INTRODUCERE
Definirea obiectului discutiei
Ideal, un sistem tolerant la defecte este un sistem capabil a executa corect
sarcinile lui de calcul sau de alta natura indiferent daca apar defecte hardware
sau software. In practica, niciodata nu poate fi garantata in orice imprejurare executarea acelor sarcini fara intrerupere. Discutiile de genul celei care urmeaza se limiteaza uzual la tipuri de defectari si de erori care sunt mai probabil sa apara.
Aplicatii in care toleranta la defecte este necesara
Exista in lumea reala asa-numitele aplicatii critice sub aspect vital. Este vorba,
de plida, de aeronave, de reactoarele nucleare, de unele instalatii chimice si de
echipamentul medical. O functionare proasta a unui calculator in cazul unor
asemenea aplicatii poate duce la catastrofa. Probabilitatea de defectare a
sistemelor din aceasta categorie trebuie sa fie extrem de scazuta, posibil unu la
un miliard pe ora de operare. Ambianta aspra este alt element care impune toleranta la defecte. Un sistem de calcul care opereaza in conditii vitrege, in care este supus la perturbatii electromagnetice, la bombardament cu particule sau altele asemenea trebuie sa fie tolerant la defecte. Un numar mare de disfunctii datorate factorilor de mediu, altminteri destul de probabile, poate face ca sistemul sa nu produca rezultate
utile decat daca are incorporata o doza de toleranta la defecte.
Din alt unghi, unele sisteme foarte complexe constau in milioane de dispozitive. Fiecare dispozitiv fizic component are o anumita probabilitate de a esua. Un numar foarte mare de dispozitive implica o probabilitate de mers neconform
inca mai mare. Sistemul poate manifesta defectari cu o asa frecventa incat el
poate deveni inutilizabil.
Masuri ale tolerantei la defecte
Este foarte important a avea definite masuri care sa cuantifice nivelul tolerantei la defecte. Ca in orice domeniu, o masura este o abstractie matematica care
exprima numai un aspect oarecare al naturii obiectelor. Sunt desigur unele masuri considerate deja traditionale. Se considera mai intai ca sistemul poate fi in una din doua stari mutual eclusive: functional sau defect.
De exemplu, un bec este fie bun, fie ars; un fir este fie continuu, fie intrerupt. In legatura stricta cu aceste doua stari se utilizeaza doua masuri traditionale: fiabilitatea si disponibilitate.
Fiabilitatea, notata cu R(t) este probabilitatea ca sistemul sa fie functional pe durata intervalului [0, t], el fiind functional la momentul t = 0.
Disponibilitatea, notata cu A(t) este cota parte din timp in care sistemul este functional in intervalul [0, t]. Ca masura complementara, se defineste o disponibilitate punctuala, Ap(t) ca probabilitatea ca sistemul sa fie functional la momentul t. O masura inrudita este si MTTF - Mean Time To Failure - care este timpul mediu cat sistemul este functional inainte ca el sa se defecteze pentru a fi reparat sau inlocuit.
Sunt insa necesare si alte masuri suplimentare. Presupunerea ca sistemul poate fi doar in starile "functional" sau "defect" este foarte restrictiva. De exemplu, un procesor cu una din cele cateva sute de milioane de porti blocata in valoarea logica 0 si restul functionale poate fi sau chiar este si functional, si defect. Poarta aceasta defecta poate afecta iesirea procesorului o data la 25.000 de ore de utilizare. Procesorul nu este lipsit de orice defectiune dar nu poate fi calificat ca disfunct. Pentru a caracteriza astfel de stari, sunt necesare masuri suplimentare pe langa traditionalele fiabilitate si disponibilitate. In continuare sunt discutate cateva masuri mai cuprinzatoare.
Fiabilitatea prin capacitate este probabilitatea ca o anumita capacitate a sistemului (masurabila - de pilda, un randament) la timpul t sa depaseasca un prag dat. O alta extindere a gamei de masuri ia in considerare totul din perspectiva aplicatiei. Aceasta duce la definirea masurii cunoscuta ca performabilitate.
Relativ la capacitatea unui sistem, fie aceasta capacitatea de calcul. De exemplu, fie un sistem cu N procesoare, sistem care se degradeaza cu gratie, adica nu brusc ci gradual. Sistemul se recupereaza din starea de disfunctie a unora dintre procesoare si este utilizabil atat timp cat cel putin un procesor este functional. Fie Pi probabilitatea ca i procesoare din cele N sa fie functionale.
Fiabiltatea sistemului este o suma a acestor probabilitati dupa indicele i, excluzand, desigur, valoarea i = 0.
R(t)=Σi=1Pi
Fie c capacitatea de calcul a unui procesor (de pilda numarul de task-uri de dimensiune fixa pe care le poate executa). Capacitatea de calcul a i procesoare este atunci Ci = i.c. Capacitatea de calcul a sistemului este in consecinta
Σi=1CiPi
Relativ la performabilitate, in legatura cu aplicatia la care se refera se definesc niste niveluri de indeplinire, L1, L2, ., Ln. Fiecare dintre acestea reprezinta un nivel de calitate al serviciului efectuat prin aplicatie. De exemplu, Li - sistemul i nu "cade" pe durata T a misiunii lui. Performabilitatea este un vector [P(L1) P(L2) . P(Ln)] in care P(Li) este probabilitatea ca sistemul sa functioneze suficient de bine pentru a permite aplicatiei sa atinga nivelul de indeplinire Li.
Redundante
Literatura de specialitate distinge doua modalitati de realizare a sistemelor tolerante la defecte:
. Sisteme cu redundanta statica (fig.1).
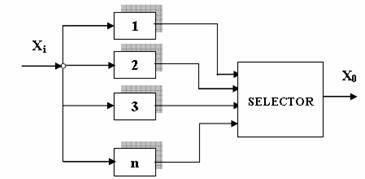
Fig1. Redundanta statica
Sistemele sunt prevazute cu redundanta hardware si software de tip static.
Esenta metodei consta in existenta unui numar de module cu acelasi semnal de
intrare. Semnalele de iesire sunt conectate la modulul "alegator" care compara aceste semnale. Semnalul de iesire de utilizat este selectat prin votul majoritar: o schema logica simpla valideaza doar acel semnal care nu difera fata de celelalte cu mai mult de o valoare de prag, aleasa convenabil functie de dinamica procesului si a preciziei masuratorilor. Metoda este aplicabila traductoarelor din sistemele automate. Acele traductoare ale caror semnale raman invalide un timp mai indelungat sunt declarate
defecte si in final isolate.
. Sisteme cu redundanta dinamica
Sun incluse in aceasta categorie sistemele care au posibilitatea detectarii si localizarii
defectelor si apoi reconfigurarea automata pentru inlocuirea componentei defecte. Metoda se bazeaza pe un numar scazut de module. O configuratie minimala utilieaza 2 module din care unul este utilizat in functionarea sistemului (fig.6). Modulul "DETECTIA DEFECTELOR" compara semnalele de iesire ale modulelor si va stabili pe baza unui algoritm corespunzator care este intr-o functionare corecta. Pe baza modulului de reconfigurare va fi selectat pentru structura in functionare modulul corespunzator.
O alta varianta a acestor sisteme (rezervare la "rece") este ilustrata in figura 7. Metoda este asemanatoare cu cea anterioara cu deosebirea ca include doua module releu montate pe intrarea componentelor . Modul pentru detectia defectelor este esential. Metoda necesita un interval timp pentru transferul functional si astfel pentru lansarea procedurii START - STOP.
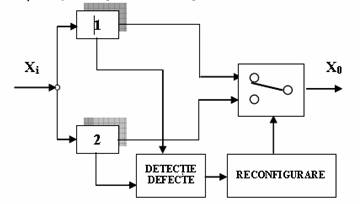
Fig2. Sisteme cu redundanta dinamica
Pentru sistemele de calcul o configuratie duplex cu redundanta dinamica este
prezentata in figura 4. Semnalele de iesire a doua sincronizatoare de proces sunt comparate (software) dupa care se va selecta prin intermediul a doua relee care dintre variante va fi conectat la iesire.
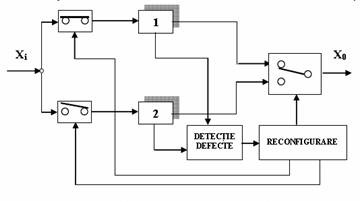
Fig3. Varianta de sistem cu redundanta dinamica
Redundanta dinamica este aplicabila sistemelor electro-mecanice. Modalitatea de calcul fiabilitatii sistemelor mecanice a fost prezentata pe larg in cadrul capitolelor anterioare. Materializarea redundantei in componente se realizeaza prin fire, bobine, contacte multiple etc. In cazul sistemelor software literature de specialitate identifica doua domenii de defecte (fig.5):
. Defect de valoare - valoarea asociata unui serviciu este eronata;
. Defect de timp - serviciu este executat intr-un timp incorrect.
Combinatia defectelor anterioare creaza categoria defectelor arbitrare.
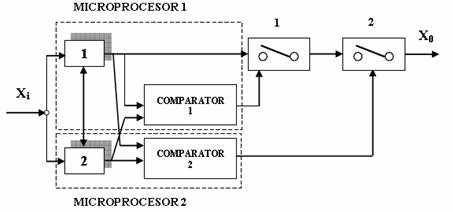
Fig4. Redundanta dinamica in sisteme de calcul
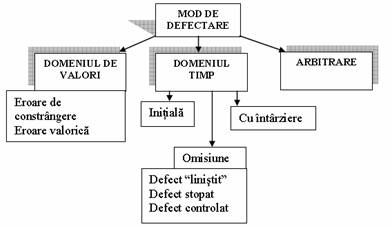
Fig5. Defecte software
Redundanta statica este utilizabila si in cazul sistemelor software prin asa numita programare n-versiuni.
Redundanta dinamica pentru sistemele software apeleaza la schema din figura 6. Etapele de aplicare a redundantei dinamice pentru acest caz sunt: detectarea defectelor (identificare prin mediu, identificare prin aplicatie), diagnoza defectelor, restaurarea sistemului, tratarea erorii si continuarea service-ului.
Redundante informationale - Redundantele informationale se realizeazǎ prin adǎugarea de biti la cei originari. Erorile in biti pot fi detectate si chiar corectate. S-au dezvoltat si se utilizeazǎ codurile detectoare si corectoare de erori. Redundanta informationalǎ atrage dupǎ sine uneori redundante hardware menite a prelucra bitii suplimentari.
Redundante temporale Redundantele temporale inseamnǎ timp suplimentar pentru ca executiile esuate sǎ poatǎ fi repetate. Cele mai multe dintre esecuri sunt tranzitorii si ele se atenueazǎ dupǎ un timp. Dacǎ existǎ timp suficient la dispozitie, modulul disfunct poate recupera si poate reface calculele afectate.
Literatura de specialitate se refera in general la trei strategii de implementarea tolerantei la defecte:
. Strategii bazate pe mascarea defectelor - este cazul sistemelor proiectate si realizate cu
coeficienti de siguranta mari;
. Strategii bazate pe detectia si localizarea defectelor (failure detection and identification) - aplicabila sistemelor mecatronice
. Strategii hibride - din cele expuse, pentru sistemele mecatronice strategia de integrare software este esentiala in detectia prezentei defectelor, localizarea acestora si reconfigurarea sistemului. Proiectarea sistemelor cu toleranta la defecte este structurata pe mai multe etape prezentate sugestiv in figura 6.
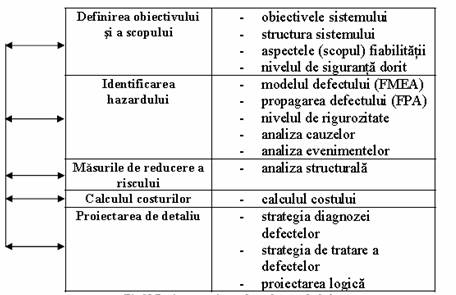
Fig.6 :Proiectarea sistemelor tolerante la defecte
In literatura exista o varietate larga de procedee pentru detectarea defectelor si care pot fi
ggrupate in trei categorii de baza: detectare bazata pe clasificarea defectelor, detectare bazata pe semnal si detectare bazata pe model. Unele aspecte referitoare la detectia pe baza de semnal au fost mentionate si cadrul analizei privind rolul, constructia si utilizarea senzorilor inteligenti in sistemele mecatronice.
Clasificarea defectelor hardware
Sunt trei tipuri de defecte hardware.
Unele sunt tranzitorii si dispar dupa relativ putin timp. Un exemplu ar putea fi o celula de memorie al carei continut este schimbat datorita unei interferente electromagnetice. Rescrierea ei cu continutul corect face ca eroarea sa dispara. Alte defecte sunt permanente si nu dispar niciodata, iar componenta trebuie reparata sau inlocuita. Exista si defecte intermitente, caz in care defectul componentei penduleaza intre o stare activa si o stare benigna. Se poate exemplifica cu cazul unei conexiuni slabe/slabite.
Rata defectarilor
Rata la care o componenta manifesta disfunctii depinde de varsta, de parametrii (micro)climatici locali, de eventualele socuri fizice cum ar fi cele date de tensiunea de alimentare, dar si de tehnologia de realizare concreta a acelei componente. Dependenta de varsta a ratei de defectare este ilustrata uzual de curba cada-de-baie (v.figura)
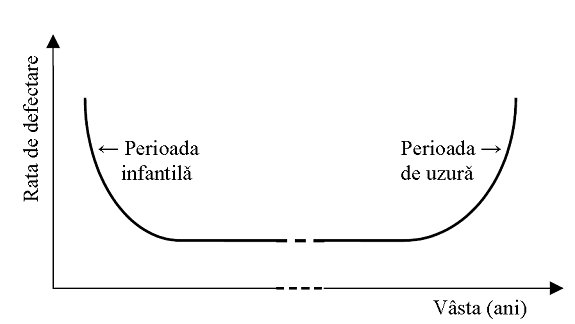
La tinerete rata
defectarilor este ridicata: sunt sanse bune ca unele module cu defecte de
fabricatie sa treaca de controlul de calitate si sa ajunga pe piata. Pe masura
trecerii timpului aceste unitati/module sunt eliminate si pentru mare parte din
viata sistemul manifesta o rata de defectare practic
O formula empirica pentru λ, rata de defectare
Rata de defectare se poate estima cu relatia
. = πL πQ (C1 πT πV + C2 πE)
in care:
πL - un factor de invatare care arata cat de matura este tehnologia
πQ - un factor de calitate a fabricatiei intre 0,25 si 20
T - un factor de
temperaturǎ (de la 0,1 la 1000), proportional cu exp(-Ea/kT) cu Ea energia
de activare [eV ] asociatǎ cu tehnologia, k
πV - un factor de stres prin tensiune pentru dispozitivele CMOS (de la 1 la 10, depinzand de tensiunea de alimetare si de temperaturǎ); nu se aplicǎ altor tehnologii (se pune egal cu 1)
πE - un factor de soc ambiant: de la cca. 0,4 (mediu de aer conditionat) la 13 (ambient dur)
C1, C2 - factori de complexitate, functii de numǎrul de porti pe chip si numǎrul de pini in pachet.
Impactul mediului ambiant
Dispozitivele care lucreazǎ in spatiul interastral, care este plin cu particule incǎrcate energetic si capabil a supune dispozitivele la variatii drastice de temperaturǎ, este de asteptat a claca mai des. Similar, calculatoarele din automobile (temperaturi ridicate si vibratii) si din aplicatiile industriale sunt susceptibile a se defecta mai frecvent.
Defect si eroare
Un defect in sensul tolerantei la defecte poate fi o disfunctie (mai curand localǎ) de hardware sau o gresealǎ de software sau de programare. O eroare este o manifestare a unui defect (fault). Ca exemplu se considerǎ un circuit de aditie in binar cu una din liniile de iesire "agǎtatǎ" la 1. Acesta-i un defect dar incǎ nu este o eroare. Defectul produce o eroare dacǎ circuitul este folosit si dacǎ rezultatul pe linia defectǎ ar trebui sǎ fie 0 si nu 1.
Propagarea defectelor si erorilor
Atat defectele cat si erorile se pot difuza in sistem. Dacǎ de pildǎ un chip scurtcircuiteazǎ puterea la masǎ, asta poate determina ca chip-urile vecine sǎ clacheze si ele. Erorile difuzeazǎ pentru simplul motiv cǎ o iesire (eronatǎ) a unui procesor este utilizatǎ frecvent ca intrare a altor procesoare. Exemplul circuitului de adunare este ilustrativ: rezultatul eronat al circuitului poate fi utilizat in alte calcule, desigur cu propagarea erorii.
Zone de continentǎ
Pentru a limita situatii de genul mentionat putin mai sus, proiectantii incorporeazǎ in sistem asa-numite zone de continentǎ. Cum? Prin bariere care reduc sansa ca un defect sau o eroare dintr-o zonǎ sǎ se propage intr-o altǎ zonǎ. O zonǎ de continentǎ poate fi creatǎ uneori prin asigurarea de alimentǎri independente pentru fiecare zonǎ. Proiectantul unui sistem incearcǎ prin aceasta sǎ izoleze electric o zonǎ de celelalte. O zonǎ de continere a erorilor poate fi creatǎ prin utilizarea de module redundante si prin voting pe iesirile lor.
Timpul panǎ la cǎdere - modelul analitic
Se considerǎ modelul urmǎtor:
Sistemul are N componente identice, toate operationale la momentul t = 0. Fiecare componentǎ rǎmane operationalǎ panǎ cand apare un defect. Toate defectele sunt permanente si apar in cele N componente independent unul de celǎlalt. Pentru o componenetǎ, fie T durata de viatǎ a acelei componente, adicǎ timpul panǎ la aparitia defectului (fatal). T este o variabilǎ aleatoare cu densitatea de probabilitate f(t) si functia de repartitie (cumulativǎ) F(t).
Intr-o interpretare probabilisticǎ, F(t) este probabilitatea ca o componentǎ sǎ esueze inainte de timpul t, F(t) = Pr(T ≤ t). Functia f(t) este un gen de ratǎ momentanǎ a cǎderii: f(t) t = Pr(t ≤ T ≤ t + t) cu t oricat de mic.
Ca orice functie densitate de probabilitate
Toleranta la defecte folosind produse Off-the-Shelf
Folosirea sistemelor "off-the-shelf" (OTS) in detrimentul produselor customizate devine mai atractiva din punct de vedere al costurilor de achizitie si al timpilor de expediere, dar ridica probleme in cea ce priveste dependenta si costul total al ownership. In ceea ce priveste aplicatiile orientate spre domeniul afacerilor, in particular, produsele construite cu scopuri precise, de regula sunt oferite impreuna cu documentatii pentru buna utilizare si validare a acestora. Trecand la distributia de masa a sistemelor OTS, utilizatorii (arhitectii de system sau clientii) gasesc adesea nu doar inconsistenta aceasta documentatie, dar si erori si/sau bug-uri ce determina scaderea increderii in produsul respectiv. In ciuda adoptarii unor produse pe scara larga, nu exista inca o documentatie formala privind nivelurile de dependenta atinse, prin care un utilizator ar putea incerca sa extrapoleze nivelurile pentru a a-si atinge mediul de utilizare dorit.
Tinand cont de aceste motive, cand sistemele sunt construite in afara produselor OTS, fault tolerance este adesea singura cale de a obtine o solutie viabila privind dependenta sistemelor. Aceste considerente nu se aplica doar sistemelor OTS, ci si produselor hardware cum ar fi microporocesoare sau a sistemelor hardware-software. Costul achizitiei a doua sau a mai multor produse OTS (dintre care unele pot fi graduate) ar putea fi mult mai redus decat dezvoltarea propriului produs.
Intrebarea care se pune dezvoltatorilo unui system folosind componente OTS sunt referitoare la plusurile de dependenta, dificultatile intampinate la implementare, cat si costurile suplimentare pe care le presupune respectivul system. Vom discuta in continuare cateva aspecte arhitecturale care determina fezabilitatea si costurile unei categorii specifice de produse OTS, si anume serverele de baze de date SQL, sau "sistemele de management ale bazelor de date" (DBMS).
Aceasta categorie de produse ofera un studio de caz realistic privind avantajelesi provocarile a software fault tolerance in ceea ce priveste produsele OTS. Produsele DBMS sunt complexe, si destul de raspandite si totusi cu destule erori in fiecare distributie. Fault tolerance in cazul produselor DBMS este un subiect atent studiat, cu solutii standard recunoscute, unele dintre ele fiind comerciale. Cu toate acestea, respectivele solutii nu prezinta protectie totala impotriva erorilor software deoarece ele presupun fail-stop sau cel putin caderi auto evidente. Erorile sunt detectate destul de rapid astfel incat continutul bazelor de date sa nu fie afectat, sau pentru a stabili un punct din care sa se faca restaurarea.
Exista foarte multe produse OTS SQL DBMS urmand standarde commune (SQL 92 si SQL 99), ce fac redundanta dinamica realizabila.. Spre exemplu o arhitectura pralel-redundanta folosind doua copii ale bazei de date, controlate de doua produse DBMS diferite, vor permite detectia erorilor prin comparare a rezultatelor provenite de la cele doua produse DBMS. Un server fault-tolerant capabil de gestionarea software faults, poate fi construit prin instalarea a doua sau mai multe produse DBMS diferite conectate intre ele, fiind vizibil pentru utilizatori ca fiind un singur server de baze de date. In particular, prdusele DBMS existente au anumite functii de control si fault-tolerance care se bazeaza pe lipsa de diversitate dintre executii replicate, pentru rularea in conditii optime si eficiente. Cu toate acestea, merita explorate costurile si avantajele solutiilor care accepta compensari de diversitate in vederea cresterii dependentei. Pentru multi utilizatori, nu exista alta alternative practica la produsele OTS DBMS, astfel ca reduceri ale performantelor pot fi acceptate in vederea asigurarii sporite.
In ceea ce urmeaza vom discuta despre aspectele arhitecturale privind software fault tolerance la produsele DBMS - fezabilitate, design alternativ si aspecte privind performantele. In sectiunea urmatoare vom dezvolta rezultatele a doua studii empirice a unor bug-uri cunoscute ale produselor DBMS, incluzand comparatii intre versiuni mai vechi si mai noi ale celor doua produse DBMS. A patra sectiune contine un rezumat privind lucrul cu replicarea bazelor de date, interoperabilitatea bazelor de date, evidentele empirice privind defectele si caderile si diversitatea componentelor OTS.
Consideratii arhitecturale
Solutii curente privind replicarea DBMS
Solutii standard pentru toleranta automata la defecte in bazele de date folosesc mecanismele schimburilor atomice si/sau stadii intermediare pentru oferi support la recuperare, ceea ce poate fi urmat de reincercari ale schimburilor esuate. Aceste solutii vor tolera defectele intamplatoare, daca sunt detectate si daca sunt combinate cu replici, acestea vor masca caderile persistente, fara intreruperea serviciului.
Exista diverse solutii de replicare a datelor. In produsele DBMS comerciale, sunt adesea numite solutii "fail-over". Urmand o cadere al principalului produs BDMS, incarcatura este preluata transparent printr-o instalare separata a unui produs DBMS continand o copie redundanta a bazei de date cu costul renuntarii la tranzactia afectata de distrugere. Pot fi folosite copii multiple. Codul pentru toleranta la defecte este integrat in produsul DBMS. Alternativ, replicarea poate fi gestionata de middleware separate de produsele DBMS, solutie denumita "black box" (toleranta la defecte este responsabila in intregime de middleware) sau solutii "gray-box" (middleware exploateaza functii folositoare disponibile ale produselor DBMS. In continuare, discutiile se vor concentra pe solutiile "black-box" singurele care pot fi construite fare acces la codul sursa al OTS si celemai convenabile pentru studiul aspectelor de design in folosirea redundantei si diversitatii. Vom considera ca toleranta la defecte este controlat de un layer de middleware. Clientii vad serverul de baze de date toleranta la defecte prin intermediul acestui layer middleware care coordoneaza canalele redundante.
Solutiile de replicare existente folosesc scheme sophisticate de reducere a surplusului implicat in pastrarea actualizata a copiilor. Slabiciunile comune sunt dependentele privind asimilarea caderi de "fail stop" sau cel putin "self evident". Aceste asimilari simplifica protocolul replicarii de date si permite unele optimizari de performanta. Spre exepmplu in protocolul Read-Once, Write-All Available (ROWAA) sintaxele Read sunt executate de catre toate replicile. Aceste solutii fault tolerant sunt considerate ca fiind adecvate prin standardizarea continutului, decat presupunerea de a fi false in principiu. Unele solutii recente cauta optimizari prin executarea sintaxelor Write pe o singura replica care apoi transmite schimbarile catre toate celelalte replici disponibile.
Asa cum vom observa, produsele OTS BDMS sufera de multe bug-uri care cauzeaza caderi noncrash, non-self-evident. Pentru aceste tipuri de caderi, solutiile curente de replicare a datelor sunt deficitare, in primul rand din punctual de vedere al detectiei erorilor. Sunt posibile doua tipuri de remedieri:
Database- sau client-specific solutions Acestea depind de client (un proces automat sau un utilizator uman) de a rula reasonablSeness verificari la iesirile produselor si la ordinea actiunilor de recuperare daca se detecteaza erori. O detectie buna a erorilor poatefi obtinuta prin exploatarea cunostintelor semantice ale datelor stocate si ale proceselor care le actualizeaza. Aceste cunostinte pot sa suporte deasemeni si o recuperare a erorilor decat doar simple rollback and retry. Principalele dezavantaje sunt costurile ridicate de implementare, cele pivind timpul de rulare si posibilitatea de acoperire scazuta a detectiei erorilor.
Generic solutions - acestea folosesc replici active pentru detectia erorilor, astfel ca erorile sa poata fi detectate prin comparative cu rezultatele executiilor redundante si/sau corectate prin vot sau copiere a rezultatelor executiilor corecte.
Diversitate
Replicarea creaza bazele eficientei toleranta la defecte, in cazul in care canalele multiple nu cad in acelasi timp la aceeasi sarcina, sau cel putin nu tind sa cada la aceleasi rezultate eronate. Pentru a inlatura astfel de caderi, un architect de servere de baze de date fault tolerant poate folosi diverse forme de diversitate:
Separare simpla a executiilor redundante - aceasta este cea mai slaba forma de diversitate, dar poate tolera totusi anumite caderi. Este bine cunoscut ca multe buguri in produsele software complexe sunt "Hisenbugs"; adica acestea cauzeaza caderi nedeterministe. Cand o baza de date cade, copia sa identica ar putea sa nu cada, chiar si la aceeasi secventa de date de intrare. Chiar si repetarea aceleiasi secvente de operatii pe aceeasi copie a bazei de date dupa rollback ar putea, in principiu nu returneaza aceleasi caderi.
Design diversity - forma uzuala a redundantei paralele pentru inlaturarea defectelor de design este aceea prin care mai multe replici ale bazei de date sunt coordonate de diverse produse DBMS
Data diversity - multumita redundantei din limbajul SQL, o secventa de una sau mai multe functii pot fi rescrise intr-o alta forma echivalenta din punct de vedere logic pentru a produce executii redundante, reducand riscul ca o cadere sa se repete cand secventa rescrisa se executa fie pe aceeasi copie fie pe o alta replica a aceluiasi produs DBMS.
Configuration diversity - poate fi considerat un caz special de data diversity. Produsele DBMS au o gama larga de parametric, ce afecteaza spre exemplu resursele sistemului pe care il folosesc (cantitatea de memorie RAM si/sau utilizarea "page size" de catre baza de date) sau nivelul de optimizare care poate fi aplicat unor anumite operatii. Dandu-se acelasi continut al bazei de date si variind parametrii intre doua instalari, pot avea loc implementari diferite ale datelor si ale secventelor de operatii, lucru care duce la descresterea riscului acelasi bug produs de aceeasi secventa SQL sa apara la doua instalari ale aceluiasi produs DBMS.
Aceste precautii pot fi combinate in principiu (spre exemplu data diversity poate fi folosita in diverse produse DBMS) si implementate in diverse moduri, incluzand aplicatii manuale facute de catre operatorul uman.
Printre formele de diversitate prezentate mai sus, design diversity pare a fi cea mai buna pentru evitarea caderilor intamplatoare in cadrul executiilor redundante, dar poate insa impune limitari substantiale sau costuri de design crescute. In primul rand, produsele OTS DBMS, chiar daca implementeaza nominal operatiile limbajului standard SQL, in practica se folosesc "dialecte" diferite: se folosesc sintaxe diferite pentru comenzi care din punct de vedere semantic sunt la fel. Si mai important este faptul ca fiecare ofera functii nonstandard care necesita fie rescrieri ale sintaxelor mentionate mai sus ca o forma de data diversity, poate di utila pentru probleme ce pot aparea la rescrieri. In plus, multe aspecte din operarea unei baze de date sunt specificate intr-un mode nedeterministic, facand dificila asigurarea consistentei printre replica, chiar si cu replicarea aceluiasi produs si chiar mai mult cu replicarea diferentiala.
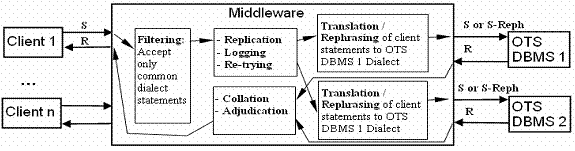
Fig7: Design stilizat al unui server de baze de date fault tolerant cu doua canale. Fiecare canal include o instalare a unui produs OTS DBMS (acestea pot fi fie acelasi produs, fie produse diferite, incluzand distributii ale aceluiasi produs) si o replica a bazei de date. Midleware trebuie sa asigure conectivitatea intre clienti si produsele DBMS, unele filtrari ale sintaxelor trimise de catre clienti (spre exemplu, trimiterea mesajelor de eroare catre clienti pentru sintaxele care nu sunt suportate de catre pprodusele OTS DBMS), replicarea si controlul tolerant la defecte(detectia erorilo, diagnoza si corectie, recuperare) si transcrierea sintaxelor SQL ("S") trimise de catre clienti catre dialectele produselor OTS DBMS respective. suport pentru "data diversity"prin "reformulare" poate forma de asemeni o parte din aceleasi componente care realizeaza transcrierea: Regulile de reformulare ("S-reph") vor produce versiuni reformulate ale sintaxelor trimise de catre clienti. Midleware trebuie de asemeni sa adjudece rezultatele ("R") de la produsele OTS DBMS si sa returneze un rezultat clientilor.
Un caz aparte de design diversity il reprezinta folosirea de distributii succesive ale aceluiasi produs DBMS. Aceasta duce la evitarea sau cel putin la reducerea problemelor create de diferentele de dialecte folosite. Ar fi de asteptat sa se tolereze mai putine defecte din moment ce distributiile successive ar avea in comun o mare parte din cod, inclusive unele bug-uri. Cu toate acestea, ar putea fi atractiv pentru actualizari privind finetea, care in alte situatii ar putea cauza unele scaderi pe alocuri ale stabilitatii la instalarea bazei de date, datorita noilor defecte introduse, si in acelasi timp pentru a se evalua daca noua distributie a atins dependenta suficienta pentru a deveni de sine statatoare.
Vom discuta in continuare despre optiunile arhitecturale disponibile pentru proiectarea solutiilor automate de detectie a defectelor, avand anumite forme de diversitate aplicate produselor OTS DBMS. Consideram o arhitectura "black-box" simpla prin care se trimite controlul redundantei catre un nivel din middleware ca in figura 7, astfel multiple produse DBMS apar utilizatorilor ca fiind un singur server. Ar putea fi un numar oarecare de canale, totusi valorile uzuale vor fi 1 (folosirea redundantei de timp prin repetarea executiei la nevoie pe un singur produs DBMS), 2 si 3 (minimul care permite mascarea erorilor prin votare). Vom face referire la sistemele cu doua replici, in caz contrar vom face precizare privid numarul de replici.
Aceasta arhitectura de baza poate fi folosita pentru diverse strategii de tolerare a defectelor, cu diverse schimburile dintre acoperirile tipurilor de caderi, performante, usurinta la integrare, si asa mai departe. Cele mai complexe aspecte de design pun problema aigurarii determinismului schemelor de replicare care il necesita. Partea dificila este ca fiecare produs DBMS are propria strategie de control al concurentei, acesta fiind nedeterministic si poate fi diferit de alte produse. Pentru nivelul middleware controlul generic al produselor OTS este mai dificil, mai ales in conditiile in care anumiti comercianti ar putea pastra aceste detalii secrete. Nivelul middleware poate inseria sintaxe la fel pe toate replicile. Acestea se reflecta in costuri ale performantelor, dar acestea vor fi acceptate pentru multe instalari, desi intolerabile la altele, in functie de tipurile de scriere folosite la o anumita instalare.
Optiuni de design prin diversitate pentru toleranta defectelor
Detectia defectiunilor serverelor
Raspunsuri eronate la sintaxe de citire pot fi detectate prin compararea rezultatelor de la iesirea canalelor, se detecteaza defectiunile care nu sunt foarte evidente si care pot cauza unele discrepante respectivelor semnale de iesire.
Atat diversitatea de design cat si diversitatea de date maresc sansa de detectie fata de replicarea simpla. In cazul determinismului replicarii este necesar ca discrepantele dintre rezultatele corecte trebuie sa fie rare, dat fiind ca acestea pot cauza resultate corecte ce ar putea fi considerate eronate fapt ce duce la reducerea performantelor. Defectiunile foarte evidente sunt detectate prin mesajele de eroare de la server (detectia se face prin mecanismul de detectie existent al produselor DBMS).
Update-uri eronate catre baza de date ce cauzeaza doar discrepante intre semnalele de iesire pot fi o problema in viitor. Pentru detectia lor, in middleware se pot compara continuturile replicilor bazei de date prin comenzile standard de citire ale produselor DBMS. Exista un grad de libertate in ceea ce priveste compararea, pentru a permite inbunatatirea raportului latenta/performanta. Middleware poate interoga fiecare produs DBMS cu privire la lista inregistrarilor modificate in fiecare operatie de scriere si apoi citeste si compara continuturile. In principiu, un produs DBMS cu bug-uri poate omite unele inregistrari mogificate din lista pe care o returneaza. Totusi, un designer ar putea decide compararea unui superset de date care par a fi afectate, lucru ce ar putea duce la o mai buna detectie a erorilor.
Un alt compromis ar putea fi facut intre latenta erorolor si componenta globala impusa de operatia toleranta la defecte: Detectia erorilor poate fi programata intr-un mod mai mult sau mai putin pessimist. In cel mai pessimist mod, la fiecare operatie, middleware executa toate comparatiile inainte de a inainta catre client raspunsul de la produsul DBMS. Un mod mai optimist se rezuma la inaintarea rezultatelor imediat si verificarea lor in paralel printr-o operatie ulterioara a clientului si a produsului DBMS.
In plus, middleware poate reduce capacitatea pentru sarcini de revizie, rulate in background, comparand intreg continutul replicilor bazei de date.
Oprirea erorilor, diagnoza si corectie
Oprirea erorilor este foarte strans legata de detectie. Pentru sintaxele de citire, middleware primeste raspunsuri multiple pentru fiecare sintaxa trimisa catre diverse canale, cate unul pentru fiecare din ele, si trebuie sa returneze un singur raspuns catre client. In general, middleware va trimite catre client un raspuns de eroare a produsului DBMS ca fiind un raspuns corect dar posibil intarziat sau ca find o eroare self-evident. Defectiunile produsului DBMS pot fi mascate in cazul in care middleware poate selecta un rezultat care are o probabilitate destul de mare de a fi corect.
Daca mai mult de doua raspunsuri redundate sunt disponibile, se poate folosi medoda votului majoritar pentru a selecta un rezultat aprobat si pentru a identifica replica defecta, care ar putea necesita o actiune de recuperare pentru a-i corecta starea.
Cu numai doua canale redundante, daca acestea dau rezultate diferite, middleware nu poate decide care dintre acestea este eronat. O posibilitate este de a nu oferi mascarea, in schimbul unui rezultat de eroare ce trebuie urmarit prin diagnoza manuala a problemei. Ca alternativa, executii redundante aditionale pot fi rulate prin reluarea sintaxelor, posibil cu diversitate de date, adica reformularea sintaxelor.
In functie de cum sunt organizate executiile redundante, middleware ar putea fi nevoit sa rezolve situatii mai complexe. Spre exemplu, doua produse DBMS diferite, A si B, pot da rezultate diferite dupa ce au fost supuse primei sintaxe de citire, unde, resupunerea la o sintaxa reformulate, A produce un mesaj de eroare, iar B produce un mesaj similar rezultatului intors de A la pasul precedent.
Recuperarea starii
Dincolo de selectarea rezultatelor probabil corecte, adjudecarea va identifica canalele probabil defecte in serverul de baze de date tolerant la defecte. Aceasta inbunatateste disponibilitatea: middleware poate selecta actiuni de recuperare directa pentru canalul diagnosticat cu defecte, permitand in acelasi timp si altor canale sa ofere in continuare serviciile.
Starea unui canal poate fi vazuta ca fiind compusa din starea datelor permanente in baza de date si cea a datelor volatile din variabilele produsului DBMS. Pentru stari eronate din final, dat fiind ca middleware nu poate vedea starea interna a fiecarei executii, produsul DBMS poate lua anumite masuri cum ar fi oprirea si repornirea produsului DBMS.
In ceea ce priveste recuperarea starii continutului bazei de date, aceasta poate fi obtinuta prin urmatoarele metode:
Standard backward error recovery - aceasta ar putea fi uneori eficienta, cel putin, daca defectele nu au deteriorat proprietatile de integritate, consistenta, izolare si durabilitate in tranzactia afectata. Diversitatea datelor va extinde setul de defectiuni ce ar putea fi recuperate prin aceasta metoda. Pentru a comanda recuperarea intarziata a erorilor, middleware poate folosi mecanismul standard de tranzactie in baza de date. Abordarea tranzactiei defecte si rerularea sintaxei ar putea produce o executie corecta. Ca alternative, middleware poate comanda ca starile replicilor bazei de date sa fie salvate la interbale regulate de timp (prin executia comenzilor de back-up a bazei de date, spre exemplu in PostgeSQL, comanda pg_dump). Dupa o cadere, o replica a bazei de date este readusa la ultimul checkpoint, iar middleware reia secventa de sintaxe. Pentru a obtine o mai buna granularitate a recuperarii, mecanismul de revenire la checkpoint poate fi folosit si la transactii: aceasta permite tratarea exceptiilor prin transactii si ar trebui aplicat cand se foloseste diversitatea datelor la "reformulare"
Diversitate in plus, aceasta permite recuperearea inaintata prin copierea starii unei replica de baza de date corecte in baza de date eronata. Deoarece formatele fisierelor bazelor de date difera intre produsele DBMS, middleware ar trebui sa interogheze canalele corecte pentru continutul bazelor de date si sa comande canalului eronat sa scrie informatiile corecte in inregistrarile corespunzatoare din baza de date. Aceasta solutie ar fi consumatoare de timp pentru a se finaliza, dar un designer poate folosi recuperare pe mai multe nivele, unde primul pas este corectarea inregistrarilor caer au fost gasite eronate la sintaxele de citire.
In timpul fazei de recuperare, serverul fault-tolerant ar lucra cu redundanta redusa. Un server cu doua canale, tolerant la defect ear fi redus la o configuratie netoleranta la defecte. Designerului i se pun la dispozitie durata fazei de recuperare (care poate fi scurtata prin folosirea algoritmilor mai eficienti sau prin reduerea lungimea starii care este verificata si corectata) si gradul de conversie aplicat in timpul operatiei netolerante la defecte.
|
Politica de confidentialitate |
| Copyright ©
2025 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |
