Structura documentelor XML
Recomandarea XML stabileste faptul ca un document XML are atat o structura logica, cat si o structura fizica. Logic, un document consta din declaratii, elemente, comentarii, referinte de caractere si instructiuni de prelucrare. Fizic, un document cuprinde unitati de memorare numite entitati, care la randul lor pot contine alte entitati.
► Structura logica descrie modul in care este construit un document XML, identificand partile acestuia si relatiile dintre ele. In structura logica generala a unui document XML se identifica doua parti, construite in ordinea urmatoare:
Prolog.
Corp.
♦ Prologul, cu caracter optional, este uzual impartit in doua componente: o declaratie XML si o declaratie de tip de document.
Declaratia XML furnizeaza informatii privind caracteristici ale documentului in ansamblu:
Versiune (version): identifica ce versiune de specificatii XML este folosita;
Codificare (encoding): precizeaza setul de caractere standard folosit la codificarea continutului documentului;
Document de sine statator (standalone): permite autorului sa specifice daca documentul este de sine statator (valoarea 'yes') sau nu (valoarea 'no').
Versiunea poate avea una din valorile '1.0' sau '1.1', acestea fiind singurele versiuni ale XML publicate pana in prezent de catre W3C. In forma sa cea mai simpla, care specifica doar versiunea utilizata, declaratia XML arata astfel:
<?xml version='1.0'?>
Spre deosebire de HTML, XML este senzitiv la tipul de litera utilizat, astfel incat este important de retinut ca este obligatorie scrierea cu litere mici a sirurilor xml si version. In interiorul declaratiei nu sunt permise spatii intre parantezele unghiulare si semnul intrebarii sau inainte de sirul xml, iar sirul de caractere reprezentand numarul versiunii se scrie intotdeauna intre semnele citarii('').
In cele mai multe cazuri, declaratia XML este prezenta, situatie in care trebuie sa fie prima linie a documentului, fara eventuale linii vide sau spatii la inceput, deoarece se poate ajunge la mesaje de eroare la tentativa de deschidere a documentului. Declaratia este tehnic optionala, un caz cand poate fi omisa fiind acela al combinarii unor secvente codificate in XML (dar memorate separat) pentru a crea documente compuse mai mari.
In acord cu specificatia XML 1.0, declaratiei XML i se poate asocia urmatoarea definitie formala:
XMLDecl ::= '<?xml' VersionInfo EncodingDecl? SDDecl? S? '?>'In definitie este folosita notatia EBNF (Extended Backus-Naur Form), caracteristica multor specificatii W3C, in care metavariabila din membrul stang (XMLDecl) este prin definitie (::=) constructia din membrul drept, respectiv: sirul de caractere '<?xml', informatia ceruta asupra versiunii (VersionInfo), eventuale declaratii optionale privind codificarea (Encoding Declaration) si statutul documentului (SDDecl = Standalone Document Declaration), urmate de un numar oarecare de spatii (S) si terminandu-se cu sirul de caractere '?>'.
In aceasta notatie formala, un semn al intrebarii neinclus intre apostrofuri inseamna ca termenul care il precede este optional. Din analiza definitiei rezulta deci ca, atunci cand este prezenta, declaratia XML trebuie sa contina cel putin informatia despre versiune, celelalte avand caracter optional..
Referitor la codificare, trebuie precizat ca documentele XML au in vedere standardul Unicode, care este standardul universal de reprezentare a caracterelor in textele prelucrate cu calculatorul. Institutia responsabila cu publicarea si tinerea la zi a acestui standard este consortiul Unicode (Unicode Consortium, www.unicode.org) , acelasi standard fiind publicat si de catre ISO (International Organization for Standardization, www.iso.org) ca ISO/IEC 10646: the Universal Character Set (UCS).
Versiunile Unicode sunt complet compatibile si sincronizate cu versiunile corespunzatoare ISO, cele doua organisme lucrand in tandem inca din 1981. De exemplu, Unicode 4.0 contine exact aceleasi caractere si foloseste aceleasi reprezentari ca ISO/IEC 10646:2003.
Obiectivul major al crearii Unicode a fost asigurarea unui cadru unitar de reprezentare a caracterelor pentru toate limbile utilizate la nivel planetar.
Tim Bray, unul din liderii grupului de lucru XML, explica in cateva din eseurile sale logica de ansamblu a standardului Unicode si argumenteaza decizia alegerii lui ca baza pentru reprezentarea caracterelor in documentele XML
In deceniile de inceput ale informaticii, textele au fost memorate folosind codurile ASCII ((American Standard Code for Information Interchange), pe 7 biti sau EBCDIC (Extended Binary Coded Decimal Interchange Code), pe 8 biti, ambele realizand reprezentarea cu cate un caracter pe un octet (byte). EBCDIC a fost dezvoltat si promovat de catre IBM, fiind utilizat cu precadere pentru calculatoarele mari (mainframe) si minicalculatoare.
Pentru microcalculatoare s-a generalizat utilizarea codului ASCII, publicat ca standard ANSI (American National Standards Institute), cu versiunea de referinta ANSI X3.4-1986.
Daca ASCII a devenit predominant in Europa si America de Nord, in alte parti ale lumii s-au inventat sisteme proprii pentru reprezentarea caracterelor specifice limbilor respective: JIS in Japonia, KOI8 pentru limba rusa, diferite standarde ISCII pentru limbile utilizate in India s.a.m.d. Cat despre limba chineza, asa cum releva Bray, numai in Taiwan erau la un moment dat in uz 12 sisteme de codificare diferite.
Pentru majoritatea limbilor din America, Europa si Orientul Mijlociu, care folosesc alfabete de mici dimensiuni, s-a creat standardul ISO-8859, cu 16 parti, ca o extensie pe 8 biti a ASCII, in care codurile de la 0 la 127 (7 biti) sunt pastrate ca atare, iar intervalul de valori de la 128 la 255 este refolosit pentru caractere accentuate (cu diacritice) ale limbilor bazate pe alfabetul latin (partile 1 la 4), cirilic (partea 5), arab (6), grec (7), ebraic (8) etc. Cu titlu de exemplu, mentionam ca limbilor Europei de Vest le este asociat standardul ISO-8859-1 (Latin-1), iar celor din Europa Centrala si de Est standardul ISO-8859-2 (Latin-2 sau Latin Extended A), in care se regasesc si literele cu diacritice specifice limbii romane.
Unicode si-a propus unificarea acestor diverse sisteme intr-un standard universal, definind coduri unice pentru caracterele folosite in toate limbile majore in care se scrie astazi, de la alfabetele din Europa, la cele cu scriere de la dreapta la stanga din Orientul Mijlociu si pana la numeroasele sisteme de scriere folosite in Asia. In continuare, standardul Unicode include semne de punctuatie, diacritice, simboluri matematice, simboluri tehnice, sageti etc.
Fiecare caracter are o denumire si un cod unic, exprimat in standardul Unicode in forma U+HHHH, unde HHHH sunt cifre hexazecimale.
Un rol aparte au diacriticele, care sunt simboluri specifice atasate unor caractere de baza, folosite impreuna pentru a reprezenta litere accentuate. De exemplu, caracterul de baza A din alfabetul latin (denumire: LATIN CAPITAL LETTER A, cod: U ), combinat cu simbolul ˘ (BREVE, U+02D8), da litera A din limba romana (LATIN CAPITAL LETTER A WITH BREVE, U
In total, versiunea 4.0 a standardului Unicode contine coduri pentru 96.447 de caractere din diverse alfabete, seturi de ideograme si colectii de simboluri. Teoretic, insa, exista posibilitatea reprezentarii a 1.114.112 puncte de cod, a caror multime este organizata in 17 planuri, numerotate de la 0 la 16, fiecare cu 2 (65.536) caractere. Planul 0 este numit BMP (Basic Multilingual Plane) si contine aproape tot ceea ce este util in prezent, practic codificand toate caracterele care au fost vreodata disponibile programatorilor inainte de crearea Unicode.
Dincolo de BMP, planurile 1 la 17 sunt numite uneori "planuri astrale", fiind dedicate unor caractere exotice, rare, sau care au avut o anumita importanta istorica.
Impreuna cu caracterele, standardul Unicode
defineste si metodele pentru reprezentarea lor pe succesiuni de
octeti in memoria calculatorului. Exista trei abordari, denumite
UTF-8,
UTF-16
si UTF-32
(unde UTF provine de la Unicode Transformation Format
UTF-8 se bazeaza pe transformarea tuturor caracterelor Unicode intr-o codificare pe un sir de unu pana la patru octeti, depinzand de valoarea codului acestora. El are marele avantaj ca toate caracterele Unicode corespunzand celor din codul ASCII, pastreaza, dupa transformarea in UTF-8, aceeasi reprezentare pe un octet, astfel incat ele pot fi utilizate cu cele mai multe dintre produsele software existente, fara necesitatea unor adaptari. UTF-8 este frecvent utilizat pentru documentele HTML, cat si pentru cele XML, majoritatea procesoarelor XML acceptandu-l ca format de codificare implicit.
UTF-16 reprezinta caracterele Unicode in secvente de 16 biti si este de preferat in situatiile cand trebuie asigurat un echilibru intre accesul eficient la caractere si folosirea economica a memoriei. El asigura o reprezentare suficient de compacta, astfel incat toate caracterele din BMP (cu coduri intre 0 si 65535) pot fi reprezentate direct, in timp ce pentru caracterele din planurile astrale, ale caror coduri au valori mai mari, sunt necesare doua perechi de unitati de cod de 16 biti, ajungandu-se deci la o reprezentare pe patru octeti. Fara a intra in detalii, mentionam doar ca in acest caz se recurge la o solutie de reprezentare bazata pe asa-numitele "coduri surogat", usor de implementat de programatori. Corespunzator, multe procesoare XML asigura suport si pentru UTF-16, alaturi de UTF-8.
UTF-32 ofera cea mai simpla metoda de codificare, reprezentand fiecare caracter pe o lungime fixa de 32 de biti (4 octeti). Avantajul acestei simplitati conteaza, insa, doar pentru cazurile in care spatiul de memorie utilizat nu este o restrictie. Datorita necesarului mare de memorie, UTF-32 nu este unul din sistemele preferate pentru documentele XML.
XML accepta codificarea textelor XML in oricare din sistemele anterioare Unicode, dar nu ofera garantia ca un produs software va fi capabil sa citeasca altceva decat codificarile standard UTF. Astfel, majoritatea procesoarelor XML recunosc uzual standardele UTF-8 si UTF-16, conformandu-se recomandarilor din specificatiile XML ale W3C, dar multe accepta si alte standarde, cum este ISO 8859-1 (Latin-1).
In concluzie, documentele care folosesc alte standarde decat cele acceptate de un anumit procesor trebuie sa inceapa cu o declaratie XML specificand standardul folosit. Pentru asigurarea portabilitatii, specialistii recomanda ca standardul preferat sa fie UTF-8, dar chiar si in acest caz, pentru completitudine, se recomanda specificarea explicita a acestuia in declaratia XML.
In cazul in care un document XML este codificat folosind un standard neacceptat de un anumit procesor, la prima intalnire a unui caracter cu o reprezentare neconforma acestuia se va produce o eroare.
De exemplu, sa reconsideram documentul XML creat cu Notepad si prezentat in figura 2, redactat in limba romana. In document a fost evitata, totusi, utilizarea diacriticelor, cuvantul salariati fiind scris salariati. Simpla scriere corecta a cuvantului nu rezolva problema, la incercarea de accesare a documentului cu Internet Explorer producandu-se eroare, la intalnirea primului caracter cu diacritice (figura 3.a).
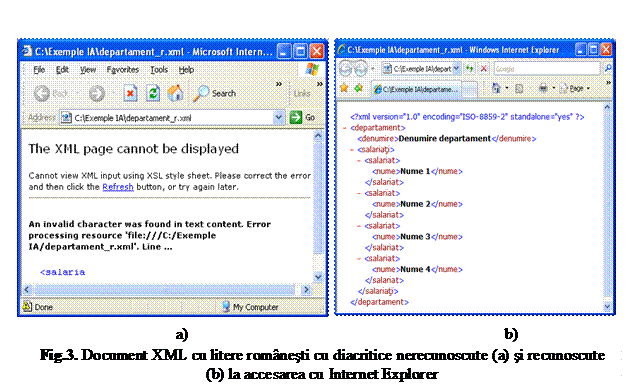 Explicatia provine din faptul
ca documentul contine un caracter cu diacritice specific standardului
ISO-8859-2, nerecunoscut implicit de catre modulul cu rol de procesor XML
al Internet Explorer. Or,
datorita faptului ca declaratia XML lipseste, documentul a
fost considerat implicit ca UTF-8, in timp ce in Notepad a fost salvat ca ASCII
(referit ca ANSI in lista tipurilor pe care acesta le accepta pentru
salvarea documentelor).
Explicatia provine din faptul
ca documentul contine un caracter cu diacritice specific standardului
ISO-8859-2, nerecunoscut implicit de catre modulul cu rol de procesor XML
al Internet Explorer. Or,
datorita faptului ca declaratia XML lipseste, documentul a
fost considerat implicit ca UTF-8, in timp ce in Notepad a fost salvat ca ASCII
(referit ca ANSI in lista tipurilor pe care acesta le accepta pentru
salvarea documentelor).
Solutia cea mai simpla este includerea la inceputul documentului a unei declaratii XML de forma:
<?xml version="1.0" encoding="ISO-8859-2"?>
Ca rezultat, documentul va putea fi complet analizat sintactic, fiind afisat de navigator in forma prezentata in figura 3.b.
O alta solutie este ca la salvarea documentului in Notepad sa se aleaga codificarea UTF-8, caz in care ar putea fi omisa precizarea ei din declaratia XML, avand in vedere ca UTF-8 este considerat implicit prin lipsa.
O declaratie XML si mai completa, prezenta deja in figura 3, arata astfel:
<?xml version='1.0'encoding='UTF-8' standalone='yes'?>
unde prin standalone='yes' se declara un document de sine statator.
Pentru intelegerea corecta a sintagmei « document de sine statator » este necesara analiza distinctiei dintre doua concepte folosite in specificatiile XML : document bine format, respectiv document valid.
XML permite utilizarea unui fisier cu scopul de a verifica daca un document este conform unei sintaxe date. Norma XML introduce in acest scop o DTD (Document Type Definition), adica o gramatica permitand sa se verifice conformitatea documentului XML. Folosirea unei DTD pentru fiecare document XML nu este obligatorie, dar trebuie asigurata respectarea exacta a regulilor de baza ale specificatiei XML.
Corespunzator, se face distinctie intre :
O DTD poate fi definita in doua moduri :
Un document XML se considera de sine statator (standalone='yes') atunci cand fie nu necesita o DTD, fie aceasta este interna.
In cazul unei DTD externe, referinta la aceasta se include in declaratia de tip de document (parte a prologului, ca si declaratia XML), caz in care standalone='no', valoare presupusa implicit prin lipsa. Asupra acestei declaratii vom reveni in paragraful destinat prezentarii DTD.
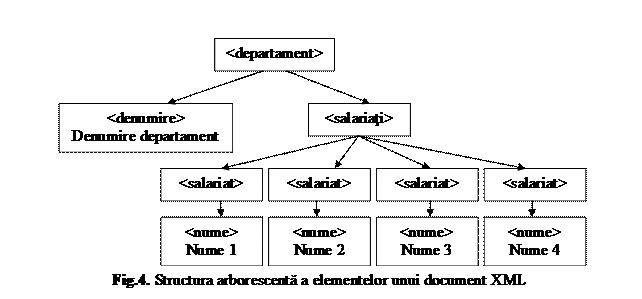
♦ Corpul este construit in continuarea prologului si contine toate datele din documentul XML. Corpul este referit in specificatii ca Element Document, fiind asemanator directorului radacina (root) al unei unitati de disc, care contine toate datele de pe acea unitate, divizate intr-un numar oarecare de directoare si subdirectoare.
Considerand exemplul din figura 3.b, elementul root corespunde ansamblului datelor departamentului, fiind delimitat de perechea de marcaje <departament> .</departament>. El poate contine un numar oarecare de alte elemente, organizate intr-o structura arborescenta cu mai multe niveluri de imbricare, in care se creeaza relatii de tipul element parinte - element copil. Elementele cu acelasi parinte sunt considerate surori (sibling elements). Structura arborescenta a elementelor ce formeaza corpul (Element Document) documentului XML cu datele departamentului este prezentata in figura 4.
Pentru a intelege mai bine modul de construire a documentelor XML este necesara o prezentare sintetica a regulilor de sintaxa asociate elementelor:
Verificarea structurii logice este asigurata de catre analizorul sintactic (parser) al navigatorului sau, mai general, al agentului software al utilizatorului, care verifica daca documentul este bine format, respectiv daca satisface regulile de sintaxa ale DTD asociate (fie ea interna sau externa), atunci cand aceasta exista.
► Structura fizica. In timp ce structura logica se refera la organizarea documentului, structura fizica corespunde continutului fizic al documentului XML.
Acest continut este divizat in piese de informatie numite entitati. In general, ca si in exemplele anterioare, acest continut este text, dar poate fi format si din date binare cum ar fi un fisier imagine. Entitatile au nume prin care pot fi identificate, si acestea trebuie declarate in prolog (uzual intr-o DTD). Ele sunt referite ulterior in interiorul corpului documentului (elementul root). La nivelul de baza, elementul radacina este si el o entitate, deoarece este elementul cel mai general al documentului, care contine toate celelalte elemente.
Deoarece toate documentele XML bine formate trebuie sa contina un element radacina, ele au astfel cel putin o entitate. Intrucat elementele se refera la continut si nu la structura, prologul si DTD nu sunt tratate ca entitati, desi sunt parte a structurii XML.
Exista doua tipuri de entitati :
Entitatile interne sunt complet definite in documentul insusi. Aceasta inseamna ca intreg continutul entitatii este gasit in documentul principal si ca acesta este declarat in prolog. Entitatile interne sunt intotdeauna de tip text.
Entitatile externe, spre deosebire de cele interne, nu sunt localizate in documentul principal, ci intr-un fisier sau sursa externa. Documentul principal contine numai o referinta la fisierul extern, printr-un URL sau o legatura. Exemplul tipic de entitate externa este un fisier imagine. Atat entitatile interne cat si cele externe pot fi analizate sintactic (parsed) sau neanalizate (unparsed). Continutul entitatilor analizate sintactic este text care respecta regulile XML. Entitatile neanalizate sunt date binare sau text care nu este in acord cu regulile generale ale XML, dar respecta regulile date de catre autor in DTD. Rezulta astfel patru combinatii posibile de entitati:
Exemplul folosit anterior contine numai entitati interne analizabile.
Un alt concept de baza privind structura fizica a unui document XML este cel de atribut. Atributele ofera o metoda de asociere de valori elementelor unei instante de document XML, fara a face atributele parte a continutului elementelor individuale. Revenind la exemplul nostru, daca s-ar introduce un element <an> in ansamblul datelor unui angajat, nu rezulta implicit ce fel de 'an' este: ar putea fi anul nasterii sau anul angajarii. Atributele sunt o cale simpla de de a specifica acest tip de informatie pentru elementele dintr-un document XML, adaugand perechi denumire/valoare in cadrul marcajului de inceput asociat elementului, cum ar fi:
<an ti
p='nastere'> sau < an tip='angajare'>
Fiecare atribut consta dintr-o denumire si o valoare, separate prin semnul egal. Denumirea atributului se construieste dupa aceleasi reguli ca si denumirea marcajelor, fiind de asemenea context senzitive. Unii autori sugereaza diferentierea marcajelor de atribute prin scrierea celor dintai cu majuscule si a celolalte cu litere mici, dar important este ca o conventie odata introdusa sa fie respectata cu strictete.
Valoarea atributului este orice urmeaza dupa semnul egal si trebuie incadrata intre semnele citarii (simple sau duble). Spre deosebire de denumirile atributelor, exista foarte putine limitari referitor la continutul unei valori de atribut. Ele pot contine aproape orice tipuri de caractere si spatii (cu conditia ca ele sa fie disponibile in schema de codificare utilizata). O exceptie importanta se refera la semnele citarii. Practica uzuala este de incadrare a valorii in semnele citarii duble, ca in exemplele de mai sus.
Totusi, daca ele insele se regasesc in valoarea atributului atunci delimitarea se va face cu semne simple si viceversa. De exemplu, pentru o dimensiune exprimata in inches:
<latime='12''> va fi corect, in timp ce <latime='12''> va fi incorect.
Textul care apare intre perechile de marcaje corespunde asa-numitelor date caracter (character data) si poate contine aproape orice caractere Unicode (implicit) sau, eventual, specifice schemei de codificare declarate in prolog. Orice in afara acestor date este considerat ca marcaj (markup), adica marcajele propriu-zise, instructiuni de prelucrare, DTD-uri si altele.
O exceptie referitor la datele caracter se constata in cazul caracterelor ampersand (&), semnelor citarii simple si duble (' si ') si a parantezelor unghiulare (< si >), care nu pot apare in cadrul sectiunilor de date caracter. Motivul este ca ele sunt rezervate pentru instructiuni de prelucrare XML. Totusi, folosirea lor in cadrul datelor caracter este posibila prin asa numitele referinte de entitati (entity references), care sunt combinatii de caractere scrise intre un & (ampersand) si un ; (semicolon). Urmatoarele cinci referinte de entitati sunt predefinite in XML:
& = &
< = <
> = >
" = '
' = '
Referintele de entitati sunt exemple de entitati externe analizabile sintactic, deoarece sunt referinte la portiuni de text care exista in afara documentului. La momentul analizei sintactice, referinta de entitate este inlocuita de textul extern. Aceasta inseamna ca, atunci cand documentul este analizat sintactic, toate aparitiile referintei de entitate & in interoirul unei sectiuni de date caracter sunt inlocuite cu simbolul ampersand (&).
CDATA
Cum s-a vazut anterior, aproape orice nu este in interiorul unei perechi de paranteze unghiulare este considerat a fi date caracter in XML. De asemenea, toate aparitiile caracterelor &, <, >, ' si ' trebuie inlocuite prin referintele de entitate corespunzatoare, pentru ca documentul XML sa fie considerat bine format. Daca insa avem prea multe asemenea caractere speciale intr-un text, pentru a evita constructiile foarte lungi si obositoare, se pot introduce in documentele XML sectiuni numite CDATA.
CDATA sunt portiuni de text in care analizorul XML nu incearca sa interpreteze textul, unde textul este considerat ca atare. Toate aparitiile lui & inr-o sectiune CDATA vor fi citite ca &.
SectiunileCDATA incep cu <![ si se incheie cu ]]>. Singurul text care nu este permis intr-o sectiune CDATA este delimitatorul final ] ]>.O DTD ne permite sa definim structura propriilor documente XML. Ea ofera o structura stricta si reguli care trebuie respectate cand se creeaza documente XML. In plus, o DTD paote fi utilizata pentru a verifica validitatea si integritatea datelor continute intr-un document XML, prin caracteristici ca:
Specificarea elementelor valide si a atributelor care pot fi folosite in documentele XML.
Cu o DTD se poate defini structura ierarhica a elementelor.
Prin DTD se poate defini si organizarea secventiala a elementelor copil ce pot exista intr-un document XML.
In esenta, o DTD consta din urmatoarele componente:
|
Item |
Descriere |
|
Element DTD |
Metadate despre un element. Specifica ce tip de date va avea elementul, numarul de realizari (aparitii) ale fiecarui element, relatii dintre elemente s.a.m.d. |
|
Atribute DTD |
Specifica diferite reguli si specificatii asociate cu datele. |
|
Entitati DTD |
Folosite pentru referirea unui fisier extern sau pentru a servi ca "scurtaturi" (short cuts) pentru textele obisnuite |
On the Goodness of Unicode (https://www.tbray.org/ongoing/When/200x/2003/04/06/Unicode
Characters vs. Bytes https://www.tbray.org/ongoing/When/200x/2003/04/26/UTF
|
Politica de confidentialitate |
| Copyright ©
2025 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |
