Descrierea datelor pentru doua variabile statistice
Cele mai multe studii statistice se refera la compararea a doua sau mai multe grupuri de subiecti sau la stabilirea unor legaturi existente intre aceste grupuri. De exemplu, doua grupuri diferite de pacienti urmeaza doua tratamente diferite pentru aceiasi boala, studiul statistic avand scopul stabilirii celui mai bun tratament. Pe de alta parte, chiar si pentru un singur grup de subiecti se pot considera doua sau mai multe serii statistice. Cel mai banal dar elocvent exemplu este cel privind stabilirea relatiei intre greutatea si inaltimea unui individ, plecand de la un lot reprezentativ extras dintr-o populatie data. In ambele exemple este deci vorba de descrierea, analizarea si compararea a doua variabile statistice simultan (evident ca se poate considera si descrierea statistica individuala, prezentata in paragrafele anterioare, dar aceasta nu poate releva legaturile sau comparatia intre cele doua seturi de date).
Analog cazului unei singure serii statistice si aici vom considera reprezentarea grafica. In cazul datelor categoriale, calitative, exista aceasta posibilitate, totusi este foarte rar folosita fiind actualmente inlocuita cu analiza factoriala a corespondentelor. Insa, in ceea ce priveste datele cantitative, numerice, aici intr-adevar avem de ales intre mai multe metode.
Sa consideram mai intai cazul a doua serii statistice i = 1, n si i = 1, n, definite pe acelasi lot de subiecti. Plecand de la cele doua serii, putem considera seria cuplurilor de observatii i = 1, n definite de cele doua variabile statistice pe acelasi individ i. Cel mai obisnuit mod de reprezentare grafica al acestui cuplu de observatii este cel folosind ,norul' de puncte definit de reprezentarea bidimensionala a punctelor (xi, yi) -asa numita diagrama de imprastiere.
Exemplu.
Sa consideram o serie statistica formata din 25 observatii privind doua din principalele enzime serice: AST (aspartate transaminase) si GGT (gamma glutamyl transferase) care joaca un rol important in investigatiile medicale, prelevate de la un lot de 25 pacienti:
|
Pacient |
AST |
ALT |
Pacient |
AST |
ALT |
|
1 |
22 |
11 |
14 |
30 |
7 |
|
2 |
24 |
40 |
15 |
16 |
24 |
|
3 |
10 |
10 |
16 |
12 |
16 |
|
4 |
32 |
6 |
17 |
33 |
27 |
|
5 |
24 |
20 |
18 |
33 |
9 |
|
6 |
53 |
15 |
19 |
9 |
5 |
|
7 |
24 |
9 |
20 |
21 |
11 |
|
8 |
58 |
34 |
21 |
17 |
10 |
|
9 |
13 |
22 |
22 |
54 |
15 |
|
10 |
30 |
10 |
23 |
32 |
8 |
|
11 |
22 |
4 |
24 |
19 |
5 |
|
12 |
29 |
13 |
25 |
23 |
4 |
|
13 |
18 |
3 |
|
||
Diagrama ,norului' de imprastiere a cuplurilor (AST, GGT) pentru lotul de 25 subiecti este reprezentata in figura de mai jos.
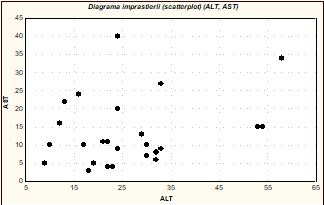
Fig. 8. Diagrama imprastierii cuplurilor (ALT, AST)
Asa dupa cum se poate observa din exemplul de mai sus, diagrama imprastierii se dovedeste un instrument util in descrierea statistica, putand produce informatii importante privind legatura intre cele doua serii statistice, fiind astfel preludiul unei analize statistice analitice ulterioare. Astfel, analizand forma norului, se pot deduce (empiric intr-adevar, dar deosebit de utile) informatii utile privind legaturile intre variabile:
norul are forma unei elipse mai mult sau mai putin alungite, paralelogram alungit, figura geometrica alungita simetrica fata de o axa = legatura liniara intre variabile;
norul are forma unui cerc sau patrat = independenta variabilelor.
Sa remarcam faptul ca este importanta alegerea unitatilor de masura a celor doua variabile pentru a nu altera legatura existenta intre ele prin modificarea formei norului; pe de alta parte, exista posibilitatea ca datele sa nu fie prezentate individual ci grupate, caz in care trebuie adoptata alta strategie (nu insistam aici asupra metodelor de a realiza acest lucru, pentru amanunte a se vedea Foucart et al., 1987).
Inafara metodei diagramelor, exista si metoda prezentarii numerice a datelor multiple, cu ajutorul unor parametri statistici. Prezentarea este facuta prin tabele, existand si aici cateva reguli pentru obtinerea unui efect cat mai mare. Astfel, este indicat, atunci cand este posibil, ca datele de aceiasi natura sa fie puse pe coloane si nu pe linii, deoarece s-a observat ca astfel pot fi citite si analizate vizual mai usor. De asemenea, tabelele pot contine fie date ,crude', adica datele reale, neprocesate, atunci cand volumul acestora nu este prea mare pentru observator dar nu si pentru un program statistic, fie rezultate ale procesarii statistice. Primul mod de prezentare este util mai ales pentru folosirea ulterioara a datelor de diferite programe statistice care, in marea lor majoritate, accepta sa prelucreze doar astfel de date. La prezentari in articole, carti sau cursuri, este evident ca prezentarea rezultatelor procesarii este preferabila, datele neprelucrate nefiind totdeauna interesante.
4. Corelatie, covarianta si regresie liniara simpla
O mare parte a studiilor statistice uzuale se ocupa cu analiza relatiei intre doua variabile statistice ce corespund aceluiasi grup de subiecti. Cel mai cunoscut exemplu, prezentat anterior, se refera la relatia ce exista intre inaltimea si greutatea unui individ ce corespunde unor anumite standarde geografice, rasiale, etc. Pentru a o identifica, se studiaza relatia dintre cele doua caracteristici masurate pe subiectii dintr-un anumit lot. Cu alte cuvinte este vorba de doua serii statistice in care cuplurile de valori (xi, yi) sunt masurate pe acelasi individ.
Exista doua mari motive pentru care se efectueaza un asemenea studiu:
1. descrierea relatiei care ar putea exista intre cele doua variabile, analizand legatura intre cele doua serii de observatii. Concret, se analizeaza daca tendinta ascendenta a uneia implica o tendinta ascendenta, descendenta sau nici o tendinta a celeilalte;
2. in ipoteza existentei unei legaturi reale intre ele, identificata in prima instanta, sa se poata prognostica valorile uneia in raport cu valorile celeilalte pe baza ecuatiei de regresie.
Asa cum se observa din cele spuse mai sus, scopul final este prognoza, in conditia ca este posibila. Metoda prin care analizam posibilele asociatii intre valorile a doua variabile statistice continue prelevate de la acelasi grup de subiecti, este cunoscuta ca metoda corelatiei si are ca indice coeficientul de corelatie. Coeficientul de corelatie poate fi calculat pentru orice set de date, dar, pentru ca el sa aiba relevanta statistica, trebuie indeplinite doua conditii majore: (a) cele doua variabile sa fie definite de acelasi lot de subiecti, cuplurile de date corespunzand aceluiasi individ si (b) cel putin una din variabile sa aiba o repartitie aproximativ normala, ideal fiind ca ambele sa fie normal repartizate. Daca datele nu au o repartitie normala (cel putin una din variabile) se procedeaza fie la transformarea lor pentru normalizare, fie la considerarea unor coeficienti de corelatie neparametrici (Altman, 1991). Testele pentru verificarea normalitatii datelor vor fi prezentate in partea dedicata inferentei statistice.
Inafara de coeficientul de corelatie se poate obtine, in cazul cand ambele variabile sunt aproximativ gaussiene, si intervalul de incredere corespunzator acestuia.
Vom prezenta in continuare formulele matematice ce stau la baza calcularii coeficientului de corelatie si a intervalului de incredere corespunzator.
Sa consideram doua serii statistice i = 1, n si i = 1, n corespunzatoare variabilelor statistice X si Y, generate de un grup de subiecti. Prin coeficientul de corelatie r al celor doua variabile, numit si Pearson's r sau coeficientul de corelatie "moment-produs" vom intelege numarul real r, cuprins intre -1 si 1, definit de formula (folosita in programele de computer):
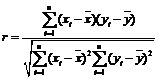 ,
,
valoarea sa putand fi privita ca o masura a elongatiei elipsei formata de norul de puncte din diagrama de imprastiere. Pentru calcule concrete (manuale, cu ajutorul calculatorului de buzunar) se foloseste formula de mai sus, scrisa sub forma:
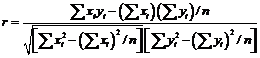 ,
,
si pentru care se intocmesc in prealabil tabele ce contin pe coloane valorile variabilelor X, Y, X2 Y2 si XY, iar pe ultima linie totalul valorilor de pe coloane. Tot in acest context sa amintim si formula covariantei celor doua variabile:
![]() .
.
In ceea ce priveste constructia intervalului de incredere 95% pentru r, plecand de la faptul ca variabila aleatoare:
![]() ,
,
este normal repartizata, rezulta ca intervalul de incredere 95% pentru z are forma (z1, z2), unde:
![]() ,
,
de unde rezulta ca, aplicand transformarea inversa, obtinem intervalul de incredere 95% pentru r, dat de:
![]() .
.
Sa
vedem acum care este interpretarea corelatiei dintre cele doua
variabile statistice. Asa cum am
spus mai inainte, coeficientul de corelatie r (Pearson) ia valori
cuprinse intre -1 si +1, trecand deci si prin 0 care indica o
asociatie neliniara intre cele doua variabile
(independenta liniara). O valoare a lui r apropiata
de -1 indica o corelatie negativa puternica, adica
tendinta unei variabile de a scadea cand cealalta variabila
creste, in timp ce o valoare a lui r apropiata de +1
indica o corelatie pozitiva puternica, adica
tendinta de crestere a unei variabile atunci cand si
cealalta variabila creste. Problema care se pune acum este
stabilirea unui prag de la care sa putem trage concluzia ca cele
doua variabile sunt intr-adevar corelate. In acest sens indicam
fie un prag definit de ![]() , de la
care se poate considera ca legatura dintre cele doua variabile
este suficient de probabila, fie utilizarea nivelului de semnificatie
p asociat calcularii coeficientului r, importanta
notiune statistica pe care o vom introduce in partea dedicata
inferentei statistice; sa notam ca daca in trecut,
cand nu existau computerele si nici programele statistice
corespunzatoare, se folosea un asemenea prag, astazi este folosit
exhaustiv doar nivelul de semnificatie p. Cu toate cele expuse mai
sus nu trebuie pierdut din vedere faptul ca un coeficient de
corelatie important nu implica totdeauna in mod necesar o
legatura naturala, intrinseca, intre caracteristicile ce
definesc cel doua variabile statistice analizate. Sunt cazuri in
medicina cand valori mari ale coeficientului de corelatie, indicand o
corelatie statistica semnificativa, nu au nici o
relevanta medicala si invers. De exemplu, aceiasi valoare
redusa a coeficientului de corelatie poate fi importanta in
epidemiologie dar nesemnificativa din punct de vedere clinic (Altman,
1991). In concluzie, coeficientul de corelatie este o masura a
legaturii liniare ,aritmetice' dintre cele doua variabile care poate
fi cateodata si intamplatoare, fara relevanta
reala. Cititorul interesat este sfatuit sa revada si
paragraful 3.3 pentru alte amanunte privind coeficientul de
corelatie.
, de la
care se poate considera ca legatura dintre cele doua variabile
este suficient de probabila, fie utilizarea nivelului de semnificatie
p asociat calcularii coeficientului r, importanta
notiune statistica pe care o vom introduce in partea dedicata
inferentei statistice; sa notam ca daca in trecut,
cand nu existau computerele si nici programele statistice
corespunzatoare, se folosea un asemenea prag, astazi este folosit
exhaustiv doar nivelul de semnificatie p. Cu toate cele expuse mai
sus nu trebuie pierdut din vedere faptul ca un coeficient de
corelatie important nu implica totdeauna in mod necesar o
legatura naturala, intrinseca, intre caracteristicile ce
definesc cel doua variabile statistice analizate. Sunt cazuri in
medicina cand valori mari ale coeficientului de corelatie, indicand o
corelatie statistica semnificativa, nu au nici o
relevanta medicala si invers. De exemplu, aceiasi valoare
redusa a coeficientului de corelatie poate fi importanta in
epidemiologie dar nesemnificativa din punct de vedere clinic (Altman,
1991). In concluzie, coeficientul de corelatie este o masura a
legaturii liniare ,aritmetice' dintre cele doua variabile care poate
fi cateodata si intamplatoare, fara relevanta
reala. Cititorul interesat este sfatuit sa revada si
paragraful 3.3 pentru alte amanunte privind coeficientul de
corelatie.
Presupunand acum ca legatura dintre cele doua variabile, reliefata de coeficientul de corelatie, nu este intamplatoare, exista trei posibile explicatii:
Variabila X influenteaza (cauzeaza) variabila Y;
Variabila Y influenteaza variabila X;
Ambele variabile X si Y sunt influentate de acelasi fenomen din fundal.
Atunci cand nu exista informatii suplimentare despre contextul in care actioneaza cele doua variabile, este nerealist sa folosim statistica pentru a valida una din cele trei ipoteze.
Prezentarea corelatiei dintre doua variabile statistice trebuie sa urmeze un anumit model. Astfel, se prezinta mai intai diagrama de imprastiere a norului de puncte. In al doilea rand, cand se prezinta coeficientul r, valoarea sa trebuie sa aiba doua zecimale si sa fie insotita de nivelul de semnificatie p si de intervalul de incredere corespunzator, daca este posibil. In fine, trebuie mentionat numarul de observatii analizate.
In ceea ce priveste covarianta, sa observam ca ea poate fi privita ca ,momentul' corelatiei si, amintindu-ne si de formula sa probabilista prezentata in paragraful 3.3, observam ca ea este nula daca variabilele care genereaza cele doua serii statistice sunt (liniar) independente; totusi, sunt cazuri de serii statistice care se deduc una din alta, de exemplu printr-o functie de gradul doi, si au, in acelasi timp covarianta nula. In principiu, deoarece covarianta este mai greu de interpretat statistic, de obicei se interpreteaza indirect prin coeficientul de corelatie (liniara) privit ca si covarianta seriilor statistice centrate reduse.
Pasul urmator in analiza legaturii dintre doua variabile statistice, atunci cand acestea sunt corelate, este sa se stabileasca concret natura legaturii liniare dintre ele, descriind-o printr-o ecuatie matematica. Scopul final al acestei abordari este prognoza valorilor uneia dintre variabile pe baza valorilor celeilalte, prognoza efectuata pe baza ecuatiei ce descrie legatura dintre cele doua seturi de date. Modul de prezentare a legaturii liniare dintre doua variabile, atunci cand aceasta exista, se numeste metoda regresiei liniare (regresia liniara). Pentru aceasta, se considera una dintre variabile ca variabila independenta sau variabila predictor iar cealalta variabila ca variabila dependenta sau variabila raspuns. Legatura liniara dintre cele doua variabile este descrisa de o ecuatie liniara, ecuatia de regresie careia ii corespunde geometric dreapta de regresie
Ca metodologie, variabila dependenta se distribuie pe axa ordonatelor, in timp ce variabila independenta se distribuie pe axa absciselor. Ecuatia dreptei de regresie se stabileste pe baza metodei "celor mai mici patrate". Metoda consta in calcularea distantelor (pe verticala) dintre punctele observate si punctele de pe o anumita dreapta ce trece prin mijlocul norului de puncte, distante cunoscute sub numele de reziduuri si in considerarea dreptei optime -dreapta de regresie, ca acea dreapta pentru care suma patratelor acestor reziduuri este minima. Rezumand, dreapta de regresie este acea dreapta ce trece prin norul de puncte format de perechile de date ale celor doua variabile si minimizeaza ,distanta' intre date si dreapta (minimizand suma patratelor distantelor). In final, obtinem ecuatia de regresie sub forma:
Y = a +bX,
unde a se numeste interceptor iar b coeficient de regresie.
Tehnic vorbind, vom folosi regresia liniara cand sunt indeplinite urmatoarele trei ipoteze:
valorile variabilei dependente Y trebuie sa aiba o repartitie normala (gaussiana);
variabilitatea variabilei prognozate Y trebuie sa fie asemanatoare cu cea a predictorului X (dispersia sau deviatia standard asemanatoare);
legatura dintre cele doua variabile, predictorul si variabila dependenta trebuie sa fie liniara (verificare empirica pe baza 'norului' de puncte, care trebuie sa aiba o 'forma' alungita -liniara).
Modul standard de a verifica simultan toate cele trei ipoteze de lucru este analiza statistica a reziduurilor. Astfel, se poate demonstra ca daca toate cele trei ipoteze sunt verificate simultan, atunci reziduurile sunt normal repartizate de medie zero.
In figura de mai jos prezentam schematic dreapta de regresie si reziduurile corespunzatoare norului de puncte.
![]()
![]()
![]()
![]()
![]()

Fig. 9. Dreapta de regresie si reziduurile corespunzatoare
Din punct de vedere matematic, dreapta de regresie este data de ecuatia:
Y = a +bX,
unde:
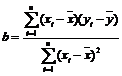 ,
,![]() .
.
Din punct de vedere practic, excluzand programele statistice pentru computere care folosesc formula de mai sus, pentru usurarea calculelor manuale cu ajutorul calculatoarelor de buzunar, folosind un tabel ca cel pe care l-am amintit la calculul coeficientului de corelatie, se pot considera urmatoarele formule:
![]() ,
,
![]() ,
,
![]() ,
,
de unde obtinem ![]() .
.
Remarca. Se poate extinde regresia liniara de la cupluri de doua variabile la mai multe variabile prin metoda regresiei liniare multiple, caz in care avem o variabila dependenta si mai multe variabile predictive (vezi paragraful urmator).
In cazul cand legatura dintre cele doua variabile statistice nu este liniara ca cea prezentata mai inainte si totusi banuim ca exista, avem de-a face cu o regresie neliniara (e.g. regresia polinomiala). Atunci, in loc de a gasi dreapta de regresie se gaseste curba respectiva de regresie.
Daca vom considera perechi de date provenind de la doua grupuri diferite de subiecti si avand aceleasi semnificatii, putem folosi dreptele de regresie calculate pentru fiecare grup pentru a compara cele doua grupuri. Daca, de exemplu, cele doua drepte de regresie au aproximativ aceiasi panta (sunt paralele), atunci putem considera diferenta pe axa verticala (Y) ca fiind diferenta intre mediile variabilei Y intre cele doua grupuri, observatie ce este apoi urmata de o testare a semnificatiei statistice a diferentei. O asemenea analiza statistica face parte dintr-un studiu statistic mai vast care se numeste analiza covariantelor, dar nu face obiectul acestei prezentari.
Exemple.
1) (Danko et al., 1977) Sa consideram
ca ![]() reprezinta
limita de elasticitate a unei marci de otel iar
reprezinta
limita de elasticitate a unei marci de otel iar ![]() reprezinta
limita sa de ruptura. Stiindu-se ca raportul
reprezinta
limita sa de ruptura. Stiindu-se ca raportul
![]() este strans
legat de continutul procentual (%) in carbon al otelului, notat aici Y,
sa se analizeze corelatia obtinuta intre cei doi parametri
pe un esantion de 79 de probe prelevate din diferite marci de
otel, date prezentate in tabelul de mai jos.
este strans
legat de continutul procentual (%) in carbon al otelului, notat aici Y,
sa se analizeze corelatia obtinuta intre cei doi parametri
pe un esantion de 79 de probe prelevate din diferite marci de
otel, date prezentate in tabelul de mai jos.
YX |
0,5 |
0,6 |
0,7 |
0,8 |
|
0,5 |
0 |
2 |
0 |
8 |
|
0,6 |
0 |
4 |
2 |
9 |
|
0,7 |
2 |
12 |
3 |
1 |
|
0,8 |
21 |
14 |
0 |
0 |
|
0,9 |
1 |
0 |
0 |
0 |
Specificam ca numerele intregi din interiorul acestui tabel reprezinta frecventa relativa de aparitie in cele 79 de probe a perechilor (X, Y) corespunzatoare. Efectuand calculele, se obtine coeficientul de corelatie r = -0,867 care indica o semnificativa corelatie negativa (cu cat mai putin continut de carbon, cu atat un mai mare indice X) si ecuatia de regresie a lui X in raport cu Y data de:
X = -0,908![]() Y +
1,268
Y +
1,268
Ca o aplicatie practica a functiei de prognoza obtinuta din regresia liniara, sa calculam care este indicele X pentru o marca de otel cu un continut procentual de carbon de 0,68. Inlocuind in ecuatia de regresie Y = 0.68, obtinem valoarea cautata a indicelui X ca fiind 0,65.
2) (Altman, 1991) Sa consideram datele culese de la un lot de 24 de pacienti avand diabet de tip I privind doua variabile:
|
Pacient |
G |
Vcf |
Pacient |
G |
Vcf |
|
1 |
15,3 |
1,76 |
13 |
19,0 |
1,95 |
|
2 |
10,8 |
1,34 |
14 |
15,1 |
1,28 |
|
3 |
8,1 |
1,27 |
15 |
6,7 |
1,52 |
|
4 |
19,5 |
1,47 |
16 |
8,6 |
|
|
5 |
7,2 |
1,27 |
17 |
4,2 |
1,12 |
|
6 |
5,3 |
1,49 |
18 |
10,3 |
1,37 |
|
7 |
9,3 |
1,31 |
19 |
12,5 |
1,19 |
|
8 |
11,1 |
1,09 |
20 |
16,1 |
1,05 |
|
9 |
7,5 |
1,18 |
21 |
13,3 |
1,32 |
|
10 |
12,2 |
1,22 |
22 |
4,9 |
1,03 |
|
11 |
6,7 |
1,25 |
23 |
8,8 |
1,12 |
|
12 |
5,2 |
1,19 |
24 |
9,5 |
1,70 |
Asa cum se observa din tabelul de mai sus, pacientul cu numarul 16 nu are specificata variabila Vcf. Putem, pe baza datelor de mai sus (neluand, evident, in considerare pacientul 16) sa prognozam valoarea sa Vcf (mult mai dificil de obtinut) pe baza valorii glucozei in sange.
Tabelul de mai jos prezinta principalele caracteristici numerice ale regresiei liniare aplicate in acest caz.
|
Variabila |
Media |
Deviatia standard |
r |
Nivel semnificatie p |
|
G |
10,30 |
4,34 |
|
|
|
Vcf |
1,32 |
0,23 |
0,42 |
0,041 |
Reprezentarea grafica de mai jos prezinta diagrama imprastierii, dreapta de regresie si intervalul de incredere 95% pentru media Vcf.
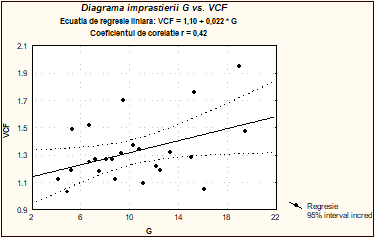
Fig. 10. Dreapta de regresie Vcf vs. G
Asa dupa cum se observa mai sus, in ciuda faptului ca valoarea coeficientului de corelatie r nu este importanta, totusi nivelul de semnificatie p = 0,041 atesta o corelatie semnificativa (vom vedea la vremea potrivita, in cadrul inferentei statistice, ce inseamna de fapt p). Ecuatia de regresie liniara este:
Vcf = 1,10 + 0.02*G ,
de unde deducem ca valoarea estimata (prognozata pe baza regresiei liniare) a Vcf pentru pacientul no. 16 este de 1,27%. Sa observam ca pe dreapta de regresie gasim valorile medii prognozate ale variabilei Vcf in functie de glucoza. Cum se foloseste insa intervalul de incredere 95% in acest caz? Sa alegem o valoare (fixata) a variabilei G (glucoza) pe axa absciselor. Ducem apoi o perpendiculara pe aceasta axa in punctul fixat si consideram intervalul (masurat pe axa ordonatelor) definit de intersectiile perpendicularei cu cele doua curbe punctate (una inferioara si alta superioara) ce definesc intervalul de incredere. Rezulta, asa cum am aratat anterior, ca orice valoare din acest interval este o posibila estimatie a mediei corespunzatoare a Vcf cu o probabilitate de 95%, punctul de mijloc al acestui interval fiind chiar pe dreapta de regresie si fiind ales (echiprobabil intre celelalte valori ale intervalului) ca valoare standard pentru media cautata. De exemplu, pentru valoarea fixata a glucozei G = 10, obtinem intervalul de incredere 95% pentru Vcf definit de (1.22, 1.40) cu punctul mediu pe dreapta de regresie de 1,31. Rezulta, deci, ca un pacient avand diabet de tip I, cu valoarea G de 10 ar trebui sa aiba o valoare a Vcf cuprinsa intre 1,22 si 1,40 cu aceiasi probabilitate de 95%. In acest caz se alege ca valoare standard media celor doua valori, care se gaseste pe dreapta de regresie, in acest caz 1,31.
|
Politica de confidentialitate |
| Copyright ©
2026 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |
