PROCESE
Notiuni generale
Un proces (sau task) este o instanta a unui program in executie. Este cea mai mica portiune de program (piece of work) ce poate fi controlata de sistemul de operare. Fiecare sistem de operare de tip multiprogramare pastreaza informatii despre (keeps tracik) toate procesele active si le aloca resursele sistem conform politicii de alocare aleasa pentru asigurarea performantei.
Intentia de a activa un program executabil este anuntata sistemului de operare printr-o comanda speciala de lansare a in executie, de genul RUN, sau printr-un apel sistem (fork). Sistemul de operare raspunde prin crearea unui proces. In general, aceasta activitate consta in crearea si initializarea structurilor de date pentru urmarirea si controlul executiei procesului in cauza.
Odata creat, procesul devine activ si concureaza pentru alocarea resurselor sistemului, cum ar fi procesorul si dispozitivele I/O. O comportare tipica a unui proces consta din ciclii de UCP ce alterneaza cu ciclii de I/O. In timp ce procesul curent executa o operatie de I/O, procesorul poate fi alocat unui alt proces gata de executie.
Obs.: Daca doi utilizatori lanseaza acelasi program in executie (de ex. un editor de texte), se vor crea doua procese, cate unul pentru fiecare utilizator.
In afara de spatiul de date si de cod, un proces mai poseda si o serie de atribute, necesare sistemului de operare pentru gestiune. Aceste atribute sunt starea curenta, prioritatea, drepturile de acces si alte informatii.
Exista doua relatii fundamentale intre procese :
- de competitie - procesele concureaza pentru alocarea resurselor sistemului;
- de cooperare - este valabila pentru un grup de procese care schimba intre ele date si semnale de sincronizare pentru progresul colectiv.
Ambele trebuie sa poata fi suportate de catre sistemul de operare. Astfel, in primul caz, trebuie tratate cu grija alocarea resurselor si protectia spatiilor de adrese specifice proceselor, iar in al doilea caz, trebuie sa existe mecanisme pentru controlul utilizarii datelor partajate si schimbarea semnalelor de sincronizare.
Procesele care coopereaza sunt grupate intr-o familie (grup) de procese. Cea mai frecventa relatie intre procesele unei familii este relatia tata-fiu. Procesele fiu, de obicei, mostenesc atributele de la parinti. Aceste atribute pot fi schimbate in timpul executiei, cu ajutorul apelurilor sistem corespunzatoare. In mod normal, procesul parinte se termina doar dupa ce toti fiii sai s-au terminat.
Ca exemplu, consideram un sistem simplificat de achizitii de date. Operatiile pe care trebuie sa le efectueze sunt : culegerea datelor de intrare de la un senzor extern (de ex., un convertor analog-numeric), scrierea lor pe disc pentru arhivare, operatii statistice care arata daca au avut loc schimbari semnificative fata de esantionarea anterioara si listarea acestor informatii statistice la imprimanta.
Cele patru activitati le vom intitula : COLLECT, WRITE, STAT si REPORT.
Cea mai simpla solutie ar fi sa scriem un program in care ele sa fie apelate secvential, in ordinea COLLECT, WRITE, STAT si REPORT.
Totusi, daca timpul de raspuns conteaza, o implementare multitasking poate produce o performanta mai buna. Aceasta deoarece UCP nu executa nimic in timpul conversiilor analog-numerice, in timpul lucrului cu discul si in timpul listarii. Solutia este de a realiza patru procese, cate unul pentru fiecare operatie, iar in timpul cat unul din procese este ocupat cu o operatie I/O, UCP poate executa un alt proces.
Din definitia problemei, rezulta ca mai intai citim datele si apoi le scriem pe disc si efectuam operatiile statistice. Operatia de scriere pe disc este operatie tipica I/O, in timp ce calculul statistic are nevoie de UCP. Deci, cele doua procese sunt candidati perfecti pentru executie concurenta : in timp ce WRITE executa operatia de scriere pe disc, UCP poate fi ocupat cu STAT, rezultand un castig de performanta. In ceea ce priveste REPORT, se poate executa doar dupa terminarea lui STAT, dar poate fi executat in paralel cu operatia urmatoare de colectare date.
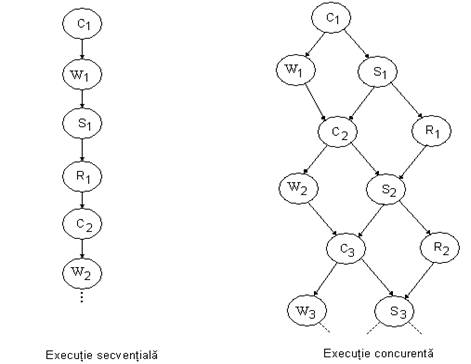
Grafuri de precedenta
(cu doua tampoane)
Cele patru procese, scrise in pseudocod :
program/module multiprocess_DAC;
process collect;
begin
while true do begin
wait_signal_from(write,stat);
p_collect;
send_signal_to(write,stat);
end;
end;
process write;
begin
while true do begin
wait_signal_from(collect);
p_write;
send_signal_to(collect);
end;
end;
process stat;
begin
while true do begin
wait_signal_from(collect,report);
p_stat;
send_signal_to(report,collect);
end;
end;
process report;
begin
while true do begin
wait_signal_from(stat);
p_report;
send_signal_to(stat);
end;
end;
begin
initialize_environment;
send_signal_to(collect,collect,stat);
initiate collect,write,stat,report
end
Noul concept introdus consta in trimiterea si receptia de semnale, folosite la sincronizarea proceselor, pentru respectarea relatiei de precedenta. Semnalele reprezinta unul dintre mecanismele de sincronizare interproces, fiind unul din cele mai importante servicii furnizate de sistemele de operare multitasking. Un proces care asteapta unul sau mai multe semnale este suspendat de catre sistemul de operare pana cand apar toate semnalele cerute. Un semnal apare in momentul in care este generat de catre un alt proces. Trimiterea semnalului nu suspenda procesul transmitator.
Sa presupunem ca exista doua tampoane (buffer-e) ce pot fi accesate de toate procesele : IB, tampon de intrare in care COLLECT depune datele, iar WRITE si STAT le citeste si OB, tampon de iesire in care STAT depune datele de iesire, iar REPORT le citeste.
Relatia de precedenta impune ca, de ex., WRITE sa astepte pana cand COLLECT scrie datele in IB, deci este suspendat pana cand soseste semnalul de la COLLECT. Fara aceasta sincronizare se poate intampla ca WRITE salveaza pe disc aceleasi date de cateva ori (daca este mai rapid decat COLLECT), sau pierde unul sau mai multe seturi de date (COLLECT este mai rapid), sau salveaza doar o parte (daca cele doua procese se suprapun), functie de momentele lansarii in executie ale celor doua procese. Cand WRITE a scris datele, trimite un semnal catre COLLECT anuntandu-l ca a terminat de salvat datele si deci COLLECT poate depune altele.
O situatie asemanatoare apare in cazul tamponului OB, negociat intre STAT si REPORT.
De asemenea, COLLECT nu poate scrie noul set de date in IB, decat dupa ce si STAT si WRITE au prelucrat vechiul set.
Ori de cate ori sistemul (de achizitionare date) porneste, COLLECT trebuie sa fie primul program care se lanseaza.
In programul principal, mai intai este initializat mediul de executie al proceselor. Apoi sunt trimise doua semnale catre COLLECT (simuland ca vin de la WRITE si STAT) si un semnal catre STAT (simuland ca vine de la REPORT) In final sunt initializate cele patru procese (initializare insemnand crearea si aducerea lor la cunostinta sistemului de operare).
Comportarea proceselor din exemplu. Fiecarui proces ii este asociata o prioritate, indicandu-i sistemului de operare importanta fiecaruia, prioritate pe baza careia se rezolva conflictele. Astfel, cand doua procese concureaza pentru obtinerea aceleiasi resurse, sistemul de operare o acorda celui cu prioritatea cea mai mare.
Asignarea de prioritati este o componenta importanta in realizarea unui compromis intre performanta si cerintele de timp de raspuns ale sistemului (tuning performance with time-critical requirements).
In ordinea descrescatoare a prioritatilor, avem : WRITE, COLLECT, REPORT, STAT.
WRITE are prioritatea cea mai mare pentru ca lucreaza cu discul si deci trebuie sa raspunda repede intreruperilor (pentru evitarea rotatiilor de disc pierdute). COLLECT are asociata urmatoarea prioritate intrucat si ea trateaza intreruperi (de la senzor) si, de altfel, ea este cea care furnizeaza datele de care depinde executia celorlaltor procese.REPORT are o prioritate mai mare decat STAT pentru ca astfel putem avea in acelasi timp si UCP si I/O ocupate. Astfel, in timp de REPORT asteapta intreruperea de la imprimanta, UCP poate executa STAT. UCP comuta imediat pe REPORT cand intreruperea apare (REPORT este mai prioritar decat STAT). Daca prioritatile ar fi fost inversate, REPORT n-ar fi reusit sa obtina controlul de la STAT (daca, in timp ce UCP executa STAT, intreruperea ar fi aparut, UCP n-ar fi comutat pe REPORT, datorita prioritatii mai mici). In cazul dat, cu REPORT mai prioritar decat STAT, ambele au ocazia sa fie in atentia procesorului.
Comportarea proceselor este reprezentata grafic mai jos. Dreptunghiurile arata ca procesele ocupa UCP, linia orizontala punctata reprezinta operatii I/O; sageata orientata in sus marcheaza aparitia unei intreruperi, iar cea orientata in jos, momentul cand procesul STAT, care nu este lansat de nici o intrerupere, este gata de executie.
Se presupune ca o operatie WRITE realizeaza doua accese la disc, iar o operatie REPORT consta din procesarea a doua intreruperi de la imprimanta.(Fig.bmp)
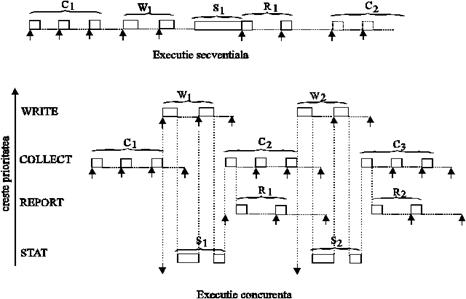
COLLECT este procesul ce ruleaza primul (lansat in programul principal). WRITE, STAT si REPORT sunt suspendate de sistemul de operare, asteptand aparitia semnalelor corespunzatoare. Cand COLLECT se termina, trimite cele doua semnale catre WRITE si STAT. Astfel, ambele procese sunt gata de executie. Dintre ele, sistemul de operare va alege procesul WRITE, avand prioritatea mai mare.
Cand faza de lucru cu UCP a primului acces la disc a procesului WRITE se termina si incepe faza de lucru I/O, sistemul de operare aloca UCP-ul procesului STAT. Cand faza de lucru I/O a primului acces la disc se incheie, incepe faza de lucru cu UCP a celui de al doilea acces la disc al operatiei WRITE. UCP este ocupat cu STAT dar, WRITE avand prioritate mai mare, sistemul de operare il va face pe acesta proces curent activ. Acest tip de planificare se numeste planificare bazata pe prioritati, de tip preemptiv (adica un proces in executie poate fi intrerupt de un alt proces cu prioritate mai mare). Cand si al doilea acces la disc se termina, procesul WRITE trimite un semnal procesului COLLECT. De asemenea, cand STAT se termina, va trimite si el un semnal la COLLECT. Dupa ce ambele semnale sunt receptionate, COLLECT este executat din nou, pentru citirea unui nou set de date si depunerea lui in IB. Cand COLLECT isi termina si cea de a doua rulare, trimite semnalele de sincronizare proceselor STAT si WRITE, astfel initializand cea de a doua lor rulare. De notat este faptul ca STAT trimite semnale catre COLLECT si REPORT, astfel ambele devenind candidate pentru executie dar, datorita prioritatii mai mari, COLLECT va castiga.
Gradul de concurenta poate creste prin folosirea a doua tampoane pentru intrare (IB1 si IB2), respectiv pentru iesire (OB1 si OB2), cum se poate vedea din figura : (fig2_3.bmp)
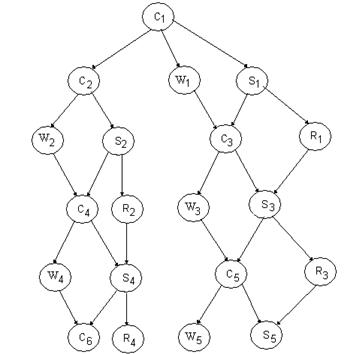
Grafuri de precedenta
(cu patru tampoane)
Totusi, performanta obtinuta nu este considerabil mai mare.
Dupa cum am mai spus, un proces este format din cod si date, fiind caracterizat de atribute si stare dinamica. Atributele asociate unui proces pot fi asignate de catre programator sau de catre sistemul de operare si includ prioritatea si drepturile de acces.
Prezentam mai jos diagrama de tranzitie a starilor proceselor: (fig2_4.bmp)
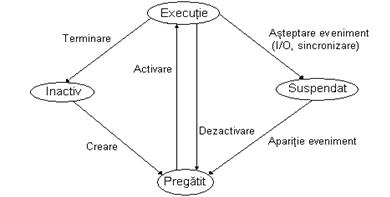
In starea inactiv sunt programele ce asteapta sa fie lansate in executie; ele vor genera procese despre care sistemul de operare nu stie inca nimic.
Un proces este in starea pregatit (gata de executie) cand are alocate toate resursele de care are nevoie, cu execeptia UCP-ului. De obicei, in aceasta stare ajung procesele imediat dupa creare. Toate procesele in starea pregatit asteapta ca sistemul de operare sa le aloce UCP-ul. Un modul al sistemului de operare, numit planificator, alege unul din aceste procese ori de cate ori UCP-ul devine liber pentru a rula un nou proces.
Un proces in starea de executie are alocate toate resursele necesare rularii, inclusiv UCP. In cazul unui sistem cu un sigur microprocesor, vom avea un singur proces activ la un moment dat in sistem. Procesul curent activ executa secventa sa de instructiuni masina, putand cere sistemului de operare servicii ca I/O sau sincronizare printr-un semnal. Depinde de politica de planificare daca sistemul returneaza controlul acestui proces dupa terminarea serviciului sau alege un altul (din procesele in starea pregatit) pentru executie.
Un proces ajunge in starea suspendat cand are nevoie de o resursa pe care sistemul de operare nu i-o poate inca aloca. Astfel de procese ies afara din competitia pentru UCP pana cand conditia de suspendare dispare. Un proces in executie poate ajunge in starea suspendat cand invoca o rutina I/O sau asteapta un semnal care nu s-a produs inca. Sistemul de operare inregistreaza motivul suspendarii pentru a putea relua procesul mai tarziu, cand conditia de suspendare dispare datorita actiunii altor procese sau aparitiei unui eveniment extern. Dupa aparitia evenimentului, se poate intampla ca UCP sa nu execute acest proces, intrucat in sistem exista un altul cu prioritate mai mare.
La un moment dat, procesele din sistem se pot afla in diverse stari, totalitatea acestora definind starea globala a sistemului . Ca raspuns la actiunile interne sau externe, procesele isi pot schimba repede starea rezultand a noua stare globala a sistemului.
Sistemul de operare grupeaza toate informatiile de care are nevoie pentru un proces intr-o structura de date numita blocul de control al procesului (PCB). Ori de cate ori un proces este creat, sistemul de operare ii contruieste PCB-ul asociat. Cand procesul se termina, PCB-ul este sters din memorie. In starea inactiv, procesele nu au asociat PCB si astfel sistemul de operare nu stie nimic despre existenta lor. PCB-ul contine atributele statice si dinamice ale proceselor :
identificatorul de proces;
prioritatea;
starea (pregatit, in executie, suspendat);
alte campuri : o lista a resurselor cerute si alocate (cererea de spatiu de memorie, max.spatiului de date si/ori dimensiunea stivei) , registri, flaguri de stare etc.
Campurile PCB-ului fie sunt completate cu datele specificate de programator la apelul sistem pentru crearea procesului, fie cu valorile implicite.
Pentru gestiunea proceselor, sistemul de operare creeaza o lista a proceselor in starea pregatit, ce contine PCB-urile proceselor aflate in aceasta stare si o lista a proceselor suspendate, cu PCB-urile proceselor suspendate. O lista a proceselor in executie nu are sens, intrucat un singur proces poate fi in aceasta stare.
Ori de cate ori un proces isi schimba starea, sistemul de operare actualizeaza corespunzator cele doua liste (daca este cazul). Datorita operatiilor frecvente de inserare si stergere, aceste liste sunt implementate, aproape intotdeauna, prin liste de legatura, uneori cu mai multi pointeri. (liste dublu inlantuite ??)Pentru a facilita planificarea, lista proceselor pregatite se tine sortata dupa prioritate (in ordine descrescatoare). Lista proceselor suspendate se gestioneaza in maniera FIFO.
La inceput, dupa trimiterea semnalelor catre COLLECT si STAT (din programul principal), listele vor arata in felul urmator :(figg1.bmp)
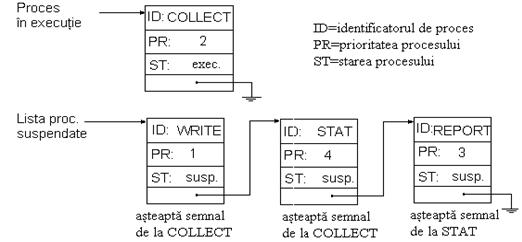
Dupa prima rulare a lui COLLECT : (fig2_5.bmp)
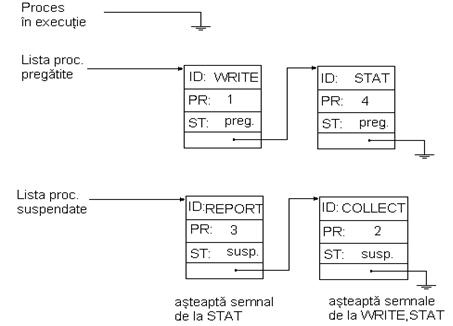
Datorita prioritatii mai mari, este ales procesul WRITE pentru executie. (fig2_7.bmp)
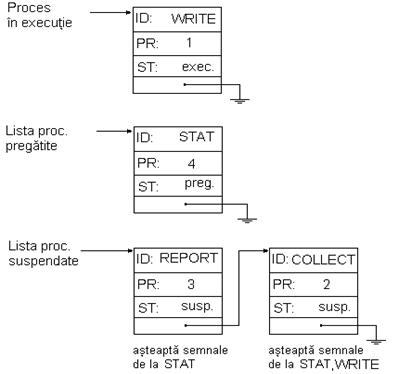
Dupa ce WRITE a terminat faza de lucru cu UCP a primului acces la disc si asteapta sa soseasca intreruperea de la disc, procesul WRITE este trecut in lista proceselor suspendate, iar STAT este ales pentru executie(fig2_6.bmp)
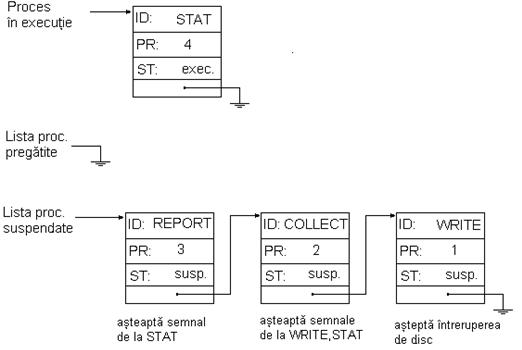
Cand apare intreruperea de terminare a operatiei cu discul, WRITE este trecut in lista pregatit, apoi este invocat planificatorul care alege ca proces curent WRITE, avand prioritatea mai mare ca STAT, si il sterge din lista pregatit, trecand in aceasta lista PCB-ul procesului STAT. (Fig2_7.bmp)
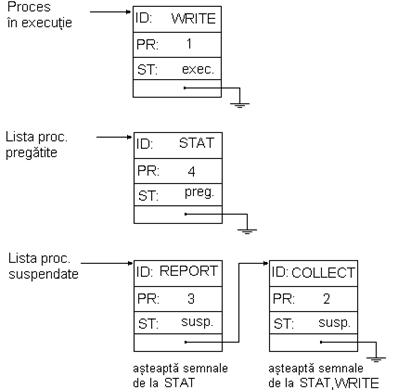
Acest exemplu ilustreaza esenta mecanismului folosit de sistemele de operare multitasking pentru a detecta, inregistra si gestiona toate schimbarile starii sistemului. De cate ori are loc o tranzitie, sistemul de operare intervine si actualizeaza listele, alegand eventual un nou proces pentru executie. Pe baza PCB-ului acestuia se creeaza mediul de executie (running environment) al noului proces curent activ. Aceasta operatie se numeste comutare de procese (task-uri). Ce este comutarea de context ??
Implementarea proceselor in UNIX
Fiecare proces are atat o faza utilizator (lucreaza in mod utilizator), cat si o faza sistem (lucreaza in mod sistem). Instructiunile obisnuite sunt executate in mod utilizator, iar apelurile sistem in mod sistem. Corespunzator, procesului ii sunt asociate doua stive.
Comutarea intre modul utilizator si sistem se realizeaza in cazurile :
- generare exceptie;
- apelurile sistem prin care utilizatorul solicita diverse servicii oferite de sistemul de operare; cele care realizeaza operatii de intrare/iesire conduc la suspendarea procesului apelator pe durata transmiterii datelor;
- cereri de serviciu ale perifericelor de intrare/iesire, care determina comutarea intre cele doua moduri de lucru.
Structurile de date folosite de nucleu pentru gestiunea proceselor sunt :
structura de proces (cate una pentru fiecare proces) ce contine :
- parametrii pentru planificare : prioritatea, timpul de UCP consumat recent, timpul cat a stat in starea suspendat ultima oara; toate acestea sunt folosite pentru a stabili care proces se selecteaza pentru rulare;
- imaginea in memorie : pointeri catre tabela de pagini asociata procesului, in cazul in care procesul este rezident in memoria principala sau adresa pe dispozitivul de swap (disc);
- semnale : mastile care arata ce semnale sunt ignorate, care sunt tratate, care sunt temporar blocate (mascate) si care sunt tratate acum de catre proces (in momentul tratarii unui semnal de catre un proces, orice semnal de acelasi tip care soseste va fi ignorat);
- alte informatii : identificatorul de proces, identificatorii de utilizator si grup efectivi, identificatorul procesului parinte, starea curenta a procesului, evenimentul pe care il asteapta.
structura de cod (text) , numai in cazul proceselor cu cod partajat, ce contine :
- modul in care procesele utilizeaza segmentul de cod;
- pozitia unde poate fi gasit segmentul de cod, etc.
structura utilizator (cate una pentru fiecare proces) ce contine :
- o copie a registrilor generali, a indicatorului de stiva (SP), a numaratorului de instructiuni (PC) care este scrisa in momentul comutarii din modul utilizator in modul nucleu;
- pointer spre structura de proces;
- parametrii si rezultatele aferente apelurilor sistem;
- toti identificatorii de grup sau de utilizator asociati procesului;
- structuri de date pentru semnale si alarme;
- pointer catre inodul directorului curent;
-informatii privind tabela de fisiere deschise;
- (?? probabil un pointer spre) o stiva fixa folosita de catre nucleu in spatiul utilizator.
Aceste structuri sunt memorate in spatiul nucleu. In cazul swapping-ului, se salveaza:
- zona de date si instructiuni ale procesului (daca segmentul de cod este partajat, nu se elibereaza zona de memorie ocupata);
- continutul stivei;
- structura utilizator, dupa ce s-au memorat in ea continuturile registrilor generali.
Tabela de procese active contine structurile de proces ale proceselor active, indiferent daca ele sunt in memorie sau pe disc (in urma procesului de swapping).
Cu ajutorul apelului sistem fork() se creeaza un nou proces astfel : se cauta o intrare libera in tabela de procese. Daca este gasita, se aloca o noua structura de proces (cu un nou identificator de proces) pentru procesul fiu si se copiaza toate informatiile din intrarea din tabela corespunzatoare procesului parinte in cea corespunzatoare procesului fiu. Apoi, se aloca memorie pentru segmentele de date si stiva (cele 2 stive??) ale procesului fiu, copiindu-se continutul celor corespunzatoare procesului parinte. In mod obisnuit nu este necesar un nou segment de cod, deoarece se partajeaza codul existent. Va fi construita in schimb o noua tabela de pagini. In structura utilizator a procesului fiu se copiaza datele din structura utilizator a procesului parinte. Astfel, vor fi pastrate valorile descriptorilor fisierelor deschise, ale identificatorilor de utilizator sau grup si ale semnalelor. (Fig2_10.bmp =Fig. Boian/139)
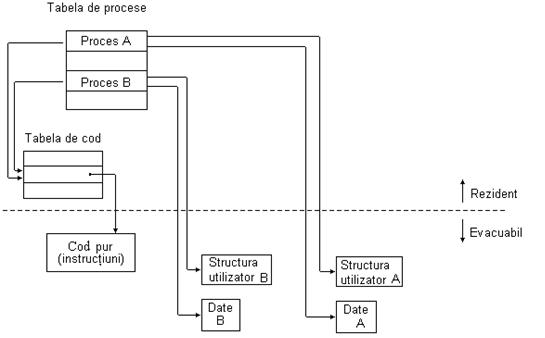
Planificarea proceselor
Cand doua sau mai multe procese sunt in starea pregatit si deci candideaza pentru executie, sistemul de operare trebuie sa decida caruia ii aloca UCP-ul. Acea parte din sistemul de operare care se ocupa cu luarea acestei decizii se numeste planificator , iar algoritmul folosit, algoritm de planificare.
In cazul sistemelor de prelucrare in loturi (batch systems), algoritmul era foarte simplu : se executa urmatoarea lucrare de pe banda. In cazul sistemelor multiutilizator time-sharing, algoritmul este mult mai complex.
Criteriile ce se iau in considerare la definirea performantei unui algoritm de planificare pot fi :
utilizarea UCP-ului;
timp de prelucrare;
timpul de asteptare;
timpul de raspuns.
Utilizarea UCP-ului reprezinta fractiunea din timp cat UCP este ocupat. Uneori se ia in considerare timpul alocat atat pentru programele utilizator cat si pentru cele sistem, alteori numai pentru programele utilizator ("useful work"). Scopul este de a tine UCP-ul cat mai mult timp ocupat, crescand astfel performanta sistemului.
Timpul de prelucrare poate fi definit ca timpul care se scurge intre momentul cand programul este lansat in executie si momentul terminarii lui.
Timpul de asteptare este timpul cat un program, pe durata executiei sale, asteapta alocarea resurselor necesare. Poate fi exprimat ca diferenta dintre timpul de prelucrare si timpul efectiv de excutie.
Timpul de raspuns este utilizat cel mai frecvent de catre sistemele de operare de timp real sau cu time-sharing. Definitiile difera pentru cele doua tipuri de sisteme. Astfel, la sistemele cu time-sharing poate fi definit, de ex., ca timpul care se scurge din momentul scrierii ultimului caracter al liniei de comanda pana cand primul rezultat apare la terminal (se mai numeste timp de raspuns la un teminal). La sistemele in timp real, poate fi definit ca timpul dintre momentul in care apare un eveniment si momentul cand este executata prima instructiune a rutinei de tratare (se mai numeste timp de raspuns la un eveniment) .
Planificatoarele cauta sa maximizeze performanta medie relativ la un anumit criteriu. Una dintre problemele intalnite la proiectarea planificatorului este aceea ca unele criterii sunt in contradictie cu altele. De exemplu,un timp de raspuns cat mai bun poate duce la scaderea utilizarii UCP-ului. Marind utilizarea UCP-ului si viteza de prelucrare, timpul de raspuns poate avea de suferit. De aceea, proiectantii incearca sa maximizeze performantele relativ la criteriul cel mai important pentru mediul de lucru (planificatoarele sunt dependente de mediu). De exemplu, pentru sistemele cu prelucrare in loturi, ma intereseaza utilizarea UCP-ului; la sistemele multiutilizator, timpul de raspuns; la sistemele in timp real, sa raspunda corespunzator multitudinii de evenimente externe.
Algoritmii de planificare pot fi preemptivi sau non-preemptivi.
In cazul non-preemptiv, controlul este cedat sistemului de operare in momentul in care in procesul curent activ apare o instructiune de acest gen sau daca procesul asteapta terminarea unei operatii I/O. Deci procesul curent activ nu poate fi inlocuit cu un alt proces aflat in starea pregatit avand prioritate mai mare.
In cazul preemptiv, procesul aflat in executie poate fi inlocuit oricand cu un alt proces cu prioritate mai mare. Acest lucru este realizat prin activarea planificatorului ori de cate ori este detectat un eveniment ce schimba starea globala a sistemului.
Indiferent daca algoritmul este preemptiv sau nu, comutarea de procese presupune salvarea starii procesului fost in executie, precum si a crearea mediului de executie a noului proces ales a fi executat, ceea ce necesita mult timp. In general, sistemele de tip preemptiv pot furniza un timp de raspuns mai bun, dar consuma mult timp cu executia planificatorului si comutarea proceselor asociate.
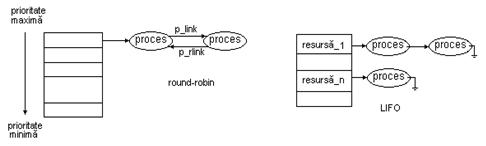
Mecanismul de planificare round-robin
In cazul sistemelor cu time-sharing, prima cerinta este sa furnizeze un timp de raspuns rezonabil si, in general, sa partajeze echitabil resursele sistemului intre toti utilizatorii. Evident, numai disciplinele de planificare preemptive pot fi luate in considerare in astfel de situatii, una dintre cele mai populare fiind round-robin.
Timpul UCP-ului este impartit in cuante, de obicei intre 10 si 100 msec., care se aloca proceselor. Nici un proces nu poate rula mai mult de o cuanta, atat timp cat mai sunt procese in sistem ce asteapta sa fie executate. Structura de date folosita este o coada a proceselor gata de executie (aflate in starea pregatit). Cand cuanta s-a terminat, UCP-ul este alocat unui alt proces (primul din coada). Acelasi lucru se intampla si in cazul cand procesul s-a blocat sau si-a terminat activitatea inaintea expirarii cuantei. Astfel, fiecare proces are alocat 1/N din timpul UCP-ului, unde N este numarul proceselor din sistem.
Round-robin asigura partajarea echitabila a resurselor sistemului intre procese. Procesele scurte se pot termina intr-o singura cuanta, obtinandu-se astfel un timp de raspuns bun. Procesele lungi au nevoie de mai multe cuante de timp, cicland in coada pana cand se termina.
Din punct de vedere hardware, se foloseste un timer care genereaza o intrerupere dupa trecerea unui interval de timp egal cu o cuanta. Cand soseste intreruperea, sistemul de operare lanseaza planificatorul pentru comutarea proceselor. Intervalul de timp este resetat inaintea executiei noului proces ales din coada.
Performanta acestui mecanism depinde foarte mult de valoarea cuantei. Astfel, o valoare mica avantajeaza procesele interactive, dar scade eficienta UCP-ului, acesta ocupandu-se mult timp cu tratarea intreruperii sosite de la timer si cu comutarea proceselor. O valoare mare creste eficienta UCP-ului, dar poate determina un timp de raspuns mic, dezavantajand procesele interactive (ex.: mai multi utilizatori apasa in acelasi timp pe o tasta). O cuanta de 100 msec. realizeaza un compromis bun.
Algoritmul de planificare round-robin se recomanda a se folosi in cazul sistemelor time-sharing multiutilizator, unde timpul de raspuns conteaza foarte mult.
Mecanismul de planificare bazat pe prioritati
(de tip preemptiv)
Algoritmul round-robin presupune ca toate procesele sunt la fel de importante, ceea ce nu este intotdeauna adevarat. Pentru departajarea proceselor in functie de importanta, se folosesc prioritati acordate fiecarui proces in parte, sistemul ruland intotdeauna procesul cu cea mai mare prioritate din sistem.
Pentru a preveni ca procesele cu cea mai mare prioritate sa ruleze tot timpul, planificatorul poate scade prioritatea procesului curent activ la fiecare intrerupere de ceas. Cand prioritatea procesului in executie a devenit mai mica decat prioritatea unui alt proces, sistemul de operare comuta intre ele.
Prioritatile pot fi asignate static sau dinamic. Static, se acorda de catre utilizator sau de catre sistem, la creare. Dinamic, se asigneaza de catre sistemul de operare, pentru realizarea unui anumit scop. De exemplu, unele procese lucreaza foarte mult cu sistemul I/O. Ori de cate ori un astfel de proces cere UCP, ar trebui sa i se acorde imediat, pentru a lansa urmatoarea cerere I/O, care astfel se va executa in paralel cu executia unui alt proces de catre UCP (altfel ocupa memoria prea mult timp). Un algoritm simplu pentru a oferi un serviciu bun proceselor orientate spre I/O este de a seta prioritatea la 1/f, unde f reprezinta fractiunea de timp ocupat cu UCP din ultima cuanta.
Se recomanda in sisteme de timp real si alte sisteme care presupun raspuns intr-un interval de timp (time-critical requirements).
Mecanismul de planificare utilizand cozi multiple
Algoritmii descrisi mai sus caracterizeaza aplicatii particulare, fiind in general ineficienti in alte situatii. Consideram, de ex., un sistem in care avem evenimente ce cer tratare intr-un anumit interval de timp (time-critical events), o multitudine de utilizatori interactivi si unele programe lungi si neinteractive se recomanda combinarea acestor algoritmi de planificare. Rezulta astfel planificarea cu cozi multiple, in care fiecare coada corespunde unui algoritm de planificare. Pentru exemplul de mai sus vom obtine trei cozi, ca in figura : (fig2_8.bmp)
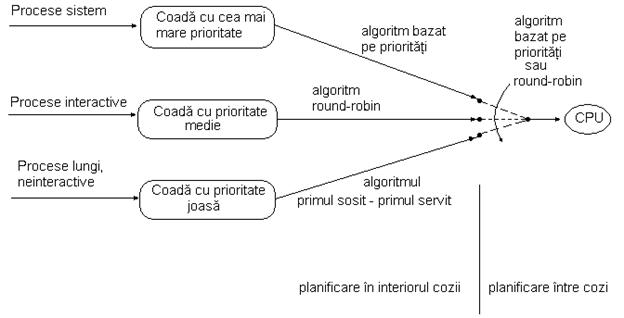
Cozile pot fi gestionate prin round-robin sau bazat pe prioritati.
In cazul gestionarii bazate pe prioritati, sunt servite mai intai procesele din coada cu prioritatea cea mai mare, folosind algoritmul de planificare corespunzator cozii respective. Cand aceasta devine vida, se trece la urmatoarea coada ca nivel de prioritate. Un proces in executie poate fi intrerupt de un alt proces ce soseste intr-o coada cu prioritate mai mare.
O varianta a acestui algoritm este algoritmul cu cozi multiple si reactie negativa (multiple-level queues with feedback). Un proces poate trece dintr-o coada in alta (schimbandu-i-se astfel prioritatea), pe baza comportarii in timpul executiei din cuanta anterioara. De exemplu, fiecare proces incepe cu prioritate maxima (este trecut automat in coada cu prioritate maxima). Procesele ce au nevoie de mai mult de o cuanta pentru terminare, sunt mutate intr-o coada de nivel mai mic. Daca procesul nu a terminat inca, dupa cateva rulari in aceasta coada, este mutat intr-o coada de nivel si mai mic. Pe de alta parte, daca procesul cedeaza voluntar controlul sistemului de operare, este mutat intr-o coada de nivel mai inalt.
Ideea este de a acorda un tratament preferential proceselor scurte si de a "scufunda" procesele consumatoare de resurse in cozi de nivele din ce in ce mai mici, fiind folosite pentru a umple timpul UCP-ului si deci de a mentine un grad inalt de utilizare a UCP-ului.
Implementare in UNIX
UNIX este un sistem de operare ce permite executia concurenta a mai multor procese. Fiecarui proces activ ii este acordata o cuanta din timpul UCP. Cuanta de timp aleasa este de 100ms. Procesele au asociate prioritati, valorile mari corespunzand prioritatilor scazute. Procesele sistem au prioritati negative, in timp ce procesele utilizator au prioritati pozitive. Pentru ajustarea acestor prioritati, este disponibila comanda nice.
Pentru planificare se foloseste mecanismul cu cozi multiple. Fiecare coada este asociata cu un nivel de prioritate. Procesele executate in mod utilizator au valori pozitive pentru prioritate, iar in cazul executiei in mod nucleu, valori negative. Alegerea in cadrul cozii se face utilizand mecanismul round-robin.
La fiecare intrerupere de ceas (100ms), se alege un nou proces pentru a fi rulat. Pentru aceasta, planificatorul cauta coada nevida cu cea mai mare prioritate, din care alege primul proces. Procesul care isi epuizeaza cuanta, dar care nu s-a terminat inca, este trecut la sfarsitul cozii corespunzatoare prioritatii lui.
Procesele aflate in starea suspendat sunt organizate intr-o tabela hashing, dupa resursa. Fiecare intrare in tabela este un pointer spre o lista a proceselor blocate pe acea resursa.
Pentru a obtine o buna performanta in cazul proceselor interactive, prioritatile se modifica in timp, functie de timpul de utilizare UCP. La fiecare secunda se incrementeaza timpul de utilizare UCP (in cazul procesului aflat in executie), respectiv timpul de asteptare (pentru procesele aflate in starea suspendat).
La fiecare 4 intreruperi de ceas se recalculeaza prioritatile pentru procesele din sirul de executie (aflate in starea pregatit); prioritatea va fi cu atat mai mare cu cat timpul de utilizare UCP este mai mare. Prioritatea proceselor aflate in starea suspendat se recalculeaza la trezire (daca este trezit dupa mai mult de o secunda).
Formule din caiet !!
Se garanteaza un timp mediu de raspuns, rezonabil pentru fiecare proces din sistem. In schimb, nu se asigura raspuns la o executie "preferentiala". Din acest motiv, UNIX nu este un SO de timp real.
Comunicare si sincronizare
4.1. Conditii de cursa si sectiuni critice
Procesele comunica frecvent intre ele. In unele sisteme de operare, procesele care lucreaza impreuna adesea partajeaza date comune pe care fiecare le poate citi sau scrie. Datele comune pot fi in memorie sau pot fi intr-un fisier pe disc. Indiferent unde sunt localizate, comunicarea intre procese ridica aceleasi probleme.
Pentru exemplificare, consideram un spooler(??) de imprimanta. Cand un proces doreste sa listeze un fisier, scrie numele fisierului intr-un director special pentru spooler. Un proces sistem, printer daemon (demon de imprimanta), verifica periodic daca sunt fisiere de listat si daca da, le listeaza si apoi le sterge numele din director.
Consideram ca directorul de spooler are un numar mare de intrari, in fiecare putandu-se inscrie un nume de fisier. Mai consideram ca avem doua variabile comune tuturor proceselor : out , care indica urmatorul fisier ce trebuie listat si in , care indica urmatorea intrare libera din director. Presupunem ca la un anumit moment intrarile de la 0 la 3 sunt libere (fisierele au fost deja listate), iar cele de la 4 la 6 sunt ocupate (cu fisiere ce asteapta sa fie listate). Consideram urmatoarea situatie : doua procese, A si B, mai mult sau mai putin simultan, doresc sa trimita fisiere la imprimanta. (fig2_9.bmp)
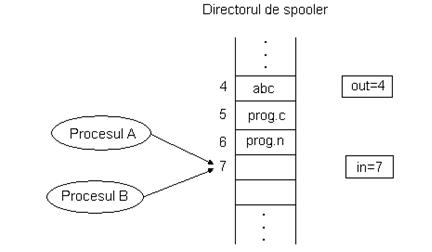
Procesul A citeste variabila in si o memoreaza in variabila next_free_slot ca avand valoarea 7. Soseste intreruperea de ceas si UCP comuta pe procesul B care, de asemenea, citeste varibila in si obtine 7, scrie numele fisierului sau in intrarea 7 si apoi incrementeaza in . Mai tarziu, UCP comuta din nou pe A. Acesta citeste next_free_slot, obtine valoarea 7 si scrie numele fisierului sau in intrarea 7, stergand astfel numele scris anterior de procesul B. Apoi incrementeaza next_free_slot si scrie valoarea obtinuta (8) in variabila in . Demonul de imprimanta nu observa nimic in neregula, dar fisierul procesului B nu va fi niciodata listat. Astfel de situatii, cand doua sau mai multe procese scriu si citesc date comune iar rezultatul final depinde de ordinea de rulare a proceselor, se numesc conditii de cursa (de intrecere, de competitie).
Greseala din exemplul de mai sus a fost ca procesul B a citit variabila in inainte ca procesul A s-o incrementeze.
Aceste parti din program in care sunt accesate datele comune se numesc sectiuni critice. Daca putem aranja lucrurile astfel incat doua procese sa nu fie in acelasi timp in sectiunile lor critice (deci sa nu acceseze simultan datele comune), putem evita conditiile de cursa.
4. Excludere mutuala
Excluderea mutuala presupune ca un singur proces sa execute la un moment dat propria sectiune critica, iar celelalte procese sa fie prevenite sa execute propriile sectiuni critice.
Daca resursa partajata este o variabila, excluderea mutuala asigura ca cel mult un proces o poate accesa la un mement dat, asigurandu-se astfel consistenta acesteia.
In cazul dispozitivelor partajate, necesitatea excluderii mutuale devine evidenta deoarece un dispozitiv poate oferi servicii unui singur utilizator la un moment dat.
Putem contura deja unele proprietati ce se cer unei solutii acceptabile de excludere mutuala :
- sa asigure excluderea mutuala intre procesele ce acceseaza resurse comune;
- sa fie independenta de sistem si portabila, cel putin la nivelul apelurilor sistem;
- sa permita o intretesere arbitrara a proceselor concurente cand nu acceseaza resursele partajate, pentru a creste gradul de concurenta in sistem;
- sa nu faca nici o presupunere privind vitezele relative ale proceselor concurente;
- sa nu faca nici o presupunere privind prioritatile proceselor concurente;
- sa nu aiba cunostinta de structurile de date private ale proceselor concurente.
4.1. Primul algoritm
Excluderea mutuala presupune ca un proces sa aiba acces exclusiv la resursa partajata in timpul executarii sectiunii critice.
Un proces care doreste sa intre in sectiunea critica ar trebui mai intai sa negocieze cu toate partile interesate pentru a se asigura ca nu exista nici o alta activitate cu care sa intre in conflict si sa instiinteze toate celelalte procese interesate ca, temporar, resursa nu va fi disponibila. Numai dupa ajungerea la un consens, procesul in cauza poate executa sectiunea critica. Odata aceasta terminata, procesul trebuie sa informeze celelalte procese ca resursa este disponibila si deci o noua runda de negocieri poate incepe.
Ca exemplificare, consideram un sistem simplu, format din doua procese care partajeaza o resursa accesata in interiorul unei sectiuni critice, pentru a mentine integritatea sistemului. Ambele procese ruleaza la infinit.
enum cine ;
int activ;
void proces1()
}
void proces2()
}
void main()
Variabila globala activ se foloseste pentru a controla accesul la o resursa partajata nespecificata (poate fi o structura de date, o portiune de cod sau un dispozitiv fizic). Aceasta variabila poate lua una din cele doua valori, proc1 sau proc2, pentru a indica procesul caruia i se permite sa intre in sectiunea critica proprie. De ex., procesul 1 bucleaza pana cand variabila activ devine proc1 si doar atunci intra in sectiunea critica. Aceasta bucla reprezinta negocierea pentru resursa. Cand termina sectiunea critica, seteaza variabila activ pe proc2, permitand astfel si procesului 2 sa utilizeze resursa. Codul procesului 2 este simetric, deci procesul 2 urmeaza acelasi protocol pentru obtinerea respectiv eliberarea resursei.
Aceasta solutie permite excluderea mutuala, dar ridica alte probleme :
in cazul in care avem mai multe procese, fiecare proces trebuie sa stie numele celorlalte procese concurente; orice restructurare a programului,din care rezulta o noua impartire a activitatii in procese, presupune modificarea atribuirilor variabilei activ in toate procesele, lucru extrem de inconvenient;
aceasta solutie nu este independenta de vitezele de executie ale celor doua procese. In cazul in care pornim cu activ setat pe proc1, cele doua procese se vor executa strict in ordinea urmatoare : P1 , P2 , P1 , P2 , P1 , P2
Astfel, viteza colectiva este data de viteza celui mai incet proces.
3. Studiem cazul cand procesul 1 cade (terminare anormala) undeva in afara sectiunii critice (alte_instructiuni).
Dupa ce termina sectiunea critica, procesul 1 seteaza activ pe proc2, permitand procesului 2 sa intre in sectiunea critica proprie. Dupa ce acesta termina sectiunea critica de executat, procesul 2 seteaza activ pe proc1, ca de obicei, dar procesul 1 nu mai este activ, deci niciodata nu se va mai schimba activ pe proc Astfel, se blocheaza si procesului 2, care bucleaza la infinit, asteptand sa i se permita accesul la o resursa care de fapt este libera.
Pe baza acestui caz,putem adauga o noua cerinta solutiei de excludere mutuala :
- sa garanteze ca terminarea normala sau anormala a unui proces in afara sectiunii critice nu afecteaza posibilitatea ca celelalte procese concurente sa acceseze resursa.
4. Studiem cazul cand procesul 1 cade in interiorul sectiunii critice.
El nu va mai fi capabil sa anunte ca resursa partajata este disponibila si astfel, nici un alt proces nu o va putea accesa ulterior
Pentru a mari siguranta, SO ar putea detecta erori prin utilizarea unor time-outs(??) pe sectiunile critice si activarea unor proceduri potrivite pentru remediere.
In baze de date mai mari, acest lucru nu este suficient. In astfel de sisteme, se salveaza mai intai datele ce se vor modifica. Daca operatia de actualizare esueaza, se poate reveni la datele anterioare incercarii de modificare.
4. Al doilea algoritm
Programul de mai jos este o alta incercare de a rezolva problema excluderii mutuale, pornind de la deficientele primului algoritm.
int p1using, p2using; /* folosite ca variabile booleene */
void proces1()
}
void proces2()
}
void main()
S-au introdus doua flag-uri p1using si p2using. Fiecare proces isi actualizeaza propriul flag, pentru a indica activitatea sa curenta sau intentiile privind folosirea resursei partajate si doar citeste flag-ul celuilalt proces cand este necesar pentru sincronizare. In rest este folosit acelasi protocol de sincronizare.
Inainte de a intra in sectiunea sa critica, procesul 1 mai intai testeaza daca resursa nu este folosita de celalalt proces, inspectand flag-ul p2using. Daca este 1, procesul 1 bucleaza pana cand flag-ul este resetat, semn ca resursa este disponibila. Atunci procesul 1 seteaza propriul flag, p1using, pentru a informa toate celelalte procese concurente ca intra in sectiunea critica. Dupa terminarea sectiunii critice, procesul 1 reseteaza p1using, semnalizand ca resursa este din nou disponibila.
Acest program este mai sigur decat cel anterior. Deoarece fiecare proces isi actualizeaza propriul flag, terminarea anormala (caderea) a unuia dintre ele in afara sectiunii critice, dupa ce a resetat flag-ul, nu blocheaza celelalte procese. De asemenea, procesele nu se mai executa intr-o ordine stricta (P1 , P2 , P1 , P2 , P1 , P2 ). Astfel, un proces poate executa sectiunea critica de un numar de ori, inainte ca celalalt proces sa faca acelasi lucru. Astfel, procesele competitoare sunt mult mai slab cuplate.
Din pacate, acest program inlatura multe restrisctii, inclusiv cea esentiala ca cel mult un proces sa fie in sectiunea sa critica la un moment dat. Consideram ca ambele procese, aproape simultan, decid sa intre in sectiunea critica proprie. Procesul 1 inspecteaza p2using si il gaseste 0. Sa presupunem ca procesul 2 intrerupe procesul 1 inainte ca acesta sa seteze p1using. Procesul 2 testeaza p1using, il gaseste 0, trage concluzia ca resursa este disponibila si, de asemenea, intra in propria sectiune critica. Daca controlul este dat in acest moment procesului 1, p1using este setat pe 1 si procesul 1 intra in propria sectiune critica. Astfel, ambele procese sunt in sectiunea critica simultan si deci nu mai este satisfacuta cerinta de excludere mutuala.
Motivul greselii este acela ca un proces inspecteaza variabila pXusing si ia decizii bazate pe valoarea citita, fara sa se asigure ca intre timp aceasta nu a fost modificata. Pentru a evita acest lucru, operatia de testare a variabilei ar trebui inclusa in sectiunea critica.
|
Politica de confidentialitate |
| Copyright ©
2026 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |
