
Modelul fuzzy este destinat sa estimeze iesirea unui proces. Modelul va fi considerat adecvat daca iesirea sa ym nu difera de iesirea procesului yp. Baza de cunostinte cu structura celulara poate fi vazuta ca o multime de reguli de inferenta care descriu modelul. Fiecare regula va avea forma:
IF raspunsul actual al procesului este similar cu un raspuns din baza, indicat prin celula CBj (reprezentand trecutul),
THEN iesirea procesului (reprezentand viitorul) va fi similara cu ( ST CBj)_y.
Considerand si factorul g de liniarizare in forma generala, o regula de inferenta poate fi exprimata si astfel:
IF u(k) g.CBj_u AND u(k-1) g(PT CBj)_u AND . AND u(k-hp+1) ) g(PThp-1CBj)_u
ANDy(k) g.CBj_y AND y(k-1) ) g(PT CBj)_y AND.AND y(k-hp+1) g(PThp-1CBj)_y
THEN y(k+1) g.( ST CBj)_y.
Regula care pleaca de la CBj se numeste regula j. Daca adancimea de evaluare in trecut este hp, regula este un sir de valori corespunzatoare la hp+1 momente de esantionare. In consecinta, numarul de reguli este mult mai mic decat numarul celulelor de baza.
Partea conditionala dintr-o regula exprima gradul in care trecutul raspunsului actual seamana cu trecutul unui raspuns din baza de cunostinte. Asemanarea se exprima printr-o masura a similaritatii partii conditionale -sm(hp,u(k),y(k),CBj,g). Regulile pentru care aceasta masura este satisfacatoare se numesc active. Sarcina selectarii numai a regulilor probabile a fi active este asumata de un algoritm de cautare.
O iesire a modelului fuzzy este rezultatul evaluarii mai multor reguli de inferenta intr-o tabela fuzzy de decizie. Procedura de constructie si de interpretare a acestei tabele se repeta integral la fiecare moment de esantionare. Tabela de decizie fuzzy este caracterizata prin dimensiune (numarul de parametri care conditioneaza o decizie) si natura informatiilor ce sunt retinute in ea. Dimensiunea este determinata de adancimea de evaluare a trecutului (ordinul fuzzy) si de extensia (latimea) multimii fuzzy de comparare. Alegerea valorilor acestor marimi este dependenta de numarul de reguli cu o similaritate mai mare ca zero ce vor fi gasite in baza de cunostinte la diferite momente de timp sau in diferite situatii. Daca valoarea lui hp tinde catre valoarea maxima np si extensia e tinde catre limita 1, probabilitatea de a gasi reguli active scade.
Tabela fuzzy de decizie a modelului se noteaza cu Dm(hp,e), iar informatiile inregisrate in ea cu Dm(hp,e)_x, unde x reprezinta tipul informatiei. Tabela este utilizata pentru calculul rezultatului final al modelului fuzzy la un moment de esantionare, extragerea anumitor indicii despre modul in care a fost obtinut acesta, pastrarea unor informatii inregistrate pentru calculul de la urmatorul pas de esantionare, calculul unei masuri a increderii pentru modelul fuzzy obtinut.
Pentru fiecare set de parametri hp si e, in tabela se inregistreaza urmatoarele tipuri de informatii: Dm(hp,e)_ssm - suma masurilor de similaritate ale regulilor; Dm(hp,e)_sysm - suma produselor intre masurile similaritatii si rezultatele regulilor; Dm(hp,e)_nr - numarul celulei de baza a raspunsului cu cea mai mare similaritate; Dm(hp,e)_g - factorul de liniarizare al raspunsului cu cea mai mare masura a similaritatii; Dm(hp,e)_maxsm - maximul masurii de similaritate a regulilor.
Calculul tabelei de decizie se face la fiecare moment de esantionare si debuteaza printr-o initializare:
FOR hp=1,.,np AND e=1,.,emax EXECUTE
Dm(hp,e)_ssm = 0; Dm(hp,e)_sysm = 0; Dm(hp,e)_nr = 0; Dm(hp,e)_g = 0; Dm(hp,e)_maxsm =0.
END
Continutul tabelei se poate modifica in continuare dupa fiecare evaluare a unei reguli. Daca, dupa evaluarea mai multor reguli, notam tabela cu Dm(hp,e), masura similaritatii urmatoarei reguli evaluate cu -sm(hp,u(k),y(k),CBj,g) si rezultatul modelului cu g.ST(CBj)_y, tabela de decizie se schimba dupa aceasta evaluare conform urmatorului algoritm de cautare:
FOR hp=1,.,np AND e=1,.,emax EXECUTE
IF -sm(hp,u(k),y(k),CBj,g) > 0 THEN:
Dm(hp,e)_ssm Dm(hp,e)_ssm + -sm(hp,u(k),y(k),CBj,g) AND
Dm(hp,e)_sysm Dm(hp,e)_sysm + -sm(hp,u(k),y(k),CBj,g). g.ST(CBj)_y;
ELSE:
Dm(hp,e)_ssm si Dm(hp,e)_sysm raman neschimbate.
IF -sm(hp,u(k),y(k),CBj,g) > Dm(hp,e)_maxsm THEN:
Dm(hp,e)_maxsm -sm(hp,u(k),y(k),CBj,g); Dm(hp,e)_nr j; Dm(hp,e)_g g .
ELSE:
Dm(hp,e)_maxsm, Dm(hp,e)_nr si Dm(hp,e)_g raman neschimbate.
END
Evaluarea unei reguli de inferenta j inseamna calcularea masurii similaritatii -sm(hp,u(k),y(k),CBj,g) si inregistrarea acestei valori in tabela fuzzy. In timpul unei evaluari, calculul acestei masuri se face de np.emax ori, ceea ce impune ca algoritmul de calcul al similaritatii sa fie eficient si rapid. Pentru aceasta, el va utiliza o extratabela unidimensionala shm(e) pentru inregistrarea rezultatelor intermediare din procesul de calcul al masurilor de similaritate. Continutul ei se modifica la fiecare modificare a adancimii evaluarii. Continutul extratabelei pentru adancimea v( vI ) este:
shmv(e) = ((fc,u,e(dui(k,j)) fc,y,e(dyi(k,j))) f0(i)). (5.28)
Inaintea evaluarii unei reguli, extratabela este setata cu 1 si se calculeaza factorul de liniarizare g. Daca CBj_u CBj_y = 0, atunci g =1, daca nu, se utilizeaza formula:
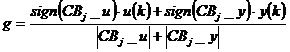 (5.29)
(5.29)
Acum se poate evalua regula, prin aplicarea urmatorului algoritm de calcul al masurii similaritatii:
SET v=1 si jv=j.
FOR e=emax,.,1 EXECUTE:
shmv(e) = shmv-1(e) ((fc,u,e(duv(k,jv)) fc,y,e(dyv(k,jv))) f0(v)), cu:
duv(k,jv) = uv(k) - g.CBjv_u; dyv(k,jv) = yv(k) - g.CBjv_y.
END
Calculele se reiau pentru toate valorile lui v, pana la v = np. Daca shmv(e) = 0 si e = emax, evaluarea regulii poate fi oprita. La sfarsitul algoritmului, se obtine -sm(v,u(k),y(k),CBj,g) = shmv(e) flin(g) si se cauta jv+1 pentru care CBj(v+1) = (PT CBjv).
La sfarsitul fiecarui pas de esantionare, un algoritm de interpretare al tabelei de decizie va alege setul de parametri (hp,e) ce vor fi utilizati pentru calculul iesirii modelului fuzzy. Alegerea se face in general empiric, pe baza experimentelor si se bazeaza pe urmatoarele considerente: hp trebuie sa se apropie de valoarea maxima np, pentru a produce o valoare satisfacatoare a masurii similaritatii la o extensie maxima emax; odata hp ales, extensia va fi micsorata pana cand masura similaritatii nu scade sub o valoare de satisfactie. Maximul masurilor similaritatii regulilor scade (sau ramane acelasi) daca e=constant iar hp creste, sau creste (eventual ramane acelasi) daca hp=constant iar e creste.
Pe baza acestor consideratii, algoritmul de interpretare va lucra astfel:
Pas1. Cauta hps, ca fiid cel mai mare hp (1 hp np) pentru care Dm(hp,emax)_maxsm fhb (valoarea de satisfactie). Daca Dm(hp,emax)_maxsm fhb, atunci hps=1.
Pas2. Cauta es, ca fiind cel mai mic e (1 e emax) pentru care Dm(hps,emax)_maxsm feb (valoarea de satisfactie). Daca Dm(hps,emax)_maxsm feb, atunci es= emax .
Un exemplu de tabela fuzzy de decizie cu np=3, emax=3, asa cum arata ea dupa evaluarea tuturor regulilor, este prezentat in figura 5.7. Tabela contine valorile maxsm, nr, g si ym=sysm /ssm. Algoritmul de interpretare poate lucra si cu o astfel de baza redusa de cunostinte, daca alegem adecvat valorile de satisfactie. Pentru exemplul din figura, daca fhb=0.1 si feb=0.3, rezultatul algoritmul este es=2 si hps=3.
Concluzia evaluarii este folosita pentru determinarea iesirii modelului, ym(k+1). Daca nu s-au putut gasi reguli care sa se asemene cu raspunsul actual, noua valoare a iesirii va fi cea de la momentul anterior: ym(k+1)=y(k). Daca tabela de decizie contine informatii despre anumite reguli eligibile, valoarea ym(k+1) poate fi calculata, fie ca suma ponderata a rezultatelor tuturor regulilor, fie ca un rezultat al regulii cu cea mai mare similaritate. In primul caz, avem:
ym(k+1) = Dm(hps,es)_sysm Dm(hps,es)_ssm (5.30)
In al doilea caz, rezultatul va fi:
ym(k+1) = Dm(hps,es)_g . ST(CBj)_y, cu j = Dm(hps,es)_nr (5.31)
Ambele formule dau bune rezultate in practica si nu exista cercetari sistematice care sa o indice pe cea care mai buna. Pentru exemplul din figura 5.7, prin metoda sumei ponderate se obtine ym(k+1) = 4.26, iar prin metoda similaritatii maxime se obtine regula 890. Daca, spre exemplu, ST(CB890)_y = 1.95, atunci ym(k+1) = 2.13 x 1.95 = 4.15.
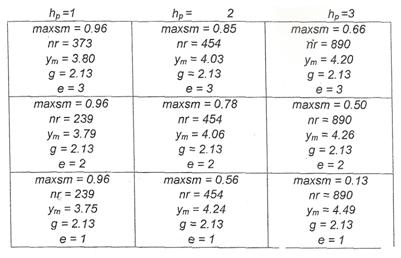
Figura III.51. O tabela fuzzy de decizie
Daca extensia este marita sau adancimea evaluarii este micsorata, rezultatul modelului fuzzy se obtine mai usor, dar el poate fi mai putin credibil. Gradul de credibilitate al iesirii modelului este reflectat de o masura fuzzy a increderii, care ia in considerare trei elemente: construita din trei componente: exactitatea, exprimata prin similaritatea maxima Dm(hp,es)_maxsm, adancimea hps in relatie cu adancimea maxima np si extensia es a multimii fuzzy de comparatie. Propunem pentru aceasta marime calitativa urmatoarea formula, pe care o vom folosi in experimente:
Q = (3.hps. Dm(hps,es)_maxsm) (np(2+es)) (5.32)
|
Politica de confidentialitate |
| Copyright ©
2025 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |