pentru concurenta.
Un monitor incapsuleaza o singura structura de date partajate. Pentru cazul in care exista mai multe obiecte de un anumit tip de date partajate, lucrul cu monitoare impune ca odata cu blocarea accesului la datele partajate sa se blocheze implicit accesul la toate obiectele de date partajate. Uneori aceasta solutie este convenabila, dar exista si situatiii in care ea este prea restrictiva.
De exemplu, pentru un modul de gestionare a fisierelor, operatiile elementare open, close, read, write pot fi asociate cu tipul file. Fiecare fisier poate fi subiectul unei excluderi de tip mai multi cititori - un scriitor. Daca pentru implementarea acestui modul de gestionare a fisierelor se foloseste un monitor pentru toate fisierele atunci apare o restrictie prea puternica si anume: numai un proces poate executa codul monitorului la un moment dat, deci se interzice implicit accesul simultan a mai multor cititori la fisiere. Este de preferat urmatoarea solutie: in loc ca o singura blocare sa protejeze intrarea in monitor, o blocare sa fie asociata cu obiectul de date fisier.
Se obtine astfel o generalizare si o imbunatatire a lucrului cu monitoare, bazata pe excluderea pe obiect. Fiecare apel la managerul de obiecte partajate trebuie sa aiba ca argument identificatorul objet_ID al obiectului care se doreste a fi alocat/blocat. Instantierea fiecarui obiect trebuie sa recunoasca o metoda de blocare. Daca implementarea blocarii foloseste un semafor atunci operatiile de la nivelul semaforului pot fi folosite pentru a asigura accesul exclusiv la obiecte. Blocarea poate fi transparenta sau nu programatorului.
Daca sincronizarea proceselor se face cu monitoare atunci un proces care intentioneaza sa execute o operatie asupra unor date partajate trebuie sa apeleze o metoda a unui monitor si abia dupa aceasta (eventual dupa un timp de asteptare) poate sa intre in monitor. Odata intrat in monitor, procesul poate fi in continuare intarziat daca nu este permisa prelucrarea datelor solicitate. O solutie pentru aceasta situatie sunt operatiile cu variabile conditionate, deci primitive low‑level echivalente cu lucrul cu evenimente sau cu semafoare, care sunt dificil de programat corect si solicita o serie de restrictii de lucru cu operatiile WAIT si SIGNAL.
O alternativa buna pentru aceasta solutie este sa se coboare problema sincronizarii la nivelul operatiilor obiectelor. In acest caz se decide continuarea executiei unei operatii numai daca starea obiectului respectiv permite executarea acelei operatii. Astfel, intarzierea inceperii executiei operatiei ar putea acoperi atat intarzierea intrarii in monitor a procesului de initializare a operatiei, cat si intarzierile de sincronizare in interiorul monitorului.
O varianta de sincronizare la nivelul
operatiilor este lucrul cu expresii de tip cale, path
expressions [
Asa cum a fost introdus anterior, monitorul este o structura pasiva de date al carei cod este executat numai prin intermediul unui proces activ care apeleaza acel monitor. Daca unui proces i se asociaza in mod unic o anumita structura de tip monitor atunci acel proces va fi restrictionat la a executa numai codul monitorului respectiv, indiferent care este procesul apelant.
Acest scenariu poate fi extins prin utilizarea obiectelor active, care coboara nivelul de luare a deciziilor la nivelul obiectului partajat. Se impune atunci existenta unui gestionar de obiecte active, care sa poata determina starea fiecaruia dintre obiectele partajate pe care le gestioneaza si care poate decide care este operatia urmatoare care se executa asupra obiectului respectiv. Utilizatorii obiectului executa apeluri de procedura similare cu apelurile de metode ale monitorului.
Un avantaj al lucrului cu obiecte active consta in faptul ca in acest fel se asigura sincronizarea la nivelul operatiilor si, in plus, operatiile exportate catre procesul apelant sunt minimale, in sensul ca ele intarzie procesul apelant un timp mult mai redus.
Cand gestionarul de obiecte este gata sa accepte un apel extern, el trebuie sa decida care set de operatii este pregatit sa preia acel apel. Daca apar situatii nedeterministe atunci si alegerea setului de operatii va fi una nedeterminista. Acest stil de control al concurentei se bazeaza pe mecanismul de lucru cu comenzi gardate [Dijkstra, 1975]. O schema de acest tip a fost propusa de Brinch Hansen [1978] pentru limbajul numit Distributed Processes si este folosita de limbajul ADA. Aici mecanismele de lucru specifice cu obiecte active sunt: ACCEPT, SELECT si RENDEZVOUS. [Welsh, Lister, 1981]
In paragrafele anterioare s-au identificat diferite situatii in care este de preferat ca procesele active sa partajeze memoria. De exemplu, un server pentru mai multi clienti este implementat convenabil prin mai multe procese server (sau threaduri) care partajeaza un acelasi spatiu de adresa.
De asemenea, s-au remarcat o serie de primitive IPC (Inter Process Communications) folosite de procese pentru a impune caracterul concurent la nivelul low-level (semafoare, cozi de evenimente, numaratoare de evenimente, variabile de secventiere) sau la nivelul limbajelor de programare de nivel inalt.
Chiar si procesele care alcatuiesc sistemele concurente si care ruleaza in spatii de adresa distincte (nu partajeaza date) au nevoie sa acceseze uneori informatii comune. Cele mai frecvente situatii de acest tip sunt cazurile in care procesele trebuie sa coopereze pentru a atinge un scop comun sau, din contra, concura pentru acces la resurse comune in sistem. De aici se vede ca mecanismele IPC se impun ca necesare si in sistemele de procese care nu partajeaza zone de memorie comune. Se deosebesc astfel doua abordari IPC si anume:
datele sunt trecute ("pasate") de la un proces la altul conform cu mecanismul de legare in pipeline;
informatia comuna este gestionata de un proces dedicat. Aici, procesul gestionar va prelua operatiile asupra datelor pe care le incapsuleaza, conform cu cererile primite de la alte procese. Acest scenariu este specific modelului client - server de gestionare a proceselor, care suporta atat cooperarea cat si competitia intre procese. Procesul server gestioneaza o resursa partajata pe care o aloca la cerere proceselor client.
Atat legarea proceselor in pipeline cat si modelul client-server suporta transferul datelor intre procese, dar de o maniera fundamental diferita. Astfel, legarea in pipe transporta datele circular intre procesele legate, in timp ce modelul client-server impune ca o prima actiune sa fie lansarea unei cereri care sa contina informatii legate atat de operatia de efectuat, cat si de datele asupra carora se va executa operatia respectiva.
Reanalizand Figura 13, se poate spune ca abordarea cea mai generala a primitivelor de limbaj fara partajarea memoriei presupune atat sincronizare cat si transfer de date. Concret, avem doua modalitasi de exploatare: (1) flux de date sincron si (2) transfer de mesaje.
Mecanismul de lucru cu un flux de date sincron presupune ca un proces poate trimite octeti intr-un flux nestructurat si un alt proces poate citi octeti de pe fluxul respectiv. In acest caz, pe flux nu sunt puse informatii despre structura octetilor sau despre tipul de date transferate pe flux. O aplicatie acare foloseste un astfel de mecanism trebuie sa poata interpreta datele de pe flux conform cu o structura definita a-priori, in timp ce sistemul insusi NU cunoaste aceasta structura si nici nu ofera suport pentru aceasta.
Transferul de mesaje este un mecanism de lucru puternic inrudit cu transferul informatiilor care insoteste transmiterea parametrilor la apelul de procedura. Aici mesajul contine un antet si un corp, fiecare cu functiuni bine delimitate in structura mesajului. Astfel, antetul (header) contine destinatia informatiei continute de mesaj, iar corpul mesajului (body) contine informatia propriu-zisa si argumentele de transfer. Aceste argumente pot sa fie supuse sau nu unor etape de validare a mesajului.
In functie de anumite conditii pe care le indeplinesc procesele care comunica prin transfer de mesaje, acesta poate fi sincron sau asincron.
Programele concurente care angajeaza transfer de mesaje sunt numite programe distribuite. [Andrews, 1991]
Exista patru tipuri de procese intr-un program distribuit:
filtru - procese care preiau, prelucreaza, depun date;
client - procese care solicita servicii;
server - procese care ofera servicii;
peer (egal, pereche, seaman) - un proces peer este fiecare dintre procesele identice care interactioneaza pentru a furniza un serviciu sau pentru a rezolva o problema.
O clasificare detaliata a proceselor de tip server se poate gasi in [Boian, 1999]
De exemplu, doua procese peer ar putea fiecare sa gestioneze o copie a unui fisier replicat si sa interactioneze pentru a se pastra consistenta datelor copiilor. Un alt exemplu de procese peer ar putea fi cele care interactioneaza pentru rezolvarea unei probleme de programare paralela in care fiecare proces rezolva o parte a problemei.
Atat transmiterea asincrona de mesaje cat si cea sincrona sunt mecanisme suficient de puternice pentru a programa toate tipurile de procese: filtre, clienti, servere, peers. Pentru comunicarea unidirectionala specifica filtrelor si proceselor peers, canalele se dovedesc un mijloc potrivit de realizare a comunicarii. Mai mult, folosind doua canale de mesaje diferite, se poate implementa corect si comunicarea intre procese de tip client- server. Daca, in plus, un client solicita mai multe raspunsuri atunci lui i se pot aloca mai multe canale de comunicare.
Detaliind clasificarea introdusa in paragraful Comunicarea datelor in sisteme concurente, principalele mecanisme IPC pentru transmiterea de mesaje sunt: porturile, canalele, mecanismele broadcast si multicast - pentru comunicarea asincrona si, respectiv, sincronizarea simpla (mecanismul rendez-vous) si invocarea la distanta (rendez‑vous extins, Remote Procedure Call) - pentru comunicarea sincrona. In limbajele de programare moderne, implementarea se bazeaza pe suportul mecanismului de comunicare prin sockets.
Modalitatea asincrona de transmitere a mesajelor este varianta generala, care nu impune restrictii de timp asupra sincronizarii proceselor care comunica prin transfer de mesaje.
Dupa cum am anticipat anterior, structura tipica a unui mesaj consta dintr‑un antet si corpul mesajului. La randul lui, antetul este format din informatii referitoare la destinatarul mesajului, informatii referitoare la expeditorul mesajului si informatii referitoare la tipul mesajului. Aici, prin expeditor si destinatar ne referim la procesele care comunica printr-un mesaj oarecare, adica la procesul care trimite mesajul, respectiv la procesul care receptioneaza mesajul (sau procesul caruia ii este adresat mesajul).
Pentru ca transferul mesajelor sa fie functional, in sistem trebuie sa existe un serviciu direct raspunzator de lucrul cu mesaje. Acest serviciu de transport al mesajelor foloseste antetul fiecarui mesaj pentru a identifica tipul mesajului si procesele partenere care comunica. In plus, acest serviciu poate stabili si urmari respectarea unor protocoale de comunicare intre procese.
Primitivele specifice de lucru pentru transmiterea de mesaje sunt grupate in perechile: SEND si WAIT, respectiv SEND si RECEIVE.
Daca consideram cazul a doua procese A si B care comunica la un moment dat prin transmitere de mesaje atunci actiunile celor doua procese sunt urmatoarele:
Procesul A - construieste si configureaza mesajul, dupa care
- executa o operatie SEND(destinatar, mesaj
Procesul B - asteapta la punctul de intalnire cu A
- executand operatii WAIT/RECEIVE(expeditor, spatiu_adresa), unde al doilea parametru reprezinta adresa de memorie la care sa se depuna mesajul.
Transmiterea este asincrona tocmai pentru ca procesul A nu asteapta de la procesul B vreun semnal prin care sa i se confime receptionarea mesajului.
Acest scenariu presupune ca procesele care comunica isi cunosc reciproc identitatea (pot sa se numeasca reciproc prin identificatorii transmisi ca parametri) si, in plus, exista un protocol de transmitere de mesaje pe baza caruia expeditorul construieste mesajul de transmis si destinatarul interpreteaza mesajul primit.
Fata de acest model de comunicare, din punctul de vedere al receptorului B, pot aparea cel putin doua cazuri particulare, care sunt frecvent intalnite in practica si, de aceea, trebuiesc luate in considerare la proiectarea unui sistem de transmitere de mesaje. Acestea sunt:
a) daca B nu este gata sa primeasca mesajul (nu a executat inca o operatie WAIT) atunci mesajele destinate lui B pot fi depuse intr-un buffer intermediar;
b) daca B a executat o operatie WAIT, dar nu exista mesaj atunci el poate sa se blocheze in asteptarea unui mesaj sau poate sa-si continue activitatea si sa revina periodic cu executarea primitivei WAIT.
Uneori se impune precizarea timpului maxim de asteptare pentru a evita asteptarea indefinita a receptionarii unui mesaj. Rezolvarea acestei probleme este cu atat mai necesara in sistemele distribuite in care astfel de situatii de intarziere pot sa apara frecvent din cauze obiective legate de faptul ca masina destinatie nu este functionala sau reteaua de comunicatie este supraincarcata. De asemenea, aceasta restrictie se impune in mod deosebit in sistemele in timp real.
In oricare dintre situatii, receptionarea mesajului coincide cu o operatie DUBLA de copiere a mesajului: o copiere din spatiul de adresa al lui A intr-o zona intermediara de lucru si o a doua copiere din zona intermediara in spatiul de adresa al lui B. Se observa ca in acest caz comunicarea se face prin intermediul unei entitati suplimentare (canal, buffer s.a.), cu rol in colectarea mesajelor adresate lui B si gestionate de serviciul de transmitere de mesaje.
In functie de restrictiile care se impun asupra proceselor partenere si asupra datelor transmise putem avea urmatoarele situatii:
procesele care comunica nu vor sau nu trebuie sa-si cunoasca reciproc identitatea;
un proces trebuie sa trimita un mesaj mai multor destinatari;
este necesar sa existe un suport pentru deosebirea mesajelor intre ele; de exemplu, sa se deosebeasca mesajele prin care se adreseaza cereri de mesajele care reprezinta raspunsuri, reveniri (reply) la mesaje anterioare;
procesele sunt dispuse sa astepte mesaje pe mai multe cai;
in anumite conditii, un mesaj poate deveni "expirat" (depasit);
uneori este necesar sa se raspunda la un mesaj nu numai expeditorului ci si altor procese.
Rezolvarea si implementarea acestor situatii a condus la definirea unor notiuni si concepte noi pe care le prezentam in continuare. Implicit, aceste concepte se regasesc in diverse primitive la nivelul fiecarui limbaj de prgramare care le recunoaste.
In interiorul unui modul de program, un mesaj poate fi transmis la o anumita locatie, de exemplu catre o variabila locala a programului respectiv. Daca aceasta locatie este destinata comunicarii programului cu exteriorul lui atunci limbajul programului poate sa o recunoasca ca pe un port de iesire sau un canal de comunicare. In timp ce aceste entitati pot fi stabilite la inceputul programului, locatia care preia mesajul la intrarea in program, adica portul de intrare, se poate stabili numai in timpul configurarii mesajului. In plus, la configurare se stabileste si care este procesul asociat unui anumit port de iesire, respectiv care este procesul care va prelua datele de pe un anumit canal.
Asocierile de tip
port <-> proces
nu sunt neaparat de tip
unu-la-unu. Daca procesul expeditor este la
randul lui un serviciu solicitat atunci este de evitat ca el sa se
blocheze intre transmiterea mesajului si receptionarea
raspunsului corespunzator. Mai mult, uneori este
necesar ca un proces sa poata sa-si organizeze de o
maniera proprie bufferul de mesaje (depunerea si preluarea mesajelor
sosite). Pentru aceste aspecte, procesul poate
sa-si defineasca mai multe porturi de comunicare cu alte
procese, porturi prin care transmite mesaje. Ulterior, procesul isi
va sonda periodic (polling)
porturile de comunicare pentru a testa in timp util sosirea vreunui mesaj.
Acest mecanism este echivalent cu comunicarea intre
obiecte active prin RENDEZ-VOUS implementat in limbajul
De asemenea, asocierile de tip
portIN <-> portOUT
nu sunt neaparat de tip unu-la-unu. De aici rezulta diferite scheme de transmitere de mesaje prin intermediul porturilor sau a canalelor, care confera comunicarii mai multa flexibilitate si totodata permit proiectarea unui sistem mai amplu de mesaje.
In plus, un anumit port poate fi dedicat unui anumit tip de mesaje, caz in care fiecare transfer prin acest port va fi precedat de o validare a tipului de mesaj asociat. Astfel, daca se proiecteaza o comunicare intre procese prin porturi "conditionate" atunci atat la iesire, cat si la intrare, mesajele vor suporta etape de verificare a conditiilor impuse.
Un exemplu de restrictie care se poate impune mesajelor este cea legata de oportunitatea preluarii mesajului respectiv. Din acest punct de vedere, un mesaj poate sa nu mai fie preluat daca el este "depasit" de continutul unui mesaj ulterior. Daca se lucreaza cu porturi dedicate atunci se poate defini dimensiunea bufferului asociat portului respectiv la 1 si politica de ocupare sa fie suprascrierea. Astfel, in orice moment in buffer exista un singur mesaj si anume cel mai recent pe subiectul pe care se comunica prin acel port.
Pentru aspectele legate de
comunicarea conditionata, se poate folosi un
limbaj de configurare a mesajelor astfel incat ele sa indeplineasca
structura impusa de canalele de comunicare. Un
astfel de mecanism este folosit de sistemul CONIC dezvoltat de
Un caz particular de comunicare este de tip (1 din n) la (1 din n). Pentru o astfel de transmitere de mesaje se pot folosi entitati intermediare fara restrictii (free-standing) cum ar fi porturile globale si cutiile postale. Utilitatea acestor locatii este similara cu rolul bufferului de tip banda din comunicarea many-to-many intre procese de tip producator-consumator.
O caracteristica a porturilor globale si a cutiilor postale este faptul ca, in timp ce mai multi (n) expeditori si destinatari pot depune/prelua mesaje dintr-o astfel de locatie, NUMAI unul (1 din n) executa cu succes operatia la un moment dat. Aceasta caracteristica deosebeste comunicarea prin porturi globale si cutii postale de tehnicile de comunicare de tip broadcast si multicast.
Un dezavantaj al transmiterii mesajelor prin porturi si canale este evident faptul ca se folosesc aceste entitati intermediare pentru comunicare, ceea ce este echivalent cu numirea indirecta a destinatarului (indirect naming).
Acest neajuns poate fi corectat prin broadcast - tehnica de difuzare de mesaje care consta in posibilitatea de a transmite mesaje "DE LA ORICINE" "from anybody") - conform cu comunicarea n la 1 - sau "CATRE TOTI" "to everyone") - conform cu comunicarea 1 la n, fara a introduce numirea indirecta ci folosind un nume special in antetul mesajului. Astfel, comunicarea prin canal ar fi echivalenta cu posibilitatea de a primi mesaje de la un anumit grup de procese, selectat la configurarea serviciului de transmitere de mesaje, iar comunicarea prin port global ar fi echivalenta cu posibilitatea de a trimite (primi) mesaje catre (de la) un grup de procese anonime, identice, dintre care NUMAI unul preia mesajul si il interpreteaza (a transmis mesajul). O varianta de numire este atribuirea de nume pentru grupuri de procese in mod similar cu numirea unui proces individual.
Prin broadcast un nod al rectelei trimite un mesaj catre TOATE celelalte noduri, indiferent daca acestea sunt sau nu conectate direct cu nodul emitator. De la emitator la nodurile conectate indirect cu el, mesajul se va transmite prin FORWARD implicit. [Andrews, 1991]
In cele mai multe retele LAN procesele partajeaza canale de comunicatie comune. In acest caz, fiecare procesor este conectat direct cu toate celelalte procesoare. De fapt, adesea aceste retele de comunicatie suporta o primitiva speciala de comunicare in retea, numita broadcast, care transmite un mesaj de la un procesor la toate celelalte. Indiferent daca transmiterea mesajelor de tip broadcast este sau nu suportata de partea hardware, aceasta furnizeaza o tehnica de programare foarte folositoare.
Se poate folosi tehnica broadcast pentru a distribui sau, din contra, pentru a grupa informatii. Adesea, tehnica este folosita pentru ca procesoarele sa interschimbe informatii despre starea curenta a retelei LAN. De asemenea, se poate folosi tehnica broadcast pentru a rezolva o serie de probleme de sincronizare in sisteme distribuite, de exemplu, apeland la o implementare distribuita care foloseste semafoare. Ideea fundamentala pentru semafoarele distribuite, ca si pentru alte protocoale de sincronizare in sisteme distribuite, este ordonarea totala a evenimentelor care comunica. O tehnica curenta pentru ordonarea evenimentelor foloseste ceasuri logice [Andrews, 1991], [Boian, 1999].
Implementarea tehnicii broadcast este ingreunata de faptul ca, din pacate, in practica nu se poate considera ca operatia BROADCASTING este una atomica. Doua mesaje trimise "to anyone" de catre doua procese diferite pot fi receptionate de alte procese in alta ordine (diferita de cea in care au fost trimise). Mai mult, un mesaj cu un timestamp mai mic poate fi receptionat dupa un mesaj cu un timestamp mai mare.
Executarea operatiei BROADCASTING cu transmitere asincrona de mesaje este echivalenta cu a transmite concurent acelasi mesaj pe mai multe canale. Ca si SEND, operatorul BROADCAST este o primitiva non-blocking, adica procesul care o executa nu se blocheaza in asteptare dupa ce transmite mesajul "to anyone". Toate copiile mesajului sunt depuse in coada si fiecare copie poate fi preluata ulterior de unul dintre procesele implicate in comunicarea prin canalul respectiv.
Putem defini conceptul de broadcasting si pentru folosirea cu transmitere sincrona de mesaje. Pentru a pastra proprietatea de a bloca procesul care transmite, o operatie BROADCAST sincrona trebuie sa blocheze expeditorul pana cand TOTI receptorii preiau mesajul. Aceasta nu este o varianta practic recomandata pentru ca, la randul lui, procesul emitator poate fi receptor pentru alte mesaje pe care ar trebui sa le confirme, s.a.m.d. Se pot defini totusi doua moduri de a obtine BROADCAST sincron:
utilizarea unui proces separat care sa simuleze un canal de broadcast; in acest caz, clientii ar trebui sa trimita si sa primeasca mesaje prin broadcast numai pe acest canal;
utilizarea comunicarii gardate: cand un proces vrea atat sa trimita cat si sa primeasca mesaje de tip broadcast, el poate folosi comunicarea gardata cu doua variabile poarta. In acest model fiecare variabila poarta are un cuantificator pentru a enumera partenerii implicati in broadcast, in sensul urmator: una dintre variabile are rolul de a transmite mesaj catre toti partenerii (outputs), in timp ce cealalta variabila preia mesaj de la oricare dintre parteneri (inputs).
Prin multicast are loc o transmitere multipla, prin care mesajul poate fi transmis "CATRE FIECARE" proces inscris in grup. In acest caz fiecare proces membru al grupului destinatar primeste o copie a mesajului.
Indiferent de mecanismul IPC folosit, operatia de transmitere, respectiv de receptionare a unui mesaj se poate concretiza in primitive diferite in functie de tipul mesajului.
Astfel, primitivele SEND si WAIT se pot regasi in patru operatii diferite:
SEND_REQUEST(destinatar, mesaj
WAIT_REQUEST(expeditor, spatiu_adresa
SEND_REPLY(expeditor_original, mesaj_de_raspuns
WAIT_REPLY(destinatar_original, spatiu_adresa_mesaj_de_raspuns
Un exemplu standard de comunicare conforma cu modelul client-server presupune o secventa de tipul:
clientul - executa SEND_REQUEST(.)
serverul - executa WAIT_REQUEST(.)
- prelucreaza cererea receptionata
- executa SEND_REPLY(.)
clientul - executa WAIT_REPLY(.).
Transmiterea mesajelor este asincrona daca clientul nu este blocat intre SEND_REQUEST(.) si WAIT_REPLY(.).
De multe ori serviciul de transmitere a mesajelor furnizeaza utilizatorului si o primitiva REQUEST_SERVICE care inglobeaza pentru client intreaga secventa proprie de operatii. In sistemul Amoeba, acesta este singurul mecanism oferit de nucleul de transmitere de mesaje.
In sistemele distribuite este posibil ca un client sa adreseze o cerere unui server care nu o poate onora. In acest caz se poate adopta solutia retransmiterii cererii de la un server la altul pana la unul care poate deservi cererea clientului. Aceasta tehnica este cunoscuta ca message forwarding (retransmitere). Retransmiterea se poate face cu REPLY catre procesul client sau fara.
Reluand mecanismul de transmitere de mesaje intre procesele A si B descris in primul paragraf, transmiterea este sincrona daca procesul expeditor A este intarziat pe SEND pana cand destinatarul executa operatia WAIT prin care confirma disponibilitatea de a receptiona mesajul transmis de A.
Fata de operatiile interne executate asupra mesajului la transmiterea asincrona, aici mesajul este copiat NUMAI O DATA si anume atunci cand expeditorul si destinatarul s-au sincronizat (s-au intalnit) si pot comunica. Deoarece conditia de sincronizare este implicita, rezulta ca sistemele cu transmitere sincrona de mesaje sunt mai usor de gestionat decat cele asincrone.
La transmiterea sincrona de mesaje rolul bufferului de mesaje este preluat de un proces care are rolul de a asigura o interfata intre procesele care comunica. Acest proces executa o unica operatie de tip WAIT(catre_oricine, orice) si asigura comunicarea prin urmatoarele actiuni:
daca un client transmite o cerere, o depoziteaza;
daca serverul solicita o actiune, o selecteaza din depozit si o transmite;
daca serverul transmite un raspuns, il depoziteaza;
daca clientul solicita un raspuns, il cauta in depozit si il transmite.
Cand procesele interactioneaza folosind variabile partajate, fiecare proces acceseaza direct acele variabile de care are nevoie. La transmiterea de mesaje, numai canalele de comunicatie sunt partajate, deci procesele trebuie sa comunice pentru a interactiona. De aici, se impune discutarea unor tehnici de sincronizare a comunicarii intre procese, synchronizing IPC.
Transmiterea asincrona de mesaje, transmiterea sincrona de mesaje, comunicarea prin RPC si mecanismul rendez-vous sunt mecanisme echivalente pentru comunicarea si sincronizarea proceselor in sisteme concurente.
Reluand ideile din paragraful Comunicarea datelor in sisteme concurente, avem ca interactiunile de tip client-server au stat la baza dezvoltarii unor mecanisme de comunicare specifice si anume invocarea la distanta (RPC, Remote Procedure Call) si rendez-vous. Ambele metode combina aspecte intalnite la monitoare si la transmiterea sincrona de mesaje. Ca si la monitoare, un modul sau un proces exporta operatii si operatiile sunt invocate printr-un apel de tip call. Ca si o operatie OUTPUT specifica transmiterii sincrone de mesaje, executia unui apel call intarzie procesul care il executa. [Andrews, 1991]
Noutatea pe care o aduc mecanismele RPC si rendez-vous este ca o operatie este un canal de comunicatie bidirectional, atat de la apelant la procesul care ofera serviciul solicitat de apel, cat si invers. In particular, apelantul intarzie pana cand primeste un raspuns legat de incheierea executiei operatiei solicitate.
Diferenta intre RPC si rendez-vous consta in modul in care sunt deservite cererile invocate. Astfel, o prima abordare este sa se declare o procedura pentru fiecare operatie si sa se creeze un proces nou pentru fiecare apel nou. Aceasta abordare se numeste RPC, Remote Procedure Call, deoarece apelantul si corpul procedurii apelate pot sa se gaseasca pe masini diferite (la distanta). O a doua abordare este ca procesul apelant "sa se intalneasca" (sa stabileasca un rendez‑vous) cu un proces existent. Un rendez-vous consta dintr-o operatie de intrare, ACCEPT - prin care un proces asteapta sa fie invocat, o operatia de prelucrare a cererii si operatia de furnizare a rezultatului (raspunsului). Aceasta situatie este numita mai corect rendez-vous extins pentru a o deosebi de un rendez-vous simplu (sincronizare simpla). In cazul comunicarii prin apel de procedura, mesajul consta in valorile parametrilor efectivi transmisi entitatii apelate, iar raspunsul este continut de valorile parametrilor returnati prin referinta entitatii apelante.
Deoarece, nici RPC, nici rendez-vous nu suporta comunicarea asincrona, rezulta ca programarea proceselor filtre si peers cu aceste mecanisme NU este o abordare naturala.
Dezvoltarea programarii concurente se poate face folosind numai procese si monitoare, care partajeaza acelasi spatiu de adrese. Intr-un astfel de model, monitoarele incapsuleaza variabile partajate, in timp ce procesele comunica si se sincronizeaza prin apelarea metodelor monitoarelor.
Cu mecanismul RPC se poate folosi o singura componenta de programare, un modul, care sa contina atat procesele cat si procedurile (metodele). De asemenea, se permite modulelor sa fie rezidente in spatii de adresa diferite, eventual chiar in noduri diferite ale retelei. Procesele interne ale unui modul pot partaja variabile si pot apela proceduri declarate in acel modul. Totusi, procesele dintr-un modul pot comunica cu procesele dintr-un alt modul numai prin apeluri de proceduri.
In esenta, RPC furnizeaza numai un mecanism de comunicare intre module. In interiorul unui modul inca trebuie programata explicit sincronizarea proceselor. In plus, programatorul trebuie sa scrie procese pentru manipularea datelor communicate prin RPC.
Mecanismul rendez-vous combina actiunea de deservire a unei cereri cu alte prelucrari solicitate de apel. Cu rendez-vous, un proces exporta operatii (in sensul ca operatiile sunt vizibile din afara) care pot fi apelate de alte procese.
Ca si la RPC, un proces invoca o operatie prin intermediul unui apel call. La RPC apelul call numeste un alt proces care sa execute si o operatie din acel proces care sa se execute. Spre deosebire de RPC, la rendez-vous o operatie este executata de acelasi proces care o exporta.
Pentru a pune in evidenta deosebirile dintre mecanismele folosite pentru transmiterea de mesaje, se pot face trei remarci comparative intre comunicarea prin canal si invocarea la distanta si anume:
comunicarea prin canal se identifica cu transmiterea de mesaje intre procesele care comunica, in timp ce invocarea la distanta consta in apelarea din cadrul unuia dintre procese a unei secvente de instructiuni a celuilalt proces, urmand ca aceste instructiuni sa se execute la punctul de intalnire.
In cazul comunicarii prin canal, sursa si destinatia sunt univoc determinate, in timp ce pentru invocarea la distanta este precizata numai destinatia. De aici rezulta ca invocarea la distanta permite stabilirea unor legaturi de comunicare de tip n ->1
Prin canal informatia circula de la sursa la destinatie, in timp ce invocarea la distanta poate conduce mesajele in ambele sensuri.
Comparand comunicarea cu precizarea indirecta a partenerilor de comunicare cu invocarea la distanta putem spune ca invocarea la distanta permite interactiunea proceselor implicate ca entitati active in comunicare, in timp ce comunicarea prin canal sau prin resurse trebuie sa apeleze la entitati intermediare, pasive.
Totusi, comunicarea prin canale si invocarea la distanta sunt mecanisme echivalente de realizare a aplicatiilor concurente. [Georgescu, 1996].
In Java, conceptul RPC este implementat ca un mecanism nou de programare distribuita, numit RMI, Remote Method Invocation. Acesta permite apelarea dintr-un program Java a unor metode executate pe alte masini virtuale Java, situate chiar pe alte statii din sistemul distribuit. Acest subiect este reluat in paragraful Suportul Java pentru concurenta si este abordat pe larg in [Boian, 1999], [Athanasiu s.a., 2000].
Din punctul de vedere al transpunerii in aplicatii, transmiterea asincrona de mesaje presupune gestionarea ca timp si spatiu de memorie a bufferului de mesaje.
Intr-un sistem cu memorie partajata, procesele isi gestioneaza de o maniera proprie transferurile de date prin procedeul bufferului de tip producator-consumator.
Intr-un sistem fara memorie partajata, asa cum s-a vazut si anterior, mesajele trebuiesc copiate de doua ori: o data din spatiul de adresa al expeditorului in bufferul de mesaje si apoi din bufferul de mesaje in spatiul de adresa al destinatarului. Aceste copieri pot sa afecteze si alte procese din sistem, altele decat cele implicate in comunicarea curenta. Daca in sistem exista un singur buffer de mesaje atunci acesta devine o structura de date partajabila si deci trebuie considerate metode de sincronizare a accesului la mesajele depuse intr-un astfel de buffer.
Proiectarea unui sistem de transfer de mesaje trebuie sa aiba in vedere:
structura mesajelor;
restrictiile impuse de mediile intermediare de transmitere a mesajelor;
gestionarea bufferului de mesaje;
tehnici de gestionare a zonelor de memorie: bufferul de mesaje, spatiile de adresa corespunzatoare mesajelor, porturile etc.
O posibilitate de implementare presupune unificarea mesajelor cu intreruperile transmise in sistem. In aceasta abordare se va proiecta o maniera comuna de transmitere si preluare a tuturor evenimentelor din sistem, indiferent daca sunt semnale specifice lucrului cu mesaje sau intreruperi hard. Gestionarul de evenimente va interpreta ulterior fiecare eveniment si va determina tipul acestuia, urmand sa fie tratat in continuare de o maniera specifica.
Limbajul de programare concurent occam este bazat pe comunicarea sincrona si pe faptul ca procesele nu partajeaza memorie. [Bacon, 1998]
Limbajul occam isi are originea in specificatiile CSP (Communicating Sequential Processes) [Hoare, 1985], cu deosebirea ca in CSP sursa si destinatia comunicarii sunt procese identificate prin nume, in timp ce in occam comunicarea are loc prin intermediul unui canal identificat printr-un nume.
In occam mecanismele IPC constau in asignarea unui proces la altul. De exemplu, o atribuire de tipul
var <- expresie
trebuie interpretata astfel: procesul de evaluare a expresiei este asociat cu procesul care retine variabila. Valoarea calculata este transmisa pe canalul prin care comunica cele doua procese prin : canal? var, respectiv canal! expresie.
Linda a fost dezvoltat la inceputul anilor '80 [Gelernter, 1985] ca un model de programare concurenta care si-a propus sa dea un nivel superior, abstract pentru IPC. Linda nu este un limbaj de programare complet nou ci este un set de primitive care pot fi folosite pentru a extinde posibilitatile unui limbaj de programare secvential, cum ar fi: C, C++, ForTran.
In loc de mesaje, Linda foloseste tuple pentru a comunica informatii intre procese. Un tuplu este o secventa de campuri cu tip predefinit. Fata de mesaje, tuplele sunt obiecte de date, interne limbajului de programare gazda.
Un socket este un capat de comunicatie (punct final de comunicatie), care poate fi numit si adresat in retea. Un socket este caracterizat de un domeniu in care are loc comunicatia si in care este numit socketul. Un socket opereaza intr‑un singur domeniu si formatul de adresa depinde direct de domeniul lui. Fiecare domeniu presupune un singur set de protocoale. Cele mai populare domenii sunt: AF_UNIX - pentru comunicatii locale UNIX - si AF_INET - pentru comunicare in Internet.
Din punctul de vedere al nivelelor unei retele, un socket este locul in care programul de aplicatie se intalneste cu furnizorul mediului de transport. Din punctul de vedere al programului de aplicatie, un socket este o resursa alocata de sistemul de operare.
Din punctul de vedere al sistemului de operare, un socket este o structura de date intretinuta de nucleul sistemului de operare. Aceasta structura este referita in programul de aplicatie printr-un intreg, numit descriptor de socket.
Concret, socketul este mijlocul de comunicare intre parteneri. Comunicarea prin socket presupune ca fiecare aplicatie are alocat un socket de la sistemul de operare. Interfata de lucru cu socket ascunde utilizatorului detaliile fizice ale retelei si este caracterizata numai prin serviciile pe care le asigura.
In functie de entitatile transportate, se deosebesc doua tipuri de sockets: socket stream si socket datagram. Corespunzator, interfata de lucru cu fiecare tip de socket va valorifica particularitatile comunicarii prin flux de date, respectiv prin pachete (datagrame).
Este important de retinut ca, comunicarea este posibila numai daca la ambele capete este utilizat acelasi tip de socket. In functie de tipul aplicatiei si de datele comunicate, programatorul va alege un anumit tip de socket si, implicit, un anumit protocol pentru transportul datelor comunicate (TCP/IP, pentru socket stream sau UDP, pentru socket datagram). Amanunte despre cele doua scheme de implementare a mecanismului de lucru cu sockets se pot consulta in [Boian, 1999].
In mediile de programare care recunosc mecanismul de comunicare prin sockets (Java, Visual C++), clasele de lucru cu sockets creeaza o interfata eleganta si flexibila, facand programarea aplicatiilor pentru comunicare la fel de usoara ca si lucrul cu fisiere. Mai mult, o interfata creata cu Java permite comunicarea cu alte programe care folosesc o interfata de acelasi tip, dar scrisa in alt limbaj de programare, de exemplu in C++.
Printre noutatile introduse de JDK 1.1. este aparitia unui nou tip de socket datagram si anume cel pentru trimiterea multipla (multicast). Aceasta noua facilitate, impreuna cu posibilitatea difuzarii unui mesaj (broadcast) catre toate statiile dintr-o retea sunt mecanisme puternice oferite de Java pentru comunicare in sisteme distribuite. Prin difuzare, mesajul este transmis catre toate statiile din sistem, in timp ce prin transmitere multipla mesajul este transmis simultan catre toate statiile CARE s-au abonat la receptia mesajului. Programatorul precizeaza explicit tipul de comunicare prin valoarea campurilor adresei IP care se transmite o data cu structura socket datagram definita pentru comunicarea respectiva. [Athanasiu, 2000], [Boian, 1999]
[Bacon, 1998] O cerinta frecvent intalnita la proiectarea sistemelor de comunicare este existenta unui server care sa poata deservi mai multi clienti simultan. Chiar daca un astfel de server preia cererile ca mesaje, este nevoie de mai multe threaduri de control interne care sa execute actiunile distincte prin care serverul prelucreaza cererile primite de la clienti diferiti. Toate aceste threaduri trebuie sa aiba acces la aceleasi structuri de date, deci sunt necesare tehnici de gestionare a spatiilor comune, partajate. De aceea, un sistem cu un astfel de server trebuie sa recunoasca atat tehnici de partajare a memoriei, cat si transmiterea de mesaje intre diferite spatii de adresa.
Daca unul dintre procesele care comunica este uni-thread atunci el se blocheaza pana la primirea raspunsului. Daca insa procesul respectiv este multi-thread si threadurile lui pot sa se creeze dinamic atunci se poate destina un thread pentru a astepta raspunsul de la procesul partener si threadul parinte isi poate continua activitatea in paralel. Acest mecanism este specific sistemelor distribuite.
Un proces Java consta din segment de cod si segment de date mapate intr-un spatiu virtual de adresare. Fiecare proces detine resurse alocate de sistemul de operare, de exemplu fisiere deschise, regiuni de memorie alocate dinamic, threaduri (fire de executie). Aceste resurse sunt eliberate de sistemul de operare la terminarea procesului.
[Rotariu, 1999] Un thread Java este unitatea de executie a unui proces. Fiecare fir de executie, ca si procesul clasic, are propriul context (o secventa de instructiuni, un set de registri de prelucrare, o stiva) si ruleaza strict secvential. Procesul nu executa instructiuni. Procesul este un spatiu de adresare COMUN pentru firele lui de executie (unul sau mai multe). Executia instructiunilor se face de catre threaduri.
Avand acces la acelasi spatiu de adresare, threadurile pot sa comunice prin variabile comune, ceea ce simplifica programarea. In afara de spatiul de adresa, firele de executie acceseaza in comun si fisierele deschise, procesele copil, timere si semnale. Pentru situatiile in care se impune acces exclusiv la variabile trebuie implementat un mecanism de sincronizare recunoscut de platforma Java.
Mediul de executie Java executa propriul control asupra threadurilor. Algoritmul de planificare a firelor, prioritatile si starile sunt specifice aplicatiei Java si sunt implementate identic pe toate platformele pe care a fost portat mediul Java. In plus, acest mediu stie sa valorifice si resursele sistemului pe care lucreaza (multitasking, multiprocesor). Ordinea executiei threadurilor de aceeasi prioritate depinde de sistemul de operare gazda. Pentru threaduri de prioritati diferite, executia este preemtiva (sistemul de operare poate sa intrerupa executia unui thread pentru a executa un alt thread de prioritate mai mare).
Diferenta importanta intre scrierea unei aplicatii cu un fir de executie principal, fata de aceeasi aplicatie scrisa cu mai multe fire consta in necesitatea de a asigura sincronizarea threadurilor care apartin aceluiasi proces. Java ofera pentru aceasta mecanisme proprii de sincronizare, extrem de usor de utilizat si inglobate in sintaxa de baza a limbajului. Cu ajutorul modificatorului synchronize se poate impune acces exclusiv la nivelul unui bloc (secventa) de instructiuni, a unei metode sau a unei instantieri de clasa.
In favoarea argumentului ca Java este un limbaj simplu spunem si ca Java nu implementeaza complet primitivele de sincronizare prevazute de standardul POSIX (ca in bibliotecile pthread). In acelasi context trebuie mentionat ca Java nu permite determinarea in avans a posibilitatilor de blocare intr-o regiune critica (prevedere deadlock). [Rotariu, 1999], [Athanasiu, 2000]
[Vaduva, 2001] Limbajul Java gestioneaza sincronizarea threadurilor prin mecanisme de tip monitor. Fiecarui obiect (instanta de clasa) care are o metoda sincronizata (declarata cu synchronize pentru ca trebuie accesata sub excludere mutuala) ii este asociat IMPLICIT un monitor. Obtinerea si eliberarea monitorului se fac automat, atomic, de catre mediul Java. Ca si in cazul lucrului cu procese, un monitor permite numai unui singur thread sa apeleze o metoda a monitorului la un moment dat.
Este de remarcat ca, in general, sub Java mecanismul de sincronizare este legat de un obiect si NU de o metoda sau de un bloc de instructiuni. In particular, daca modificatorul synchronize este aplicat unei metode statice a unei clase, numai atunci monitorul se asociaza clasei si nu obiectului.
[Athanasiu, 2000] In Java, threadurile se executa in acelasi spatiu de adresa, deci pe aceeasi masina. Rezulta ca numai programarea threadurilor nu este un mecanism suficient de puternic pentru aplicatii distribuite. Odata cu dezvoltarea programarii orientate obiect, s-a incercat extinderea conceptului de apel de procedura la apelul de metoda. Astfel, Java recunoaste mecanismul RMI (Remote Methods Invocation) pentru implementarea aplicatiilor client-server, ca echivalent pentru mecanismul de invocarea la distanta de tip RPC.
Arhitectura RMI este organizata pe trei nivele si anume:
nivelul obiectelor skeleton/stub;
nivelul referintelor la distanta (actiuni diferite pentru client si server);
nivelul transport (comunicarea efectiva).
Un stub sau cotor [Boian, 1999] este obiectul care "reprezinta" serverul pe masina clientului. Acesta are rolul de a impacheta parametrii de apel ai metodei la distanta intr-un mesaj care va fi transmis prin retea.
Un skeleton este obiectul care "reprezinta" clientul pe masina serverului. Acesta despacheteaza mesajul receptionat (parametrii transmisi la apel), invoca metoda referita, obtine rezultatul sau prinde o exceptie generala si, in final, asambleaza un mesaj de raspuns care va fi transmis clientului ca rezultat al apelului.
Obiectele skeleton si stub sunt generate automat pornind de la clasa care implementeaza serverul.
O data cu JDK 1.2. s-a renuntat la skeleton si s-a implementat un mecanism de exportate bazat pe proprietatea serverului de a fi vizibil din exterior. La exportare sunt instantiate fire de executie care realizeaza transparent translatarea necesara apelului la distanta.
Presupunand cunoscute mecanismele prezentate in paragrafele anterioare, ne propunem sa luam in discutie o serie de probleme clasice, specifice programarii concurente.
Analiza cerintelor pentru obtinerea solutiei concurente este dirijata pe urmatoarele directii:
q care sunt structurile de date partajate si care pot fi modificate; cu alte cuvinte, care sunt elementele accesate prin excludere mutuala;
q cum sa se gestioneze asteptarea pentru acces la o resursa comuna si cum sa se realizeze "trezirea" proceselor in asteptare;
q cum sa se gestioneze diferite categorii de procese particulare de tip: producator, consumator, cititor, scriitor;
q cum sa se permita diferitelor procese sa citeasca simultan, chiar daca in acelasi timp asteapta acces exclusiv la un proces de scriere.
In cele ce urmeaza vom accepta ca un buffer este o secventa oarecare de locatii (sloturi), fiecare de dimensiune fixata si capabila sa memoreze date. Entitatile care au acces la continutul bufferului sunt procesele active, atat cele de sistem, cat si cele utilizator.
In functie de operatia pe care un proces incearca sa o execute asupra bufferului, procesul respectiv devine producator, consumator, cititor sau scriitor. Deoarece procesele sunt concurente (folosesc in comun bufferul de date), rezulta ca trebuie avute in vedere conditii de sincronizare a accesului la datele memorate in locatiile bufferului, cum ar fi:
a) daca un proces consumator cere o preluare de date din buffer si acesta este gol atunci procesul trebuie blocat pana la aparitia unor date in buffer;
b) daca un proces producator cere o depunere de date in buffer si acesta este plin atunci procesul trebuie blocat pana la eliberarea unei locatii a bufferului;
c) daca un proces cititor cere sa consulte continutul bufferului atunci poate fi permis simultan accesul si altor cititori, dar trebuie restrictionat accesul vreunui scriitor;
d) daca un proces scriitor cere sa scrie (sa adauge sau sa modifice) date in buffer atunci, pe durata scrierii, nici un alt cititor sau scriitor nu poate avea acces la buffer.
Gestionarea bufferului din perspectiva accesului diferitelor tipuri de procese a condus la definirea catorva probleme specifice calculului concurent.
Problema adunarii concurente consta in gestionarea mai multor procese concurente, care, fiecare, aduna o unitate la valoarea curenta a unei variabile comune. [Scheiber, 1999]
Programatorul obisnuit cu calculul secvential se asteapta ca o rezolvare naturala a problemei sa initializeze valoarea variabilei comune cu zero, sa permita fiecarui proces sa incrementeze valoarea curenta si rezultatul sa fie egal cu numarul proceselor care au rulat.
Daca solutia este abordata de o maniera secventiala atunci nedeterminismul executiei concurente a proceselor si, in acelasi timp, lipsa atomicitatii operatiei de incrementare sunt motivele pentru care rezultatul este foarte rar egal cu numarul proceselor lansate in executie concurent.
Operatia de incrementare consta in trei microoperatii, si anume: (1) se incarca valoarea curenta a variabilei intr-un registru acumulator, (2) se incrementeaza valoarea curenta in registru si (3) se salveaza valoarea din registru in variabila. Prin definitie, concurenta nu presupune ca aceasta secventa de microoperatii este atomica. Astfel, procesele pot sa interfere in preluarea si interpretarea valorii curente a variabilei si, mai departe, doua procese active sa preia aceeasi valoare a variabilei, sa o incrementeze independent si sa depuna succesiv ACEEASI valoare din registru de lucru in locatia variabilei.
O solutie corecta a problemei trebuie sa lanseze procesele in executie concurenta si sa asigure atomicitatea operatiei de incrementare la nivelul fiecarui proces activ, astfel incat valoarea finala a variabilei sa fie egala cu numarul proceselor rulate. Cea mai simpla maniera de rezolvare este tratarea incrementarii ca secventa critica, deci instructiune supusa accesului sub excludere mutuala, exclusiv de un proces la un moment dat.
Nedeterminismul executiei concurente reiese din faptul ca la executii diferite ordinea in care procesele incrementeaza valoarea curenta a variabilei este aleatoare.
In [Scheiber, 1999] este tratata in detaliu rezolvarea problemei adunarii concurente folosind diferite mecanisme de asigurare a excluderii mutuale: algoritmul Dekker, semafoare, monitoare, RPC.
Problema producator-consumator se refera la organizarea bufferului de date cand acesta este accesat de procese de tip producator si consumator.
Problema trebuie tratata diferit in functie de proprietatile particulare pe care le are bufferul in ceea ce priveste dimensiunea lui, politica de ocupare cu date, protocolul de acces la date s.a.m.d. De exemplu, se poate presupune ca bufferul este de dimensiune fixata, adica marginit sau, mai mult, ca este ciclic. De obicei se considera cazul in care sloturile sunt logic numerotate si un proces are acces la o anumita locatie bine precizata in functie de operatia pe care procesul respectiv o solicita si, eventual, in functie de operatia anterioara care s‑a executat asupra bufferului.
De asemenea, putem pune in evidenta cazuri particulare de probleme in functie de numarul proceselor care au acces la bufferul de date. Astfel, putem avea situatia mai simpla cu un producator si un consumator sau, o situatie mai generala, cu mai multi producatori si mai multi consumatori.
O alta directie de generalizare rezulta daca se considera ca un producator poate depune pe banda la un acces mai multe produse si un consumator, de asemenea, poate lua de pe banda la un acces mai multe produse.
In acest paragraf ne propunem sa exemplificam rezolvarea problemei producator-consumator in cateva situatii particulare, folosind semafoare.
Un producator, un consumator, buffer ciclic. Pentru rezolvarea acestei situatii sunt necesare si suficiente doua semafoare cu urmatoarele semnificatii: unul numit DATE care sa reprezinte datele din buffer la un moment dat (numarul articolelor produse si inca neconsumate) si celalalt numit SPATII care sa reprezinte locatiile libere din buffer la un moment dat.
Algoritmul de rezolvare poate fi reprezentat prin urmatoarea schema sugestiva:
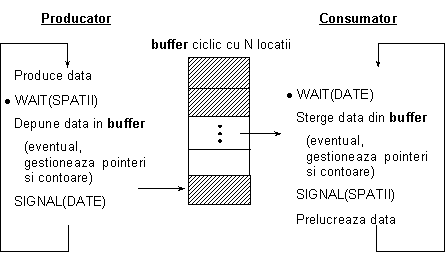
= posibila intarziere
Figura 15. Rezolvarea cu semafoare a problemei producator-consumator (1P, 1C)
Valorile initiale ale semafoarelor sunt: DATE = 0 si SPATII = N, unde N este numarul de locatii din buffer. In continuare algoritmul trebuie sa transcrie urmatoarele afirmatii:
q Cand producatorul vrea sa depune date in buffer, el executa o primitiva SIGNAL(DATE); daca operatia de depunere este permisa (posibila) atunci are loc o incrementare a valorii semaforului DATE;
q Cand consumatorul vrea sa ia date din buffer, el executa o primitiva SIGNAL(SPATII); daca operatia este permisa (posibila) atunci are loc o incrementare a valorii semaforului SPATII;
q Cand bufferul este gol (adica valoarea lui DATE este 0) si apare un potential consumator atunci acesta va fi blocat la WAIT(DATE) in asteptare la semaforul DATE;
q Cand bufferul este plin (adica valoarea lui SPATII este 0) si apare un potential producator atunci acesta va fi blocat la WAIT(SPATII) in asteptare la semaforul SPATII.
Observatii.
Deoarece am considerat cazul unui singur producator si al unui singur consumator rezulta ca nu apar probleme de acces concurent, deci nu trebuiesc rezolvate probleme legate de excluderea mutuala a accesului la datele din buffer.
Operatiile WAIT si SIGNAL fiind atomice, asigura ca actiunile unui producator nu se pot interfera cu cele ale unui consumator.
O implementare completa a algoritmului trebuie sa stabileasca politica de depunere/preluare a datelor in/din buffer. Pentru aceste aspecte, schema algoritmului a propus programatorului folosirea unor contoare si eventual a pointerilor de localizare in structura bufferului.
Mai multi producatori si/sau mai multi consumatori, buffer ciclic. Deoarece exista mai multi producatori sau mai multi consumatori care au acces la bufferul de articole rezulta ca se impune rezolvarea concurentei acestor procese. Concret, procesele de acelasi tip trebuie sa se excluda reciproc de la utilizarea simultana a bufferului.
Pentru rezolvarea acestei probleme, solutia anterioara se poate completa cu cate un semafor poarta pentru sincronizarea producatorilor si, respectiv a consumatorilor. Fie aceste semafoare POARTA_P si POARTA_C.
In figura urmatoare este prezentata schema algoritmului de rezolvare a problemei producator-consumator in care avem mai multi producatori si un consumator. Pentru acest caz s-a folosit numai variabila POARTA_P necesara pentru sincronizarea producatorilor.

= posibila intarziere
Figura 16. Rezolvarea cu semafoare a problemei producator-consumator (nP, 1C)
Functia semaforului poarta este indeplinita daca valoarea initiala este 1 [Georgescu, 1996]. Aceasta modalitate de utilizare a semaforului POARTA_P este cea care asigura excluderea mutuala a proceselor producator deoarece secventa de operatii executate intre WAIT(POARTA_P) si SIGNAL(POARTA_P) este sectiunea critica a procesului producator apelant [Georgescu, 1996].
Solutia cu monitoare a problemei producator-consumator propune incapsularea intr-un monitor a bufferului, a contoarelor si a pointerilor care asigura utilizarea corecta a bufferului.
Aceasta abordare este justificata de faptul ca bufferul este o resursa partajata. Solutia este eleganta deoarece insasi structura de monitor asigura accesul exclusiv al proceselor la monitorul-buffer. De aici rezulta ca mai este esentiala deosebirea intre situatiile cu un producator/consumator sau mai multi.
Deoarece problema excluderii mutuale a proceselor este rezolvata, rezulta ca mai trebuie asigurata sincronizarea proceselor, respectiv blocarea lor in situatiile de buffer gol sau plin. Pentru aceasta propunem folosirea a doua variabile de conditie numite tocmai GOL si PLIN. Cu acestea, metodele DEPUNE si PREIA asociate monitorului-buffer ar putea fi:
procedure DEPUNE(articol)
if (buffer plin) then WAIT(PLIN
endif
depune articol in buffer
SIGNAL(GOL
return
procedure PREIA
if (buffer gol) then WAIT(GOL
endif
preia articol din buffer
SIGNAL(PLIN
return articol
In acest paragraf propunem o solutie pentru problema producator-consumator care foloseste obiecte active. Aici sincronizarea (intalnirea, RENDEZ‑VOUS) intre procesele care comunica se stabileste folosind primitivele SELECT si ACCEPT.
Ca si in solutia cu monitor, entitatea elementara, aici obiectul activ, corespunde bufferului de articole. In plus, vom introduce variabila NR care sa retina numarul de articole care se gasesc in buffer la un moment dat. Evident, valoarea initiala pentru NR va fi 0.
Algoritmul de rezolvare
urmareste o structura similara cu lucrul in
Propozitiile ACCEPT sunt executate prin apeluri externe de catre procesul (taskul) care a intrat in constructia SELECT. Nu este definit care task executa la un moment dat instructiunile dintr-un ACCEPT. Aici fiecare ACCEPT este gardat de indeplinirea unei conditii, in sensul ca apelul metodei depune, respectiv preia este executat numai daca este indeplinita conditia introdusa prin clauza WHEN.
O constructie SELECT permite definirea mai multor propozitii ACCEPT accesibile proceslor pentru apel.
task-body buffer is
declaratii
begin
loop
SELECT
when NR<lung_buff
ACCEPT depune(articol) do depune articol in buffer
end
NR=NR+1
actualizeaza pointeri la urmatoarea locatie pentru depunere
OR
when NR>
ACCEPT preia(articol) do preia articol din buffer
end
NR=NR-1
actualizeaza pointeri la urmatoarea locatie pentru preluare
end
end loop
end buffer
Ca si in lucrul cu monitoare, se
apeleaza din exterior o metoda interna monitorului/taskului
buffer pentru a depune (prelua) un articol in (din)
buffer. Pentru monitoare, programatorul este cel care
trebuie sa gestioneze situatiile de buffer plin (gol). Pentru obiecte
active, in
Cand sunt indeplinite conditiile unei alternative SELECT atunci procesul producator (consumator) care a testat conditiile este acceptat de taskul activ buffer. Se spune ca are loc intalnirea (RENDEZ-VOUS) intre cele doua entitati si urmeaza sa se execute instructiunile din alternativa SELECT respectiva.
Problema cititor-scriitor se refera la organizarea bufferului de date cand acesta este accesat de procese de tip cititor si scriitor.
Asa cum am aratat si anterior, un cititor este un proces care poate accesa o resursa simultan cu alte procese cititor, dar fara a putea opera modificari asupra resursei respective. In acelasi timp, un scriitor este un proces care trebuie sa aiba acces exclusiv la resursa comuna, avand si drepturi de modificare asupra resursei respective.
In timp ce procesele producator si consumator aveau de executat activitati comparabile asupra bufferului (unul depunea articole, celalalt le prelua), procesele cititor si scriitor au de executat activitati fundamental diferite, care trebuie ordonate corect pentru executie. Pentru aceasta, proceselor cititor si scriitor pot sa li se asocieze anumite reguli de prioritate pentru executie.
Daca, de exemplu, resursa comuna este un fisier de pe disc, atunci ordinea executiei proceselor trebuie sa respecte regula: informatia citita sa fie cea mai actuala. Pentru aceasta putem presupune ca de indata ce un scriitor cere sa acceseze fisierul (resursa comuna), acesta va primi controlul de indata ce toti cititorii curenti (procesele cititor active) isi vor fi finalizat actiunile, fara ca vreun cititor sa mai primeasca accesul intre timp.
Uneori este de preferat ca scriitorul sa primeasca controlul chiar intrerupand procesele cititor. Prin mecanismele puse la dispozitie de limbajele de programare, programatorul poate sa organizeze accesul la bufferul de date de o maniera convenabila.
Fie o solutie a problemei cititor-scriitor care foloseste doua semafoare generale, C - pentru cititor, S - pentru scriitor si doua semafoare poarta, POARTA_S si POARTA.
Semaforul C are valoarea initiala 0 si numara cererile esuate ale cititorilor de a citi bufferul cand exista un scriitor care scrie; acesti cititori vor fi blocati in asteptare la semaforul C. Semaforul S are valoarea initiala 0 si numara cererile esuate ale scriitorilor de a scrie in buffer cand exista cititori care citesc bufferul si exista scriitor care scrie deja; acesti scriitori vor fi blocati in asteptare la semaforul S.
Semaforul poarta POARTA_S are valoarea initiala 1 si este folosit pentru a asigura accesul exclusiv al unui scriitor la resursa comuna (excluderea reciproca a scriitorilor). Semaforul poarta POARTA are valoarea initiala 1 si este folosit pentru a impune restrictii particulare de acces exclusiv la resursa comuna pentru un numar fixat de cititori si/sau scriitori. Utilitatea acestui semafor este evidenta atunci cand sunt acceptate urmatoarele situatii: atunci cand un cititor cere sa acceseze resursa el devine cititor activ; atunci cand un cititor activ chiar citeste resursa atunci este un cititor activ care citeste; atunci cand un scriitor cere sa acceseze resursa el devine scriitor activ; atunci cand un scriitor activ chiar scrie (modifica resursa) atunci este un scriitor activ care scrie. La un moment dat pot fi mai multi scriitori activi, dar numai unul dintre ei scrie efectiv.
Pentru acest algoritm propunem urmatoarele notatii:
ca = numarul cititorilor activi;
cc = numarul cititorilor activi care citesc;
sa = numarul scriitorilor activi;
ss = numarul scriitorilor activi care scriu efectiv
Algoritmul poate fi reprezentat astfel:
|
Cititor |
Scriitor |

Figura 17. Rezolvarea cu semafoare a problemei cititor-scriitor
"Diagonalele" punctate din schema algoritmului reprezinta semnale de sincronizare. Astfel se arata ca eliberarea resursei poate determina trimiterea unor semnale de sincronizare de tip "wake-up" inspre cozile de procese ale celor doua semafoare R si W. in acest fel, ultimul cititor care si-a incheiat actiunea de a citi poate "trezi" oricare dintre scriitorii activi care nu scriu si ultimul scriitor activ care si-a incheiat actiunea de a scrie poate "trezi" oricare dintre cititorii activi.
O solutie pentru problema cititor-scriitor, care sa foloseasca regiuni critice conditionate ar putea fi urmatoarea:
|
Cititor |
Scriitor |

Figura 18. Rezolvarea cu regiuni critice conditionate a problemei cititor-scriitor
Se poate observa ca, pentru programator, aceasta solutia este cu mult mai simpla decat cea care foloseste semafoare. Afirmatia este sustinuta de doua argumente: (1) singura grija a programatorului este sa foloseasca corect apelul primitivei AWAIT si (2) problema deblocarii (trezirii) proceselor in asteptare este implicit gestionata de mecanismul de lucru cu regiuni critice.
Reluand problema producator-consumator se poate observa ca solutiile propuse au considerat bufferul de date ca fiind entitatea elementara care sa se reprezinte ca monitor, respectiv task (obiect) activ.
Pentru rezolvarea cu monitoare a problemei cititor-scriitor, nu mai este corect sa consideram ca monitorul incapsuleaza datele si proprietatile bufferului deoarece ar aparea urmatoarea contradictie: pe de o parte se stie ca structura de monitor implica accesul exclusiv al unui singur proces la metodele monitorului la un moment dat, iar pe de alta parte, problema cititor-scriitor trebuie sa permita mai multor cititori sa consulte simultan bufferul de date.
Propunem o solutie care foloseste un monitor citeste-scrie si doua variabile de conditie: LIBER_LA_CITIRE si LIBER_LA_SCRIERE. Metodele monitorului sunt: startCiteste, endCiteste, startScrie, endScrie. In plus, monitorul mai are trei variabile locale: cc si sa - cu aceleasi semnificatii ca si in rezolvarea problemei cu semafoare, adica cc este numarul cititorilor care la un moment dat sunt in curs de citire a bufferului, iar sa este numarul de scriitori activi (care si-au anuntat intentia de a scrie si au fost intarziati) - si seScrie - variabila booleana care are valoarea TRUE cat timp exista un scriitor care scrie in bufferul de date.
Descrierea monitorului este urmatoarea:
citeste-scrie: monitor
entry-procedures startCiteste, endCiteste, startScrie, endScrie
var cc, sa: integer
seScrie: boolean
LIBER_LA_CITIRE, LIBER_LA_SCRIERE: condition
procedure startCiteste()
if sa > 0 then WAIT(LIBER_LA_CITIRE)
cc = cc + 1
SIGNAL(LIBER_LA_CITIRE)
daca un cititor poate citi atunci si alti cititori pot;
// fiecare cititor trezeste alti cititori
return
end
procedure endCiteste()
cc = cc - 1
if cc = 0 then SIGNAL(LIBER_LA_SCRIERE)
return
end
procedure startScrie()
sa = sa + 1
if seScrie or cc > 0 then WAIT(LIBER_LA_SCRIERE)
seScrie = TRUE
return
end
procedure endScrie()
seScrie = FALSE
sa = sa - 1
if sa > 0 then SIGNAL(LIBER_LA_SCRIERE)
else SIGNAL(LIBER_LA_CITIRE)
return
end
begin
seScrie = FALSE
end citeste-scrie
In acest paragraf preluam din [Georgescu, 1996] o serie de probleme specifice calculului concurent.
Problema rezervarii biletelor. Fiecare terminal al unei retele de calculatoare este plasat intr-un punct de vanzare a biletelor pentru un anumit scop (spectacol, calatorie etc.). Se cere sa se gaseasca o modalitate de a evita vanzarea mai multor bilete pentru acelasi loc.
Jocul vietii. Un tabel dreptunghiular, notat A, cu m linii si cu n coloane contine celule care pot fi vii sau moarte. Fiind data o configuratie curenta a tabelului, se cere sa se determine configuratia generatiei urmatoare, stiind ca celulele moarte isi pastreaza starea, iar o celula vie moare daca si nuami daca numarul celulelor vii, vecine ei este mai mic decat 2 sau mai mare decat 4. O celula are cel mult 8 vecini: pe orizontala, pe verticala si pe diagonale.
Problema filosofilor chinezi. La o masa rotunda stau cinci filosofi chinezi. Principala lor activitate este aceea de a gandi, dar, evident, din cand in cand trebuie sa si manance, folosind pentru aceasta cate doua betisoare. Stiind ca intre oricare doi filosofi se afla un betisor si ca un filosof poate manca doar daca a ridicat de pe masa atat betisorul din stanga sa, cat si pe cel din dreapta sa, se cere sa se simuleze activitatile filosofilor asezeti la masa.
Problema barbierului somnoros. Pravalia unui barbier este formata din doua camere: cea de la strada, folosita ca sala de asteptare si cea din spate, in care se gaseste scaunul pe care se aseaza clientii pentru a fi barbieriti. Daca nu are clienti, barbierul somnoros se culca. Sa se simuleze activitatile care se desfasoara in pravalia barbierului. Problema este o reformulare a problemei producator- consumator in care locul bufferului de articole este preluat de scaunul barbierului, iar consumatorul este barbierul, in sensul ca isi barbiereste clientii.
Problema ceasului desteptator al lui Hoare a fost enuntata de C.A.R. Hoare [1974]. Mai multe persoane, numerotate cu 1, 2, ., n au urmatorul tabiet: persoana k doreste sa se trezeasca din k in k ore pentru a intreprinde o foarte scurta activitate, dupa care se culca la loc. Se cere sa se simuleze aceste activitati.
Problema alocarii resurselor. Sunt disponibile max unitati dintr-o resursa oarecare. Exista nc clienti care doresc sa aiba de mai multe ori acces la resursa respectiva, un acces constand in a lua (a incerca sa ia) un numar de unitati din resursa, de a folosi aceste unitati si apoi de a le returna. Se cere sa se simuleze aceste activitati.
Problema gradinii ornamentale sau problema excluderii reciproce. Intrarea in gradinile ornamentale ale unui oras oriental se face prin N porti. Se pune problema sa se tina evidenta numarului de persoane care au intrat in gradina. Fiecare poarta de intrare in gradina este o resursa care trebuie accesata exclusiv de un proces. Daca la un moment dat pe una dintre porti intra o persoana atunci in acel moment pe nici o alta poarta nu mai intra vreo persoana in gradina.
Problema emitator-receptor. Un emitator emite succesiv mesaje, fiecare dintre ele trebuind sa fie receptionat de toti receptorii, inainte ca emitatorul sa transmita mesajul urmator. Un caz particular pentru aceasta problema ar fi cea in care emitatorul este grabit si emite mesajul numai acelor receptori care la momentul emisiei sunt gata sa il primeasca; totusi, se cere ca cel putin un receptor sa primeasca mesajul.
Problema autobuzului. Un autobuz, avand capacitatea maxima de N locuri, parcurge o traiectorie circulara pe care se afla P persoane care urca si coboara din autobuz. Se cere sa se simuleze activitatea autobuzului si a pasagerilor. Se presupune ca nici un pasager nu doreste sa faca mai mult de un tur complet.
|
Politica de confidentialitate |
| Copyright ©
2025 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |