Modul in care sunt inreconectati neuronii in reteaua neurala determina topologia acesteia. Cateva din cele mai utilizate topologii sunt prezentate in Figura III.13. Retelele artificiale sunt structurate - ca si cele biologice - ierarhic, in straturi (sau nivele) de neuroni. Cele cu un singur nivel se numesc unistratificate (SLNN - single-layer neural network), iar cele cu mai multe niveluri se numesc multistratificate (MLNN - multilayer neural network).
Nivelului de intrare i se aplica anumite semnale (stimuli), iar cel de iesire furnizeaza raspunsul la acesti stimuli. Nivelele intermediare dintre cele doua se numesc nivele ascunse, deoarece iesirile lor nu sunt direct observabile. Intreaga retea poate fi asimilata unui procesor sofisticat de semnale. Prelucrarile sunt insa distribuite peste intraga structura, fiecare neuron facand parte dintr-un program global de executie, spre deosebire de masinile clasice von Neumann, care executa numai algoritmi secventiali.
Cele mai importante modele pentru retelele neurale artificiale, asa cum au evoluat ele cronologic, sunt prezentate in continuare.
Modelul McCulloch - Pitts. Neurobiologul W. McCulloch si statisticianul W. Pitts au elaborat in 1943 primul model matematic al unui neuron biologic idealizat, sugerand si idei pentru utilizarea acestuia. Modelul are structura simpla din Figura III.14. Iesirea neuronului artificial este exprimata astfel:
![]() (3.83)
(3.83)
unde xij sunt stimuli de la intrarea j a neuronului i, f este o functie de transfer neliniara, Qi este termenul de activare. Modelul McCulloch-Pitts reprezinta un singur neuron in bucla deschisa, care nu are nici un mecanism de ajustare a ponderilor sau de comparare cu raspunsul dorit si nu este supus la nici un proces de instruire.
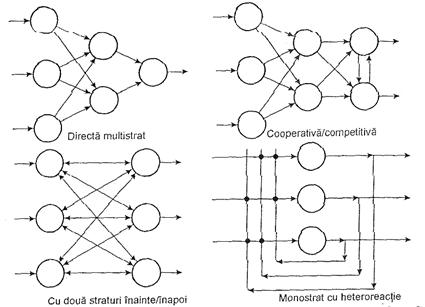
Figura III.13. Topologii pentru retele neurale artificiale
Perceptronul. In perioada dezvoltarii teoriei reglarii automate adaptive, F. Rosenblatt a dezvoltat o noua generatie a modelului McCulloch - Pitts, cu capabilitati de invatare si adaptare.
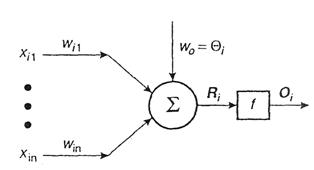
Figura III.14. Modelul neuronului artificial McCulloch - Pitts
Perceptronul original este un un sistem de clasificare cu instruire supervizata. El poate recunoaste forme abstracte sau geometrice, bazat pe trei nivele (sau unitati): unitatea senzoriala S (careia i se aplica stimuli optici), unitatea asociativa A (care este instruita in prealabil) si unitatea de raspuns R ( care furnizeaza iesirile). Schema bloc este prezentata in Figura III.15.
Unitatea senzoriala este o matrice bidimensionala cu 400 de fotodetectori, conectati aleator cu unitatea asociativa, care emit semnale electrice binare daca stimulii ce li se aplica depasesc un anumit prag. Unitatea A, alcatuita din subcircuite predicate, detecteaza trasaturi specifice ale modelului de intrare, similar cu detectorii de pe retina unui ochi. Rezultatul analizei predicator este tot binar. Nivelul de raspuns contine perceptronii (detectorii de modele). Numai ponderile acestui nivel sunt instruibile. Functia de transfer utilizata este de tip hard-limiter:
![]() (3.84)
(3.84)
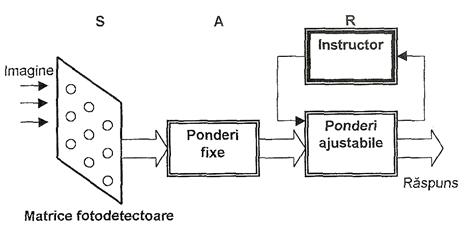
Figura III.15. Arhitectura perceptronului original
In timpul instruirii, stimulii aplicati la intrare produc o iesire O care este comparata cu iesirea tinta T, iar semnalul de eroare E rezultat este folosit pentru ajustarea ponderilor:
![]() (3.85)
(3.85)
Rezulta:
![]() (3.86)
(3.86)
Instruirea se desfasoara conform urmatorului algoritm:
Initializeaza valorile O si ponderile wij(0) cu valori mici aleatoare;
Aplica un model cu intrare xp si iesirea corespunzatoare Tp (p - numarul de modele din set);
Calculeaza
iesirea actuala din: 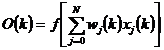 sau, in notatia vectoriala:
sau, in notatia vectoriala: ![]()
Adapteaza ponderile utilizand relatiile iterative:
![]()
Repeta pasii 2- 4, pana cand cand ponderile nu se mai modifica.
Se poate demonstra ca pentru n variabile de intrare se obtin NLF(n) functii logice implementabile, conform relatiei:
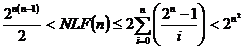 (3.87)
(3.87)
Pentru n foarte mare, din (3.87) se observa ca NLF(n) va fi extrem de mic. Perceptronul simplu poate functiona ca un discriminant in recunoasterea modelelor din doua clase sau ca o unitate logica binara de implementare a functiilor AND, OR, NOT (dar nu si XOR) cat si a celor de pluralitate sau majoritate.
Perceptronul multinivel (MLP - multilayer perceptron) constituie o dezvoltare a modelului original. El este compus din mai multi perceptroni simpli ce formeaza o topologie directa (Figura III.16).
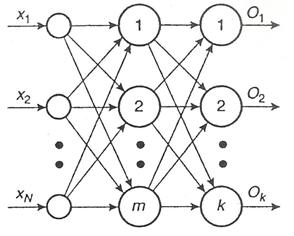
Figura III.16. Modelul perceptronului multinivel
Neliniaritatea neuronilor este de tip sigmoidal, de forma:
![]() (3.88)
(3.88)
unde k este amplificarea sigmoidala, cu variatie monotona
intre -![]() si +
si +![]() . Nu exista o metoda formala pentru
determinarea numarului optim de noduri pe nivel sau al numarului de
nivele ascunse, ele fiind alese in functie de aplicatie. Algoritmii
uzuali de instruire pentru MLP sunt Delta si BP. Modelul poate fi utilizat
pentru implementarea unor functii logice de clasificare arbitrare sau
pentru implementarea unor transformari neliniare in probleme de aproximare
functionala.
. Nu exista o metoda formala pentru
determinarea numarului optim de noduri pe nivel sau al numarului de
nivele ascunse, ele fiind alese in functie de aplicatie. Algoritmii
uzuali de instruire pentru MLP sunt Delta si BP. Modelul poate fi utilizat
pentru implementarea unor functii logice de clasificare arbitrare sau
pentru implementarea unor transformari neliniare in probleme de aproximare
functionala.
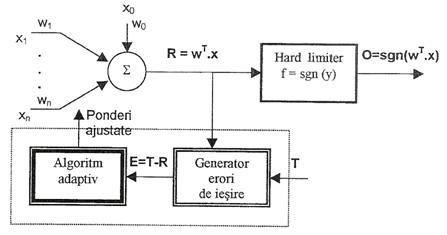
Figura III.17. Modelul ADALINE cu bloc de instruire
Modelele ADALINE si MADLINE. B. Windrow a construit doua modele de retele neurale cu trei straturi. ADALINE (adaptive linear neuron) are pe stratul din mijloc un singur neuron, ca in Figura III.17. Intrarile si iesirile au doua valori ( ), iar ponderile (pozitive sau negative) sunt ajustate prin minimizarea erorii medii patratice:
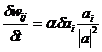 (3.89)
(3.89)
unde constanta aI[0,1]. Pentru instruirea modelului ADALINE se utilizeaza algoritmul Windrow - Hoff, cu urmatorii pasi:
Asigneaza valori aleatoare ponderilor, in domeniul [-1, 1];
Aplica modelul cu intrarea selectata si iesirea tinta corespunzatoare;
Calculeaza semnalul de eroare E;
Ajusteaza fiecare pondere, pe baza ecuatiei (3.15), astfel incat eroarea sa se reduca cu 1/n, unde n este numarul ponderilor;
Repeta procesul pana cand eroarea devine 0;
Repeta procesul pentru urmatorul set de intrari.
Modelul MADALINE (many ADALINE) utilizeaza mai multe structuri ADALINE montate in paralel care furnizeaza o singura iesire, a carei valoare este selectata pe baza anumitor reguli. Modelele ADALINE - MADALINE se utilizeaza efectiv in sistemele de comunicatii si pentru controlul secvential al proceselor.
Modelul retelei directe multinivel a fost construit in stransa legatura cu algoritmul cu propagare inapoi (BP - backpropagation), dezvoltat in 1974 de Werbos si redescoperit independent de Rumelhart si Parker. Retelele neurale artificiale directe multinivel (FFANN - feedforward ANN) au o arhitectura similara cu cea prezentata in Figura III.16. Algoritmul BP instruieste reteaua pentru a realiza o corespondenta asociativa distribuita intre nivelele de intrare si iesire. Ceea ce il deosebeste de alti algoritmi similari este procedura prin care se calculeaza ponderile in faza de instruire.
O sesiune de instruire a retelei consta in utilizarea unei perechi model (xk, Tk), unde xk este intrarea, iar Tk este iesirea dorita (tinta modelului). Intrarile xk determina raspunsuri la iesirea fiecarui neuron de pe fiecare nivel, inclusiv un raspuns actual Ok pe nivelul de iesire. Diferenta intre Ok si tinta formeaza semnalul de eroare, care depinde de valorile ponderilor tuturor nodurilor si trebuie minimizat. Dupa calculul erorii de iesire, algoritmul BP recalculeaza ponderile de pe ultimul nivel ascuns, in asa fel incat eroarea sa sufere o prima minimizare. In continuare, se calculeaza eroarea la iesirea acestui ultim nivel si se modifica ponderile corespunzatoare nivelului ascuns anterior acestuia, pentru o noua minimizare a erorii. Procesul de calcul continua sa determine eroarea si valorile ponderilor mergand inapoi, din nivel in nivel ascuns pana la intrare. Cand se ajunge la intrare si ponderile nu se mai modifica (adica a fost atins un echilibru), algoritmul selecteaza urmatoarea pereche (xk, Tk) si repeta procesul. Pentru ca raspunsul se formeaza prin deplasare inainte, iar ponderile se calculeaza prin deplasare inapoi, algoritmul se numeste cu propagare inapoi.
Formalismul matematic al algoritmului BP se construieste considerand o retea neurala cu l nivele si Nl noduri pe nivelul l. Notam cu wl,j,i - ponderea intre nodul i al nivelului l-1 si nodul j al nivelului l, Ol,j(xp) - iesirea actuala (pentru modelul xp al nodului j pe nivelul l), Tl, j(xp) - iesirea dorita (pentru modelul xp al nodului j pe nivelul l), al,j(xp) - iesirea activata (pentru modelul xp) a nodului j pe nivelul l (inaintea neliniaritatii), p - numarul de modele de instruire (p = 1,, P).
Daca nodul i de pe nivelul (l+1) primeste semnale de la nodul j de pe nivelul l prin ponderea wijl si daca nivelul l are Nl noduri, atunci semnalul de iesire al nodului i de pe nivelul (l+1) la modelul k al retelei este:
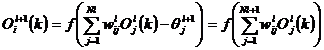 (3.90)
(3.90)
unde θil+1 este o valoare de prag.
Daca se utilizeaza
functia sigmoidala ![]() , a carei derivata este
, a carei derivata este ![]() , atunci eroarea totala E, pentru toate modelele k,
este determinata ca suma a diferentelor patratice intre
iesirea actuala a retelei si iesirea dorita a
nivelului:
, atunci eroarea totala E, pentru toate modelele k,
este determinata ca suma a diferentelor patratice intre
iesirea actuala a retelei si iesirea dorita a
nivelului:
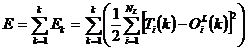 (3.91)
(3.91)
Regula de instruire pentru evaluarea unui set de ponderi care sa minimizeze E consta in efectuarea de modificari ale acestora proportional cu derivata negativa a erorii in raport cu ponderile:
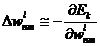 (3.92)
(3.92)
Pentru calculul dependentei erorii Ek de ponderea nm a neuronului de pe nivelul l, se poate utiliza regula inlantuita:
![]() (3.93)
(3.93)
Atunci:
![]() (3.94)
(3.94)
Introducand in relatia (3.94) functia sigmoidala si derivata ei, pentru ponderile de pe nivelul de iesire (l = L-1) obtinem:
![]() (3.95)
(3.95)
si procedura de modificare a ponderilor pe nivelul de iesire devine astfel:
![]() (3.96)
(3.96)
unde h este factorul de proportionalitate cunoscut sub numele de rata de instruire. Pe de alta parte, daca l este diferit de L-1, atunci OmL-1 depinde de wnml si aplicand regula inlantuita (2.2.26) obtinem o noua dependenta de ponderi a erorii:
![]() (3.97)
(3.97)
Pentru ponderile de pe ultimul nivel ascuns (l = L - 2), expresia (2.2.30) devine:
![]()
si - in consecinta - procedura pentru ajustarea ponderilor pe acest ultim nivel este:
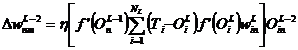 (3.99)
(3.99)
Relatia se poate sumariza prin:
![]() (3.100)
(3.100)
sau, pentru ponderile nivelului de iesire:
![]() (3.101)
(3.101)
iar pentru ponderile de pe nivelele ascunse:
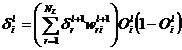 (3.102)
(3.102)
Relatia (3.102) pune in evidenta faptul ca pentru nodurile nivelului l, calculul lui dil depinde de erorile calculate pe nivelul l+1, adica procedura se desfasoara cu propagare inapoi. Procesul de calcul al gradientului si de ajustare a ponderilor se repeta pana se gaseste eroarea minima. In practica se stabileste si un criteriu de terminare, pentru a se asigura finitudinea algoritmului.
Functionarea algoritmului de instruire BP poate fi rezumata astfel:
Initializeaza toate ponderile cu valori mici, aleatoare.
Alege perechea model de instruire (x(k), T(k)).
Calculeaza iesirile actuale ale
fiecarui neuron de pe un nivel, plecand de la nivelul de intrare si
trecand peste fiecare nivel ascuns, pana la nivelul de iesire L: 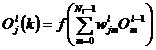
Calculeaza gradientul dil si diferenta Dwijl pentru fiecare intrare a neuronilor unui nivel, pornind de la nivelul de iesire inapoi, trecand peste fiecare nivel ascuns, pana la nivelul de intrare.
Actualizeaza ponderile.
Repeta pasii 2 - 5.
Cu toate ca algoritmul BP este frecvent utilizat pentru instruirea FFANN, el impune uneori un volum excesiv de calcul - proportional cu numarul ponderilor - iar viteza de instruire scade odata cu cresterea dimensiunii retelei. In ciuda tehnicilor recomandate pentru accelerarea vitezei de instruire, algoritmul BP nu este totdeauna potrivit pentru aplicatii in timp real.
Modelul
CMAC.
Luand ca referinta creierul uman, J. Albus a dezvoltat controlerul
articulat pe model cerebelar (CMAC - Cerebellum Model Articulation
Controller). Modelul propus este, in mare parte, similar functional cu cel
prezentat anterior, pentru ca amandoua invata prin
supervizare si utilizeaza asociatia intre un model de intrare
si un raspuns dorit. Exista totusi si diferente.
Astfel, CMAC utilizeaza pentru instruire algoritmul Windrow (sau regula
Delta), bazat pe modificari treptate ale ponderilor pentru minimizarea
erorii, conform relatiei ![]() . Rata de instruire b are valori cuprinse
intre 0.2 si 0.8.
. Rata de instruire b are valori cuprinse
intre 0.2 si 0.8.
Viteza de instruire a modelului CMAC este, in comparatie cu algoritmul BP, cu cateva ordine de marime mai mare. In plus, pentru ca intrarile si iesirile sunt valori binare, retelele CMAC se pot implementa usor cu circuite logice CMOS.
Modelele teoriei rezonantei adaptive (ART - adaptive resonance theory) sunt sisteme cognitive si comportamentale, dezvoltate de S. Grossberg si G. Carpenter. Ele invata fara supervizare, prin instruire competitiva, cautand autonom categorii sau creand altele noi, daca este necesar. Dilema plasticitate - stabilitate ce apare la retelele directe se rezolva combinand tehnicile de instruire inainte (intrare - iesire) cu cele inapoi (iesire - intrare).
Arhitectura ART consta in doua nivele (Figura III.18): cel de intrare are N noduri si efectueaza compararea, iar cel de iesire are M noduri si efectueaza recunoasterea. Ele interactioneaza atat direct, cat si prin reactie. Uneori se foloseste ca nivel intermediar o retea adaptiva de filtrare.
In timpul instruirii,
stimulul aplicat la intrare este propagat spre iesire prin ponderile
filtrului adaptiv. Semnalele de iesire sunt retrimise inapoi prin
intermediul aceluiasi filtru, astfel incat pe nivelul de intrare vom avea
doua semnale: unul direct si unul reflectat. Dupa ce suma
ponderata a nodurilor de intrare este propagata catre stratul de
iesire si comparata cu clasificarile (sumele ponderate) ale
fiecarui nod de pe acest nivel, iesirea cea mai potrivita se va
propaga inapoi prin noi ponderi tij spre nivelul de intrare,
celelalte fiind suprimate. Semnalul de reactie este comparat cu actualele
intrari iar vectorul de comparatie rezultat este analizat de un
circuit special, care utilizeaza o masura a
similaritatii intre  si un prag de
admitanta r. Daca
si un prag de
admitanta r. Daca ![]() , atunci reteaua ART a identificat corect o categorie
(s-a detectat o rezonanta) iar daca
, atunci reteaua ART a identificat corect o categorie
(s-a detectat o rezonanta) iar daca ![]() se testeaza
urmatoarea similitudine, s.a.m.d. Aceasta instruire
autonoma poate fi utilizata pentru procese dinamice ai caror
parametri se modifica in timp.
se testeaza
urmatoarea similitudine, s.a.m.d. Aceasta instruire
autonoma poate fi utilizata pentru procese dinamice ai caror
parametri se modifica in timp.
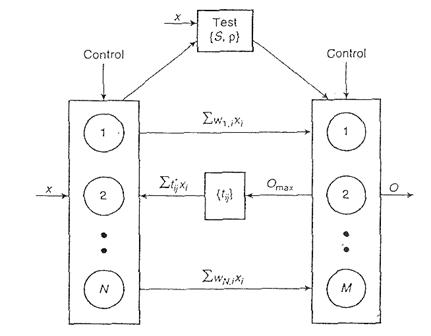
Figura III.18. Reprezentarea modelului ART
Algoritmul ART lucreaza in felul urmator:
Initializare: ![]() .
.
Aplica un vector de intrare x.
Calculeaza iesirea: ![]()
Selecteaza cel mai potrivit exemplar: ![]()
Calculeaza ratia: 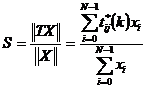
Daca ![]() , salt la 8, altfel, salt la 7.
, salt la 8, altfel, salt la 7.
Dezafecteaza cea mai buna potrivire, reseteaza iesirea celui mai potrivit nod si salt la 3.
Adapteaza cea mai buna potrivire:
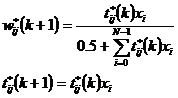
Activeaza toate nodurile dezafectate si salt la 2.
Modelul Hopfield a fost conceput in 1982 si consta dintr-o retea monostrat autoasociativa integral conectata (Figura III.19).
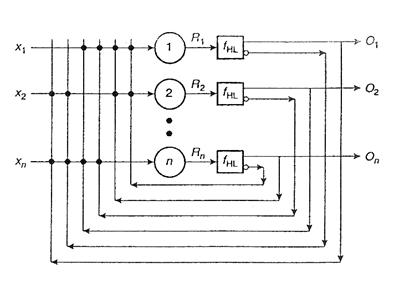
Figura III.19. Modelul de baza Hopfield
Intrarile sunt fie binare, fie bipolare ( ). Unitatea de procesare a modelului are doua iesiri, una directa si una inversoare, care sunt cuplate inapoi cu intrarile tuturor celorlalte unitati, exceptand-o pe cea in cauza. Ponderile simetrice (wij = wji) sunt obtinute prin conexiuni rezistive. Cum nu exista rezistente negative, conexiunile excitatoare utilizeaza iesirile directe, iar cele inhibatoare, iesirile inversoare.
Hopfield descrie acest model printr-o functie de energie care depinde de starile neuronilor interconectati j si i, adica de iesirile V si ponderile wij:
![]() (3.103)
(3.103)
Functia E este minimizata in raport cu iesirile VI:
![]() (3.104)
(3.104)
Ecuatia (3.104) poate duce la rezultate incorecte datorate minimelor locale, insa reteaua este capabila sa detecteze aceste situatii.
Formalismul matematic al modelului Hopfield porneste de la expresia neliniaritatii Ri a neuronului i al retelei unistrat:
![]() (3.105)
(3.105)
unde xi este intrarea externa catre nodul i, Oj este iesirea neuronului dupa neliniaritate, qi este valoarea de prag a neuronului, iar wij - ponderile. In notatie vectoriala, ecuatia (2.2.38) devine:
![]() (3.106)
(3.106)
Pentru toate nodurile, obtinem:
R = WO + x - q (3.107)
unde W este o matrice simetrica n x n, cu wij = wji si wii = 0. Daca functia de activare este sgn(.), iesirile Oi vor lua valorile . In timpul instruirii, iesirile sunt actualizate asincron (adica numai una la un moment dat).
Algoritmul de instruire Hopfield este urmatorul:
Aloca ponderi aleatoare wij = 1 pentru toti i diferti de j si wij = 0 pentru i = j (actualizare asincrona - toti termenii diagonali sunt nuli).
Initializeaza reteaua cu un model necunoscut xi =Oi(k), 0 i N-1, unde Oi(k) este iesirea i de la momentul t = k = 0.
Itereaza pana la atingerea convergentei, utilizand relatia:
![]() , unde f(.) este o neliniaritate de tip hard - limiter (fHL).
Procesul se repeta cand iesirile nodurilor raman neschimbate.
, unde f(.) este o neliniaritate de tip hard - limiter (fHL).
Procesul se repeta cand iesirile nodurilor raman neschimbate.
Treci la pasul 2 si repeta procesul pentru urmatorul xi.
Modele de tip memorie. Memoria de tip RAM (Random Acces Memory) nu este o retea neurala, dar principiul ei de functionare a generat modele neurale de acest tip. O memorie RAM consta dintr-o matrice de biti, decodificator de adrese, magistrale de date, de adrese si de comenzi. Scrierea in RAM poate fi asemanata cu invatarea, iar citirea cu asocierea sau regasirea. In principiu, o asemenea memorie poate fi vazuta ca o retea asociativa unidirectionala. Comparand insa memoriile RAM cu ANN, gasim diferente fundamentale: memoria RAM poate fi actualizata usor si rapid fara a utiliza ponderi sau iteratii de instruire, pe cand o ANN odata instruita este dificil de reprogramat, dar poate furniza iesiri corecte din intrari incomplete.
Modelul memoriei asociative bidirectionale (BAM-Birectional Asociative Memory) nu este o matrice, ci o retea neurala heterorasociativa cu doua straturi, FA si FB . Ea poate asocia modele din doua seturi Ak si Bk, avand structura din Figura III.20.
Instruirea unei BAM furnizeaza o matrice a ponderilor W, cu dimensiunea n x m , care este calculata astfel:
![]() (3.108)
(3.108)
unde Ak si Bk sunt modelele pereche ce vor fi asociate la pasul de instruire k.
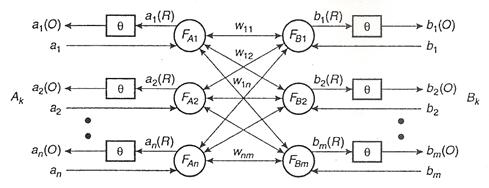
Figura III.20. Arhitectura retelei BAM
Modelul memoriei asociative temporale (TAM - Temporal Asociative Memory) este o ANN cu doua straturi care functioneaza ca un codificator ciclic cu reactie si utilizeaza instruirea cu supervizare. Memoria TAM invata sa asocieze ciclic modele secventiale bipolare sau binare (A1 cu A2, A2 cu A3, A3 cu A4,..., An-1 cu An si An cu A1). Arhitectura ei este similara cu a memorie BAM (Figura III.21).
In faza de instruire reteaua invata sa asocieze in ambele directii perechi consecutive de modele (Ak, Ak+1). Similar cu instruirea BAM, matricea ponderilor se calculeaza astfel:
![]() (3.109)
(3.109)
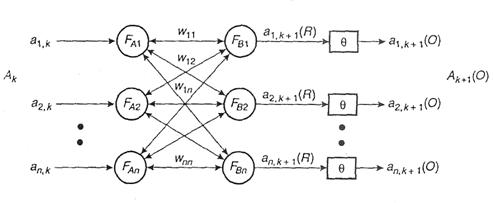
Figura III.21. Arhitectura retelei TAM
Modelul memorie asociative liniare (LAM - Linear Associative Memory) a fost initiat in 1972 de J. Anderson si se bazeaza pe principiul hebbian de modificare a ponderile intre noduri la fiecare activare a conexiunilor. Arhitectura modelului este prezentata in Figura III.22.
Conform lucrarilor lui Anderson, Kohonen sau Nakano, o retea LAM stocheaza unidirectional, printr-o matrice de corelatie, p seturi de perechi de modele (AP, BP). In timpul instruirii, matricea ponderilor este calculata astfel:
![]() (3.110)
(3.110)
Daca la intrare se aplica un model Ap, perechea lui Bp este cautata prin calculul unui vector de iesire:
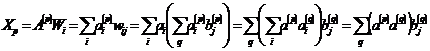 (3.111)
(3.111)
Daca vectorii a(p) sunt mutuali ortogonali (AiAjT=0, i j), atunci ultima suma se reduce la un singur termen:
![]() (3.112)
(3.112)
Astfel, vectorul de
iesire Xj este direct proportional cu vectorul dorit b(p). Daca
toti vectorii Ak sunt
unitar normalizati (![]() , p = 1, 2, .., m) atunci iesirea Xj = Ak, deci
iesirea regaseste intrarea model.
, p = 1, 2, .., m) atunci iesirea Xj = Ak, deci
iesirea regaseste intrarea model.
Figura III.22. Arhitectura retelei LAM
Modelul cu vector liniar de cuantizare (LVQ - Linear Vector Quantization) este un sistem de clasificare introdus de T. Kohonen. Reteaua are un singur nivel, cu noduri de tip "invingatorul ia tot". In timpul instruirii de tip competitiv, ANN cauta nodul de iesire cu cea mai buna potrivire in raport cu modelul de intrare. Retelele LVQ sunt utilizate pentru recunoasterea caracterelor sau a vorbirii naturale.
Modelul retelelor cu autoorganizare (SOM - Self Organizing Map) a fost dezvoltat tot de T. Kohonen. Retelele SOM implementeaza un algoritm de clasificare bazat pe o reprezentare redusa a datelor de intrare sub forma unei harti a relatiilor dintre ele.
Figura III.23. Arhitectura retelei PNN
Retelele SOM au similitudini cu retele LVQ, pentru ca amandoua au un singur nivel si utilizeaza o distanta metrica pentru a gasi nodul de iesire cel mai potrivit a reda modelul de intrare. Spre deosebire insa de LVQ, nodurile de iesire ale retelelor SOM nu corespund unor clase cunoscute de modele, ci unor categorii necunoscute, pe care insasi reteaua le formeaza din datele de instruire. Este cautat nodul cu iesirea situata la cea mai mica distanta de model si ponderile catre acest nod sunt modificate in sensul cresterii similaritatii cu modelul. Sunt modificate simultan si ponderile celorlalte noduri (care initial au fost stabilite aleator), efectul global fiind deplasarea acestora pe pozitii care sa permita cea mai buna reprezentare modelului de intrare.
Modelul retelei neurale probabilistice (PNN - Probabilistic Neural Network) este tot un sistem de clasificare, care incearca sa delimiteze granite intre diferitele categorii. Modelul impune ca datele de intrare pentru instruire sa fie cu adevarat reprezentative pentru anumite clase.
Reteaua are doua nivele ascunse (Figura III.23). Primul nivel contine un nod dedicat pentru fiecare model al instruii, iar cel de al doilea contine cate un nod dedicat pentru fiecare clasa. Conexiunile intre nodurile de pe primul nivel si nodul corespunzator clasei, situat pe al doilea nivel, se modifica in timpul instruirii PNN prin utilizarea unor estimari ale distributiilor de probabilitate pe clase, fiecare noua intrare fiind clasificata in acord cu media ponderata a celor mai potrivite exemple de instruire. Instruirea este foarte rapida.
Modelul retelei cu functii radiale fata de de baza (RBF - Radial Basis Function), dezvoltat de M.J.D. Powell, poate fi utilizat atat pentru clasificare cat si pentru aproximare functionala. Reteaua consta in trei nivele. Nodurile de iesire sunt combinatii liniare ale unor functii calculate de catre nodurile nivelului ascuns, conform figurii 10.24.
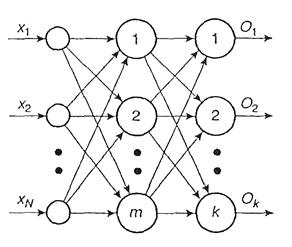
Figura III.24. Modelul retelei cu functii radiale fata de baza
Neliniaritatile de tip gaussian ale acestor functii produc la stimuli un raspuns nenul semnificativ numai atunci cand intrarile sunt localizate intr-o mica regiune din spatiul de intrare. De aceea acest model se mai numeste retea cu localizare receptiva a campurilor. O functie gaussiana are forma:
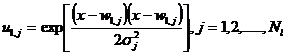 (3.113)
(3.113)
unde u1,j este iesirea nodului i de pe primul nivel, x este modelul de intrare, w1,j este vectorul ponderilor pentru nodul j de pe primul nivel sj este parametrul de normalizare pentru nodul i, iar Nl este numarul nodurilor de pe primul nivel. Iesirea retelei va fi:
![]() (3.114)
(3.114)
unde Oj si w2,j sunt vectorii iesirii si ai ponderilor pentru nodul de iesire j, u1 este vectorul iesirilor de pe primul nivel, iar N2 este numarul nodurilor de iesire.
Fiecare nod produce o iesire identica pentru intrari cu o aceeasi distanta radiala fata de nucleul (baza) wij, de unde si numele modelului. Intreaga retea formeaza o combinatie liniara de functii care executa transformari din RN1 in RN2.
Algoritmul de instruire RBF are trei pasi:
Initiaza instruirea nivelului ascuns cu un algoritm nesupervizat.
Continua instruirea nivelului de iesire cu un algoritm cu supervizare.
Pentru acordul fin al retelei, aplica simultan nivelelor ascuns si de iesire o instruire cu supervizare.
Modelele cognitron si neocognitron au fost dezvoltate de Fukushima. Neocognitronul este o retea ierarhica multistrat in cascada. Neuronii de pe fiecare nivel au intrari analogice de tip rampa pozitiva ce porneste din 0. Reteaua poate fi instruita pentru a recunoaste seturi de modele. Invatarea se face cu sau fara supervizare. In timpul instruirii, neuronii de pe stratul inferior extrag trasaturile elementare ale modelului, care sunt transmise din strat in strat, avand loc o integrare graduala a acestor caracteristici. Pe stratul superior de iesire fiecare neuron raspunde numai la un model specific. Calculele se bazeaza pe instruirea competitiva, utilizandu-se combinatii de dinamici contributive si inhibitorii. Procesul de extragere a trasaturilor, numit si codificare progresiv-redundanta a caracteristicilor elementare, este inspirat din procesele biologice de recunoastere a formelor. De aceea neocognitronul poate fi desemnat ca o retea de recunoastere a modelelor, indiferent de dimensiunea sau translatia acestora.
Modelul masinii de invatat Boltzmann se bazeaza pe o tehnica de optimizare simpla. Ciclul de instruire urmareste o ajustare progresiva a ponderilor in doua faze alternative (pozitiva si negativa). In timpul fazei pozitive, intregul set de modele intrare-iesire este incapsulat in perechi de noduri, iar neuronii ascunsi sunt constransi sa evolueze dupa dinamici Metropolis [124]. Dupa ce sistemul atinge un echilibru, el este mentinut in aceasta stare cateva cicluri, pentru stabilirea conexiunilor. In faza negativa sunt incapsulate numai intrarile.
In ultimii ani au mai fost propuse modelul energetic restrans Coulomb (RCE - Restricted Coulomb Energy), care se bazeaza pe o arhitectura directa cu trei nivele ce respecta legile lui Coulomb, modelul Culhertson - o retina artificiala utilizata pentru recunoasterea vizuala a modelelor, proiectul Encephalon ce se bazeaza pe memoriile holografice si principiul lui Hebb sau reteua neurala celulara (CNN - Cellular Neural Network), care se bazeaza pe automatul celular - o retea in care fiecare nod este conectat numai cu cele invecinate.
Mentionam aici si doua circuite electronice integrate, care implementeaza ANN. Procesorul VLSI tip retea neurala probabilistica (pRAM256) este un circuit specializat care are 256 neuroni reconfigurabili. Circuitul neural accelerator (NAC) compus din 16 elemente de procesare pe 10 biti, care pot fi configurate diferit si care pot efectua 500 milioane de operatii pe secunda, permitand implementarea unei varietati de modele neurale - directe sau cu reactie - cu unul sau doua nivele ascunse.
|
Politica de confidentialitate |
| Copyright ©
2025 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |
