
UTILIZAREA MATEMATICII CA INSTRUMENT DE LUCRU LA ELABORAREA MODELELOR IN VEDEREA FUNDAMENTARII METODELOR DE ANALIZA SI EVALUARE A RISCURIULOR PROFESIONALE
1. Notiuni de matematica fuzzy
Teoria spatiilor fuzzy este de data relativ recenta si conceptul de "multimi fuzzy" (multimi vagi, imprecise) a fost introdus in 1965 de L. A. Zadeh (Univ. Berkley California SUA) pentru a defini o clasa de fenomene descrise imprecis sau vag.
Spre deosebire de teoria probabilitatilor si statistica matematica care se ocupa cu studiul incertitudinii aleatoare obiective, multimile fuzzy sunt generate de incertitudinea aleatoare subiectiva, care opereaza cu notiuni imprecise ca nuante ce descriu starea unui sistem.
Fenomenul aleator la multimile fuzzy, rezulta din nesiguranta in ceea ce priveste apartenenta sau neapartenenta unui obiect sau eveniment la o clasa, in timp ce la fenomenele fuzzy exista "grade de apartenenta" intre apartenenta completa si nonapartenenta.
In teoria si aplicatiile multimilor fuzzy mai sunt intalnite si definite alte tipuri de relatii de tip grad de apartenenta, dintre un element si multimea din care face parte, cum ar fi: "gradul de atractivitate", "gradul de utilitate", "gradul de importanta".
In general matematica fuzzy este o disciplina legata de stiintele despre om si mediul sau si constituie un pas important ca metoda, de abordare a subiectivismului in cunoasterea noastra si in aprecierea interdependentelor cu mediul.
Numim multime FUZZY (vaga), o multime de elemente X caracterizate printr-o proprietate A si unde un element oarecare x I X, are un anumit grad de apartenenta la proprietatea A.
Folosind un limbaj imprecis, putem spune ca, pentru o multime fuzzy (vaga), nu exista o tranzitie de la apartenenta la nonapartenenta unui element la o proprietate.
Modelul teoriei multimilor vagi este gasit in logica continua, spre deosebire de teoriile clasice care au drept model logica bivalenta.
Daca mA (x) reprezinta functia ce exprima gradul de apartenenta la proprietatea A si poate fi apreciata cu valori x I 0 si 1 , atunci perechile de valori aflate in corespondenta bijectiva, reprezinta o multime fuzzy, iar functia de apartenenta poate fi definita matematic printr-o functie algebrica, formula sau algoritm.
Deci :
mA(x) = 1 x I A (1)
mA(x) = 0 x A (2)
Exemplu Fie multimea nuantelor de gri (ca un amestec de alb cu negru), o proprietate, iar multimea obiectelor gri o multime de elemente, fiecarui obiect x din aceasta multime, i se poate asocia un anumit "grad de negru" sau "grad de gri" ca o functie de apartenenta la proprietatea multimii respective.
Aceasta asociere se poate face subiectiv, in functie de gradul de percepere a nuantelor de gri de catre un subiect, si poate fi exprimata individual printr-o valoare cuprinsa intre 0 si 1, unde valoarea 1 defineste negrul absolut si 0 defineste lipsa negrului sau albul absolut.
Se supune in acest caz ca multimea obiectelor gri si multimea valorilor atribuite nuantelor, reprezinta un set fuzzy
Tabel nr. 1
|
nuanta | |||||||||||
|
x | |||||||||||
|
mA(x) |
In principiu daca apreciem limbajul ca sursa de informatii, orice afirmatie cu caracter imprecis (in sens clasic) se poate asocia cu o multime fuzzy.
Este convenabil sa se opereze cu multimi fuzzy normale, care au proprietatea:
maxx mA(x) = 1, x I A (3)
Daca aceasta conditie nu poate fi satisfacuta, atunci se normalizeaza gradele de apartenenta prin raportarea fiecarui grad de apartenenta mA(x) la maxx mA (x).
Operatiile uzuale din teoria clasica a multimilor (reuniune, intersectie, imagine, complementarietate, produs algebric etc.) se pot reface in cazul multimilor fuzzy, cu termenii functiilor de apartenenta.
Relatii intre multimile vagi
(1) Egalitatea in sens nevag a doua multimi vagi - Doua multimi vagi A si B sunt egale daca:
mA(x) = mB(x) (4)
(2) Egalitatea in sens vag a doua multimi vagi - Doua multimi vagi sunt egale daca este satisfacuta relatia:
mA(x) - mB(x) e ) x I E (5)
unde:
e - reprezinta o abatere admisibila din punct de vedere practic.
E - reprezinta o proprietate comuna multimilor A si B.
(3) Incluziunea nevaga a doua multimi vagi o multime vaga A este inclusa intr-o multime B, daca A B, daca:
mA(x) mB(x), ( ) x I E (6)
(4) Incluziunea vaga a doua multimi vagi o multime vaga A este inclusa in sens vag intr-o multime B, daca este satisfacuta relatia:
mA(x) < mB(x), ( ) x I E (7)
(5) Multime complementara a unei multimi vagi - o multime A* este complementara lui A, daca este satisfacuta relatia :
mA*(x) = 1 - mA(x) (8)
(6) Intersectia in sens nevag a doua multimi vagi intersectia nevaga a doua multimi vagi A B, este o submultime C inclusa in sens nevag in A si B la care gradul de apartenenta al unui element x este egal cu gradul de apartenenta maxim posibil.
Sunt satisfacute restrictiile:
A B = C
mC(x) mA(x)
mC(x) mB(x)
mC(x) mA B(x) = min mA(x), mB(x) (8)
(7) Intersectia in sens vag a doua multimi vagi intersectia vaga a doua multimi vagi A si B, este o submultime inclusa in sens vag in cele doua, la care un element are gradul de apartenenta egal, cu gradul de apartenenta in sens vag maxim.
mC(x) mA B(x) min mA(x), mB(x) (9)
(8) Reuniunea nevaga a doua multimi vagi - Reuniunea nevaga a doua multimi A si B vagi, este o multime M care prezinta sau proprietatea descrisa de multimea A sau proprietatea descrisa de multimea B, si unde gradul de apartenenta al unui element x este egal cu cel mai mic grad de apartenenta posibil.
mM(x) = mA B(x) = max mA(x), mB(x)] (10)
(9) Reuniunea vaga a doua multimi vagi - Reuniunea vaga a doua multimi vagi este o multime M, care prezinta sau o parte din proprietatea multimii A sau o parte din proprietatea multimii B , si unde un element x are un grad de apartenenta egal cu cel mai mic grad de apartenenta posibil.
mm (x) = ma b (x) max mA(x), mB(x)], deci
mA B(x) - max mA(x), mB(x) e (11)
unde:
e - este o abatere acceptabila.
(10) Produsul algebric nevag a doua multimi vagi - Produsul algebric nevag AxB , a doua multimi vagi A si B , este o multime vaga a carei caracteristici provin din produsul caracteristicilor multimilor A si B, iar gradul de apartenenta al unui element x la aceasta multime este definit de relatia:
mA B(x) = mA(x) mB(x) (12)
(11) Produsul algebric vag a doua multimi vagi - Produsul algebric nevag AxB, a doua multimi vagi A si B, este o multime vaga a carei caracteristici provin din produsul caracteristicilor multimilor A si B, iar gradul de apartenenta al unui element x la aceasta multime este definit de relatia:
mA B(x) mA(x) mB(x) (13)
(12) Suma algebrica nevaga a doua multimi vagi - Suma algebrica A+B a doua multimi vagi A si B, este o multime vaga a carei grade de apartenenta satisfac relatia:
mA+B(x) = mA(x) + mB(x) - mA(x) mB(x) (14)
Suma algebrica vaga a doua multimi vagi - Suma algebrica A+B a doua multimi vagi A si B, este o multime vaga a carei grade de apartenenta satisfac relatia:
mA+B(x) mA(x) + mB(x) - mA(x) mB(x) (15)
Operatiile cu multimi fuzzy (vagi) pot fi combinate si cu operatii cu multimi nevagi, cu algebre Boolene, cu remarca: de a fi pastrat sensul conceptual al rezultatului;
VAG cu VAG = VAG, NEVAG cu VAG = VAG (16)
In concluzie, o multime fuzzy poate fi precis definita daca fiecarui element x i se asociaza o functie de apartenenta mA(x) la o proprietate ce caracterizeaza multimea , care are valori cuprinse intre 0 si 1 si care reprezinta gradul sau de apartenenta la acea proprietate.
Preocuparile teoretice si practice s-au concentrat pentru definirea gradului de apartenenta, astfel:
Gradul de apartenenta poate fi definit:
- cu ajutorul unor formule matematice
- printr-un tabel de valori
- printr-un algoritm recursiv
- prin functii de alte functii de apartenenta etc.
In functie de modul de aplicare al teoriilor matematicii fuzzy, functiile care reprezinta gradul de apartenenta au fost alese in concordanta cu o proprietate a sistemului analizat, de exemplu:
Pentru probleme de risc literatura de specialitate propune o functie exponentiala de tipul:
EXP(-x) sau e(-x) (17)
Pentru probleme de repartitie se utilizeaza functii lineare crescatoare sau descrescatoare sau algoritmi recursivi de programare dinamica
Sisteme informationale si decizii de tip fuzzy
Abordarea sistemica a problemelor complexe este o metoda utilizata pentru atingerea unor parametrii sau scopuri dorite si se realizeaza in principal prin doua metode: analiza (cand este necesar sa se prevada comportarea unui sistem specificat) si sinteza (cand este necesar sa se construiasca un sistem cu o comportare specificata).
In cazul real sistemele sunt insuficient de bine definite, sau au o structura complexa, cand este dificil sa se faca o analiza precisa, acesta este cazul sistemelor din stiintele economice, stiintele sociale, sau denumite in general 'soft sciences'.
Motivul ineficientei metodelor matematice clasice, in analiza si sinteza sistemelor de 'soft sciences' este legat de nereusita in a manevra conceptele imprecise, vagi, care apar din lipsa de tranzitie clara de la apartenenta la o anumita clasa, la nonapartenenta la aceeasi clasa.
Imprecizia este legata de complexitatea sistemului, care atunci cand depaseste un anumit prag, nu se mai pot face afirmatii precise despre comportarea acestuia.
Spre exemplificare in legatura cu preocuparile din cadrul tezei: sistemul de munca si legat de acesta sistemul securitatii si sanatatii in munca, este un sistem de tip 'soft science', complex, care din punct de vedere conceptual are toate caracteristicile unui sistem fuzzy, imprecizia fiind prezenta datorita imposibilitatii modelarii lui astfel incat sa poata fi caracterizat pentru toate starile interne.
In concluzie un proces de decizie fuzzy, tine seama de multimea scopurilor, multimea restrictiilor si multimea alternativelor (variantelor), care pot fi de natura fuzzy sau nonfuzzy, la care se asociaza un criteriu de optim, pentru alegerea variantei preferate
In cazul existentei mai multor criterii de optim se poate stabili gradul de apartenenta al variantelor analizate la fiecare criteriu de optim luat independent si in final se alege varianta cu gradul de apartenenta maxim la valorile de optim.
Particularizand demersul teoretic, la problemele de analiza si evaluare a riscului, este usor de imaginat situatia in care sunt necunoscute precis starea de securitatea muncii, cat si probabilitatea de aparitie a situatiilor de risc, iar in acest caz se disting trei categorii de parametrii care intervin la procesul de decizie, si anume:
parametrii cunoscuti
parametrii necunoscuti
parametrii imprecisi (cu valori intr-un anumit interval).
Procesul de luare a unei decizii in aceasta situatie, care este mai aproape de realitatea practica, este un proces subiectiv, iar alegerea variantelor optime de decizie se face cu ajutorul unor criterii subiective.
Fazele tipice ale algoritmului de modelare fuzzy sunt urmatoarele:
Descrierea bazei euristice a problemei
Alegerea variabilelor de intrare-iesire
Stabilirea multimilor fuzzy si a valorilor lingvistice asociate acestora
Intocmirea bazelor de reguli pentru inferente fuzzy
Stabilirea procedeelor de fuzificare, realizarea interferentelor logice si de defuzificare a iesirilor
Baza de reguli pentru inferente Fuzzy (Baza de Reguli Fuzzy-BRF) se deduce din datele privind punctele de functionare ale sistemului analizat. Aceste date sunt accesibile prin monitorizarea sistemului existent in functiune, a unuia similar sau pe baza unui model analitic. Sistemele fuzzy prezinta o stransa interdependenta intre functiile de apartenenta ale variabilelor din sistem si BRF. In esenta, regulile fuzzy se definesc in functie de gradul de suprapunere a domeniilor fuzzy intrare-iesire peste campul punctelor de functionare a sistemului. Prin urmare, o BRF se construieste prin punerea in legatura (corelare) logica a marimilor fuzzy asociate variabilelor de iesire, cu multimile fuzzy ale variabilelor de intrare.
Sistemele fuzzy prelucreaza informatia dupa o filozofie proprie, care in principial se desfasoara conform fluxului urmator:
T (fuzificare) T (inferente) T T (compunere) T (defuzificare) T (18)
Fiecare veriga a lantului de prelucrare poate fi realizata prin diferite tehnici si procedee. Unele metode dau rezultate mai bune decat altele, fapt confirmat in aplicatii, calitatea rezultatelor fiind in functie de experienta si flerul cercetatorului.
Caracterul fuzzy al evaluarilor si al valorilor utilizate
Criteriile si metodele de evaluare s-au dezvoltat in paralel cu conceptia generala despre risc si securitate in munca, precum si cu teoriile privind geneza accidentelor de munca si a bolilor profesionale.
Caracteristica generala comuna a metodelor de evaluare sau estimare a securitatii in munca, indiferent de momentul in care se face evaluarea (preaccident sau postaccident), este aceea ca se scoate in evidenta ca o modalitate de apreciere a situatiei, aspectul calitativ si mai difuz cel cantitativ.
Din punct de vedere al modului de exprimare a rezultatului final, neexistand o unitate de masura cantitativa a securitatii in munca, metodele de evaluare dau o apreciere bazata pe nuante, deci un caracter vag, imprecis (fuzzy), ca mod de cuantificare a nivelului de risc / securitatea muncii.
Din
punct de vedere al naturii datelor si informatiilor, care intra
intr-o metoda de evaluare, se pune in evidenta o
inconsecventa matematica privind modul de tratare a acestor
variabile, prezentata in tabelul 2.
Tabel nr. 2
|
Nr. |
Caracter informatii |
Tip variabile |
Mod de tratare matematica |
|
PRECISE (masurabile) |
CERTE |
statistic |
|
|
IMPRECIZIE OBIECTIVA |
INCERTE |
probabilistic |
|
|
IMPRECIZIE SUBIECTIVA |
IMPRECISE |
fuzzy |
Variabilele care apar in tabelul 6 constituie datele de intrare, (lNPUT) pentru procesul de evaluare si procesul de decizie, iar problemele care apar sunt cele de agregare si tratare matematica in functie de obiectivul si restrictiile impuse deciziei.
Daca se trateaza ca exemplu procesul de evaluare a riscului securitatii in munca, din punct de vedere sistematic, se disting urmatoarele etape prezentate in figura 1.
METODA DE EVALUARE


INPUT OUTPUT
Fig. 1 Procesul de evaluare a riscului/securitatii in munca
Din analiza modelului prezentat in figura 10 - rezulta ca oricat de riguroasa ar fi metoda de evaluare a riscului/securitatii in munca, datele de intrare in ansamblul lor au un caracter predominant subiectiv, fiind apreciate, colectate si introduse in sistem de catre om, iar decizia finala este pur subiectiva, ea apartinand omului, deci caracterul subiectiv predomina, iar imprecizia ca incertitudine subiectiva, determina caracterul vag (fuzzy) al acestor evaluari.
In general tipurile de informatii si de variabile utilizate in analiza si evaluarea riscului, se pot incadra in urmatoarele categorii:
EXACTE - rezultat al masurarii unor parametrii sau caracteristici fizico-chimice, (CERTITUDINE)
PROBABIEISTICE - rezultate din statistica datelor exacte sau prin estimarea unor situatii prin probabilitati, (INCERTITUDINE)
FUZZY - prin cuantificarea subiectivismului uman (IMPRECIZIE)
HIBRIDE - prin combinarea tipurilor de mai sus
Exista metode care dau posibilitatea ca tipurile de informatii si de variabile, utilizate la o evaluare, sa fie prelucrate intr-un model matematic sau cu o metoda de evaluare, sansa succesului unor astfel de prelucrari fiind prezentata in tabelul
Tabel nr.3
Succesul prelucrarii datelor de diferite proveniente
|
INFORMATIE/ VARIABILA |
EXACTA |
PROBABILISTICA |
FUZZY |
HIBRIDA |
|
DETERMINISTA |
distorsiune |
distorsiune |
distorsiune |
|
|
PROBABILISTICA |
incert |
distorsiune |
distorsiune |
|
|
FUZZY |
incert |
distorsiune |
distorsiune |
|
|
HIBRIDA |
incert/bine |
bine |
bine |
Din studiul datelor prezentate in tabelul 3 se remarca posibilitatea combinarii variabilelor hibride, cu cele exacte, probabilistice sau fuzzy, care intr-un model matematic adecvat, ales corespunzator tipului de variabile, pot fi apoi prelucrate si interpretate.
In general metodele de evaluare folosite in analiza de risc, fie ca evaluarea se face direct sau indirect, nu utilizeza decat modele matematice de tip statistic si algebric pentru selectarea datelor si agregarea lor.
Metodele bazate pe teoria fiabilitatii sunt acele care utilizeaza instrumente matematice specifice, cum ar fi: programarea liniara, teoria grafurilor s.a., dar nici acestea nu lucreaza cu date de natura hibrida sau fuzzy.
Orice problema de evaluare prezinta un set de rezultate, care implica abordarea unei conduite decizionale, deci este necesara adoptarea unei decizii.
Figura 2 prezinta posibilitatile de adoptare a unei decizii, tinand cont de tipul de date prelucrate si de tipul de obiective, de restrictiile specifice problemei de rezolvat.
Pentru exemplificarea caracterului evaluarilor utilizate in analiza de risc, se observa ca datorita datelor de intrare introduse in model, cu un caracter care este predominant fuzzy, conditiile in care se adopta o decizie in acest domeniu sunt cele de incertitudine vaga sau fuzzy (imprecizie).
De ce metode de evaluare cu variabile fuzzy ?
Daca la utilizarea practica a unei metode de analiza si evaluare a riscului intr-un sistem de munca, aportul evaluarilor si al grupului de decizie finala, introduc in metoda imprecizia ca o manifestare a incertitudinii, atunci se impune cuantificarea si tratarea matematica unitara a subiectivismului uman.
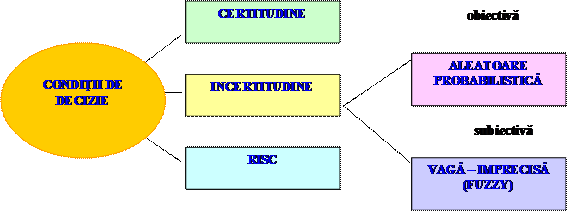
Fig. 2 Conditii pentru adoptarea unor decizii
Matematica fuzzy ofera instrumentul care face posibila cuantificarea incertitudinii subiective, utilizand un set de posibilitati de cuantificare vagi, care sa exprime gradul de imprecizie.
Figura 3 prezinta o modalitate de tratare matematica si de masurare a impreciziei, de asemenea fiind prezentate de asemenea si posibilitatile de cuantificare fuzzy, utilizand niste functii de apartenenta, denumite gradul de apartenenta la o proprietate, gradul de importanta, gradul de atractivitate, ca un set de caracteristici ce pot fi evaluate si apreciate de catre subiectul uman. Continutul acestui set de caracteristici nu este strict delimitat, el depinde de experienta, cunostintele profesionale, modul de perceptie a realitatii inconjuratoare, astfel incat fiecare subiect uman are o alta parere.
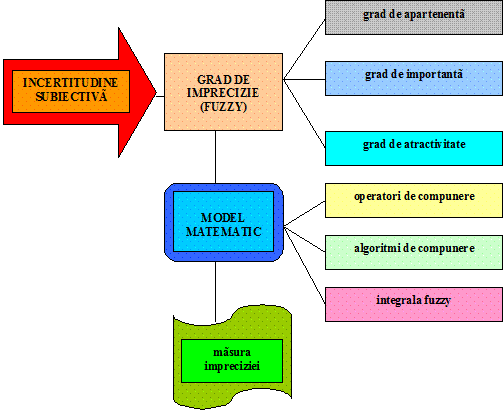
Fig.3 Cuantificarea gradului de incertitudine subiectiva (imprecizie)
Din analiza mai atenta a figurii 3 se mai pot desprinde urmatoarele aspecte:
operatorii de compunere se utilizeaza la probleme de agregare directa a datelor imprecise sau in cadrul unor modele matematice, si pot fi formule matematice sau functii;
algoritmii matematici se utilizeaza la modelarea unor fenomene cu caracter imprecis, datorat necunoasterii efectelor cu influenta asupra datelor finale.
In situatia unor probleme care utilizeaza 'patternuri' sau puncte de identificare, care pot fi apreciate subiectiv prin valori imprecise (fuzzy), pentru obtinerea formei si caracterului unei suprafete compusa dintr-o multime de puncte de identificare, se utilizeaza integrala fuzzy
Orice model matematic care utilizeaza date imprecise, duce la un rezultat care este definit ca masura impreciziei
2. Elemente probabilistice de baza utilizate in securitatea sistemelor
In securitatea sistemelor, probabilitatile sunt utilizate pentru a evalua riscurile direct asociate unui pericol identificat si riscurile reziduale rezultate in urma aplicarii unei actiuni de diminuare a riscului. Desi aceste probabilitati sunt in general punctuale, evaluarea lor necesita cunoasterea, totala sau in parte, a distributiei de probabilitate din care au rezultat.
Dupa natura variabilei aleatoare - discreta sau continua - care intervine in modelarea fenomenului periculos sau a actiunii de diminuare a riscului, se va avea de-a face cu distributii de probabilitate discrete sau continue.
Legea de probabilitate a unei variabile aleatoare X este definita global prin densitatea sa sau prin functia de repartitie notate respectiv f(x) sau F(x) astfel ca:
Pr(X = x) = f (x)dx (19)
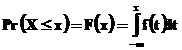 (20)
(20)
unde x este o valoare data a variabilei aleatorii X, numita de asemenea realizare sau quantila de X care apartine intervalului D de definire a lui X.
In acest sens:
- F (x) este numita functie de repartitie la nedepasire
- Functia complementara la 1 notata G(x) =1 - F(x) = Pr (X>x) este numita functie de repartitie la depasire.
Statisticile de ordine
Fie un esantion de n observatii independente (x1,x2,,xn), corespunzatoare celor n realizari ale variabilei aleatoare X reprezentand un parametru de risc.
Pentru un numar infinit de esantioane de aceeasi dimensiune n, cu valorile de observatii ordonate crescator, valorile de rang i au o distributie statistica a quantilei xi care este a priori functie de marimea esantionului si se numeste functie de repartitie empirica a quantilei xi, utilizata pentru ajustarea esantionului la o lege de probabilitate teoretica a priori si reciproc.
Legea de probabilitate a quantilei de un anumit ordin
Fie o valoare x a variabilei aleatoare, astfel incat in codul de esantion sa existe:
(i-1) valori independente, inferioare lui x (evenimentul E1)
(n-i) valori independente superioare lui x (evenimentul E2)
1 valoare xi cuprinsa in intervalul [x-dx, x+dx], unde dx este infinit de mic (evenimentul E3)
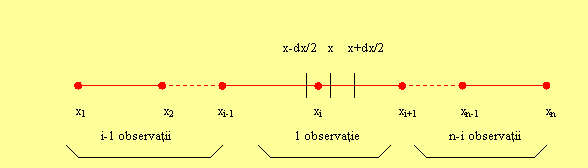
Plecand de la aceste consideratii, vom determina legea de distributie a quantilei de ordin (rang) i din intervalul [x-dx, x+dx].
Consideram urmatoarele ipoteze:
cele n realizari independente xi ale variabilei aleatoare x sunt echivalente cu o realizare xi de n variabile aleatoare X1
a priori, cele n realizari xi sunt echiprobabile, altfel spus, functia de repartitie a priori Fi corespunzatoare fiecarei variabile aleatoare independente Xi este o lege continua si uniforma pe intervalul [01] notata cu F
Pentru n si i fixate, evenimentele E1, E2 si E3 precizate anterior sunt bine identificate iar probabilitatile lor P1, P2 si P3 sunt usor calculabile.
Intr-adevar:
P1 = Pr (E1) = Pr (X<x) = Pr ( ∩(Xj<x))
j = 1,i-1
Dar realizarile (i-1) sunt independente, de unde:
P1 = ∏ Pr (Xj<x)
= ∏ Fj(x) = (F(x))i-1 (22) j = 1,i-1
De asemenea:
P2
= Pr (E2) = Pr (X>x) = Pr (
∩(Xj>x)) (23) j = i+1,n
P2 = ∏ Pr (Xj>x)
= ∏ (1-Pr (Xj<x)) = ∏ (1-Fj(x))
= (1-F(x))n-i (24) j = i+1,n
Insa
realizarile (n-i) sunt independente, de unde:
Pr
(x-dx/2<X>x+dx/2) = fi(x)dx (25)
In final:
Se observa ca:
(i-1)! moduri de a observa E1 corespunzator lui i-1 permutari posibile ale valorilor i-1 inferioare lui x
(n-i)! Moduri de a observa E2 corespunzator lui n-i permutari posibile ale valorilor n-i superioare lui x
1 singur mod de a observa E3
Prin urmare, evenimentul E(E1, E2, E3), ca E1 sa se produca de (i-1)!ori, E2 sa se produca de (n-i)!ori si E3 sa se producao data, este distribuit dupa o lege multinomiala.
Daca Gi este functia sa de repartitie, atunci:
![]() (26)
(26)
![]() (27)
(27)
![]() (28)
(28)
![]() (29)
(29)
- Valoarea medie
![]() (30)
(30)
- Modul
![]() (31)
(31)
- Mediana
Se obtine rezolvand ecuatia urmatoare:
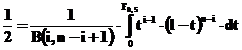 (32)
(32)
Solutia ei este:
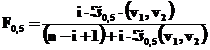 (33)
(33)
unde ![]() o,5 (v1 , v2) este
mediana functiei lui Fisher-Snedecor la v1 si v2
grade de libertate cu v1 =2i si v2=2(n-i+1) .
o,5 (v1 , v2) este
mediana functiei lui Fisher-Snedecor la v1 si v2
grade de libertate cu v1 =2i si v2=2(n-i+1) .
Pentru valorile lui n superioare lui 20, se poate utiliza aproximarea propusa de Chegodayev (1955):
![]() (34)
(34)
a carei eroare maxima este inferioara lui 1% oricare ar fi n si care se reduce cand rangul i se apropie de n/2.
Alti autori au propus pentru n expresii diferite pentru frecventa empirica asociata quantilei de rang i dar cu o precizie mai mica, respectiv:
- Hazen (1930):
![]() (35)
(35)
- Weibull (1939):
![]() , medie a distributiei (36)
, medie a distributiei (36)
- Tukey (1962):
![]() (37)
(37)
- Gringorten (1963):
![]() (38)
(38)
Varianta
![]() (39)
(39)
Calculul caracteristicilor statistice empirice
Plecand de la n observatii xi , se poate calcula pentru i=1 la n:
![]() si
si ![]() (40)
(40)
care permite sa se determine parametri empirici urmatori:
media ![]()
varianta si abaterea (ecart)-tip si
coeficientul de asimetrie ![]()
coeficientul de aplatizare g
ai caror algoritmi de calcul sunt dati mai jos:
- Media
![]() (41)
(41)
- Varianta si abaterea (ecart) - tip
![]() (42)
(42)
![]() (43)
(43)
- Coeficientul de variatie
![]() , pentru
, pentru![]() (44)
(44)
este un parametru de dimensiune, care exprima dispersia relativa in jurul mediei.
Observatii:
Coeficientul de variatie este deci cu atat mai mic cu cat dispersia absoluta in jurul mediei este mai mica.
Pentru un numar n de observatii, coeficientul de variatie de esantionare
![]() este distribuit dupa
inversul unei legi de tip Student descentrata aproximativ la
coeficientul
este distribuit dupa
inversul unei legi de tip Student descentrata aproximativ la
coeficientul ![]() . Ceea ce se poate scrie:
. Ceea ce se poate scrie:
![]() (45)
(45)
unde:
- v=n-1 este numarul de grade de libertate
- si ![]() descentrarea in care g este coeficientul de
variatie teoretica pe care o
inlocuieste in estimari prin coeficientul de variatie calculat.
descentrarea in care g este coeficientul de
variatie teoretica pe care o
inlocuieste in estimari prin coeficientul de variatie calculat.
Calculele
lui ![]() si
si ![]() permit pentru i=1 sa se obtina parametrii urmatori :
permit pentru i=1 sa se obtina parametrii urmatori :
d) Coeficientul de asimetrie g al lui Fisher
![]() (46)
(46)
cu ![]() (47)
(47)
si ![]() (48)
(48)
Reguli de utilizare:
- daca ![]() , distributia este etalata la dreapta;
, distributia este etalata la dreapta;
- daca ![]() , distributia este etalata la stanga;
, distributia este etalata la stanga;
- daca ![]() , distributia nu este in mod obligatoriu
simetrica, dar cazul contrar este
adevarat .
, distributia nu este in mod obligatoriu
simetrica, dar cazul contrar este
adevarat .
e) Coeficientul de aplatizare g al lui Fisher
![]() (49)
(49)
cu
![]() (50)
(50)
Reguli de utilizare:
daca ![]() , distributia este mai putin
aplatizata decat distributia Normala pentru aceeasi medie
si abatere (ecart) - tip;
, distributia este mai putin
aplatizata decat distributia Normala pentru aceeasi medie
si abatere (ecart) - tip;
daca ![]() , distributia este mai aplatizata
decat distributia normala.
, distributia este mai aplatizata
decat distributia normala.
Observatie :
Acesti doi ultimi parametri servesc la evaluarea formei legii de distributie a esantionului de xi .
Pentru n suficient de mare, incertitudinile asupra lui g si g sunt distribuite dupa legile lui Gauss definite dupa cum urmeaza :
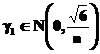 (51)
(51)
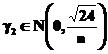 (52)
(52)
Ajustarea unei legi de probabilitate la un esantion
Fiind dat un esantion de marime n notat (xi) pentru care, in vederea estimarii caracteristicilor statistice empirice, se determina legea sa de distributie statistica utilizand hartie speciala.
Aceasta hartie permite in general sa se reprezinte pe abscisa valorile observate xi si pe ordonata o anamorfoza a functiei de repartitie sau a variabilei reduse specifica legii de probabilitate asociata.
Transformarea liniarizeaza pe aceasta hartie suita de quantile obtinute din legea luata in considerare si prin aceasta suita de puncte observate.
Pe aceasta hartie, daca esantionul este distribuit dupa o lege normala, reprezentarea sa este o dreapta numita "dreapta lui Henry", care este, prin constructie, anamorfa functiei de repartitie a legii lui Gauss.
Ajustarea consta in plasarea pe hartie speciala a datelor observate asociate la frecventa lor empirica cumulata. Daca punctele plasate pe hartie sunt aliniate, se poate deduce ca esantionul este distribuit conform legii de probabilitate asociata cu hartia. Un test de verificare permite masurarea gradului de incredere al acestei ipoteze.
Nu este echivalent:
sa se ajusteze o lege de probabilitate la un esantion
sa se ajusteze un esantion la o lege de probabilitate
Intr-adevar:
in primul caz, legea de probabilitate nu este cunoscuta si parametri sai sunt dedusi din caracteristicile statistice ale esantionului
in al doilea caz, legea de probabilitate este cunoscuta si prin aceasta chiar parametrii sai, independent de esantionul caruia se doreste sa i se verifice adecvarea la lege
Frecventa empirica cumulata
Frecventa empirica cumulata sau
frecventa de esantionare a observatiei de rang i retinuta (dupa aranjarea
esantionului in ordine crescatoare) este mediana cuantilei de ordin
i, ![]()
Pentru n>20 se poate utiliza aproximatia lui Chegodaev:
![]() (53)
(53)
Procedura de ajustare
Dupa aranjarea in ordine crescatoare a esantionului, se noteaza (xi) noul esantion.
Procedura de ajustare presupune parcurgerea urmatorilor pasi:
Se asociaza la fiecare xi frecventa empirica a quantilei de rang i si se formeaza n cupluri (xi, Fn(i))
Se plaseaza punctele n pe hartie speciala
Se verifica alinierea punctelor
Daca punctele n sunt aliniate, se poate admite ca esantionul este distribuit dupa legea asociata hartiei speciale. Pentru a consolida aceasta ipoteza, se realizeaza atunci un test de verificare.
Teste de verificare statistica
Testele de verificare pot raspunde la doua intrebari diferite:
Q1 : O lege de distributie fiind cunoscuta (prin forma sa matematica si valorile numerice ale parametrilor) si descriind in mod perfect populatia P, care este probabilitatea ca esantionul (x1, . xn) sa poata fi considerat ca fiind extras din populatia P ?
Q2 : O lege de distributie fiind definita prin forma sa matematica aleasa a priori si prin valorile numerice ale parametrilor estimati dupa esantionul (x1 , . xn ),care este probabilitatea pentru ca legea de distributie sa reprezinte efectiv populatia P al carei esantion este reprezentativ a priori ?
In practica, la intrebarea Q2 trebuie sa raspunda testele de adecvare.
Plecand de la esantionul de observatii (x1 , . xn), quantila x0= (x1 , . xn) a functiei discriminante careia i s-a determinat forma matematica si care este ea insasi o lege de probabilitate de densitate f a variabilei aleatoare X.
Se testeaza ipoteza H0 ca diferentele intre distributia de esantionare si distributia teoretica sa poata fi atribuite hazardului.
Ipoteza
de buna adecvare va fi respinsa cu riscul a daca x0 este
in regiunea critica ![]() cum este vizualizat in schema urmatoare:
cum este vizualizat in schema urmatoare:
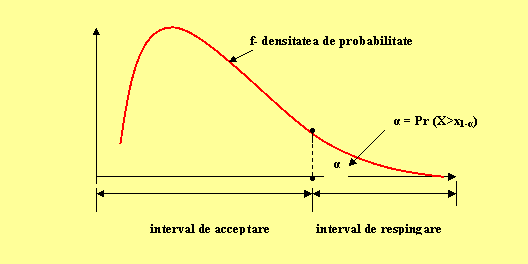
Fig. 4
Practic:
daca x0 x1-a, atunci se concluzioneaza ca diferentele intre esantion si legea teoretica sunt datorate hazardului si se accepta ajustarea la pragul de risc a
daca x0>x1-a , se concluzioneaza ca un factor necunoscut intervine in diferentele care nu mai sunt datorate hazardului si se respinge ajustarea la pragul de risc a
Dupa marimea n a esantionului, doua teste neparametric (independente de legea teoretica) permit sa se valideze o ajustare:
testul![]() pentru marile
esantioane (n>30)
pentru marile
esantioane (n>30)
testul Kolmogorov-Smirnov pentru micile esantioane (n>30)
Aceste teste de verificare statistica fac in mod evident apel la doua functii discriminante care reprezinta o masurare a abaterii care exista intre frecventele observate o1 , . on si teoretice t1 , . tn etc. si permit sa se verifice normalitatea unei distributii observate.
Testul Kolmogorov-Smirnov
Acest test permite sa se valideze calitatea unei ajustari a unui esantion mic la o lege de distributie teoretica.
Sa consideram un esantion de marime n, aranjat in ordine crescatoare.
Fie Fn (i) frecventa empirica referitoare la datele i si F(xi) frecventa la nedepasirea acestor date i calculate plecand de la legea teoretica. Se calculeaza pentru oricare i diferentele:
![]() (54)
(54)
Functia
discriminanta corespunde lui ![]() .
.
Se interpreteaza rezultatele dupa cum urmeaza:
a) daca K=0:
Exista o perfecta adecvare in care e bine sa nu ai incredere caci teoretic este putin probabila.
b) daca K>0:
Cele doua distributii
sunt diferite. Se compara atunci valoarea K cu quantila ![]() a functiei
lui Kolmogorov
si se concluzioneaza:
a functiei
lui Kolmogorov
si se concluzioneaza:
daca K ![]() , variatiile intre distributii sunt datorate
hazardului si ipoteza de adecvare nu este de respins la pragul de
risc a , deci se accepta ajustarea;
, variatiile intre distributii sunt datorate
hazardului si ipoteza de adecvare nu este de respins la pragul de
risc a , deci se accepta ajustarea;
daca K > ![]() , trebuie respinsa ipoteza de buna adecvare intre
esantion si legea teoretica.
, trebuie respinsa ipoteza de buna adecvare intre
esantion si legea teoretica.
Determinarea lui ![]() este
obtinuta:
este
obtinuta:
- fie plecand de la tabelul statistic;
- fie prin calcul direct prin formula aproximativa dedusa din functia lui Kolmogorov:
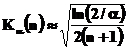 (55)
(55)
Abaterea relativa dintre valoarea obtinuta cu aceasta formula si cea din tabelul statistic este inferioara la 1% pentru orice a plecand de la n , care se diminueaza cand n creste.
Legea valorilor extreme
In securitatea sistemelor, se iau in considerare in general evenimente de probabilitate foarte apropiata de 1 sau foarte apropiata de 0 corespunzand unor quantile foarte mari sau foarte mici. Acestea apartin de fapt cozilor de distributie ale variabilei aleatoare studiate.
In practica, cunoasterea acestei variabile este realizata plecand de la un esantion de masuratori observate. Distributia celei mai mari sau celei mai mici masuratori de esantionare observate poarta numele de lege a valorilor extreme.
Utilizarea statisticilor de ordine
Fie F(x) functia de repartitie a variabilei X. Legea de distributie a probabilitatii de aparitie a quantilei de ordin i se scrie plecand de la distributia inrudita F a esantionului de baza .
![]() (56)
(56)
unde B este functia Beta.
a) Pentru i = 1, se obtine legea de probabilitate a celui mai mic element al unui esantion aranjat in ordine crescatoare notat X1= inf (x1 .xn).
![]() (57)
(57)
Ca urmare:
![]() (58)
(58)
b) De asemenea pentru i=n, se obtine legea de probabilitate a celui mai mare element al unui esantion aranjat in ordine crescatoare, notat:
Xn= sup(x1 .xn) (59)
![]() (60)
(60)
Ca
urmare: ![]() (61)
(61)
Distributia asimptotica a celei mai mari quantile
Determinarea expresiilor matematice
a) Limitele triviale ale legii celei mai mari valori se scriu:
- Pentru F(x) <1 atunci ![]()
- Pentru F(x) =1 atunci ![]()
Mai precis Gn (x) se poate scrie:
![]() (62)
(62)
Pentru n suficient de mare si 1- F(x) mic, deci x mare, se obtine:
![]() (63)
(63)
care s-ar putea scrie a
priori ![]() punand
punand
![]() (64)
(64)
b) Gumbel a aratat ca prin intermediul anumitor ipoteze :
Daca
![]() , distributia limita a lui Xn cand n tinde spre infinit se scrie :
, distributia limita a lui Xn cand n tinde spre infinit se scrie :
![]() (65)
(65)
unde ![]() (66)
(66)
Se obtine distributia lui Gumbel de forma matematica:
![]() (67)
(67)
unde:
![]() este parametrul de
pozitie
este parametrul de
pozitie
![]() este parametrul de
scara
este parametrul de
scara
Tipuri de legi asimptotice
S-a vazut ca forma matematica a distributiei de probabilitate a celei mai mari quantile conduce la aparitia legii de repartitie a variabilei X a populatiei initiale. Gnedenko a aratat ca oricare ar fi legea de distributie initiala, nu exista decat trei tipuri de legi asimptotice ale celei mai mari quantile (sau ale celei mai mici quantile observate), numita legea valorilor extreme.
a) Tipul I: legea lui Gumbel
![]() (68)
(68)
b) Tipul II: legea lui Frechet
![]() (69)
(69)
Pentru x > x0, b > 0 si 0 < a < 0,5
Observatii:
F(x) se poate scrie de asemenea:
![]() (70)
(70)
Se noteaza ca daca X urmeaza unei legi a lui Frechet, atunci ln(X-x0) urmeaza unei legi a lui Gumbel.
c) Tipul III: legea lui Weibull
![]() a, b > (71)
a, b > (71)
legea de tip I este numita cu descrestere exponentiala;
legile de tip II si III sunt cu descrestere algebrica.
|
Politica de confidentialitate |
| Copyright ©
2026 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |