Accelerarea procesului de inmultire
binara prin folosirea unui sumator CSA si
cresterea la
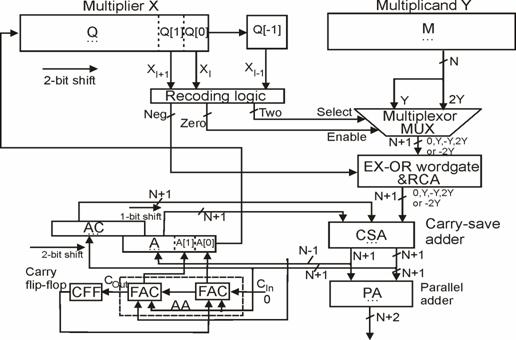
In tendinta unui castig cat mai consistent de performanta, sa combinam cele doua concepte de accelerare anterior expuse. Astfel, preconizand, de aceasta data, o prezentare sintetica de tipul celei din fig. 3.33, dar referindu-ne la elementele de structura din fig. 3.36, in fig. 3.38 se contureaza schematic, un dispozitiv de inmultire radix 4 cu CSA (prelucrare dupa [Parh00]).
Comentand noua structura, remarcam, mai intai, logica de
recodificare (recoding logic) comandata de aceiasi trei biti din
rangurile Q[1], Q[0] si Q[-1] ale unui corespondent registru multiplier Q.
Aceasta prezinta aceleasi trei iesiri ca si cea din fig.
3.33, cu aceleasi observatii legate de sinteza logica. Este
insa o diferenta, anume "zero" se aplica la intrarea de
autorizare "Enable" ale unui multiplexor care trebuie sa posede o astfel
de intrare (cum ar fi, spre exemplu, circuitul integrat MUX 74LS153 [Yarb97]).
Iesirea "zero" nu mai comanda direct deplasarea (shift control, ![]() ) ca in fig. 3.33, ci, atunci cand este activata,
furnizeaza la cele (n+1) iesiri ale MUX vectorul binar format
exclusiv din 0-uri. Acest vector impreuna cu Y si 2Y, generati in maniera
sugerata in fig. 3.34, sunt
aplicati la un scazator binar, sintetizat printr-un strat EX-OR
wordgate si un sumator paralel, spre exemplu, RCA, care, atunci cand este
activa intrarea sa "neg", permite, in maniera prezentata in fig.
3.36, sa se formeze complementul de doi pentru (-Y), respectiv (-2Y). In acest mod, la
unul dintre cele trei seturi de intrari ale CSA sunt disponibili vectorii
corespunzatori tuturor multiplilor prevazuti in tabelul din fig.
3.31, adica 0, Y, -Y, 2Y si (-2Y). La celelalte doua seturi de
intrari se aplica vectorii suma, respectiv carry, stocati
temporar in registrele A, respectiv AC, ale accumulator registers cu
configuratia generala data in fig. 3.36.
) ca in fig. 3.33, ci, atunci cand este activata,
furnizeaza la cele (n+1) iesiri ale MUX vectorul binar format
exclusiv din 0-uri. Acest vector impreuna cu Y si 2Y, generati in maniera
sugerata in fig. 3.34, sunt
aplicati la un scazator binar, sintetizat printr-un strat EX-OR
wordgate si un sumator paralel, spre exemplu, RCA, care, atunci cand este
activa intrarea sa "neg", permite, in maniera prezentata in fig.
3.36, sa se formeze complementul de doi pentru (-Y), respectiv (-2Y). In acest mod, la
unul dintre cele trei seturi de intrari ale CSA sunt disponibili vectorii
corespunzatori tuturor multiplilor prevazuti in tabelul din fig.
3.31, adica 0, Y, -Y, 2Y si (-2Y). La celelalte doua seturi de
intrari se aplica vectorii suma, respectiv carry, stocati
temporar in registrele A, respectiv AC, ale accumulator registers cu
configuratia generala data in fig. 3.36.
|
|
|
Fig.3.38 |
Totusi, operarea bazata pe recodificarea Booth in radix 4 reclama unele elemente distinctive fata de structura din fig. 3.36. Astfel, doar cei mai semnificativi (n-1) biti ai vectorului binar suma de la iesirea CSA sunt incarcati in bitii corespunzatori ai registrului A, iar in cele mai putin semnificative doua ranguri ale acestuia (A[1] si A[0]) se introduc valorile binare de la iesirile unui sumator paralel aditional (additional adder, AA), reprezentat in fig. 3.38 de tip RCA. La intrarile acestuia, se aplica, pe de o parte, cei mai putin semnificativi doi biti ai vectorului suma, si, pe de alta parte, cel mai putin semnificativ bit al vectorului binar carry concatenat cu bitul stocat intr-un flip - flop de carry (carry flip - flop, CFF). In acesta se introduce valoarea binara de la iesirea cout a sumatorului AA, posibil sa apara la generarea bitilor definitivi ai produsului care sunt "impinsi" din A in Q. Pentru formarea acestora, la cei doi biti lsb ai vectorului suma se aduna bitul lsb al vectorului carry, decalat cu o pozitie spre stanga si avand atasat la pozitia 0-ului rezultat prin deplasare, valoarea memorata (in CFF) a carry-ului rezultat la anterioara activare a CSA-ului. Incarcarea registrului A a fost prevazuta a se realiza sincron pe intreaga sa lungime de (n+1) ranguri, simultan cu a registrului AC si a bistabilului CFF, ceea ce implica o latenta care sa acopere intervalul de timp reclamat de propagarea semnalelor pe calea cea mai defavorabila (uzual, cea de traversare a numarului
|
|
|
Fig.3.39 |
mai mare de niveluri logice) din logica AA. Conex cu anterioara remarca legata de formarea vectorului suma reala din vectorii CSA, de suma si carry, mentionam ca la finele fiecarui pas (ciclu) al procedurii registrul A .Q este shift-at cu 2 pozitii la dreapta, pe cand registrul AC trebuie shift-at doar cu o pozitie la dreapta (vezi fig. 3.38), sens in care, spre deosebire de registrul AC din fig. 3.36, trebuie prevazut cu capacitate de deplasare. Desigur, respectand intocmai procedura descrisa, pot fi imaginate si alte versiuni de implementare.
Modul in care sunt aplicate cele relatate poate fi urmarit pe
aceiasi operatie exemplu, folosita la ilustrarea si a
celorlalte proceduri, in fig. 3.39. Subliniem ca am apelat la
aceleasi conventii de reprezentare uzitate in fig. 3.37 (M*
pentru continutul complementului de doi a celui din M,![]() pentru deplasarea la dreapta cu o pozitie a
continutului din AC si, prin analogie,
pentru deplasarea la dreapta cu o pozitie a
continutului din AC si, prin analogie, ![]() pentru deplasarea la dreapta cu doua pozitii a
continutului din registrul dublu A.Q, precum si acolada pentru
marcarea celor trei vectori binari adunati in maniera CSA) si in
fig. 3.35 (pentru identificarea triadei de biti Q[1]Q[0]Q[-1]
investigata la un moment dat). In plus, apar coloanele CFF si AA ilustrand
perechile de biti adunati precum si cout-ul generat
la aceasta operatie si stocat in CFF. Cei doi biti lsb din
A apar in dreptul respectivului registru dar in coloana AA, iar bitii
suma din AA nu au mai fost "intorsi" in rangurile A[1] si A[0]
ale registrului A, ci au fost "impinsi" direct in registrul Q, aceasta
doar pentru a conferi o minima claritate fluxului informational din
fig. 3.39.
pentru deplasarea la dreapta cu doua pozitii a
continutului din registrul dublu A.Q, precum si acolada pentru
marcarea celor trei vectori binari adunati in maniera CSA) si in
fig. 3.35 (pentru identificarea triadei de biti Q[1]Q[0]Q[-1]
investigata la un moment dat). In plus, apar coloanele CFF si AA ilustrand
perechile de biti adunati precum si cout-ul generat
la aceasta operatie si stocat in CFF. Cei doi biti lsb din
A apar in dreptul respectivului registru dar in coloana AA, iar bitii
suma din AA nu au mai fost "intorsi" in rangurile A[1] si A[0]
ale registrului A, ci au fost "impinsi" direct in registrul Q, aceasta
doar pentru a conferi o minima claritate fluxului informational din
fig. 3.39.
|
Politica de confidentialitate |
| Copyright ©
2025 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |