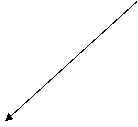
Spatiul fizic de stocare nu este mare. Utilizatori multipli dispersati in teritoriu, la cativa metri (birouri, laboratoare), la sute de kilometri (pentru locatii la distanta). Distanta satelitilor - cost de comunicatie mare. Costul BD centralizate nu se justifica, dimensiunile specifice BD aferente de date sunt inca nesemnificative. In perioadele de activitate intensa (introduceri note, actualizare date de identificare etc.) - cost ridicat + executii lente in tot sistemul, sau blocari repetate ale nodului central. Chiar daca implementarea unei solutii centralizate este mai putin complexa si mai ieftina, se justifica realizarea unui sistem de BDD.
Natura distribuita: Cluj-Napoca, Sfantu Gheorghe, Sighetu Marmatiei, pe forme de invatamant, linii de studii, sau specializari - distribuirea BD printr-o fragmentare, replicare si, o alocare functionala.
La fragmentarea orizontala - un nou atribut care sa reflecte locatia unde se desfasoara cursurile pentru fiecare student. Pentru lizibilitatea BD - atributul Locatie C(30) - localitatea in care au loc cursurile. La numarul actual de studenti de aproximativ 12.000 se repeta pentru fiecare cei 30 de octeti necesari specificarii locatiei, → 360.000 de octeti ineficienti. Rezolvare - definirea unei noi tabele denumita LOCATII (CodLocL, Locatie) - CodLocL -fi in corespondenta cu cheia externa CodLocL din tabela STUDENTI. → in Error! Reference source not found. = 12.063 octeti - fata de 360.000.
|
Nr. |
Denumire |
Descriere |
CodLocL |
Locatie |
|
|
CodLocL |
N(1) |
Cluj-Napoca |
|||
|
Locatie |
C(30) |
Sfantu Gheorghe |
|||
|
Sighetu Marmatiei |
Tabela FORME_INVATAMANT - corespondenta cu cheia externa din tabela STUDENTI - posibilitatea tinerii evidentei studentilor si pentru la FF, FR si ID. Prin conventie s-a stabilit ca studentii la zi au valoare 0 in cadrul campului CodFormInv.
Fragmentarea
Fragmente orizontale, iar apoi pe alocuri noi fragmente orizontale si verticale → fragmentare mixta - anumite aspecte functionale si organizatorice.
3 locatii se foloseste selectiille (predicatele):
p1: CodLocL = 0, pentru studentii care studiaza in Cluj-Napoca;
p2: CodLocL = 1, pentru studentii care studiaza in Sfantu Gheorghe;
p3: CodLocL = 2, pentru studentii care studiaza in Sighetu Marmatiei.
Locatia din Cluj - majoritatea studentilor. Fragmentarea trebuie aplicata si in acest caz Un sistem centralizat nu este o varianta buna. Exista secretariate speciale pentru la ZI sau ID. Pentru ca datele referitoare ele sa poata fi prelucrate independent si cu un grad sporit de concurenta, se spargere acest fragment in 2 fragmente in functie de forma de invatamant. Predicatele:
p4: CodFormInv = 0, pentru studentii de la zi;
p5: ~(CodFormInv = 0) = ~p4, pentru ID, eventual FR sau FF.
Invatamantul la zi - 3 linii de studiu: romana, maghiara si germana. Ultimele doua linii sunt gestionate separat prin activitatea de secretariat. →
p6: CodLinie = 0, linia romana;
p7: CodLinie = 1, linia maghiara;
p8: CodLinie = 2, linia germana.
In cadrul facultatii exista la zi specializarile:
. Management
. Marketing
. Economia Comertului, Turismului si Serviciilor
. Finante si Banci
. Contabilitate si Informatica de Gestiune
. Economie si Afaceri Internationale
. Economie Agroalimentara si a Mediului
. Informatica Economica
. Statistica si Previziune Economica
. Economie Generala si Comunicare Economica
. Economia Intreprinderii
. Economia Comertului, Turismului si Serviciilor (Sf. Gheorghe)
. Economia Intreprinderii (Sf. Gheorghe)
. Contabilitate si Informatica de Gestiune (Sighetu Marmatiei)
LINIA MAGHIARA
. Marketing
. Finante si Banci
. Informatica Economica
. Economia Comertului, Turismului si Serviciilor (Sf. Gheorghe)
. Economia Intreprinderii (Sf. Gheorghe)
LINIA GERMANA
. Economie si Afaceri Internationale
. Economia Intreprinderii
|
CodSectie |
Sectia |
|
MNG |
|
|
MK |
|
|
ECTS |
|
|
FB |
|
|
CIG |
|
|
EAI |
|
|
EAM |
|
|
IE |
|
|
SPE |
|
|
ECGE |
Continutul relatiei SECTII
p9: CodSectie = 1, MNG;
p10: CodSectie = 2, MK;
p11: CodSectie = 3, ECTS;
p12: CodSectie = 4, FB;
p13: CodSectie = 5, CIG;
p14: CodSectie = 6, EAI;
p15: CodSectie = 7, EAM
p16: CodSectie = 8, IE;
p17: CodSectie = 9, SPE;
p18: CodSectie = 10, EGCE;
p19: CodSectie = 11, EI.
Primii 2 ani - trunchiul comun - nu au nici o sectie asociata. Consideram codul sectiei 0, completat un numar de serie. Caracteristici: au secretariat propriu, au note putine, iar operatiunile de actualizare a BD privind informatiile de identificare vor fi mai frecvente.
p20: CodSectie = 0 sau Seria > "", trunchiul comun;
Predicatele minterm ce vor sta la baza fragmentarii orizontale vor fi:
m1: (CodLocL = 0) (CodFormInv = 0) (CodLinie = 0) (CodSectie = 0), Cluj-Napoca, zi, linia romana, trunchi comun;
m2: (CodLocL = 0) (CodFormInv = 0) (CodLinie = 0) (CodSectie = 1) , Cluj-Napoca, zi, linia romana, MNG;
m3: (CodLocL = 0) (CodFormInv = 0) (CodLinie = 0) (CodSectie = 2), Cluj-Napoca, zi, linia romana, MK;
m4: (CodLocL = 0) (CodFormInv = 0) (CodLinie = 0) (CodSectie = 3), Cluj-Napoca, zi, linia romana, ECTS;
m5: (CodLocL = 0) (CodFormInv = 0) (CodLinie = 0) (CodSectie = 4), Cluj-Napoca, zi, linia romana, FB;
m6: (CodLocL = 0) (CodFormInv = 0) (CodLinie = 0) (CodSectie = 5), Cluj-Napoca, zi, linia romana, CIG;
m7: (CodLocL = 0) (CodFormInv = 0) (CodLinie = 0) (CodSectie = 6), Cluj-Napoca, zi, linia romana, EAI;
m8: (CodLocL = 0) (CodFormInv = 0) (CodLinie = 0) (CodSectie = 7), Cluj-Napoca, zi, linia romana, EAM;
m9: (CodLocL = 0) (CodFormInv = 0) (CodLinie = 0) (CodSectie = 8), Cluj-Napoca, zi, linia romana, IE;
m10: (CodLocL = 0) (CodFormInv = 0) (CodLinie = 0) (CodSectie = 9), Cluj-Napoca, zi, linia romana, SPE;
m11: (CodLocL = 0) (CodFormInv = 0) (CodLinie = 0) (CodSectie = 10), Cluj-Napoca, zi, linia romana, ECGE;
m12: (CodLocL = 0) (CodFormInv = 0) (CodLinie = 0) (CodSectie = 11), Cluj-Napoca, zi, linia romana, EI;
m13: (CodLocL = 0) ~(CodFormInv = 0), Cluj-Napoca, invatamant la distanta;
m14: (CodLocL = 0) (CodLinie = 1), Cluj-Napoca, linia maghiara;
m15: (CodLocL = 0) (CodLinie = 2), Cluj-Napoca, linia germana;
m16: (CodLocL = 1) (CodLinie = 0), Sfantu Gheorghe, linia romana;
m17: (CodLocL = 1) (CodLinie = 1), Sfantu Gheorghe, linia maghiara;
m18: (CodLocL = 2), Sighetu Marmatiei.
Predicatele minterm alese sunt minimale si complete. De exemplu, un predicat echivalent cu predicatul m18 ar putea fi
(CodLocL = 2) (CodFormInv = 0) (CodLinie = 0) (CodSectie = 0)
La fragmentarea verticala, pe exemplul care avea la baza relatia STUDENTI, s-a constatat ca aplicatiile care ruleaza solicita doar anumite atribute, intr-o masura mai mare sau mai mica. Acestea erau:
Nume (A1), Pren (A2), CNP (A3), Sex (A4), CodLocD (A5), AnStud (A6), Seria (A7), CodLinie (A8), CodSectie (A9), ExplTaxa (A10), Taxa (A11), CodSit (A12), Orfan (A13), Media (A14), Grupa (A15)
Lor le mai adaugam Matricol (A16), CodLocL (A17), CodFormInv (A18).
Restul atributelor se utilizeaza mai rar si in general atunci cand e vorba de actualizarile datelor personale ale studentilor din anul 1 → relatia STUDENTI va fi divizata in 2 fragmente verticale, primul fragment fiind format din cele 18 atribute intre care exista afinitati de intensitati diferite, iar cel de-al doilea fragment este format de restul atributelor: PrenT (A19), PrenM (A20), DataN (A21), CodLocN (A22), CodNat (A23), CodStarCiv (A24), CodTara (A25), CodFac (A26) si CodAlte (A27). Aceasta fragmentare se va aplica doar asupra studentilor de la Cluj, linia romana.
Atributul IdStud ca fiind A0 - identificatorul de tuplu.
|
A0 A1 A2 A3 A4 A5 A6 A7 A8 A9 A10 A11 A12 A13 A14 A15 A16 A17 A18 |
A19 A20 A21 A22 A23 A24 A25 A26 A27 |
|
|
m1 |
|
ZI ROM CLUJ F2 SFANTU GHEORGHE |
|
m2 |
|
|
|
m3 |
F1.3 (MK) |
|
|
m4 |
|
|
|
m5 |
F1.5 (FB) |
|
|
m6 |
F1.6 (CIG) |
|
|
m7 |
F1.7 (EAI) |
|
|
m8 |
F1.8 (EAM) |
|
|
m9 |
F1.9 (IE) |
|
|
m10 |
F1.10 (SPE) |
|
|
m11 |
|
|
|
m12 |
F1.12 (EI) |
|
|
m13 |
F13 (ID) |
|
|
m14 |
F14 (MAG) |
|
|
m15 |
F15 (GER) |
|
|
m16 |
|
|
|
m17 |
F17 (MAG) |
|
|
m18 |
F18 (SIGHET) |
|
Fragmentare mixta in relatia STUDENTI
Fragmentarea trebuie sa indeplineasca 3 conditii: completitudine, posibilitatea refacerii relatiei initiale si caracterul disjunct. Aceste conditii sunt indeplinite, ceea ce se poate observa si din figura.
Completitudinea fragmentarii orizontale: reuniunea fragmentelor trebuie sa genereze relatia initiala.
![]()
m1 m2 m3 m18 = (((m1 m2 m3 m12) m14 m15) m13) (m16 m17) m18
m1 m2 m3 m12 = (CodLocL = 0) (CodFormInv = 0) (CodLinie = 0) STUDENTI = (CodLocL = 0) (CodFormInv = 0) (CodLinie = 0) (1)
m13 = (CodLocL = 0) ~(CodFormInv = 0) (CodLocL = 0) ~(CodFormInv = 0) (CodLinie = 0) (2), deoarece toti studentii de la ID sunt la sectia romana
T (CodLocL = 0) (CodLinie = 0) (3)
m14 m15 = (CodLocL = 0) ~(CodLinie = 0) (4)
T (CodLocL = 0)
m16 m17 = (CodLocL = 1)
m18 = (CodLocL = 2)
(CodLocL = 0) (CodLocL = 1) (CodLocL = 2) = STUDENT q.e.d.
→ conditia de completitudine - demonstrata.
Disjunctivitatea fragmentarii orizontale: intersectia fragmentelor trebuie sa genereze relatia vida.
![]()
m1 m2 m3 m18 = (CodLocL = 0) (CodFormInv = 0) (CodLinie = 0) (CodSectie = 0) (CodSectie = 1) (CodSectie = 2) (CodSectie = 3) (CodSectie = 4) (CodSectie = 5) (CodSectie = 6) (CodSectie = 7) (CodSectie = 8) (CodSectie = 9) (CodSectie = 10) (CodSectie = 11) ~(CodFormInv = 0) (CodLinie = 0) (CodLinie = 1) (CodLinie = 2) = ((CodFormInv = 0) ~(CodFormInv = 0)) = F F
In cazul fragmentarii verticale aceste doua conditii sunt indeplinite. Atributele fragmentului vertical A19, , A27 nu se suprapun peste celelalte A0, , A18. Multimea atributelor implicate in fragmentare A0, , A27 sunt chiar atributele relatiei STUDENT.
Refacerea relatiei initiale
![]() STUDENT
= ((F1.1 F1.2 F1.3 F1.4 F1.5 F1.6 F1.7 F1.8 F1.9 F1.10 F1.11 F1.12) A0=A0 F2) F13 F14 F15 F16 F17 F18,
unde
STUDENT
= ((F1.1 F1.2 F1.3 F1.4 F1.5 F1.6 F1.7 F1.8 F1.9 F1.10 F1.11 F1.12) A0=A0 F2) F13 F14 F15 F16 F17 F18,
unde
F1.1 = A0, A1, , A18 sm1(STUDENT) = A1, , A18 s(CodLocL = 0) (CodFormInv = 0) (CodLinie = 0) (CodSectie = 0) (STUDENT)
F2 = A19, , A27 s(CodLocL = 0) (CodLinie = 0) (STUDENT)
F18 = sm18 = s (CodLocL = 2) (STUDENT)
Ipoteza: puterea de calcul si de stocare sunt omogene in toate siturile care urmeaza a fi populate cu fragmentele rezultate.
La invatamantul de zi, Cluj-Napoca, orientat deja pe specialitati, se grupeaza cate 2 sau 3 sectii, deoarece nu exista secretariate separate pentru fiecare sectie in parte. Gruparea facuta este aleatoare. Se poate tine insa cont de gradul de "inrudire" al sectiilor, de numarul de studenti din fiecare, sau de alocarea lor pe secretariate astfel incat sa existe o distributie relativ omogena.
(CodSectie = 1 (CodSectie < 3), MNG + MK;
(CodSectie >2) (CodSectie < 5), ECTS + FB;
(CodSectie >4) (CodSectie < 7), CIG + EAI;
(CodSectie >6) (CodSectie < 9), EAM + IE;
(CodSectie >8) (CodSectie < 12), SPE + ECGE + EI.
![]()
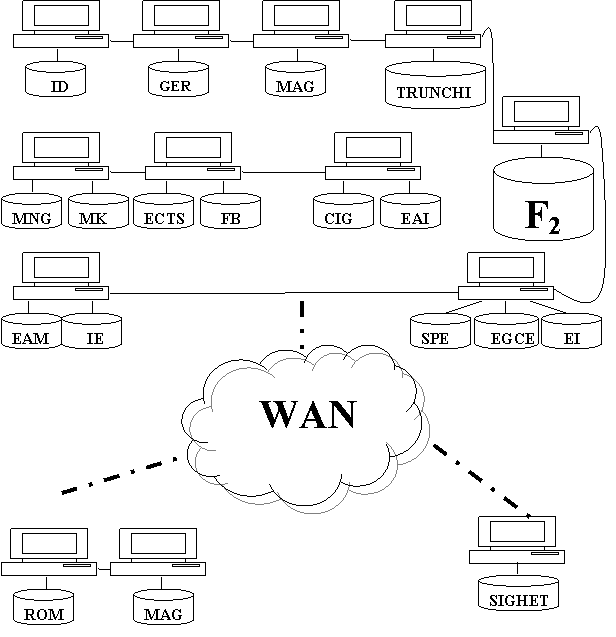
Alocarea fragmentelor relatiei STUDENTI pe situri
Alocarea - prin respectarea conditiei de completitudine a fragmentarii si disjunctivitate. Tabela CATALOG trebuie sa urmeze aceeasi alocare. Notele studentilor din Sighet este normal sa fie stocate acolo, a celor de la FB la Cluj si nu la Sighet. Chiar daca din punctul de vedere al spatiului fizic de stocare, pe situl din Sighet ar exista o incarcare mai usoara datorita lipsei notelor (la fel si in siturile din Sfantu Gheorghe), plasarea notelor de la sectia FB, chiar daca ar echilibra gradul de incarcare fizica a sitului, ar dauna caracterului local al referintei. Accesarea catalogului ar necesita intotdeauna accese la distanta.
Nici alocarea fragmentului F2 nu este buna deoarece atunci la activitati de actualizare masive - pentru studentii din primul an - este nevoie tot de accese la distanta, chiar daca distanta se refera la doua situri din acelasi LAN. Sunt si alte tabele de dimensiuni mai mici, cu frecvente scazute a actualizarilor, dar fara de care BD si intreg sistemul nu ar putea functiona. Actualizarea adresei unui student se face daca sunt disponibile siturile secretariatului de care apartine studentul si situl pe care este memorat fragmentul F2. Aceste conditii fiind indeplinite va fi necesar cel putin un acces la distanta (asta doar daca cererea e lansata de pe unul din cele doua situri implicate). Un acces mai rapid s-ar realiza daca ambele fragmente ar fi locale.
S-a realizat o acoperire completa in privinta tabelelor de baza ale BD - alocarea facuta anterior nu raspunde cerintelor de securitate, disponibilitate, fiabilitate si acces fara intarzieri prea mari. Exemplu, situl care contine datele referitoare la studentii din trunchiul comun are o pana. Sistemul va continua sa functioneze, insa datele referitoare la acestia nu vor fi disponibile.
Rezolvarea problemei, precum si cea a alocarii optime a celorlalte relatii se face cu ajutorul replicarii datelor. In cazul tabelelor mici rar actualizabile s-a propus, la discutiile despre relatii nefragmentate, replicarea tuturor acestora in toate siturile. In cazul relatiilor principale - cate o replicare in alte situri decat cele in care sunt stocate originalele. Aceasta replicare elimina neajunsurile de care s-a discutat, printr-un cost de inmagazinare, implementare si de comunicatie relativ redus.
Relatiile nefragmentate care vor fi memorate in fiecare sit:
LOCATII(CodLocL, Locatie)
ORFAN(CodOrf, Orfan)
SITUATII(CodSit, Situatie)
NATIONALITATI(CodNat, National)
STARE_CIVILA(CodStarCiv, StareCiv)
TARI(CodTara, Tara)
FACULTATI (CodFac, Facult)
FORME_INVATAMANT (CodFormInv, FormaInv)
LINII_STUDIU(CodLinie, LinStud)
SECTII(CodSectie, Sectie)
TAXE (CodTaxa, ExplTaxa, Taxa)
ALTE_ASPECTE(CodAlte, Alte)
TIP_STRAZI (TipStr, DenStr)
TIP_EXAMEN(CodEx, TipEx)
MATERII (CodMat, DenMat, Credite)
CADRE (IdProf, NumeProf, PrenProf).
Chiar daca in ultimele 3 relatii probabilitatea de accesare a anumitor tuple ar fi diferita pentru siturile din locatii diferite, consideram ca obtinem o solutie mai buna replicand intreg continutul in toate cele 3 locatii. Daca cineva care este la Cluj va fi interesat sa stie ce materii se predau la Sighet, pentru furnizarea raspunsului nu vom avea nevoie de accese la distanta.
Distribuirea pe situri a fragmentelor relatiilor, in functie de strategia expusa anterior (relatiile Sighet si Sf.Gheorghe sunt replicate la Cluj). Cu aceasta solutie a nu avea nevoie de accese la distanta atunci cand se acceseaza din Cluj cele doua BD si pentru a spori securitatea. De exemplu, un incendiu la secretariatul din Sighet ar distruge toate datele referitoare la aceasta locatie. La fel si pentru Sfantu Gheorghe.
Pentru ID a fost nevoie de 2 situri cu continut identic, deoarece nu puteam sa amestecam functionalitatile, plasand pe acelasi sit date referitoare la studentii de la limba romana cu cea limba germana. Dar, din moment ce exista doar doua calculatoare, nu putem spune ca reteaua locala va fi gatuita, iar timpul de acces "la mica distanta" va fi apropiat de cel al operatiilor normale de I/O.
In cadrul sectiilor la zi din Cluj - performanta destul de buna, deoarece un sit isi extinde caracterul local al referintei asupra a 4-5 sectii distincte. Acest lucru permite atat arondarea unui numar mai mare de sectii la un secretariat, cat si efectuarea unor activitati specifice unui secretariat dintr-o alta locatie, fara a fi necesar sa se reproiecteze alocarea. Figura nu surprinde totala a relatiilor nefragmentate, insa aceasta este usor de intuit.
Operatiile de reproiectare a alocarii si replicarii trebuie facute partial anual sau semestrial: de exemplu cand un student a incheiat trunchiul comun si a trecut la o specializare. Aceste activitati de intretinere pot fi facute cu oprirea sistemului si necesitand proceduri manuale, sau pot fi oferite dinamic, daca proiectantul prevede acest lucru. Cea de-a doua varianta este mai naturala, insa ceva mai costisitoare. Acest cost poate fi amortizat din costul cumulat al potentialelor reproiectari manuale ulterioare.
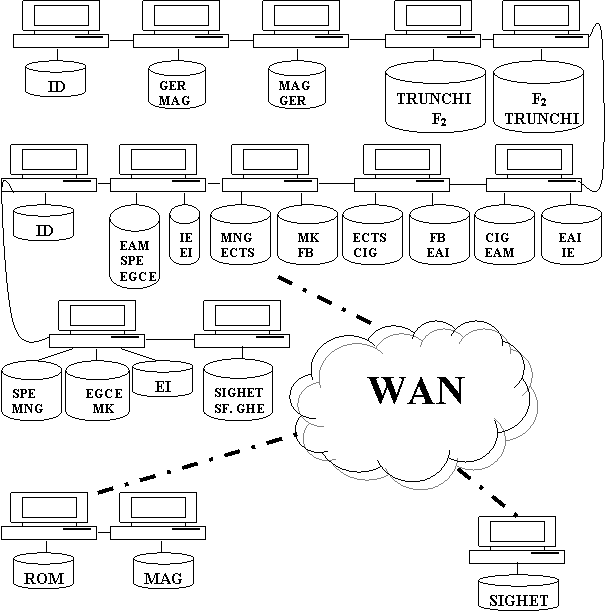
Replicarea fragmentelor relatiei STUDENTI si CATALOG pe situri
"Knowledge discovery is the most desirable end-product of computing"[1]
In lume > 10 exabytes/an (1 exabyte= ![]() bytes) → 250
megabyti /persoana si cresterea este
exponentiala. Studiu - Universitatea Berkeley: in intreaga istorie
pana la 1999, omenirea a produs 12 exabytes de date, alti 12 exabytes
1999 - 2002 si 12 exabytes in 2003 .
→ omenirea intr-un ocean de date.
bytes) → 250
megabyti /persoana si cresterea este
exponentiala. Studiu - Universitatea Berkeley: in intreaga istorie
pana la 1999, omenirea a produs 12 exabytes de date, alti 12 exabytes
1999 - 2002 si 12 exabytes in 2003 .
→ omenirea intr-un ocean de date.
Cantitatea de date se dubleaza in fiecare an. NASA - mai multe date decat poate analiza[3]. Cercetatorii trebuie sa memoreze si sa prelucreze mii de octeti pentru fiecare din cele 3 G de baze DNA pentru a construi genomul uman in proiectul de construire a acestuia. Zilnic sute de megabytes circula pe Internet si avem nevoie de a extrage semnificatii si cunostinte din ele"3.
O mica parte din aceasta cantitate - utilizata. DM s-a nascut din aceasta necesitate.
"Computerele ne-au promis o fantana a intelepciunii dar ne-au oferit o cantitate imensa de date-Gregory Piatetsky-Shapiro"
DM - utilizarea unor algoritmi si proceduri pentru a extrage cunostinte (modele).
Nu orice descoperire de informatii sau cunostinte este DM[4] - cautarea unor informatii BD sau pe Internet - domeniul regasirii informatiilor (information retrieval) - informatica clasica si nu utilizeaza tehnologii DM.
Realizarea previzionarii pe baza datelor prin clasificare sau regresie.
Obiectivul previzionarii - construirea unui model - permite unei valorilor unei variabile sa fie previzionate pe baza valorile date ale altor variabile.
In clasificare, variabila previzionata - tip categorie, in cazul regresiei variabila previzionata - numerica.
Majoritatea metodelor de DM se bazeaza pe clasificare.
DM este o ramura a IA+BD. Multe tehnici utilizate de DM exista de mai multi ani, fiind descoperite in cercetarile de IA din anii 80 si inceputul anilor 90. Aplicate acum BD de dimensiuni mari pentru a extrage modele.
"Folosind un cadru metodologic si teoretic imbunatatit s-a ajuns la intelegerea modului in care retelele neuronale pot fi comparate la ora actuala cu tehnicile corespunzatoare din statistica, recunoasterea formelor, si ML si se aplica tehnologia cea mai indicata fiecarei aplicatii. Ca rezultat al acestor dezvoltari a luat nastere o tehnologie denumita DM ceea ce a creat o noua industrie viguroasa"[5].
DM - Aspecte generale
"DM - analiza unor seturi de date in vederea descoperirii de relatii nebanuite si transformarii acestora astfel incat sa fie cat mai utile posesorului lor".[6]
"DM- se defineste ca procesul descoperirii unor pattern-uri in date. Procesul trebuie sa se desfasoare automat sau (mai uzual) semiautomat"[7].
DM denumita si KDD-Knowledge Discovery in Databases-a fost definita ca si "o colectie de tehnici utilizate pentru extragerea de informatii din date".
DM este explorarea si analiza cantitatilor mari de date pentru a descoperi modele si reguli[9].
Scopul final al DM este de a extrage cunostinte din date[10].
Prima conferinta internationala de DM a avut loc la Montreal in 1995 - s-a stabilit ca knowledge - cunostinta in sens DM sau KDD - va desemna "tipare si relatii intre date"[11]
DM - un ansamblu de metode prin care, in mod automat, se cauta tipare care ar putea fi ascunse in datele stocate in BD mari. DM utilizeaza tehnici din statistica, machine learning (ML) si recunoasterea formelor
Cresterea dimensiunilor BD orientate pe activitati in ultimii anii: analiza pietei si optiunile consumatorilor, etc. aduce DM in topul noilor tehnologii de afaceri.
Diferenta intre DM si alte tehnici de analiza este abordarea utilizata in explorarea relatiilor dintre date. Multe dintre tehnicile de analiza se bazeaza si sunt limitate de intuitia analistului - abordari bazate pe verificare - utilizatorul formuleaza ipoteze despre relatiile dintre date si ulterior utilizeaza tehnici pentru a verifica aceste ipoteze. Eficienta acestor metode de analiza - limitata de un numar de factori:
Exemplu: Dorim sa analizam influenta cumpararii cips-urilor in cazul cumpararii berii. Avand BD cu vanzarile se poate analiza, cati dintre care au cumparat cips-uri au cumparat bere. Deci se verifica ipoteza "cumparatorii de bere cumpara si cips-uri" - se presupun anumite relatii intre variabile si se verifica aceste relatii → important - se pleaca de la o ipoteza si se verifica ipoteza respectiva. In DM nu se pleaca de la o ipoteza ci se determina cei mai importanti factori de influenta asupra rezultatelor si realizeaza o clasificare, respectiv clusterizare a elementelor de intrare. Deci in DM nu sunt necesare ipoteze si prin el se determina relatiile si modelele ascunse.
DM, in contrast cu aceste metode analitice, utilizeaza o abordare bazata pe algoritmi care sunt rulati pentru a se descoperi legaturile intre date.
Algoritmii DM analizeaza mai multe relatii intre date, scotand in evidenta cele dominante sau exceptionale.
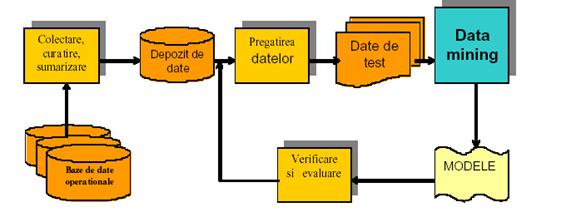
Ciclul DM
Dupa alti autori[15] etapele ar fi:
Curatarea datelor - eliminarea datelor inconsistente
Integrarea datelor - combinarea datelor din surse multiple
Selectarea datelor - accesarea datelor relevante pentru analiza din cadrul BD
Transformarea datelor - transformarea sau consolidarea datelor astfel incat sa ajunga la o forma adecvata pentru DM, de exemplu prin operatii de agregare
DM - un proces esential in care se aplica metode inteligente pentru a extrage tipare din date
Evaluarea tiparelor - aplicarea diferitor metode pentru a gasi modelele de cunostinte cu adevarat semnificative
Prezentarea cunostintelor - utilizarea de tehnici de vizualizare si reprezentare a cunostintelor pentru a prezenta utilizatorului cunostintele extrase.
Unii autori considera DM si KDD diferite, altii considera tot lantul ca fa cand parte din DM. [Pang06] KDD se considera procesul dat de Figura 1.3.
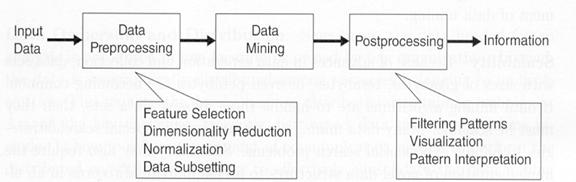
Abordari sunt echivalente.
Dupa intelegerea & formularea problemei, se aduna datele relevante → are loc o preprocesare a lor iar pe baza acestor date se creeaza un model.
DM -pasul de descoperire, pasul in care se actioneaza asupra datelor efectiv pentru obtinerea informatiei utile. Deosebita sa importanta in cadrul procesului KDD este limpede; cu toate acestea, se aloca doar 20% din timp si efort "minarii" in sine, restul revenind problemelor de preparare a datelor.
Importanta pentru DM - activitatea de data warehousing (DW). Diferenta dintre sistemele de BD operationale si DW- depozitele de date:
BD contin datele rezultate din activitatea curenta a intreprinderii si folosesc la procesarea tranzactiilor si a interogarilor.
DW sunt "magazii de informatii colectate din surse multiple, stocate intr-o schema unitara si care de obicei se gasesc la o aceeasi locatie" [HK2001, p.12]. DW - un instrument de analiza pentru decidenti usureaza luarea deciziilor strategice oferind facilitati de agregare a datelor.
Nivelul de detaliere a datelor din DW - mai mic de cel din BD operationale - scopul DW - a conferi o imagine de ansamblu asupra intreprinderii. Ponderea efortului depus pentru a pregati datele in vederea unui studiu de DM este mare → utilizarea DW - un avantaj, datele sunt de calitate inalta si pot fi folosite fara mari modificari in DM. Infrastructura pentru procesarea informatiilor este deja existenta intr-un DW → nu se porneste de la zero in organizarea accesului, integrarii, consolidarii si transformarii datelor din BD multiple [HK2001, p.95].
Parte foarte importanta - evaluarea modelului prin diferite tehnici de evaluare →modelul poate fi implementat si supervizat.
Aplicatii DM
Domeniile de aplicabilitate ale - sectoare precum biologia, medicina, astronomia sau criminologia. In economie si afaceri:
Marketingul - cele mai multe motive de a face studii de DM. Tendinta generala este de a trece de la cota de piata la cota de client in cadrul asa-numitului "one-to-one marketing"[16] . Trebuie descoperite preferintele si obisnuintele clientilor pentru a le adresa campanii publicitare care sa duca la rate de raspuns cat mai ridicate. Se pot realiza, de exemplu, prin utilizarea unor carduri de fidelitate (in cazul marilor supermarketuri) sau a cartilor de credit/debit (pentru banci) - se inregistreaza datele personale ale clientului, toate tranzactiile intre client si firma, date referitoare la locul unde au fost efectuate tranzactiile etc. Un astfel de instrument, in combinatie cu o BD operationala sau cu un DW, este deosebit de util pentru descoperirea tiparelor in comportamentul clientilor. Pornind de la informatiile obtinute, supermarketul poate nu numai sa focalizeze campaniile publicitare ci si sa afle care dintre produse se vand bine impreuna → le poate plasa in rafturi contigue pentru a creste vanzarile.
DM - pentru retinerea clientilor care aduc castiguri intreprinderii. In telefonia mobila sau sectorul bancar, concurenta este acerba si consumatorii isi pot schimba furnizorul fara costuri suplimentare insemnate. Berry si Linoff [18] "atragerea unui client nou costa mai mult decat pastrarea unui client vechi, dar adeseori dorinta de a mentine un consumator este destul de scump. DM este cheia in a ne da seama care dintre clienti ar trebui stimulati, care nu, si care ar trebui lasati sa plece."
Alt domeniu - descoperirea fraudelor in telefonie, in domeniul bancar sau in cel al comertului cu amanuntul. In tarile in care cartile de credit se folosesc cu regularitate este deja clasic exemplul blocarii acestor mijloace de plata in urma unor tranzactii care ies din tiparul obisnuit prin aceea ca se depasesc cu mult sumele extrase sau frecventa de utilizare. Procedeul urmat pentru a identifica aceste exceptii se bazeaza pe utilizarea datelor istorice cu ajutorul carora se construieste un model de comportament fraudulos. Pasul de DM serveste pentru a gasi instante asemanatoare celor din model si a le cataloga de asemenea drept frauduloase.[CHS1997, p.34]
Aplicatiile DM din diferite domenii pot fi clasificate pe seturi de probleme cu caracteristici similare. Distinctia dintre probleme se realizeaza prin parametrizare, care face posibila personalizarea de la aplicatie la aplicatie. De exemplu, aceeasi abordare si model folosite pentru determinarea fraudei la o banca poate fi folosita si pentru dezvoltarea aplicatiilor de descoperire a fraudei in asigurarile medicale. Diferenta consta in parametrizarea modelelor, de exemplu, in stabilirea atributelor specifice folosite si in a modului de utilizare a lor.
Fiecare aplicatie DM este sustinuta de un set de algoritmi utilizati pentru obtinerea relatiilor din date. Aceste abordari difera in functie de tipul de problemei la care sunt aplicate.
Gio Widerhold, On the Barriers of Future of Knowledge Discovery, in U.M.Fayad, G. Piatetski-Shapiro, P. Smyth, R. Uthurusamy, Advenced in Knowledge Discovery and DM, AAAI Press/The MIT Press, 1996.
[Negnetwitsky 2002] p.350 Negnetwitsky M., Artificial Intelligence, Guide to Intelligent Systems, Addison Wesley, Second Edition, 2002, p.350
Rusell S., Norvig P., Artificial Intelligence, A Modern Approach, Prentice Hall in Artificial Intelligence, Second Edition, 2003.
I.H.Witten, E.Frank, DM, Practical Learning tools and Techniques with Java Implementation, Morgan Kaufmann Pub., 1999.
Machine learning (ML) - ramura a IA care se ocupa cu dezvoltarea tehnicilor care permit calculatoarelor sa «invete». Acest lucru se realizeaza analizand seturi de date.
Recunoasterea tiparelor este un subdomeniu a ML si reprezinta o colectie de metode pentru invatare supervizata.
[HK2001] Han, Jiawei, Kamber, Micheline: Data Mining: Concepts and Techniques. Morgan Kaufmann, 2001, 550 p.
Termenul "one-to-one marketing" a fost introdus de catre Don Peppers si Martha Rogers in cartea numita The One To One Future, aparuta in 1994. Se refera la practica de a trata personalizat oameni diferiti. Astfel, este foarte importanta diferentierea clientilor, nu doar cea a produselor.
|
Politica de confidentialitate |
| Copyright ©
2025 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |