sisteme concurente
Originea problematicii programarii concurente se regaseste la inceputul anilor ' Dar, inainte de aceasta, se poate vorbi de aspecte concurente la nivelul sistemului de operare, mai ales odata cu aparitia calculatoarelor paralele si a retelelor de calculatoare.
Cronologic vorbind, primele "simptome" de concurenta s-au manifestat la inceputul anilor , odata cu aparitia sistemelor seriale cu multiprogramare. Acestea au adus nou: (a) tehnica polling (prin care procesorul poate sonda periodic starea perifericelor), (b) lucrul cu intreruperi, (c) canalul de intrare- iesire (un procesor specializat pe efectuarea operatiilor de intrare- iesire) care poate lucra in paralel cu procesorul central.
Aceste mecanisme au permis introducerea unor tehnici noi de exploatare eficienta a unitatii centrale de prelucrare. Dintre acestea, s-au remarcat utilizarea zonelor de memorie de tip tampon (buffers) si dezvoltarea tehnicii spooling. Bufferele de memorie aveau rolul de a regla diferenta de viteza intre perifericele lente si procesoarele rapide. Tehnica spooling (Simultaneous Peripheral Operation On-Line) se refera pe de o parte la posibilitatea citirii in avans a programelor si pe de alta parte la posibilitatea afisarii asincrone a rezultatelor. Aceste doua directii evidentiau un aspect nou de paralelism, concretizat in posibilitatea suprapunerii in timp a executiei operatiilor de intrare- iesire si a calculelor aritmetice si logice.
Ca o extensie a sistemelor cu multiprogramare s-au impus sistemele interactive si sistemele multitasking. Principalele caracteristici specifice sistemelor interactive sunt: (a) tehnica de deservire a cererilor utilizatorilor in timp partajat (time-sharing), (b) redirectarea si (c) legarea in pipe.
Urmatoarea etapa a fost dezvoltarea sistemelor multiprocesor si a sistemelor multicalculator. Un sistem multiprocesor rezulta din interconectarea a doua sau mai multor procesoare cu memorii si echipament de intrare- iesire comune. Intr-un sistem multicalculator, calculatoarele sunt interconectate intre ele prin linii de comunicare formand o retea de calculatoare. Intr-o retea avem mai multe calculatoare autonome (independente) care pot sau nu sa comunice fiecare cu fiecare. Comparativ cu organizarea unei retele de calculatoare, un sistem multiprocesor este controlat de un acelasi sistem de operare, care asigura interconexiunea intre procesoare si toate componentele care concura la realizarea sarcinilor.
Daca doua sau mai multe calculatoare sau procesoare coopereaza intr‑o maniera oarecare atunci putem spune ca totalitatea resurselor lor formeaza un sistem distribuit. De aici sistemele multicalculator, retelele de calculatoare si si sistemele multiprocesor apar ca si cazuri particulare de sisteme distribuite. Retelele locale sunt apreciate ca cele mai adecvate si raspandite organizari fizice pentru sistemele cu prelucrare distribuita.
Exista numeroase asemanari intre sistemele multiprocesor si sistemele multicalculator. Cele mai multe asemanari rezulta din faptul ca ambele tipuri de sisteme suporta operatii efectuate paralel si sau concurent.
In acest paragraf ne vom opri asupra unor clasificari ale sistemelor de calcul in general si ale sistemelor concurente, in special.
O proprietate specifica sistemelor paralele si concurente este granularitatea - care reprezinta numarul de procesoare din sistemul respectiv [Braunl, 1993]. Un sistem cu granularitate fina, fine-grained, contine procesoare multe si nu foarte puternice. Daca proprietatea se refera la o aplicatie paralela sau concurenta, atunci granularitatea masoara numarul de procese, respectiv numarul de operatii elementare asociate unui proces. Astfel, o aplicatie paralela de granularitate fina va lucra cu multe procese, fiecare continand putine operatii elementare.
La nivelele inferioare, low-levels, paralelismul este mai mult fine-grained, in timp ce la nivelele superioare este coarse-grained.
Fiecare nivel lucreaza cu aspecte diferite ale procesului de paralelizare. Metodele si constructorii de la un nivel au aplicabilitate limitata la acel nivel si, in general, nu se pot aplica la alte nivele.
In tabela urmatoare [Braunl, 1993] punem in evidenta patru nivele de abstractizare pentru abordarea conceptului de paralelism. Dintre aceste nivele se remarca nivelul procedura, care corespunde paralelismului asincron, de tip coarse-grained si nivelul expresie, care corespunde paralelismului sincron, de tip fine-grained.
Un element important in tratarea fiecarui nivel este entitatea de calcul care prelucreaza datele. De acest element depinde ulterior programarea aplicatiei pe baza careia functioneaza sistemul paralel respectiv.
Nivelul program La acest nivel se executa simultan programe complete, cosiderate indivizibile. Calculatorul nu trebuie sa fie unul paralel, dar sistemul de operare trebuie sa fie multitasking, de exemplu implementat in time-sharing.
Nivelul procedura La acest nivel, sectiuni diferite ale aceluiasi program sunt executate in paralel. Aceste secvente de program in executie sunt numite procese si corespund procedurilor din calculul secvential. La acest nivel problemele sunt impartite in subprobleme, care au intre ele un grad mare de independenta, astfel incat sa se minimizeze schimbul de date intre procese.
|
|
Entitatea elementara de prelucrare |
Exemple de sisteme |
|
Program |
Job, task |
SO multitasking Sisteme in timp partajat |
|
Procedura |
Proces |
MIMD |
|
Expresie |
Instructiune |
SIMD |
|
Bit |
Instructiune interna |
SC von Neumann |
Tabel 1. Nivele de paralelism
Domeniile de aplicabilitate ale tratarii paralelismului la nivel de proces, respectiv de procedura, ar fi: programarea in timp real, programarea sistemelor destinate controlului proceselor, procesarea paralela cu scop general (general purpose parallel processing). Acest ultim domeniu cuprinde situatiile in care se cauta imbunatatirea performantelor unui sistem/aplicatie prin descompunerea unei probleme in subprobleme care pot fi distribuite surjectiv pe procesoare distincte.
Nivelul expresie La acest nivel aplicatia trateaza expresiile aritmetice de evaluat in paralel, pe componente. Acestea pot fi executate in taskuri simple, sincrone. De exemplu, calcularea unei sume de matrici poate fi foarte usor privita intr-un paralelism sincron prin asignarea calculului fiecarui element al matricei suma cate unui procesor.
Conceptele folosite la acest nivel sunt vectorizarea si paralelismul datelor.
Nivelul bit. La acest nivel apare executia paralela a operatiilor pe biti la nivel de cuvant de memorie. Acest nivel de paralelism se gaseste in orice microprocesor.
O clasificare importanta si cuprinzatoare a sistemelor de calcul a fost data de Flynn [Flynn, 1972] si poate fi deosebit de utila si astazi pentru prezentarea diferitelor modele de arhitecturi concurente. Aceasta clasificare se bazeaza pe numarul de fluxuri independente de instructiuni si numarul de fluxuri independente de date din sistem.
Flynn a impartit sistemele in patru tipuri: SISD, SIMD, MISD, MIMD. In continuare vom face cateva consideratii pe marginea fiecarei clase de sisteme identificate de Flynn.
Un sistem SISD, Single Instruction stream Single Data stream, este modelul conventional pentru un calculator uniprocesor. Un astfel de sistem va executa o singura secventa de instructiuni la un moment dat, asupra unui unic set de date pe care il primeste la inceputul executiei. Acesta este modelul original von Neumann pentru functionarea calculatoarelor.
Practic, orice model serial de abordare a activitatilor unui sistem conduce catre un exemplu de sistem SISD. Acesta poate fi: (1) determinist - daca ordinea in care sunt executate instructiunile este unic determinata de starea variabilelor aplicatiei de executat sau (2) nedeterminist - daca activitatile au la un moment dat mai multe variante de continuare a executiei.
Un sistem SIMD, Single Instruction stream Multiple Data stream, contine mai multe elemente de prelucrare, dar care sunt destinate sa execute aceeasi secventa de prelucrare la un moment dat. De aceea, modelele de procesoare inserate in astfel de sisteme pot fi unele simple: nu trebuie sa preia instructiuni din memoria proprie ci numai sa primeasca spre prelucrare instructiunile de la o unitate centrala (comuna) de control. Totusi, aceste procesoare trebuie sa poata opera pe date independente, cum ar fi elementele unui vector sau ale unei structuri multidimensionale liniarizata. Orice masina care poate executa instructiuni pentru prelucrarea in paralel a elementelor unui vector poate fi considerata de tip SIMD. Componenta destinata prelucrarii vectorilor poate fi un procesor specializat, atasat procesorului central, format din mii de procesoare mici si incarcat numai pentru a executa operatiile cu vectori.
Din punct de vedere practic, exista o varietate mare de aplicatii care solicita operatii cu vectori sau cu matrici. Importanta unor astfel de aplicatii poate sa conduca la utilizarea unor sisteme de calcul extrem de scumpe si de performante, cum ar fi supercalculatoarele create exclusiv pentru executarea unor activitati predefinite.
Sistemele MIMD, Multiple Instruction stream Multiple Data stream, sunt sistemele capabile sa execute simultam mai multe preluari si prelucrari de instructiuni asupra a diferite seturi de date. Aceste instructiuni nu trebuie sa fie dependente unele de altele si pot fi executate asincron. Aceasta este o categorie foarte larga de sisteme si include retelele de calculatoare si sistemele multiprocesor rezultate din calculatoare independente.
Observatie Este evident ca din clasificarea anterioara lipseste combinatia MISD, Multiple Instruction stream Single Data stream, care s-ar referi la un sistem care poate prelucra un acelasi flux de date in mai multe fluxuri (secvente) de instructiuni. La vremea la care Flynn a dat aceasta organizare a sistemelor, categoria MISD se considera a fi vida. Astazi, tinand cont in special de posibilitatile oferite de prelucrarea paralela, se poate constata ca sunt suficiente modele care se pot incadra in tipologia MISD. Dintre acestea probabil unul dintre cele mai reprezentative este executia de tip pipeline. Chiar functionarea procesorului poate fi privita ca o executie in pipeline daca se considera urmatoarele unitati functionale ale procesorului ca fiind faze pipeline: (1) fetch - extragerea urmatoarei instructiuni din programul de executat, (2) decode - decodificarea codului de instructiune preluat anterior, (3) execute - executarea microoperatiilor corespunzatoare instructiunii decodificate anterior, (4) write-back - scrierea rezultatului in zona de memorie rezervata acestui scop.
Clasificarea data de Flynn pentru sistemele de calcul poate fi sintetizata in urmatoarea tabela [Braunl, 1993]:
|
SC uniprocesor |
SISD |
SIMD |
SC vectoriale PARALELISM SINCRON (exista un singur thread de control) |
|
SC in pipeline |
MISD |
MIMD |
SC multiprocesor SC distribuit PARALELISM ASINCRON (exista mai multe threaduri de control; fiecare procesor executa propriul lui program) |
Tabel 2. O clasificare a sistemelor concurente
Din aceasta tabela sintetica se poate observa ca numai modelul SISD este ne-specific calculului nesecvential, fiind asociat cu sistemul uniprocesor
Dupa interconexiunea dintre procesoare putem detalia clasele MIMD si SIMD astfel:
MIMD - sisteme multiprocesor = sisteme strans cuplate si sisteme cu comunicare prin memorie partajata
sisteme distribuite = sisteme slab cuplate si sisteme cu comunicare prin schimb de mesaje
SIMD - sisteme vectoriale (vector computer) = sisteme necuplate sau cu "lant" intre elementele de prelucrare
sisteme scalare (array computer) = sisteme cuplate prin conexiuni de retea.
Concurent inseamna "in acelasi timp". [Bacon, 1998]
Un sistem concurent trebuie sa gestioneze activitati separate, care se desfasoara simultan. Mai exact, vom considera ca doua activitati sunt concurente daca, la un acelasi moment, fiecare activitate se afla intr‑un punct situat intre punctul de start si punctul final al desfasurarii sale (ambele activitati sunt in desfasurare).
Dupa Bacon [1998], activitatile concurente pot fi privite din doua puncte de vedere si anume: din punctul de vedere al structurii interne a sistemului, rezultand sisteme inerent concurente, sau din punctul de vedere al aplicatiilor care stau la baza functionarii sistemului respectiv, rezultand aplicatii potential concurente. In cele ce urmeaza vom lua in discutie caracteristici ale acestor entitati delimitate de Bacon.
Un sistem este inerent concurent daca gestioneaza activitati care se pot intampla simultan in exteriorul sistemului de calcul, de exemplu utilizatori care doresc sa execute programe sau clienti care vor sa execute tranzactii.
O posibilitate de obtinere a concurentei este determinarea solutiei prin aplicarea unui algoritm concurent de divizare a problemei in parti care, la randul lor, pot fi rezolvate prin activitati desfasurate in paralel. Aceasta varianta este recomandata pentru aplicatiile cu volum mare de calcule si de date si in care este importanta cerinta de obtinere a rezultatelor in timp real. Aplicatiile de acest sunt aplicatii potential concurente. Abordarea concurenta imbunatateste rezolvarea secventiala cel putin din doua puncte de vedere: (1) un acelasi raspuns poate fi obtinut la acelasi pret folosind un numar mai mare de calculatoare mai ieftine sau (2) un model mai performant (mai scump) de realizare a sistemului fizic poate conduce la rafinarea rezultatului problemei.
Dupa cum am definit si anterior, sistemele care trebuie sa gestioneze simultan activitati care se desfasoara in mediul exterior lor sunt cunoscute ca sisteme inerent concurente. Din aceasta categorie fac parte:
sistemele in timp real;
sistemele de gestiune a bazelor de date si de prelucrare a tranzactiilor;
sistemele de operare.
In fiecare caz, implementarea sistemului este de preferat sa fie distribuita pe mai multe sisteme de calcul (host-uri, noduri, site-uri) decat sa abordeze o metodologie centralizata de organizare si gestionare.
Principala caracteristica a sistemelor in timp real consta in faptul ca functionarea lor trebuie sa tina cont de anumite restrictii de timp impuse de mediul inconjurator sistemului respectiv. Importanta restrictiilor temporale impuse imparte sistemele in timp real in (a) sisteme puternic dependente de timp si (b) sisteme slab dependente de timp.
Din alt punct de vedere, sistemele in timp real pot fi: (a) statice, respectiv (b) dinamice. Intr-un sistem static, analiza activitatilor pe care sistemul trebuie sa le execute poate fi facuta in etapa de proiectare a sistemului. Intr-un sistem dinamic, cererile asupra sistemului pot fi adresate la orice moment de timp, neregulat si imprevizibil. Mai mult, un sistem dinamic trebuie sa poata raspunde acestor cereri in timp real si respectand parametrii de performanta impusi de clientul care a adresat cererea.
Cele mai reprezentative exemple de sisteme in timp real sunt cele proiectate pentru controlul proceselor, de exemplu sisteme de monitorizare a pacientilor unei unitati sanitare, sisteme de monitorizare a zborurilor, a motoarelor vehiculelor, sisteme de control al traficului aerian, controlere pentru roboti, sisteme de procesare si vizualizare de imagini in timp real etc..
In astfel de sisteme de control la nivel de proces (process control) scenariul comun de functionare se bazeaza pe faptul ca datele sunt colectate - prin controlul (testarea) sistemelor care genereaza acele date - si apoi analizate prin algoritmi specifici. Atat colectarea cat si analiza acestor date sunt evenimente periodice si previzibile. Totusi, aceasta activitate periodica de colectare si analiza trebuie sa poata raspunde unor evenimente neprevazute. Astfel, se remarca doua tipuri de activitati: de monitorizare si de control. Monitorizarea implica colectarea datelor, in timp ce controlul implica corelarea periodica si eficienta a datelor, atat cu scopul functionarii sistemului, cat si cu cererea clientului care asteapta un raspuns din partea sistemului.
Sistemele de control la nivel de proces sunt sisteme in timp real puternic dependente de timp si statice.
Proiectarea sistemelor in timp real trebuie sa prevada situatiile limita in care sistemul insusi trebuie sa decida importanta evenimentelor neprevazute care apar. Astfel, sistemul trebuie sa poata decide la un moment dat daca este mai important sa monitorizeze datele astfel incat rezultatele sa fie de o precizie maxima sau este de preferat diminuarea preciziei si furnizarea raspunsului intr‑un timp minim posibil, eventual chiar in timp real.
Caracterul concurent al acestor sisteme rezulta cel mai adesea tocmai din faptul ca mai multe calculatoare mici sunt corelate astfel incat sa controleze un proces industrial sau experimental de dimensiune si/sau de importanta mare.
Nu toate sistemele in timp real sunt sisteme distribuite de tip multicalculator. De exemplu, o aplicatie simpla, un robot, un motor de vehicul pot incapsula un singur calculator de control, pentru care partea de software va asigura singura atat monitorizarea cat si controlul intregului sistem. Mai mult, aplicatiile sunt distribuite daca sunt scrise astfel incat sa permita desfasurarea simultana a mai multor activitati distincte.
O alta clasa de sisteme in timp real sunt sistemele multimedia. Spunem despre un sistem ca este multimedia daca are posibilitatea sa imbogateasca afisarea clasica prin text si grafica cu imagini in miscare si/sau voce. Presupunand ca o statie de lucru are un sistem de navigare bazat pe ferestre, unele ferestre pot fi folosite pentru video. Multe aplicatii, cum ar fi: telefonia‑video, posta‑video sau videoconferintele trebuie sa afiseze in timp real o persoana care vorbeste. In acest caz partea video (imaginea) si partea audio (vocea) trebuie sa se sincronizeze astfel incat, pe ecranul participantilor la comunicare acestea sa ajunga simultan (vocea trebuie sincronizata in special cu miscarea buzelor vorbitorului filmat).
Videoconferintele si telefonia‑video functioneaza in timp real. Daca sistemul nu memoreaza nici un fel de date, acestea sunt pierdute dupa incheierea transmisiei. Posta‑video presupune transmiterea de mesaje electronice care pot contine text, combinat cu voce si cu imagini in miscare. Aici componentele acestea trebuiesc memorate si transmise la statia care va receptiona mesajul. O data ce este declansat procesul de citire a mesajului, sistemul trebuie sa respecte anumite cerinte specifice caracterului de sistem in timp real cu privire la transmiterea sincronizata a componentelor si la minimizarea ratei de intarziere. Probleme de sincronizare in sistemele multimedia sunt dezbatute in [Bacon, 1998].
Statiile multimedia sunt considerate sisteme in timp real cu atat mai mult cu cat, intr‑o transmisie de telefonie‑video, de exemplu, datele alterate pot fi retransmise numai daca intervine explicit o voce umana care sa ceara repetarea lor. De aici rezulta ca un sistem multimedia este unul slab dependent de timp.
Sistemele multimedia isi au originea in sistemele cu timp partajat (timesharing). Diferenta este una cantitativa deoarece un sistem multimedia solicita o putere de prelucrare mai mare, latime de banda de retea, capacitate de memorare mai mare si aplicatii soft care sa poata valorifica aceste facilitati.
Comparand un astfel de sistem slab dependent de timp cu un sistem de control se remarca o diferenta calitativa deoarece intr un sistem de control este mult mai restrictiva cerinta ca raspunsul primit sa fie in timp real, un sistem de control fiind unul puternic dependent de timp.
In concluzie, cerintele care se impun pentru realizarea unui sistem in timp real ar putea fi:
sa suporte activitati independente; dintre acestea, unele pot fi periodice (cum este colectarea de date) sau neprevizibile (cum este cerinta de a raspunde la un semnal de tip alarma);
sa respecte cerintele fiecareia dintre activitatile in desfasurare;
sa aiba in vedere posibilitatea ca unele activitati sa poata coopera pentru satisfacerea unor scopuri comune.
Aplicatiile de baze de date vizeaza un volum mare de date, cum ar fi datele stocate pe medii permanente. Actiunea specifica a unui utilizator de baze de date consta in interogari asupra datelor din acea baza de date. Spre deosebire de un utilizator, proprietarul bazei de date se preocupa de intretinerea bazei de date, astfel incat datele continute sa respecte caracteristicile unei baze de date consistente, actuale, sigure, corecte.
Prin sistem de gestiune a bazelor de date (DBMS DataBase Management System) ne referim la un sistem de date proiectat sa interactioneze cu utilizatorii sai si sa organizeze citirile si scrierile de date in sistem astfel incat sa raspunda optim cerintelor utilizatorilor. Un sistem DBMS este unul concurent deoarece trebuie sa satisfaca simultan cerintele mai multor utilizatori.
In cele ce urmeaza, prin tranzactie denumim generic o cerere a unui client adresata bazei de date. Cel mai simplu exemplu de sistem de prelucrare a tranzactiilor este serviciul oferit de un automat bancar (ATM Automatic Teller Machine).
Considerente legate de proiectarea si organizarea sistemelor de tip DBMS se pot gasi in [Bacon, 1998]. O problema importanta care apare in DBMS consta in solutionarea conflictelor generate la nivelul cererilor (interogarilor) adresate bazei de date. Accesul concurent este o solutie viabila atat timp cat acesta reuseste sa scada timpul de raspuns al DBMS la cererile utilizatorilor. Mai mult, din punctul de vedere al bazei de date, tranzactiile care numai citesc date se pot executa in paralel, indiferent de numarul acestora.
In contextul celor prezentate anterior, un exemplu de aplicatie reprezentativa este problema cititor-scriitor.
Pentru realizarea unui sistem de gestiune a bazelor de date si de prelucrare a tranzactiilor se impun cateva cerinte importante cum ar fi:
sa suporte activitati independente;
sa asigure posibilitatea ca activitati diferite sa poata accesa si actualiza date comune, dar numai in limitele pastrarii consistentei si corectitudinii bazei de date;
sa asigure ca rezultatele tranzactiilor au fost depozitate in zone de securitate maxima, inainte ca utilizatorul sa fie anuntat ca tranzactia s‑a incheiat cu succes.
In acest context este important sa se deosebeasca un calculator destinat unui utilizator de un calculator multiuser. In prima categorie intra orice sistem de calcul de la calculatorele personale mici si relativ ieftine pana la statiile de lucru cuprinse in retele de calculatoare. Sistemele multiuser sunt formate din mai multe minicalculatoare sau microcalculatoare performante, destinate fiecare unui numar mic de utilizatori, sau din mai multe sisteme multiprocesor de tip mainframe sau supercalculatoare. Fiecare dintre aceste structuri se bazeaza pe configuratii hardware specifice, in concordanta cu caracterul concurent al aplicatiilor pe care le vor suporta.
Intr-un sistem singleuser tastatura si ecranul utilizatorului sunt "impachetate" impreuna cu memoria si procesorul/procesoarele sistemului, rezultand astfel un singur sistem de calcul. Utilizatorii unui sistem multiuser acceseaza sistemul prin intermediul unui terminal. Terminalele sunt separate de memoria principala, de procesoarele centrale si de perifericele partajate in sistem. Functiile unui terminal sunt de obicei orientate pe anumite tipuri de activitati, de exemplu un terminal poate dezvolta o aplicatie de grafica sau un sistem de navigare bazat pe ferestre. Pentru executarea acestor functiuni, un terminal poate avea propria memorie interna si propriile procesoare. Se remarca de aici ca terminalul clasic format din monitor si tastatura este completat cu componente care sa-l transforme intr‑un calculator cu destinatie pre-fixata (special-purpose computer). Un sistem multiuser poate avea un numar mare de terminale, chiar situate la distanta fata de un calculator central si care sunt gestionate in grup prin terminale speciale.
Un sistem de operare de interes general ruleaza pe calculatoare personale, pe statii de lucru monoutilizator sau pe sisteme partajate. Scopul unui astfel de sistem de aplicatii este sa execute programele utilizatorilor si sa aloce acestor aplicatii resursele hardware solicitate (memorie, discuri, procesoare etc.).
Pricipalele caracteristici ale unui sistem concurent se regasesc bine reprezentate atat in sistemele singleuser cat si in sistemele multiuser moderne. Putem sa dam doua argumente in sustinerea acestei afirmatii: pe de o parte faptul ca perifericele tind spre o structura care le apropie de organizarea pe nivele a procesoarelor si, pe de alta parte, sistemul de operare, direct raspunzator de starea perifericelor, poate sa execute programe- utilizator cat timp perifericele executa diverse operatii de intrare-iesire.
Mai mult, intr‑un sistem singleuser, cat timp se executa o activitate de durata mai lunga (de exemplu paginarea unui document foarte mare) utilizatorul poate lansa in paralel executia altor taskuri (de exemplu, citirea ultimelor mesaje sosite prin e-mail). Pentru aceasta, sistemul de operare trebuie sa poata suporta simultan astfel de activitati distincte, concurente, prin rularea de aplicatii diferite odata cu gestionarea diferitelor componente din sistem.
Caracterul de sistem concurent este mai puternic la nivelul sistemelor multiuser prin executarea simultana a mai multor aplicatii utilizator, prin paralelizarea desfasurarii taskurilor perifericelor cu satisfacerea comenzilor curente ale utilizatorilor sistemului.
Tinand cont de clasificarea anterioara a sistemelor concurente, putem spune ca sistemele de operare gestioneaza evenimente care sunt mai degraba neregulate si neprevizibile decat periodice, iar procesul de incarcare a datelor de intrare/iesire este unul dinamic. In plus, consideratiile de timp in sistemele de operare sunt importante, dar nu de o importanta majora si inflexibile ca in sistemele in timp real.
In plus fata de consideratiile facute la nivelul unui sistem singleuser, pentru un sistem multiuser sistemul de operare (1) trebuie sa gestioneze partajarea resurselor sistemului intre diversi utilizatori astfel incat sa le ofere tuturor aceeasi calitate a serviciilor, (2) trebuie sa raspunda oricaror conflicte care pot sa apara intre cererile utilizatorilor asupra resurselor sistemului (memorii, timp de prelucrare, spatiu rezervat fisierelor). Cererile adresate sistemului de operare apar in mod dinamic si unele pot implica o serie de componente adiacente sistemului, pe care tot sistemul de operare trebuie sa le gestioneze.
Daca sistemul multi-utilizator este unul distribuit atunci se adauga noi valente sistemului de operare. De exemplu, apare posibilitatea ca mai multi utilizatori sa partajeze acelasi sistem de fisiere. De aici, sistemul de operare trebuie sa poata gestiona centralizat fisierele comune, trebuie sa aiba prevazute mecanisme specifice de protectie fata de erorile de disc sau caderile soft. Pentru toate aceste motive este de preferat ca sistemul de fisiere sa fie furnizat ca un serviciu de retea (network-based service). De asemenea, este de preferat ca un numar rezonabil de servere de fisiere sa poata furniza suficient spatiu de memorare si capacitate de prelucrare pentru toate calculatoarele din sistemul distribuit si nu numai pentru sistemele mici. Aceste servere partajate trebuie sa raspunda cererilor simultane ale diferitilor clienti, deci sunt sisteme concurente.
Sistemele de operare ale calculatoarelor care fac parte din sisteme distribuite trebuie sa contina soft pentru comunicare. La nivelul cel mai scazut, gestionarea unei conexiuni de retea este o actiune similara cu gestionarea unui periferic de viteza foarte mare. Diferentele apar mai ales din faptul ca datele care sunt lansate in retea pot fi expediate de oricare dintre statiile distribuite si nu numai de la un singur periferic. Calculatoarele pot trimite in sistem date sau mesaje de mare viteza, ceea ce face ca simultan pe canalele de comunicatie sa se transmita secvente de date de la diferite surse. La nivelele inalte ale gestionarii comunicarii in sistemele distribuite se pune problema corectitudinii si completitudinii datelor transmise. Gestionarea acestor situatii este un argument in favoarea afirmatiei ca insusi subsistemul de comunicare din cadrul unui sistem de operare distribuit este un sistem concurent.
In concluzie, principalele cerinte pentru realizarea unui sistem de operare ar fi:
sa suporte activitati independente la nivelul aplicatie (deci in exteriorul sistemului de operare), fie mai multe activitati ale unui singur utilizator, fie diferite activitati ale mai multor utilizatori; cererile pe care aplicatiile le adreseaza sistemului de operare sunt dinamice si neprevizibile;
sa suporte activitati diferite in interiorul aplicatiilor sale de tip: cereri simultane de la mai multi clienti ai sistemului si diverse taskuri de gestionare a componentelor distribuite in sistem;
sa permita diverselor activitati sa coopereze pentru obtinerea unor scopuri comune;
sa gestioneze conflictele care apar la alocarea resurselor din sistem;
sa asigure pastrarea corectitudinii datelor din sistem in urma operatiilor de intrare/iesire asupra acelorasi zone de memorie;
sa asigure corectitudinea executiei unei activitati, chiar daca aceasta a fost descompusa in mai multe taskuri care au fost executate paralel sau concurent cu taskurile altor activitati.
Serverele de informare sunt cazuri particulare de sisteme inerent concurente, cel mai bine fiind reprezentate de serverele de WEB.
In 1990 Tim Berners-Lee a dezvoltat un sistem standard de tip hipermedia, numit World Wide Web, pe scurt, WWW. Domeniul de aplicare initial a fost fizica nucleara, la centrul CERN, Elvetia. Esenta sistemului consta in faptul ca nucleul sistemului il reprezenta partea de comunicare in retea si astfel se crease posibilitatea transferului in sistem a paginilor hipermedia, fara restrictii (world wide).
In 1993 centrul NCSA (National Center for Supercomputing), Universitatea din Illinois, a dezvoltat browserul Mosaic. Importanta si noutatea acestei aplicatii era interfata comoda, orientata pe ferestre, care recunostea transferul paginilor hipermedia intr‑un sistem de informare. Incepand cu Mosaic, amploarea pe care au luat-o sistemele de tip WWW a fost exploziva. Enorm de multe companii, universitati si particulari si-au construit servere de informare care sa poata fi citite (vizitate) de oricine are un browser de navigare.
Fiecare pagina hipermedia poate sa contina text, imagini si legaturi catre alte pagini. O astfel de pagina este creata folosind un limbaj de marcare de tip HTML (HyperText Markup Language), care este similar cu limbajul standard SGML. In plus fata de SGML, limbajul HTML are si instructiuni referitoare la modul de afisare a paginii create.
Intr-un server de informare cum este WWW fiecare pagina este identificata printr-un nume, adica o adresa URL (Universal Resource Locator), care se foloseste ca legatura (link) catre pagina respectiva. Daca o pagina P-parinte trebuie sa vada (sa contina o legatura catre) o alta pagina, P-copil, atunci in pagina P-parinte afisata vom avea un text de legatura (highlighted) catre pagina P-copil. In acelasi timp, codul HTML al paginii P-parinte va contine atat textul de legatura cat si adresa URL a lui P-copil. Deci, in pagina parinte nu apare obligatoriu adresa URL a paginii copil. Pentru a deschide pagina copil, este suficient un click de mouse pe textul de legatura (link) din pagina parinte. Pentru a localiza pagina copil, browserul contacteaza serverul care contine pagina identificata de linkul ales pe pagina parinte, transfera informatia furnizata de acel server si o afiseaza in locul paginii parinte. Protocolul de comunicare respectat de browserul de web si de serverul de web implicate in secventa de operatii anterioare este numit http, hypertext transfer protocol.
Fiecare client (browser) lucreaza secvential, putand sa vizualizeze (sa afiseze) la un moment dat o singura pagina. Un server oarecare poate sa primeasca concurent oricate cereri de furnizare de pagini de informatii. Deci avem aici un alt exemplu in care serverul poate sa aiba mai multi clienti simultan.
O extindere recenta in tehnologia paginilor web este adaugarea de secvente animate pe pagini, scrise de obicei in limbajul de programare Java. Aici prelucrarea concurenta poate fi facuta la nivelul clientului pentru a mari viteza de animare si pentru a permite animatiei sa co-existe pe pagina in paralel cu actiunile utilizatorului, de exemplu cu perioada de incarcare a unei forme pe pagina curenta.
Fata de sistemele inerent concurente (concurente prin structura interna a componentelor lor), sistemele care functioneaza pe baza aplicatiilor potential concurente nu sunt sisteme concurente prin structura lor, ci dobandesc caracteristici de sisteme concurente prin natura aplicatiilor pe care le executa.
Caracterul concurent al unei aplicatii poate sa rezulte din unul dintre urmatoarele aspecte:
exista un volum mare de calcule care trebuiesc efectuate;
exista un volum mare de date care trebuiesc prelucrate;
se impune cerinta ca rezultatul aplicatiei sa fie furnizat in timp real;
echipamentele hardware permit o eventuala executie in paralel a activitatilor concurente.
In cele ce urmeaza vom aborda cateva tehnici de obtinere a unei solutii concurente pentru o problema data. Exemple concrete de utilizare si implementare a acestor metode se gasesc in [Bacon, 1998], [Quinn, 1994].
Replicarea (multiplicarea, copierea) codului si partitionarea (impartirea) datelor sunt doua metode prin care un algoritm secvential poate primi caracteristici de algoritm concurent.
Prin partitionare, volumul mare de date pe care trebuie sa le prelucreze aplicatia concurenta se imparte in secvente distincte, fiecare secventa fiind ulterior prelucrata de un alt proces/procesor. Programul de prelucrare poate sa fie acelasi sau se poate ca partitii diferite sa fie prelucrate de programe diferite. In cazul in care programul de prelucrare este unic, se poate prevedea ca fiecare prelucrare sa se execute pe baza unei copii a programului respectiv, adica sa se aplice o replicare a codului programului de prelucrare.
In figura urmatoare este reprezentata situatia in care solutia concurenta presupune atat partitionarea datelor, cat si replicarea codului.

Figura 1. Replicarea codului. Partitionarea datelor
Intr-o astfel de abordare, daca toate componentele trebuie sa functioneze pana la terminarea taskurilor proprii, atunci timpul total de functionare este egal cu timpul de initializare a executiei paralele, plus timpul maxim necesar componentei celei mai costisitoare de timp, plus timpul de sincronizare a rezultatelor componentelor. Un timp optim se obtine daca impartirea pe componente se poate face astfel incat componentele sa solicite timpi relativ egali de functionare (astfel timpii de asteptare sunt redusi la minim). Aceasta situatie este cea care maximizeaza si concurenta pentru executia acelui algoritm.
Aceasta metoda statica de partitionare este potrivita pentru probleme de gasire a unor clase particulare de puncte pentru functii date (radacini, puncte de intoarcere).
Fata de situatia descrisa anterior, pentru unele probleme este important ca odata ce una din componente isi incheie executia, algoritmul sa decida incheierea executiei si pentru toate celelalte componente. In acest caz se modifica considerabil timpul total de executie a algoritmului. Pentru aceeasi clasa de probleme, aceasta solutie este potrivita atunci cand este suficient sa se gaseasca o prima solutie a problemei.
O alta abordare simpla a concurentei este prelucrarea in pipeline. Aceasta presupune ca ansamblul activitatilor care trebuie aplicate datelor poate fi impartit in faze de prelucrare distincte, astfel incat diferite secvente de date sa treaca in flux de la o faza la alta.
Un exemplu clasic de prelucrare in pipeline este realizarea unui compilator pentru care fazele de lucru sunt: analiza lexicala, analiza semantica, verificarea tipurilor de date, generarea de cod s.a.m.d. Aici, imediat ce un modul a trecut de analiza lexicala el este trimis in faza de analiza semantica si automat un al doilea modul este incarcat pentru analiza lexicala.
In acest model este important ca diferite activitati sunt simultan in executie in diferite faze ale lor si trebuie sa se sincronizeze intre ele: sa astepte ca noile date sa devina disponibile sau, din contra, sa astepte ca faza urmatoare sa-si termine procesul asupra datelor curente.
Multi algoritmi pot fi reprezentati intr‑o structura arborescenta a spatiului lor de solutii. In aceste cazuri oportunitatea procesarii paralele este imediata daca ramuri diferite ale arborelui de reprezentare sunt independente. Aplicatiile potrivite pentru acest model sunt problemele de cautare. Cazul cel mai nefavorabil (traversarea intregului spatiu de solutii) este atins numai daca problema nu admite solutie. Altfel, algoritmul trebuie sa decida incheierea activitatilor ramurilor odata ce pe una din ramuri a fost gasita solutie.
Acest model este de asemenea potrivit pentru abordarea problemelor de recunoastere a formelor. Aici fiecare ramura de executat in paralel va putea fi traversata in mod repetat deoarece exista alternative diferite pentru atingerea unei solutii (cazuri nedeterministe). Mai mult, aici fiecare ramura poate avea asociata o probabilitate cu care sa conduca la solutie. In acest caz, algoritmul trebuie sa vizeze si selectarea combinatiei de ramuri care conduc la cea mai buna probabilitate de obtinere a unei solutii.
O structura arborescenta de abordare introduce noi aspecte de paralelism fata de caracteristicile simple, statice, de partitionare liniara descrise anterior. O problema noua care se ridica aici este cum sa se construiasca dinamic un numar rezonabil de activitati paralele si pentru fiecare sa se pastreze evidenta proceselor proprii si a procesoarelor implicate.
In sistemele de gestiune a tranzactiilor se impune accesul diferitelor tranzactii la aceleasi date comune. Exista cazuri particulare de sisteme in care datele nu pot fi partitionate (intr‑un sistem de rezervare a biletelor nu este eficient sa se distribuie pentru vanzare locuri diferite la case de bilete diferite). Caracterul concurent al unor astfel de aplicatii poate fi atins nu prin simpla partitionare a datelor ci prin partajarea datelor intre mai multe procese din sistem. O situatie specifica pentru aceasta abordare este urmatoarea: intreaga sarcina de efectuat este impartita in activitati si este retinuta intr‑o zona comuna de memorie ca o structura de date care poate fi folosita in comun de diferite entitati. Fiecare activitate citeste o lucrare din structura comuna de date, o marcheaza ca fiind luata spre executie si o trimite spre executie activitatii specifice.
O problema care se ridica este evitarea deteriorarii datelor odata cu accesul cocurent la zona comuna.
Aceste cateva abordari simple ale caracterului concurent la nivelul algoritmilor pun accent pe partitionarea datelor static sau dinamic, respectiv pe partitionarea codului intr‑o structura de tip pipeline. In general, acestea sunt optiunile programatorului care are de abordat un sistem potential concurent. Pentru sistemele inerent concurente, solutia cea mai potrivita foloseste partajarea datelor.
La nivelul aplicatiilor, se pot enunta cateva cerinte prin care sa se impuna caracterul concurent al solutiei problemei de rezolvat. Astfel, aplicatiile trebuie:
sa suporte activitati individuale;
sa poata gestiona aceste activitati de o maniera similara; aceste activitati trebuie sa poata fi create la cerere si intrerupte cand nu mai sunt necesare;
sa sincronizeze diferite activitati care se desfasoara simultan; sa asigure posibilitatea transferului de date intre activitatile simultane;
sa se adapteze fiecarei situatii particulare de tip: activitatile pot partaja date sau, din contra, trebuiesc impuse restrictii de acces comun la anumite date.
Aplicatiile vor fi scrise intr‑un limbaj de programare care, impreuna cu sistemul de operare gazda, sa aiba facilitati de implementare a conditiilor de mai sus.
In acest paragraf vom aborda o clasificare a sistemelor concurente, [Bacon, 1998], care deosebeste sistemele conventionale de cele experimentale. Din acest punct de vedere se remarca trei categorii de sisteme: (1) sisteme pentru dirijarea controlului (control-driven), (2) sisteme pentru dirijarea fluxului de date (data-driven) si (3) sisteme interogative (demand-driven).
Modelul conventional von Neumann este unul de tip 1, de dirijare a controlului: procesorul preia si executa o secventa de instructiuni in timp ce un contor de program (program counter) joaca rol de controller de secventa. In astfel de sisteme, posibilitatea executiei in paralel a unor secvente de instructiuni este o problema care poate fi rezolvata numai tinand cont de specificul sistemului respectiv. Mai mult, se pune intrebarea cum se pot identifica instructiunile care, din punct de vedere al semanticii aplicatiei, se pot executa in paralel.
Alte modele de dirijare a controlului sunt sistemele conventionale uniprocesor, sistemele multiprocesor bazate pe memorie partajata si sistemele multiprocesor- multicalculator. O caracteristica majora a acestor modele consta in faptul ca permit marirea numarului de componente ale sistemului.
Modelele bazate pe dirijarea fluxului de date si modelele interogative sunt reprezentate de arhitecturi specifice dintre care se remarca masinile suport pentru aplicatiile scrise in limbaje functionale. [Bacon, 1998]
Realizarea sistemelor concurente rezulta si prin utilizarea unei structuri hardware specifice. Astfel, un model hard de baza care sa suporte aplicatii concurente ar putea fi cel din figura urmatoare. Sagetile din aceasta reprezentare arata directia in care creste caracterul concurent, pe masura ce se dezvolta noi componente in sistem.
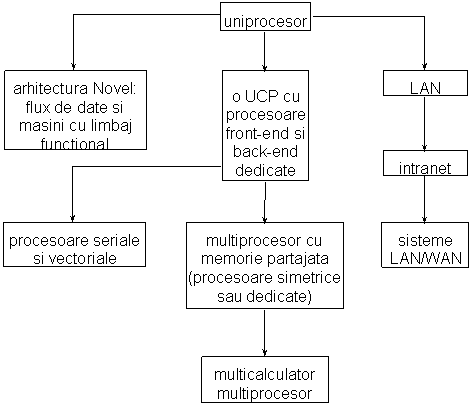
Figura 2. Topologii de sisteme concurente
Din aceasta figura se observa ca arhitecturile bazate pe flux de date si aplicatiile functionale sunt alternative pentru masinile conventionale von Neumann. Este de asteptat ca acestea sa exploateze toate aspectele de concurenta ale sistemului si ale aplicatiilor corespunzatoare, mai mult decat este posibil in sistemele conventionale, in care concurenta a aparut ca o completare oarecum fortata.
Pe axa centrala a reprezentarii anterioare se porneste de la un sistem uniprocesor care se completeaza pana la sistemele multiprocesor- multicalculator. Caracteristica esentiala a arhitecturilor din aceasta grupa rezulta din cresterea progresiva a puterii de calcul a sistemelor respective. Procesoarele dedicate pot gestiona diferite componente, dar un model consistent apare cand sunt folosite procesoare diferite pentru a executa programe rezidente in acelasi spatiu de memorie.
Retelele de calculatoare apar ca o alternativa pentru structurile complexe de interconectare necesare in sistemele multicalculator si multiprocesor. O retea medie de tip LAN poate fi folosita pentru conectarea completa a unui numar rezonabil de calculatoare in care comunicarea este realizata mai mult prin software specific, decat prin protocoale la nivel hardware. Pe masura ce reteaua LAN este completata cu noi resurse, calculatoarele astfel conectate pot fi folosite pentru prelucrari distribuite, permise (limitat numai) de softul de comunicare si de componentele sistemului de operare gazda.
Ori de cate ori se pune problema crearii unei arhitecturi noi de sisteme de calcul se va avea in vedere exploatarea unor resurse de prelucrare puternice si ieftine, a unor spatii de memorare cu acces rapid si de capacitate mare, a unor medii de comunicare cu largime de banda suficienta pentru a asigura o buna functionare a intregului sistem. Pe de alta parte, se va cauta valorificarea structurilor existente, atat in ceea ce priveste arhitecturile sistemelor deja recunoscute, cat si topologiile de interconectare cunoscute si verificate.
Pentru sisteme particulare, evident ca se vor experimenta modele noi de arhitecturi interne si topologii de interconectare.
In considerentele anterioare s-au evidentiat o serie de abordari intuitive ale notiunii de concurenta, rezultate in special din exemplificarea diferitelor tipuri de sisteme de calcul care recunosc activitati care sunt simultan in executie. Caracterul concurent a rezultat din doua aspecte diferite: fie mai multe secvente ale codului unui algoritm concurent sunt in curs de executie in paralel, fie datorita faptului ca mai multi clienti pot interoga sistemul simultan. In oricare dintre situatii, sistemul concurent este mai degraba unul distribuit pe mai multe calculatoare decat unul centralizat pe un singur sistem de calcul.
Definirea conceptului de functionare "in acelasi timp" se poate da corect numai in contextul in care se considera timpul ca element esential in functionarea unui sistem concurent.
In sistemele concurente sunt importante aplicatiile de sistem (software systems), implementate pe diverse configuratii hardware, care suporta desfasurarea simultana a mai multor activitati. Aceste activitati sunt dependente in diferite sensuri si presupunem ca, la nivelul lor, se poate defini un scop comun care devine obiectivul functionarii intregului sistem concurent. Acesta poate fi foarte general - de exemplu, sistemul sa suporte activitatile independente ale diferitilor utilizatori ai sistemului de operare - sau foarte precis - cum ar fi un sistem concurent realizat pentru a gasi cea mai frecventa parte de vorbire care apare intr‑o codificare de date lingvistice.
In situatii diferite, relatiile dintre activitatile independente pot fi diferite. Pot aparea relatii de cooperare pentru atingerea unui scop comun, de competitie pentru utilizarea resurselor, de interactiune cu mediul exterior in sistemele interactive, de respectare a unor restrictii temporale s.a.m.d.
Din punctul de vedere al utilizarii memoriei disponibile in sistem, activitatile pot folosi numai memoria principala a unui singur calculator (cand activitatea este de tip "incarca si mergi mai departe" - load and go) sau pot avea acces la memoriile principale ale mai multor statii din sistemul distribuit. Mai mult, sunt situatii in care accesul activitatilor este permis atat la nivelul zonelor de memorie principala, cat si la memoriile permanente de tip disc (de exemplu intr‑un sistem de fisiere care gestioneaza discul fix).
Ansamblul tuturor acestor caracteristici ale activitatilor unui sistem asigura acelui sistem caracterul de sistem concurent.
Abordarea sistemelor concurente ridica o serie de probleme care pot fi rezolvate numai apeland la entitati specifice. Din acest punct de vedere trebuie spus ca tratarea concurentei trebuie sa faca distinctie intre actiuni concurente singulare (single concurrent actions) si actiuni concurente compuse (concurrent composite actions). Putem defini o actiune singulara ca fiind o operatie de citire sau de scriere din/in memoria principala, dar problematica sistemelor concurente nu se poate folosi numai de acest tip de operatii. Un motiv ar fi simplul fapt ca procesele concurente sunt corect si complet descrise prin astfel de operatii singulare numai daca se poate presupune ca orice operatie este garantata de resursele hardware ca este indivizibila, adica atomica. Ori aceasta conditie este prea restrictiva in conditiile unui sistem concurent general. De aceea, definitia unei actiuni concurente singulare trebuie extinsa la operatii de nivel mai inalt decat citirea/scrierea din memorie.
Dupa Andrews [1991], o actiune atomica este o secventa de una sau mai multe stari care apare ca fiind indivizibila, in sensul ca nici un proces extern ei nu are acces (nu vede) vreuna dintre starile intermediare. Detaliind, Andrews defineste doua tipuri de actiuni atomice: (1) o actiune atomica este de granularitate fina daca poate fi implementata direct printr-o instructiune masina unica sau (2) o actiune atomica poate fi o secventa de actiuni atomice de granularitate fina, indivizibila.
O actiune concurenta compusa rezulta prin combinarea actiunilor singulare intr‑o operatie de nivel inalt. Considerentele legate de aceste aspecte ale concurentei deschid doua directii distincte si anume: (1) legarea acestor notiuni de structura modulara a softului unui sistem, in particular de tipurile abstracte de date recunoscute la nivelul sistemului respectiv si (2) stabilirea legaturilor intre actiunile singulare astfel incat sa se poata decide daca ele pot forma sau nu actiuni compuse.
[Andrews, 1991] O actiune atomica face o transformare de stare indivizibila. Aceasta inseamna ca orice stare intermediara care ar putea sa existe in implementarea actiunii nu trebuie sa fie vizibila de alte procese.
Proprietatea de granularitate (definita si la inceputul capitolului al doilea) reprezinta numarul de procesoare din sistem sau, daca se refera la o aplicatie, atunci granularitatea reprezinta numarul de procese care compun aplicatia respectiva.
O actiune atomica fine-grained este una care este implementata direct de hardware-ul sistemului pe care se executa programul concurent.
Uneori este nevoie sa folosim un mecanism de sincronizare pentru a construi o actiune atomica coarse-grained - care este o secventa de actiuni atomice fine-grained care apare ca fiind indivizibila.
Exemple.
presupunem ca o baza de date contine doua valori x si y si ca aceste valori trebuie sa fie in fiecare moment egale. Cu alte cuvinte, nici un proces nu are acces la baza de date daca x y. Pentru a asigura aceasta restrictie, orice proces care modifica valoarea lui x trebuie sa modifice si valoarea lui y, ca parte a aceleiasi actiuni atomice.
Fie un proces care insereaza elemente intr-o coada reprezentata printr-o lista de legaturi. Un alt proces extrage (removed) elemente din lista, presupunand ca exista elemente in lista. Doua variabile pointeaza la capul si, respectiv, la coada listei. Valorile acestor variabile sunt modificate o data cu executarea operatiei de inserare, respectiv de extragere a elementelor din lista. Daca lista contine un singur element atunci o inserare si o extragere simultane pot creea conflicte, lasand lista intr-o stare instabila (unstable state). De aceea, inserarea si, respectiv, extragerea elementelor din lista trebuie sa fie actiuni atomice. Mai mult, daca lista este vida atunci trebuie sa se intarzie executarea unei extrageri pana cand se va fi executat o inserare.
Toate aceste aspecte legate de caracterul concurent al unui sistem se regasesc in capitolele urmatoare, tratate din diferite puncte de vedere.
Un atribut adevarat pentru oricare executie a unui program este o proprietate a programului respectiv. Orice proprietate se poate exprima pe baza a doua proprietati speciale si anume:
Siguranta (safety) si
Vivacitatea, viabilitatea (liveness) [Andrews, 1991], [Georgescu, 1996], [Bacon, 1998].
In general, un program este sigur daca "nu se intampla nimic rau in timpul executiei" si este viabil daca "este de asteptat sa apara un rezultat bun
Un program secvential este sigur daca starea finala este corecta si este viabil daca executia lui se termina.
Caracterul nedeterminist al programelor concurente nu ne permite sa extindem cu usurinta aceste fomulari de la programele secventiale la programele concurente. De aceea, pentru un program concurent, definitiile proprietatilor de siguranta si viabilitate vor folosi conceptele specifice aplicatiilor concurente. Astfel, siguranta unui program concurent consta in asigurarea excluderii mutuale si absenta interblocarii (interblocarea apare cand procesele asteapta indeplinirea unor conditii care nu pot fi satisfacute), iar viabilitatea se exprima prin faptul ca un proces in asteptare va fi semnalizat in curand si astfel va putea sa-si continue executia.
Viabilitatea unui program concurent depinde de:
2a. corectitudinea alocarii resurselor (fairness) - ceea ce se exprima prin faptul ca un proces va obtine sansa de a intra in executie, independent de starea altor procese;
2b. asteptarea activa (starvation) - adica faptul ca un proces activ, care este blocat pe un timp nedefinit de unitatea de planificare (desi este teoretic capabil sa se execute) va fi ales la un moment dat pentru a-si continua executia. Aceasta conditie este una esentiala si pentru evitarea starii de blocare globala a sistemului (deadlock).
Din tot ceea ce s-a scris pana acum in acest material nu se pot delimita notiunile de concurent, paralel, distribuit. Explicam aceasta prin caracterul dinamic al cercetarilor actuale in aceste domenii si, mai mult, prezentam in continuare cateva opinii referitoare la diferentele si intersectiile sferelor de cunostinte ale celor trei concepte.
[Boian, 1994] Desfasurarea proceselor in sistemele de calcul poate fi facuta:
secvential - cand procesele folosesc resursele unul in urma celuilalt;
paralel - cand procesele se pot desfasura in acelasi timp folosind resurse diferite;
concurent - cand procesele se desfasoara in paralel, dar folosesc resurse comune. Putem privi atunci concurenta ca o imbinare intre paralelism si interactiune.
O caracteristica a programarii paralele poate fi exprimata astfel: procesele paralele nu sunt conditionate unul de celalalt, executia unuia dintre ele nu este in nici un moment dependenta de rezultatele partiale ale celuilalt. Fata de aceasta, spunem ca avem programare concurenta atunci cand procesele paralele se interconditioneaza reciproc.
Cu alte cuvinte, daca procesele se desfasoara in acelasi timp, pe resurse diferite atunci programarea este paralela, iar daca procesele se desfasoara in paralel, pe resurse comune atunci vorbim despre programare concurenta. De aici avem ca programarea concurenta apare ca un caz particular de programare paralela. Urmatoarele afirmatii sustin aceasta dependenta.
Daca un sistem dispune de mai multe procesoare care sunt capabile sa coopereze intre ele atunci il vom numi sistem cu procesare paralela. Prin cooperarea intre procesoare intelegem, pe de o parte ca procesoarele executa sarcini de calcul diferite ale aceluiasi program si, pe de alta parte, ca lansarea unei anumite secvente asteapta pana cand toate secventele care trebuie sa-i preceada logic s-au terminat. Pentru ca procesele sa coopereze intre ele, in sistem trebuiesc implementate mecanisme specifice de comunicare si sincronizare. In cadrul fiecarei secvente dintre cele care se executa in paralel (care se lanseaza in executie simultan), instructiunile componente se executa concurent. Cu alte cuvinte, executia concurenta presupune paralelism si schimb de informatii intre procesele care se executa in paralel.
Se poate evidentia totusi o delimitare intre paralelism si concurenta in sensul ca paralelismul pune accent pe executia propriu-zisa, simultana a proceselor, in timp ce aspectele concurente se refera la rezolvarea interactiunilor dintre procese.
Daca in sistem exista mai multe procesoare atunci paralelismul programat este efectiv. Altfel, executia secventelor paralele este simulata intr‑un paralelism abstract.
Daca in sistem exista un singur procesor atunci concurenta poate aparea numai la nivelul logic al unei aplicatii. Daca insa sistemul este multiprocesor atunci concurenta apare si la nivel fizic.
[Georgescu, 1996] Dezvoltarea calculului paralel este potrivita sistemelor multiprocesor cu comunicare prin zone de memorie comune. Daca un sistem multiprocesor respecta un protocol de comunicare prin linii de comunicatie atunci programarea impune utilizarea algoritmilor distribuiti.
Conform principiilor programarii paralele, rezolvarea unei probleme presupune descompunerea acesteia in subprobleme independente rezolvabile in acelati timp, pe procesoare distincte. Daca mai multe procese (programe in executie) pot fi rulate simultan si nu neaparat pe procesoare distincte atunci vorbim de programarea concurenta a acelor procese. In acest caz comunicarea intre procese se face prin memorie comuna sau prin mecanisme specifice concurentei, dar se va evita comunicarea prin variabile globale.
Scopul programarii paralele consta in elaborarea algoritmilor care sa speculeze existenta mai multor procesoare pentru a micsora timpul de calcul.
Intr-un sistem multiprocesor, algoritmul de comunicare intre procese poate folosi zone de memorie comune sau linii de comunicatie. In primul caz aplicatia se incadreaza mai bine in specificul calculului paralel, iar in al doilea caz suntem condusi spre algoritmi distribuiti.
[Ionescu, 1999] Sistemul paralel este o masina cu procesoare multiple, capabila sa prelucreze informatiile prin manevrarea concurenta a datelor.
Sistemele cu procesare paralela sunt sistemele cu interconectare stransa si arhitecturile cu spatiul de adresa al memoriei partajat, in timp ce sistemele cu procesare distribuita sunt cele cu interconectare slaba si arhitecturile bazate pe transmitere de mesaje (se partajeaza canale de comunicatie).
Paralelismul apare odata cu executia simultana pe procesoare diferite a mai multor procese care comunica si se sincronizeaza intre ele.
[Boian, 1999] Intr-un sistem distribuit, accesul utilizatorului la resursele departate se face ca si cum acele resurse s-ar afla pe masina locala. Pentru aceasta, se impune ca, la nivelul sistemului de operare, sa fie controlata migrarea datelor, calculelor si proceselor implicate in utilizarea resurselor la distanta. Detaliind, se poate spune ca programarea paralela trateza migrarea proceselor, in timp ce programarea distribuita trateaza migrarea (distribuirea) calculelor.
[PC Report 40] Domeniile "calde" in programarea concurenta sunt in general legate de utilizarea sistemelor distribuite [I. Athanasiu].
Conform cu S. Williams [1990], nu exista nici o delimitare clara intre notiunile concurent si paralel, prin urmare ele sunt folosite de diferiti autori dupa preferinta. Datorita caracterului sau mai general, insa, se prefera utilizarea termenului de paralel.
In sistemele distribuite executia paralela/concurenta a proceselor apare in mod natural in diverse situatii de cooperare rezultate din: (a) activitati individuale (separate) ale diferitilor utilizatori, (b) independenta resurselor sistemului, (c) localizarea proceselor server pe calculatoare diferite. Executia paralela este posibila daca specificul aplicatiei permite separarea activitatilor.
De exemplu, pentru cazul unui sistem distribuit bazat pe modelul resurselor partajate, pot aparea doua situatii care conduc la executia paralela: (1) din punctul de vedere al cererilor: mai multi utilizatori lanseaza simultan comenzi independente sau interactioneaza simultan cu programele aplicatii; (2) din punctul de vededre al raspunsurilor sistemului distribuit: mai multe servere de procese lucreaza concurent, fiecare raspunzand diferitelor cereri primite prin procese client.
La nivelul sistemelor de operare sau al bazelor de date, probleme specifice ale cooperarii intre procese cum sunt sincronizarea, tratarea excluderii mutuale sau evitarea impasului/interblocarii (deadlock), se rezolva in contextul prelucrarilor multitasking sau multiuser. Pentru prelucrarile de tip monoprocesor, solutiile se dau prin intermediul structurilor de tip semafor sau monitor. Aceste solutii presupun existenta in sistem a unei memorii comune, partajata de procesele care comunica.
Una dintre problemele care apar la nivelul cooperarii intre procese intr‑un sistem distribuit este rezultatul faptului ca intr‑un sistem distribuit nu exista o zona de memorie comuna tuturor componentelor sistemului. De aici, rezulta ca rezolvarea problemelor de tip sincronizare si comunicare in sisteme distribuite trebuie sa foloseasca algoritmi specifici, care sa respecte caracterul distribuit al sistemului gazda si al aplicatiei.
O alta caracteristica fundamentala a sistemelor distribuite consta in faptul ca intr‑un sistem distribuit nu exista un ceas global al intregului sistem si nu exista nici macar o sursa de obtinere a unui timp global. Procesele isi gestioneaza executia bazandu-se numai pe informatia stocata pe masina locala.
Solutiile corecte care rezolva problemele de comunicare si sincronizare in sisteme distribuite trebuie sa tina cont de aceste doua particularitati (ne-existenta unei zone de memorie comuna si lipsa unui ceas global al intregului sistem). In plus, aceste sisteme trebuie sa respecte un principiu fundamental al programarii distribuite si anume: in sistemele distribuite trebuie evitata existenta unui unic punct de blocare, adica trebuie eliminata posibilitatea ca, prin blocarea unui singur punct (calculator, proces), sa se blocheze intreg sistemul. Solutii pentru rezolvarea problemei sincronizarii temporale a cooperarii intr‑un sistem distribuit se pot gasi in Boian, 1999
De asemenea, cele doua particularitati fundamentale ale sistemelor distribuite arata ca, din punctul de vedere al tipului de conexiune intre noduri, un sistem distribuit este un sistem slab-conectat (loosely coupled). Intr-un astfel de sistem nu exista un procesor master ci toate relatiile dintre procesoare sunt decise pe baza de negocieri realizate prin schimburi de mesaje. Prin schimb de mesaje se va intelege atat transmiterea mesajului cat si secventa necesara prelucrarii lui.
In general, ipoteza excluderii mutuale sau a sectiunii (regiunii) critice cere ca accesul la o anumita resursa sa fie exclusiv - daca mai multe procese pot sa o acceseze in acelasi timp.
Asa cum am afirmat si anterior, in sistemele monoprocesor o resursa critica poate fi "protejata" prin semafoare, monitoare sau prin variabile cu acces exclusiv. Aceste mecanisme sunt posibile deoarece (a) procesele sunt coordonate de catre acelasi nucleu si (b) toate procesele au acces la memoria interna a sistemului si in aceasta memorie interna ele partajeaza o zona comuna. Sistemele distribuite sunt lipsite tocmai de memoria comuna partajabila intre procese. Deci si pentru implementarea regiunii critice si a excluderii mutuale se impun metode specifice caracterului distribuit, cum ar fi: (1) coordonarea centralizata, (2) coordonarea complet distribuita sau (3) coordonarea printr-o metoda de tip token-ring.
Coordonarea centralizata presupune ca se alege un proces ca si coordonator al intregului sistem. Acesta va initia un dialog cu celelalte procese prin mesaje de tip request, reply sau release. Printr-un mesaj request un proces oarecare cere coordonatorului intrarea in sectiunea critica. Acest mesaj trebuie sa fie urmat de un mesaj reply prin care procesul coordonator aproba ca procesul subordonat sa intre in sectiunea critica. Executia sectiunii critice se termina cu un mesaj release prin care procesul anunta coordonatorul ca si-a incheiat executia sectiunii critice.
In spiritul principiului fundamental al sistemelor distribuite enuntat anterior, trebuie spus ca programarea coordonarii centralizate trebuie sa asigure ca, in situatia in care procesul coordonator cade, celelalte procese vor coopera pentru alegerea unui nou coordonator.
Coordonarea complet distribuita foloseste sincronizarea cu ceasuri logice si rezolva problema excluderii mutuale numai prin cooperarea proceselor distribuite, fara ca vreun proces sa aiba atributii speciale.
Coordonarea printr-o metoda token-ring presupune ca procesele sunt ordonate" intr‑un inel logic si identificate prin numarul lor de ordine in acest inel. Un token este un mesaj special de comunicare, transmis circular in inelul proceselor.
Pentru tratarea si a altor aspecte ale coordonarii in sisteme distribuite cum ar fi: problema impasului, problema tolerantei la erori sau problema consistentei deciziilor proceselor concurente se poate consulta [Boian, 1999], [Coulouris, 1999].
|
Politica de confidentialitate |
| Copyright ©
2025 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |