
Laborator - Algoritmi de clasificare Bayes
Introducere :
Formele sunt atat obiectele fizice observabile dar si modele matematice relativ la celule, particule , forme de unda, spectre de frecventa (imagini TV, semnale radar, zgomote, EKG-uri), aplicatiile de recunoasterea formelor fiind prezente in medicina, imageria satelitara, meteorologie, criminalistica sau aplicatii militare. O forma data poate fi descrisa printr-un set de entitati caracteristice exprimate prin numere reale (biti) XF=(x1,..xn), unde N depinde de precizia urmarita (de exemplu rezolutia unei imagini). Algoritmii de clasificare Bayes fac parte din metodele statistice de clasificare si recunoastere a formelor.
Baza teoretica :
I. Algoritmi de clasificare Bayes (cazul a doua clase)
Fie W = ![]() w (M clase disjuncte de forme de
acelasi tip w wM,
M ≥ 2) si se considera cunoscute din determinari
statistice probabilitatile apriori P ( wi ) ale claselor wi (pentru i=1.M),
si se presupune ca P( wi ) > 0 si
w (M clase disjuncte de forme de
acelasi tip w wM,
M ≥ 2) si se considera cunoscute din determinari
statistice probabilitatile apriori P ( wi ) ale claselor wi (pentru i=1.M),
si se presupune ca P( wi ) > 0 si ![]() P( wi
P( wi
1. Regula lui Bayes de clasificare (ipoteza binara)
In cazul a doua clase de forme w w (M=2), o forma noua de intrare X (vector aleator n-dimensional de caracteristici) poate fi clasificata (teoretic) prin compararea probabilitatilor aposteriori dupa regula :
P ( w | X ) >< P ( w | X ) =>
X I{![]() (1)
(1)
unde:
i=1,2:
P ( wi | X ) este probabilitatea aposteriori (probabilitatea ca dupa ce X a fost clasificat, forma X sa apartina clasei wi
P ( wi ) este probabilitatea apriori a clasei wi, i=1,2 (probabilitatea ca o forma sa apartina clasei wi
2. Algoritmul lui Bayes cu eroare minima de clasificare
Algoritmul Bayes cu eroare minima realizeaza clasificarea formelor pe baza compararii raportului de plauzibilitate cu un anumit prag. Definim :
raportul de plauzibilitate L ( x ) = ![]() (al claselor w w , relative la forma X), unde f( x | w ) si f( x | w ) sunt functiile
densitate ale vectorului X conditionate de w respectiv w
(al claselor w w , relative la forma X), unde f( x | w ) si f( x | w ) sunt functiile
densitate ale vectorului X conditionate de w respectiv w
pragul raportului de
plauzibilitate n = ![]()
si notam cu h = - ln L
Relatia lui Bayes devine :
h( x ) >< ln ![]() T X I {
T X I {![]() (2)
(2)
Demonstratie :
h( x ) >< ln ![]() - ln L >< - ln n L >< n
- ln L >< - ln n L >< n ![]() >< n
>< n 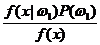 ><
>< ![]() P ( w | X
) >< P ( w | X
) (conform relatiei (1)) T X I{
P ( w | X
) >< P ( w | X
) (conform relatiei (1)) T X I{![]()
Testul de clasificare Bayes poate duce la situatii de ambiguitate, in cazul egalitatii membrului stang. De aceea se evalueaza performanta testului prin calcularea probabilitatii erorii de clasificare. La egalitate se obtine ecuatia suprafetei de separatie:
L (x) = n
ce imparte spatiul Rn in doua regiuni
R1 : L (x) ≥ n si R2: L (x) < n
Eroarea de clasificare a formei X apare cand se atribuie X regiunii R2 in cazul in care XI R1 sau daca X se atribuie lui R1 cand in realitate XI R2
Probabilitatea erorii de clasificare e este :
e = P (XI R2|w ) P
(w )+ P
(XI R1|w ) P
(w ) =
P (w ) ![]() + P (w )
+ P (w ) ![]()
Din R1 R2 = Rn T
![]() +
+ ![]() =
= ![]()
Deci se obtine :
e = P (w ) + ![]() P (w ) f
( x | w ) - P (w ) f
( x | w ) dx (2a)
P (w ) f
( x | w ) - P (w ) f
( x | w ) dx (2a)
Pentru minimizarea lui e trebuie ca termenul integral din relatia (2a) sa fie negativ:
P (w ) f ( x | w ) - P (w ) f ( x | w
Deci R1 e definit prin
P (w ) f ( x | w P (w ) f ( x | w ) relatie identica cu relatia (2)
In ipoteza ca densitatile de probabilitate conditionate f ( x | w ) si f ( x | w ) sunt normal distribuite, avand vectorii medie m si m , si matricele de covariatie S si S se poate scrie relatia echivalenta :
(x - m )T S (x - m ) - (x - m )T S (x - m ) + ln ![]() >< 2 ln
>< 2 ln ![]() TX I {
TX I {![]() (3)
(3)
Demonstratie:
Din relatia (2) avem ln![]() >< ln
>< ln ![]() ,
,
Inlocuind f ( x | w ) =![]() exp(-
exp(-![]() (x - m )T S (x - m )) (vezi mai jos def. 3) si f
( x | w ) => (x - m )T S (x - m ) - (x - m )T S (x - m ) + ln
(x - m )T S (x - m )) (vezi mai jos def. 3) si f
( x | w ) => (x - m )T S (x - m ) - (x - m )T S (x - m ) + ln ![]() >< ln
>< ln ![]() (q.e.d.)
(q.e.d.)
Definitia 1 : Vectorul-medie al unui vector aleator n-dimensional X=
(x xn)T este vectorul coloana mX m mn )T = ( E x , ., E xn )T ![]() E (X)
E (X)
unde sij=cov(xi xj)=covarianta,
sii=Var(xi xi si si varianta
/ dispersia si = abaterea medie patratica)
Definitia 2 : Matricea de covariatie SX I Rn x n este matricea patratica de
ordin n, asociata lui X (un vector aleator n-dimensional X= (x xn)T (cu componente
ce au media m si dispersia S)), definita ca: SX= E ( ( X - E ( X ) ) ( X - E ( X ) )T) = E ( X XT ) -E (X) E ( XT ). Deci SX=
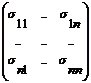
Definitie 3 : Un vector aleator n-dimensional X= (x xn)T (cu
componente ce au media m si dispersia S) este repartizat
normal (sau gasussian, notat f
(x) ![]() N (m S)), daca matricea de
covariatie S SX este pozitiv definita si
are functia de densitate de probabilitate f(x)=
N (m S)), daca matricea de
covariatie S SX este pozitiv definita si
are functia de densitate de probabilitate f(x)=![]() exp(-
exp(-![]() (x - m)T S (x - m)), unde
m mX e vectorul-mediu al lui X. Functia d(x, m S)=((x -
m)T S (x - m))½
este distanta Mahalanobis intre vectorii coloana x si m
asociata matricii simetrice S
(x - m)T S (x - m)), unde
m mX e vectorul-mediu al lui X. Functia d(x, m S)=((x -
m)T S (x - m))½
este distanta Mahalanobis intre vectorii coloana x si m
asociata matricii simetrice S
4. Algoritmul lui Bayes de risc minim (extinde algoritmul cu eroare minima de clasificare)
Notam cu cij costul clasificarii eronate a formei X I wj cand de fapt este wI i, j 2) si presupunem ca o decizie eronata este mai scumpa decat o decizie corecta:
Pentru c12 > c11 si c21 > c22 in urma minimizarii costului mediu
r = ![]()
![]()
![]() cij P( wi ) f
(x | wi) dx.
cij P( wi ) f
(x | wi) dx.
Se obtine relatia :
![]() ><
>< ![]()
![]() T X I {
T X I {![]() (4)
(4)
Pentru cazul cand c12-c11=c21-c22 (ex. cazul particular c11=c22=0 si c12=c21) din relatia de calcul al algoritmului de risc minim (4) se obtine relatia algoritmului Bayes cu eroare minima de clasificare (2).
Daca in membrul stang al ecuatiilor (1) si (4) apare o situatie de egalitate nu se poate trage nici o concluzie. In consecinta se poate atribui forma uneia dintre clase, sau se rafineaza testul prin adaugarea de noi caracteristici, sau se aplica alt algoritm.
Odata ce clasificatorul a fost proiectat si antrenat, in situatia in care densitatile de probabilitate conditionate ale vectorilor caracteristicilor selectate sunt cunoscute pentru fiecare clasa sau pot fi estimate precis dintr-un set de esantioane (set de antrenare), se aplica regula de clasificare Bayes, care minimizeaza probabilitatile de recunoastere eronata sau riscul mediu. In situatia, mai des intalnita, cand acestea nu sunt cunoscute se utilizeaza fie functiile discriminant, fie metode neparametrice de clasificare.
II. Clasificare Bayes pentru M clase (M>2)
Pentru M (M > 2) clase de forme din spatiul Rn , notate w wM, o forma noua de intrare X (vector aleator n-dimensional de caracteristici) poate fi clasificata prin :
a) compararea probabilitatilor aposteriori dupa regula de forma :
P ( wi | X ) >< P ( wj | X
) => X I{![]() , pentru j j (5)
, pentru j j (5)
ceea ce e echivalent cu
P ( wi ) f (x | wi >< P ( wj ) f(
x | wj)
=> X I{![]() , pentru j j (6)
, pentru j j (6)
unde :
i, j =1.M, cu M > 2
P ( wi | X ) este probabilitatea aposteriori (probabilitatea ca dupa ce X a fost clasificat, forma X sa apartina clasei wi
P ( wi ), P ( wj ) este probabilitatea apriori a clasei wi (respectiv wj) (probabilitatea ca o forma sa apartina clasei wi, respectiv wj
b) decizie bazata pe minimizarea riscului (costului mediu) pentru M clase
Pentru calculul riscului avem expresia :
r = ![]()
![]()
![]() cij P( wi ) f
(x | wi) dx (7)
cij P( wi ) f
(x | wi) dx (7)
unde :
Ri sunt regiunile din spatiul Rn corespunzand claselor wi, pentru 2 i .M
iar cij este costul deciziei eronate X I wj cand clasa adevarata este wi
Algoritmul Bayes de risc minim poate fi scris pentru cazul a M clase de forme:
![]() cij P( wi ) f (x | wi)
<
cij P( wi ) f (x | wi)
< ![]() cik P( wi ) f (x | wi
cik P( wi ) f (x | wi
pentru k j T X Iwj,
i,j,k .M (8)
In cazul particular cii = 0 si cij=1 pentru i j algoritmul capata forma de la punctul (a)
Covrola Corolar : In ipoteza ca f ( x | wi ) si f
( x | wj ) sunt densitati normale cu vectorii
medie mi si mj, si matricile de covarianta Si si Sj se poate scrie relatia echivalenta:
(x
- mi)T Si (x - mi)T - (x - mj)T Sj (x - mj)T + r : In ipoteza ca f ( x | wi ) si f ( x | wj ) sunt densitati
normale cu vectorii medie mi si mj, si matricile de
covarianta Si si Sj se poate scrie relatia
echivalenta: (x - mi)T Si (x - mi)T - (x - mj)T Sj (x - mj)T +
Clasificatori si functii discriminant
+ ln ![]() >< 2 ln
>< 2 ln ![]() , T X I wi (9)
, T X I wi (9)
+ ln ![]() >< 2 ln
>< 2 ln ![]() , T X I wi (9)
, T X I wi (9)
Pentru cazul a M clase de forme din spatiul Rn (M > 2), notate w wM, se considera cunoscute probabilitatile apriori P ( wi ) si densitatile conditionate f (x | wi i M.
Proiectarea unui clasificator presupune calcularea
explicita a unui set de M functii discriminant si selectarea
clasei care corespunde maximului ![]() gk::
gk::
gk : Rn R, 1 k M, astfel ca gi (X) > gj (X), pentru j j (9)
Cand inegalitatea din ecuatia (8) nu este stricta se ajunge la ambiguitatea deciziei, caz in care clasificarea nu poate fi decisa. Solutia: fie se alege oricare din cele doua clase wi, wj fie se alege un algoritm mai puternic.
Ex: Se poate alege setul de functii discriminant de forma:
a) in cazul algoritmului Bayes cu eroare minima de clasificare
gk (x) = ln P (wk) + ln f (x | wk sau gk (x) = P (wk f (x | wk pentru 1 k M
b) in cazul algoritmului Bayes cu risc minim
gk (x) = -![]() cik P( wi ) f
(x | wi
cik P( wi ) f
(x | wi
Functii discriminant de tip Bayes pentru vectori de caracteristici repartizati normal
Pentru forme X de intrare din spatiul Rn cu densitati conditionate normale de forma :
f ( x, wi ) ![]() N (mi Si i M
N (mi Si i M
Luam in considerare un clasificator Bayes cu eroare minima de clasificare pentru M clase, cu functiile discriminant :
gk (x) = ln P (wk) + ln f (x | wk ), pentru 1 k M
se obtine pentru vectori repartizati normal relatia:
gk (x) = - (x - mk)T![]() (x - mk) -
(x - mk) - ![]() ln 2p -
ln 2p - ![]() ln (det
ln (det ![]() ) + ln P(wk (10)
) + ln P(wk (10)
selectarea clasei corespunzand lui ![]() gk:
gk:
Cazuri particulare:
a) Pentru ![]() = s In (componente vectorilor X
sunt independente avand dispersia s ) se obtine relatia:
= s In (componente vectorilor X
sunt independente avand dispersia s ) se obtine relatia:
gk (x) = - ![]() || x - mk||2 + ln P(wk k M (11)
|| x - mk||2 + ln P(wk k M (11)
b) Pentru clase echiprobabile P(wk) = 1/M atunci functiile discriminant sunt
gk (x) = || x - mk (12)
Clasificator utilizand cele mai apropiate esantioane (algoritmul K-NN - "the kth Nearest Neighbour") in ipoteza binara, aceasta regula de clasificare este simplu de aplicat si consta in a acorda lui x clasa care este cel mai frecvent reprezentata printre cele k esantioane mai apropiate (pe baza distantei euclidiene) de x (se alege k impar). Dezavantajul ei consta in nevoia de a stoca toate esantioanele si de a le compara pe fiecare cu un esantion necunoscut.
Pentru k = 1 se obtine regula de clasificare pe baza celui mai apropiat esantion (The Nearest Neighbour): se aloca lui x clasa w sau w careia ii apartine cel mai apropiat din esantioanele x1, x2, . xN stocate in memorie. Pentru M > 2 clasa de apartenenta a lui x este stabilita de asemenea de clasa de apartenenta a celui mai apropiat vecin.
gk (x)=![]() {d2
(xF, x)} (13)
{d2
(xF, x)} (13)
unde xF - tot lotul cunoscut si repartizat pe clase, x - forma de clasificat.
Selectarea clasei se face
prin ![]() .
.
Clasificatorul bazat pe cel mai apropiat prototip. Se construieste cate un prototip pentru fiecare clasa cate un prototip prin medierea tuturor formelor deja cunoscute, apartinand acelei clase. Pentru o forma F reprezentata prin vectorul XF de caracteristici se calculeaza distantele dintre XF si vectorii medie ai claselor, distanta minima stabilind clasa de apartenenta (comparare este de tip template-matching cand vectorul medie este prototipul clasei sale):
min d2 (xF, mk) =|| x - mk||2=gk (x)= d2 (xF, mi0 T X Iwi0 (14)
Clasificatorul liniar are setul de functii discriminant:
gk (x) = - ![]() ( xT x - 2mkT x +mkT mk) + ln P(wk k M
( xT x - 2mkT x +mkT mk) + ln P(wk k M
gk (x) = wkT x + wk0 (15)
unde wk = ![]() mk, si wk0 = -
mk, si wk0 = -![]() mkT mk+ ln P(wk), pentru 1 k M
mkT mk+ ln P(wk), pentru 1 k M
Bibliografie : V.Neagoe, O. Stanasila - Recunoasterea formelor si retele neurale - algoritmi fundamentali, Ed. Matrix Rom, Bucuresti, 1998.
Problema : Fie patru clase de semnale
bidimensionale X= ![]() repartizate normal.
repartizate normal.
clasa w {A1=![]() , B1=
, B1=![]() , C1=
, C1=![]() , D1=
, D1=![]() },
},
clasa w {A2=![]() , B2=
, B2=![]() , C2=
, C2=![]() , D2=
, D2=![]() },
},
clasa w {A3=![]() , B3=
, B3=![]() , C3=
, C3=![]() , D3=
, D3=![]() },
},
clasa w {A4=![]() , B4=
, B4=![]() , C4=
, C4=![]() , D4=
, D4=![]() }.
}.
Se cere:
a) Calculati probabilitatile apriori (P(w ) , P(w ) , P(w ) , P(w )), vectorii medie (m m m m ) si matricele de covariatie (S S S S
b) Ecuatia suprafetei de separatie
c) Reprezentarea grafica
d) Regula de decizie
e) Sa se clasifice vectorii : J1=![]() , J2=
, J2=![]() , J3=
, J3=![]() , J4=
, J4=![]() folosind
folosind
functiile discriminant de tip Bayes;
cel mai apropiat vecin;
cel mai apropiat prototip.
Laborator
In fisierul C: wine.names se afla descrierea unui set de date care reprezinta trei clase de vinuri. Prima clasa este formata din 59 de vectori de caracteristici, a II-a din 71 de vectori, iar ultima clasa contine 48 de vectori. In fisierul C: wine.data sunt prezentati toti acesti vectori, avand la inceput indexul clasei de apartenenta. Astfel, fiecare vector are 15 caracteristici.
Se introduc manual datele vinurilor in Matlab (excluzand indexul clasei), astfel incat 98 de vectori sa fie utilizati ca vectori de antrenare (vectori cunoscuti apriori) si 80 de vectori utilizati in testare. Vectorii vor fi alesi in ordinea prezentata in fisier, mai intai vectorii de antrenare si apoi vectorii de test, impartirea vectorilor in lot de antrenare si test este data la fata locului. Fiecare vector astfel introdus va reprezenta o linie in matricea de antrenare respectiv in cea de test. Fisierul C:wine.doc contine datele asezate astfel incat sa fie copiate cu usurinta in Matlab.
Se clasifica apoi vectorii de test, pe baza vectorilor de antrenare cu ajutorul algoritmului Bayes, apoi prin algoritmul Nearest Neighbour si prin Nearest Prototipe, notandu-se rezultatele.
Pentru a atribui valori unei
matrice in Matlab, se utilizeaza spatii pentru separarea elementelor
aceleiasi linii si ; pentru separarea liniilor. De exemplu
pentru a scrie matricea 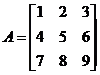 se utilizeaza
linia A = [1 2 3;4 5 6;7 8 9].
se utilizeaza
linia A = [1 2 3;4 5 6;7 8 9].
Avand un
vector V, pentru a alege toate elementele cu indexul cuprins in
intervalul [a;b] se utilizeaza selectia V(a:b). In
cazul unei matrice X(a:b,c:d) alege toate liniile avand indexul in
intervalul [a;b] si toate coloanele avand indexul in intervalul
[c;d] (a < b si c < d). O atribuire ar duce la o
matrice cu
b - a + 1 linii si c - d + 1 coloane. Prin folosirea
sintaxei X(a:b,:) se aleg toate liniile cu indexul in intervalul [a;b]
si toate coloanele matricei X.
Mai departe, toate cuvintele scrise cu rosu in cadrul unei linii de comanda in Matlab reprezinta variabile.
Functia np implementeaza algoritmul de recunoastere cel mai apropiat prototip:
[clt,cla] = np(x,xt,cl,nrva,nrvt);
unde x - matricea vectorilor de antrenare, vectori asezati pe liniile matricei pe baza carora se construiesc prototipurile claselor, xt - matricea vectorilor de test, asezati pe liniile matricei, cl - numarul claselor, nrva/nrvt - reprezinta un vector care contine numarul vectorilor din fiecare clasa in matricea de antrenare/test (implicit numarul vectorilor pe fiecare clasa este acelasi, deci, in cazul de fata, acesti parametrii sunt ignorati); clt/cla - matricele de confuzie pentru lotul de test/antrenare. Rata de recunoastere corecta va fi afisata pe ecran dupa fiecare rulare.
Functia nn implementeaza algoritmul de recunoastere cel mai apropiat vecin:
clt = nn(x,xt,cl,nrva,nrvt);
unde x - matricea vectorilor de antrenare, vectori asezati pe liniile matricei pe baza carora se construiesc prototipurile claselor, xt - matricea vectorilor de test, asezati pe liniile matricei, cl - numarul claselor, nrva/nrvt - reprezinta un vector care contine numarul vectorilor din fiecare clasa in matricea de antrenare/test (implicit numarul vectorilor pe fiecare clasa este acelasi, deci, in cazul de fata, acesti parametrii sunt ignorati); clt - matricea de confuzie pentru lotul de test. Rata de recunoastere corecta va fi afisata pe ecran dupa fiecare rulare.
Functia bayes implementeaza functiile discriminant de tip Bayes, facand concomitent si clasificarea corespunzatoare:
[cla,clt] = bayes(x,xt,cl,nrva,nrvt);
unde x - matricea vectorilor de antrenare, vectori asezati pe liniile matricei pe baza carora se construiesc prototipurile claselor, xt - matricea vectorilor de test, asezati pe liniile matricei, cl - numarul claselor, nrva/nrvt - reprezinta un vector care contine numarul vectorilor din fiecare clasa in matricea de antrenare/test (implicit numarul vectorilor pe fiecare clasa este acelasi, deci, in cazul de fata, acesti parametrii sunt ignorati); clt/cla - matricele de confuzie pentru lotul de test/antrenare. Rata de recunoastere corecta va fi afisata pe ecran dupa fiecare rulare.
|
Politica de confidentialitate |
| Copyright ©
2025 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |