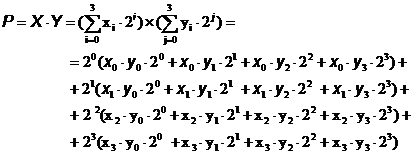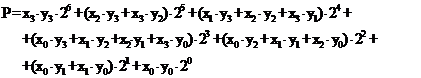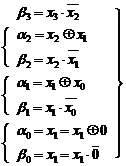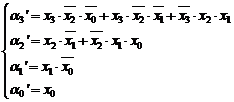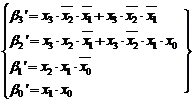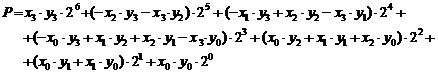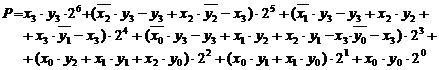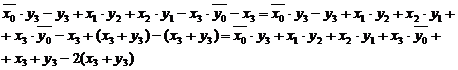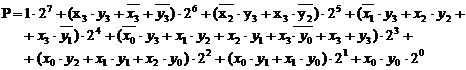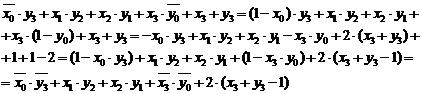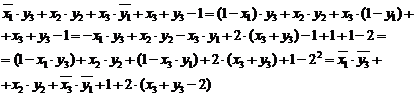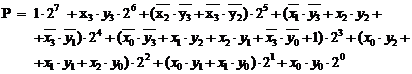Structuri matriciale combinationale pentru inmultirea binara
Asa cum mentionam in paragraful anterior, la polul opus procedurilor "one - bit - at - a time" se situeaza cele la care, in modul complet paralel, sunt investigati toti bitii multiplier-ului X concomitent, operatia fiind executata intr-un singur impuls de CLOCK. Una dintre solutiile de implementare in acest sens o constituie apelarea la asa numitele structuri matriciale combinationale (combinational array structures). Pentru a ajunge la sinteza unor astfel de multiplier-e, sa reanalizam modul de formare a unui produs.
Fara a pierde din generalitate si doar din ratiuni de economisire a scrierii, sa consideram cei doi operanzi, X si Y, reprezentand doua numere intregi si fara semn, de 4 biti, adica :
|
|
Pe de o parte, produsul ![]() se formeaza,
luand in consideratie ponderea fiecarui bit, pe seama urmatoarei
dezvoltari se obtine o forma care pune in evidenta
produse de un bit :
se formeaza,
luand in consideratie ponderea fiecarui bit, pe seama urmatoarei
dezvoltari se obtine o forma care pune in evidenta
produse de un bit :
|
|
Daca in forma (3.25) se rearanjeaza termenii grupand produsele de un bit de aceiasi pondere, se ajunge la :
|
|
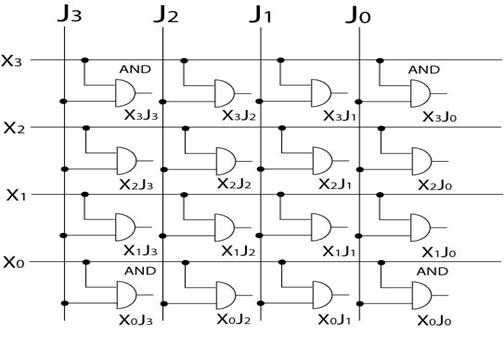
Relatia (3.26) sta la baza sintezei multiplier-ului ca o
structura matriceala combinationala. Aceasta este
alcatuita din doua matrici de circuite, dintre care prima are
menirea de a forma termenii produs de un bit ![]() . Intrucat, la nivelul unui singur bit, produsul aritmetic
coincide cu produsul logic, aceasta prima matrice consta din n
. Intrucat, la nivelul unui singur bit, produsul aritmetic
coincide cu produsul logic, aceasta prima matrice consta din n![]() n circuite logice AND dupa modelul din fig. 3.40. Iesirile
circuitelor AND sunt aplicate unei a doua matrici alcatuita, de
aceasta data, din celule full adder cell (FAC) care, interconectate
corespunzator, au menirea de a realiza mai multe sumatoare RCA, cate unul
pentru fiecare suma dintre paranteze plus cei doi termeni extremi din
relatia (3.26).
n circuite logice AND dupa modelul din fig. 3.40. Iesirile
circuitelor AND sunt aplicate unei a doua matrici alcatuita, de
aceasta data, din celule full adder cell (FAC) care, interconectate
corespunzator, au menirea de a realiza mai multe sumatoare RCA, cate unul
pentru fiecare suma dintre paranteze plus cei doi termeni extremi din
relatia (3.26).
|
|
|
Fig.3.40 |
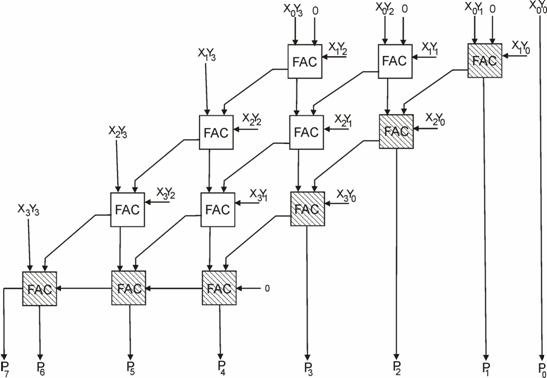
Deplasarea impusa de procesul de inmultire (marcata in
(3.25) si (3.26) prin ponderile lui 2) este asigurata prin dispunerea
spatiala a celulelor FAC, asa cum se arata in fig. 3.41.
Este de remarcat ca sumele dintre parantezele relatiei (3.26) pot da
carry, astfel incat bitii ![]() , unde
, unde ![]() , ai produsului se obtin luand in consideratie
si potentialii biti de transport din rangurile anterioare. Perioada trenului
impulsurilor de clock care strobeaza aplicarea celor 2 operanzi X si
Y, la structura matriceala combinationala trebuie sa
acopere intervalul de timp necesar traversarii de catre semnale a
caii celei mai defavorabile, implicand numarul cel mai mare de
circuite logice. Ori, la schema din fig.3.41, se poate observa, in mod simplu,
ca inlantuirea celor 6 FAC-uri hasurate (intr-un RCA)
stabileste calea cea mai defavorabila (lunga), care corespunde
propagarii carry-ului. Daca notam cu d intarzierea (delay) pe un
FAC, atunci, admitand operanzi de n biti, pentru matricea de FAC-uri
(fig.3.41), rezulta timpul de
, ai produsului se obtin luand in consideratie
si potentialii biti de transport din rangurile anterioare. Perioada trenului
impulsurilor de clock care strobeaza aplicarea celor 2 operanzi X si
Y, la structura matriceala combinationala trebuie sa
acopere intervalul de timp necesar traversarii de catre semnale a
caii celei mai defavorabile, implicand numarul cel mai mare de
circuite logice. Ori, la schema din fig.3.41, se poate observa, in mod simplu,
ca inlantuirea celor 6 FAC-uri hasurate (intr-un RCA)
stabileste calea cea mai defavorabila (lunga), care corespunde
propagarii carry-ului. Daca notam cu d intarzierea (delay) pe un
FAC, atunci, admitand operanzi de n biti, pentru matricea de FAC-uri
(fig.3.41), rezulta timpul de ![]() :
:
|
|
|
|
|
Fig.3.41 |
La acest interval mai trebuie
adaugat si delay-ul pe care il notam cu d', pe o poarta AND din
matricea reprezentata in fig.3.40. Intrucat toate produsele de un bit
rezulta in ![]() , avem pentru intreaga structura timpul TS
dat de:
, avem pentru intreaga structura timpul TS
dat de:
|
|
Cum, daca admitem, pentru
simplitate, ca delay-ul d' corespunde tuturor portilor logice,
indiferent de tip, atunci acceptand ![]() , conform cu (3.28) avem
, conform cu (3.28) avem ![]() si, de aici, o
complexitate de timp, in dependenta de intarzierea pe un circuit
logic elementar, de
si, de aici, o
complexitate de timp, in dependenta de intarzierea pe un circuit
logic elementar, de ![]() .
.
Pe de alta parte, in ceea ce priveste costul circuitelor,
implicit al ariei de integrare, dominanta este matricea de FAC-uri, ori
sinteza acesteia necesita, in general, ![]() celule FAC (fig.3.41). Prin urmare complexitatea
integrarii, in termeni de circuite reclamate sau arie de substrat de
siliciu, poate fi apreciata de
celule FAC (fig.3.41). Prin urmare complexitatea
integrarii, in termeni de circuite reclamate sau arie de substrat de
siliciu, poate fi apreciata de ![]() .
.
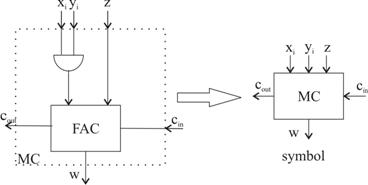
Ar mai fi de remarcat faptul ca intreaga structura matriceala este una ordonata, favorabila tehnologiei de integrare VLSI [Haye98]. Acest aspect rezulta si din "curgerea" interconexiunilor (vezi fig.3.40, dar in special fig. 3.41) dintre celule, dar, fiind alcatuita din doua matrice complet distincte, structura de integrat nu este omogena. Pentru a surmonta acest neajuns al integrarii VLSI, circuitele AND din prima matrice (fig.3.40) se asociaza celulelor FAC din a doua matrice (fig. 3.41), formand asa numite celule inmultitor (multiplier cell, MC), dintre care una este prezentata schematic in fig.3.42, impreuna cu simbolul aferent. Intrarile xi si yi sunt, uzual, valori de biti ale celor doi operanzi, X si Y, iar Z constituie o intrare conectata, uzual, la iesirea w a unui MC aflat in etajul de mai sus.
|
|
|
Fig.3.42 |
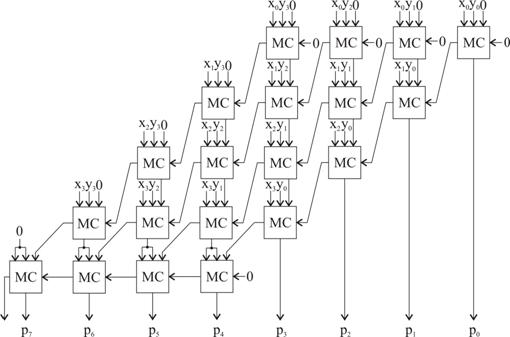
Uzitand de noile celule MC, sa configuram printr-o structura
matriceala combinationala aceeasi operatie de
inmultire a carei produs este dat de relatia (3.26). Se poate
remarca faptul ca MC-urile din primul etaj sunt folosite doar pentru
portile AND pe care le includ formand produsele de un bit avand unul dintre
factori pe x0. Acest "sacrificiu" de circuite este compensat de
structura regulata care face interconectarile dintre celule mai
simple, adica aria de substrat de siliciu revendicata de conexiunile
corespunzatoare unei structuri mai putin omogene este, in general,
mai mare decat cea necesara integrarii circuitelor "sacrificate". In
rest, celelalte MC-uri contribuie la formarea sumelor dintre parantezele
expresiei (3.26). Ar mai fi de observat ca ultimul etaj care, in
esenta "colecteaza" transporturi, are legaturile modificate
in raport cu celelalte etaje in sensul ca, fiind epuizati bitii
operanzilor, intrarile xi si yi sunt ambele
legate de iesirea w a celulei MC din etajul de mai sus. Desigur,
mentionam ca in layout-ul fizic al structurii s-ar putea ca
interconectarile sa difere fata de cele prevazute in fig.3.43,
in care s-a urmarit ca legaturile sa fie cat mai ordonate
si sa prezinte un numar minim de intersectii, obiective ce
reprezinta, de altfel, deziderate primare ale proiectarii tehnologice
a unui layout VLSI in general. De asemenea se poate remarca cresterea
numarului celulelor la ![]() , dar aceasta "scumpire" a implementarii este doar
aparenta avand in vedere particularitatile implementarii
unei astfel de structuri in tehnologie VLSI [Vlad86].
, dar aceasta "scumpire" a implementarii este doar
aparenta avand in vedere particularitatile implementarii
unei astfel de structuri in tehnologie VLSI [Vlad86].
|
|
|
Fig. 3.43 |
|
||||||||||||||
|
Fig.3.44 |
||||||||||||||
Odata introdusa problematica realizarii de multiplier-e
prin structuri matriceale combinationale, sa ne propunem o
sinteza mai complexa, anume sa admitem ca operanzii sunt
numere intregi cu semn si, in plus, sa aplicam proceduri bazate
pe recodificari Booth in radix 2. Stiut fiind ca ambele
recodificari apeleaza atat la operatia de adunare, cat si
la cea de scadere, precum si la a nu executa nicio operatie (no
operation, NOP), celula inmultitor, ca element fundamental al noii
structuri, va trebui sa fie diferita de cea studiata (MC). Ea va
trebui sa poata fi configurata dupa caz, astfel incat,
pentru iesirile w si cout (am adoptat notatiile uzitate in
fig.3.42), sa fie realizate ecuatiile booleene date in tabelul din fig.3.44.
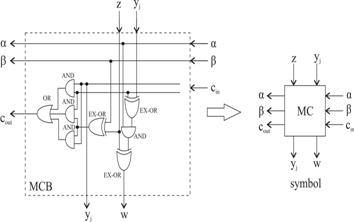
Iesirea w a noii celule inmultitor, pe care o notam cu MCB
(litera sufix B fiind adoptata de
scadere,
iar, in cazul NOP, ea trebuie sa reproduca intrarea z reprezentand
iesirea MCB-ului din etajul de mai sus. Ca si ![]() .
.
Pentru a distinge intre w corespunzator Addition si Substraction si w corespunzator NOP facem uz de o variabila de control pe care o notam cu a, iar, pentru a
|
||||||||||||||
|
Fig.3.45 |
||||||||||||||
distinge intre cout corespunzator Addition si cout corespunzator Substraction, uzitam de o a doua variabila de control pe care o notam b. Astfel, pentru a si b, adoptam conventiile din fig.3.45, unde d provine de la don't care si reprezinta o valoare logica indiferenta. Plecand de la cele din Fig. 3.45, si urmarind, prin particularizare, obtinerea ecuatiilor din fig.3.44, pentru w si cout rezulta, fara dificultate expresiile booleene:
|
|
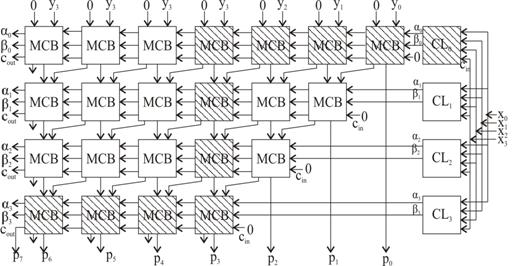
Pe baza ecuatiilor (3.29), pentru celula MCB, rezulta o posibila implementare la nivel de poarta ca in fig.3.46, care contine si simbolul de reprezentare a celulei. Sa consideram, in continuare, aceeasi doi operanzi, X si Y, dati de (3.24), cu mentiunea ca, de data aceasta, bitii msb x3 si y3 reprezinta semnele celor doua numere. Acestui caz ii corespunde o structura matriceala combinationala cu aranjamentul trapezoidal de MCB-uri din fig.3.47. In etajul superior al structurii se remarca, mai intai cele patru MCB-uri la care se aplica cei patru biti ai multiplicand-ului Y. Pana la dimensiunea produsului final, avem o extensie a semnalului, in sensul ca la restul de 3 MCB-uri din aceleasi etaj superior se aplica, in mod repetat, semnul y3. Aceasta pentru ca, la inmultirea a doi operanzi reprezentati in C2, fiecare produs partial operat este un numar cu semn, care se impune extins pana la dimensiunea produsului final.
|
|
|
Fig.3.46 |
|
|
|
Fig.3.47 |
Acest lucru
se realizeaza si in etajele urmatoare, astfel incat structurile
in forma de romb din fig 3.41 si din fig.3.43, devin, in cazul
analizat (fig.3.47), de forma trapezoidala. Pe de alta parte,
pentru MCB-urile cele mai din dreapta din fiecare etaj, avem ![]() si liniile de control ai si bi - care sunt specifice unui anumit etaj
(rand) i, unde
si liniile de control ai si bi - care sunt specifice unui anumit etaj
(rand) i, unde ![]() , a caror functii booleene sunt realizate, pentru
fiecare etaj, de catre o schema logica combinationala
(combinational logic, CLi). La intrarile acestora se
aplica bitii multiplier-ului X, configurand, dependent de structura
binara a acestuia (prin intermediul variabilelor ai si bi), functiile w si cout
realizate de MCB-urile dintr-un anumit etaj.
, a caror functii booleene sunt realizate, pentru
fiecare etaj, de catre o schema logica combinationala
(combinational logic, CLi). La intrarile acestora se
aplica bitii multiplier-ului X, configurand, dependent de structura
binara a acestuia (prin intermediul variabilelor ai si bi), functiile w si cout
realizate de MCB-urile dintr-un anumit etaj.
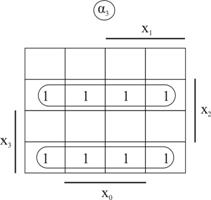
Sa ne propuneam ca, in cele ce urmeaza, sa disecam
sinteza schemelor CLi pentru cazul particular al exemplului adoptat.
In acest sens, vom elabora, pentru fiecare din recodificarile Booth, cate
un tabel de adevar, prezentat in fig. 3.48, respectiv fig. 3.49. Completarea
tabelelor incepe cu obtinerea, din setul variabilelor de intrare (input
variables) a formelor recodificate Booth aplicand cunoscutele reguli (vezi
exemplele din fig.3.13, respectiv fig.3.20). Apoi, pentru fiecare
variabila xiB, respectiv xiMB, se completeaza
corespunzatoarele coloane ai' si bi', unde ![]() . Regulile sunt aceleasi pentru ambele tabele, astfel
ca, referindu-ne doar la cel din fig.3.48, avem:
. Regulile sunt aceleasi pentru ambele tabele, astfel
ca, referindu-ne doar la cel din fig.3.48, avem:
Daca xiB = 0, atunci ai bi
Daca xiB = 1, atunci ai =1 si bi
Daca xiB = ![]() , atunci ai =1 si bi
, atunci ai =1 si bi
Aceste reguli concorda intocmai cu cele specificate in fig.3.45.
In urma completarii coloanelor variabilelor liniilor de control (control lines variables), se poate trece la elaborarea, individuala, pentru fiecare variabila a ecuatiei booleene care sa stea la baza sintezei corespondentei schemei CLi. Uzitand de diagrama Veitch-Karnaugh, urmarim obtinerea expresiilor logice minimizate pentru
fiecare variabila de control. Astfel, in fig.3.50 se prezinta diagrama Veitch-Karnaugh pentru a si modul de acoperire a unitatilor binare. Din fig.3.50 rezulta urmatoarea expresie booleana pe seama careia se sintetizeaza, in parte, CL3:
|
|
Procedand in mod similar si pentru restul variabilelor de control, obtinem:
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Fig.3.48 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Fig.3.49 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
Fig.3.50 |
Facem o remarca, secundara, legata de ultimele doua ecuatii din (3.31) in care intervine elementul neutru 0 pe motiv de modularitate a realizarii (toate variabilele ai sunt sintetizate in mod identic, doar cu alte variabile de intrare, si pentru variabilele bi este valabila aceeasi observatie) ceea ce favorizeaza tehnologia de implementare.
Pe de alta parte, in ceea ce priveste modificarea Booth recording, adoptand aceiasi modalitate de lucru, obtinem pentru variabilele de control:
|
|
Concluzionand, prin comparatie, rezulta o sinteza mai omogena cea data de (3.30) si (3.31) in raport cu cea data de (3.32), dar, apreciem, ca diferenta nu este spectaculoasa.
In final, ca si in cazul altor dispozitive de inmultire, o
sa ne referim la performanta si costul unei structuri de tipul
celei din fig.3.47. In primul rand, subliniem ca, aidoma
inmultitorului din fig.3.43, noua structura matriceala
combinationala este regulata, cablajul de interconectare dintre
MCB-uri este ordonat, ceea ce duce la un layout fara probleme majore,
favorabil integrarii VLSI. Pe de alta parte, in ceea ce priveste
factorul timp, calea cea mai lunga pe care trebuie sa o parcurga
semnalele este cea data de inlantuirea MCB-urile hasurate
cu CL0 (fig.3.47). Daca acceptam, din nou, aceiasi
intarziere d' pe o poarta logica, indiferent de tipul acesteia (ceea
ce reprezinta o aproximatie destul de fortata
cunoscuta fiind, spre exemplu, lentoarea portilor EX-OR in raport cu
celelalte [Yarb97]), atunci pe un MCB avem delay-ul ![]() (cel mai defavorabil,
vezi fig.3.46). Cu aceasta precizare, pentru intreaga structura din fig.3.47,
rezulta
(cel mai defavorabil,
vezi fig.3.46). Cu aceasta precizare, pentru intreaga structura din fig.3.47,
rezulta ![]() , considerand ca CL0 este realizat cu un
singur nivel de logica, conform (3.31) sau (3.32). Daca, insa
,admitem ca, la limita, delay-ul pe CL0 este acelasi
ca pe un MCB, atunci in termeni de d, pentru cazul general, avem
, considerand ca CL0 este realizat cu un
singur nivel de logica, conform (3.31) sau (3.32). Daca, insa
,admitem ca, la limita, delay-ul pe CL0 este acelasi
ca pe un MCB, atunci in termeni de d, pentru cazul general, avem ![]() , sau o complexitate de timp de
, sau o complexitate de timp de ![]() .
.
Ramanand in sfera multiplier-elor pentru numere intregi cu semn, reprezentate in C2 si implementabile cu structuri matriceale combinationale, sa prezentam, de aceasta data, la nivel de principiu metoda Baugh-Wooley, favorabila realizari practice in anumite circumstante [Parh00]. Pentru a ajunge la aceasta metoda, sa reconsideram operanzii dati de (3.24), la care x3 si y3 sunt biti de semn, si sa uzitam de (3.5) pentru a interpreta numerele negative. In aceste conditii, produsul dat de (3.26), devine:
|
|
Uzitand de (3.33),
anumiti termeni ponderati rezulta negativi, iar metoda
Baugh-Wooley urmareste evitarea acestora. In acest sens, produsele de
un bit negative din (3.33) sunt supuse unor transformari simple, cum este
cea intreprinsa, in calitate de exemplu, pentru ![]() :
:
|
|
Aplicand transformari de tipul celei din (3.34) tuturor termenilor negativi din (3.33), se obtine forma:
|
|
In paranteza cu ponderea 23 efectuam artificiul de adunare si scadere a valorii
![]() , astfel incat:
, astfel incat:
|
|
Insumarea primilor 6 termeni din (3.36) da o valoare
negativa, iar, datorita inmultirii cu 2, valoarea ![]() este "impinsa"
inspre paranteza ponderata cu 24, care devine:
este "impinsa"
inspre paranteza ponderata cu 24, care devine:
|
|
Analizand (3.37), se poate observa,
asemanator cu (3.36), ca primii termeni insumati dau o
valoare negativa, iar valoarea ![]() este "impinsa"
inspre paranteza ponderata cu 25, de unde ajunge la ultimul
termen, ponderat cu 26, asupra caruia se efectueaza
urmatoarea transformare:
este "impinsa"
inspre paranteza ponderata cu 25, de unde ajunge la ultimul
termen, ponderat cu 26, asupra caruia se efectueaza
urmatoarea transformare:
|
|
Valoarea (-2) din (3.38) poate fi substituita prin (-1) in pozitia cu ponderea 27, care valoare poate, la randul ei, inlocuita cu 1 si un imprumut din urmatorul rang, care este inexistent. In aceste conditii, se ajunge de la (3.35) la forma de produs Baugh-Wooley, data de expresia:
|
|
Ca si in cazul procedurilor Booth, pe langa procedura Baugh-Wooley originala, exista, si una modificata (modified Baugh-Wooley). Acesta se bazeaza pe o noua forma a produsului P, operand unele transformari asupra formei (3.39). Astfel referindu-ne din nou la paranteza prevazuta cu ponderea 23 din (3.39), o supunem urmatoarelor transformari evidente:
|
|
Primii patru termeni din (3.40)
insumati duc la o valoare negativa, iar ![]() este "impinsa"
inspre paranteza avand ponderea 24. Procedand pentru aceasta in mod asemanator,
obtinem:
este "impinsa"
inspre paranteza avand ponderea 24. Procedand pentru aceasta in mod asemanator,
obtinem:
|
|
Analizand (3.41), se poate trimite ![]() inspre paranteza cu ponderea 25, care prin tratare
asemanatoare devine
inspre paranteza cu ponderea 25, care prin tratare
asemanatoare devine ![]() si se "impinge"
inspre paranteza cu ponderea 26 aceeasi valoare
si se "impinge"
inspre paranteza cu ponderea 26 aceeasi valoare ![]() . Operand la nivelul acestei paranteze, rezulta:
. Operand la nivelul acestei paranteze, rezulta:
|
|
Sintetizand aceste transformari, de la (3.39) se ajunge la forma de produs modified Baugh-Wooley, data de expresia:
|
|
Se poate remarca faptul ca paranteza cu cei mai multi termeni, cea avand ponderea 23, are la forma (3.43) cu un termen mai putin decat la forma (3.39), ceea ce permite un castig de performanta. Cele doua forme de produs Baugh-Wooley stau la baza sintezei de structuri matriceale combinationale dupa modelul parcurs la solutiile din fig. 3.40 si fig. 3.41, respectiv din fig. 3.43. Prin prisma implementarii, procedurile Baugh-Wooley permit realizarea de proiecte mai simple de astfel de structuri decat cele care uziteaza de termeni ponderati negativi, asa cum sunt acestia prezentati in relatia (3.33). De asemenea, formele Baugh-Wooley pot fi folosite si la sinteza de dispozitive de inmultire paralele realizate nu cu celule FAC inlantuite in maniera RCA, asa cum am vazut, ci cu arbori de CSA-uri, asa cum vor fi prezentati in urmatorul paragraf.
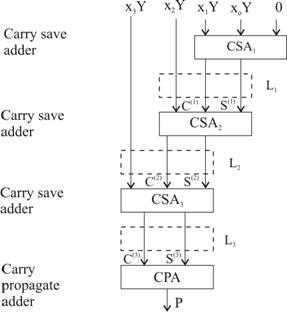
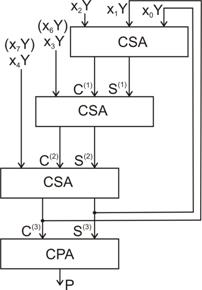
Dar, sa mai facem o remarca relativ la structurile matriceale combinationale studiate, sens in care, fara a pierde din generalitate, ne vom referi la o structura de tipul celei din fig. 3.41. Mai exact pentru acelasi exemplu al numerelor din (3.24) proiectul din fig. 3.41, poate fi reprezentat, la nivel de diagrama bloc, ca o inlantuire de sumatoare CSA, asa cum poate fi observat in fig. 3.51. Cu mentiunea ca cele trei perechi de vectori binari (C(i), S(i), unde i=1, 2, 3) sunt aplicati din etaj in etaj in maniera prezentata in fig. 3.41, sa mai specificam ca in ultimul nivel, la a carui iesire se prezinta produsul P, este constituit dintr-un sumator cu propagarea transportului (carry propagate adder). Chiar daca prin prisma latentei procesului de inmultire, solutiile din fig. 3.51 si fig. 3.36
|
|
|
Fig.3.51 |
(cea cu un singur sumator CSA) nu difera in mod esential, fiind executat, in principiu, acelasi numar de adunari, varianta cu mai multe sumatoare CSA prezinta avantajul ca operatia poate fi pipeline-izata, permitand cresterea capacitatii de trecere (throughput) si facand-o astfel favorabila aplicarii in procesoare matriceale (array processors) [HuEr05]. Astfel, intre straturile de CSA-uri, se intercaleaza straturi de latch-uri Li, unde i=1, 2, 3. Odata stocati vectorii C(i) si S(i) in nivelul de latch-uri corespunzator, Li, vectorii de la intrarile CSAi se pot modifica. In acest fel, se pot executa in maniera suprapusa mai multe operatii aflate in faze deferite ale efectuarii lor. Aidoma suprapunerii in executie a instructiilor [HePa03], constituind un control pipeline-izat, tot asa si operatiile aritmetice, in particular inmultirea, pot fi executate de catre un pipeline aritmetic [Poll90]. In urma umplerii acestuia, adancimea pipeline-ului da numarul de operatii care sunt in executie concomitenta la un anumit moment dat. Accelerarea provine, in acest caz, datorita faptului ca, in acelasi interval de timp, se executa un numar mai mare de, in cazul nostru, inmultiri.
Indiscutabil, un proiect de tipul celui din fig.3.51 revendica, in
general, o consistenta arie de integrare. Cand aceasta din urma
constituie un factor critic, o solutie o poate reprezenta
inlantuirea de sumatoare CSA care permite doua treceri si
este expusa, schematic in fig. 3.52. Sa presupunem ca, spre
deosebire de structura din fig.3.51, care permite inmultirea unor numere pe
patru biti, de aceasta data dimensiunea operanzilor este de opt
biti. La prima trecere prin lantul de CSA-uri sunt adunate, in
maniera CSA, cinci produse de un bit ale lui Y(![]() la
la ![]() ), interval de timp dupa care vectorii binari C(3)
si S(3) sunt aplicati in locul anteriorilor
), interval de timp dupa care vectorii binari C(3)
si S(3) sunt aplicati in locul anteriorilor ![]() si
si ![]() si sunt adunate
restul de trei produse de un bit (
si sunt adunate
restul de trei produse de un bit (![]() la
la ![]() ), iar, in final, noii vectori C(3) si S(3)
sunt adunati, cu propagarea transportului, de catre CPA. Aceasta
solutie tehnica, deosebit de favorabila prin prisma ariei de substrat
de siliciu, intampina unele dificultati.
), iar, in final, noii vectori C(3) si S(3)
sunt adunati, cu propagarea transportului, de catre CPA. Aceasta
solutie tehnica, deosebit de favorabila prin prisma ariei de substrat
de siliciu, intampina unele dificultati.
|
|
|
Fig.3.52 |
Astfel, intervalul de timp necesar propagarii semnalelor prin structura matriceala formata de CSA-uri trebuie monitorizat in mod strict pentru a permite substituirea produselor de un bit, pentru a doua trecere, la momentul oportun. Apoi, remarcam faptul ca in ceea ce priveste dimensiunea CSA-urilor, aceasta este mai mare decat a celor dintr-o structura de tipul celei din fig. 3.51 (ne-am referit la inmultirea de numere fara semn). Dar cel mai mare dezavantaj al solutiei din fig. 3.52 este ca ea nu permite ca operatia sa fie executata pipeline-izat.
Ca o remarca finala pentru structurile matriceale combinationale constituite din inlantuiri de sumatoare CSA in, uneori, asa numitii arbori "one-sided CSA trees" [Parh00], este ca ele conduc la solutii, in general, mai lente, dar de o mai mare regularitate, implicit cu o arie de chip mai redusa, in raport cu structurile arborescente veritabile pe care le prezentam in cele ce urmeaza. Totusi, uneori balanta alegerii poate fi inclinata pentru structurile matriceale datorita capacitatii de trecere mare a operatiilor, atunci cand acestea se executa pipeline-izat.
|
Politica de confidentialitate |
| Copyright ©
2025 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |