
Acum problema se pune astfel: daca avem o functie de pierdere L si un vector aleator X , interpretata drept istoric al platilor, cum este cel mai bine sa aproximam o variabila aleatoare Y, interpretata drept o plata viitoare? Cu alte cuvinte se pune problema definirii unui L-aproximant conditionat. Definirea lui se bazeaza pe faptul ca o variabila aleatoare reala admite intotdeauna o repartitie conditionata regulata fata de o s-algebra F. Se stie (vezi de exemplu lectia "Conditioning" ca exista o probabilitate de trecere Q de la (W,F) la (A,B(A)) astfel ca egalitatea P(Y I B F w = Q(w,B) sa fie adevarata P-a.s. Atunci definim AL(Y F) astfel:
Sa presupunem ca AL(Y) este definit printr-o functie A(m), unde m este repartitia variabilei aleatoare Y. Avem dreptul sa scriem asa deoarece L-aproximantul nu depinde atat de variabila aleatoare Y cit depinde de repartitia sa , m Ei bine, atunci definim
AL(Y F w) = A(Q(w
Exemplul . Daca L(x,y) = x-y p, p 1 , atunci pentru p > 1 Ap(Y) este solutia unica a
ecuatiei E( X-t p- sign(X-t))
= 0. In termeni de repartitie, A(m) este
solutia unica a ecuatiei ![]() dm(x)
= 0.
dm(x)
= 0.
Atunci Ap(Y F w) este solutia unica a
ecuatiei ![]() Q(w,dx)
= 0. Scrisa ca medie conditionata, este vorba despre
solutia t(w) a ecuatiei E( Y-t sign(Y-t) F w
Q(w,dx)
= 0. Scrisa ca medie conditionata, este vorba despre
solutia t(w) a ecuatiei E( Y-t sign(Y-t) F w
Aici m este repartitia lui Y iar Q(w) este repartitia conditionata a lui Y de F .
Pentru p = 2 obtinem A2(Y) = E(Y F) iar daca p = 1 obtinem mediana lui Y conditionata de F.
Exemplul Daca L(x,y) = ehx-ehy p cu p > 0, h >0 , am vazut ca AL(Y) este ![]() . Atunci avem ) AL(Y F) =
. Atunci avem ) AL(Y F) = ![]() . Daca p = 2
obtinem prima exponentiala conditionata
. Daca p = 2
obtinem prima exponentiala conditionata
Hh(Y F ) =
![]() .
.
Exemplul 3. L(x,y) = (x - y)2ehx cu h > 0, AL(Y) = ![]() este premiul Esscher.
Sa il notam Esschh(Y) . In acest caz AL(Y F) =
este premiul Esscher.
Sa il notam Esschh(Y) . In acest caz AL(Y F) =![]() = Esschh(Y F) este premiul Esscher
conditionat. Din capitolul precedent rezulta inegalitatea
= Esschh(Y F) este premiul Esscher
conditionat. Din capitolul precedent rezulta inegalitatea ![]() E(Y F
E(Y F
PROPOZITIA 6.1. Fie L o functie de pierdere cu proprietatea ca AL(Y) exista pentru orice risc pozitiv marginit Y . Atunci AL(Y F) construit ca mai sus are proprietatea de optim
E(L(Y,AL(Y F F E(L(Y,Z) F Z care este F - masurabila
Demonstratia se bazeaza pe urmatoarea formula de calcul
LEMA 6.2. Fie Y o variabila aleatoare cu valori reale, F o sub-s-algebra a lui K , Q repartitia conditionata regulata a lui Y in raport cu F , L : A ) o functie masurabila si Z o variabila aleatoare care este F - masurabila. Atunci aproape pentru toti w I W are loc egalitatea
E(L(Y,Z) F w) = ![]() (w))Q(w,dy)
(w))Q(w,dy)
Demonstratia lemei. Este standard. Din ipoteza si din formula de transport avem
E(h(Y)
F w) = ![]() Q(w,dy) (P - a.p.t)
Q(w,dy) (P - a.p.t)
Pasul 1. Daca L(y,z) = h(y)g(z) cu f,g
masurabile pozitive atunci E(L(Y,Z) F w) = E(h(Y)g(Z) F w) = E(h(Y) F w)g(Z(w)) (variabilele F - masurabile ies din media conditionata!) = g(Z(w))![]() Q(w,dy) =
Q(w,dy) = ![]() g(Z(w)) Q(w,dy) =
g(Z(w)) Q(w,dy) = ![]() (w))Q(w,dy) deci formula este
adevarata in acest caz.
(w))Q(w,dy) deci formula este
adevarata in acest caz.
Pasul 2. Drept urmare, daca L(y,z) = 1A B(y,z) cu A,B boreliene, formula (6.3) este adevarata. Fie
C = C I B A E(1C(Y,Z) F ) = ![]() (w))Q(w,dy)
(w))Q(w,dy)
Atunci C este un p-sistem care contine dreptunghiurile A B cu A,B boreliene. Cum dreptunghiurile formeaza un sistem de generatori stabil la intersectii finite pentru B(A ), rezulta ca toate multimile boreliene C sunt in C, deci (6.3) este valabila pentru functii de forma L(y,z) = 1C(y,z)
Pasul 3. Fiind valabila pentru indicatori, (6.3) este valabila pentru functii L simple.
Pasul
4. Fie L oarecare.
Atunci exista un sir crescator de functii simple si
pozitive(Ln)n astfel ca Ln L . Alicind teorema
Beppo-Levi conditionata avem E(L(Y,Z) F w) = E(limn Ln(Y,Z) F w) = limn E(Ln(Y,Z) F w) (P - a.s.) = limn ![]() (w))Q(w,dy) =
(w))Q(w,dy) = ![]() ) Q(w,dy) (teorema Beppo-Levi
obisnuita) =
) Q(w,dy) (teorema Beppo-Levi
obisnuita) = ![]() (w))Q(w,dy).
(w))Q(w,dy).
Acum demonstrarea Propozitiei 6.1 este imediata:
E(L(Y,AL(Y F F w = ![]() AL(Y F w))Q(w,dy)
AL(Y F w))Q(w,dy) ![]() (w))Q(w,dy) =E(L(Y,Z) F w) aproape pentru toti w
(w))Q(w,dy) =E(L(Y,Z) F w) aproape pentru toti w
COROLAR 6.3. Fie L o functie de pierdere cu proprietatea ca AL(Y) exista pentru orice risc pozitiv marginit Y . Atunci
E(L(Y,AL(Y F E(L(Y,Z) ) Z care este F - masurabila
Observatie. Deci L-aproximantii conditionati raspund la intrebarea: dintre toate functiile Z care sunt F - masurabile , cine asigura o pierdere minima medie, daca inlocuim riscul adevarat Y cu Z ?
Raspuns: Z = AL(Y F
Pe noi ne intereseaza un caz particular, anume cind F este generat de un vector aleator, X . Atunci vom nota AL(Y X ) in loc de AL(Y s(X)). Aceasta variabila aleatoare are atunci proprietatea de optim
E(L(Y,AL(Y X X E(L(Y,g(X)) X g:At A masurabila
Cu consecinta
E(L(Y,AL(Y X E(L(Y,g(X))) g:At A masurabila
Revenim acum la intrebarea initiala: cum putem folosi experienta acumulata X pentru a gasi un predictor de pierdere minima pentru Y = Xt+1 ? Raspuns: acesta este AL(Xt+1 X
Aceasta este ideea de credibilitate cand se inlocuieste functia de pierdere patratica cu alt tip de functie de pierdere. Apar diferente insemnate: aproximantii nu mai sunt neaparat proiectori . Totusi, in cele doua cazuri folosite in actuariat (premiul exponential si premiul Esscher) apar formule nu foarte complicate.
COROLAR 6.4. Presupunem ca variabilele aleatoare (Xr)r sunt conditionat i.i.d. daca se da Q q. Fie t un numar natural si X = (Xr)1 r t
Fie h > 0 . Atunci premiul exponential conditionat este
Hh(Xt+1 X) = ![]()
unde jh Q) = ![]() ( =
( = ![]() r caci variabilele
aleatoare sunt identic repartizate!) iar premiul Esscher este
r caci variabilele
aleatoare sunt identic repartizate!) iar premiul Esscher este
Esschh(Xt+1 X = ![]()
unde yh Q) = ![]()
Demonstratie. Hh(Xt+1 X) = ![]() . Dar
. Dar ![]() = E(
= E(![]() X) = E(
X) = E(![]() X) (deoarece variabilele sunt conditionat independente!; vezi
lectiile anterioare!) = E(jh Q X) . Apoi premiul Esscher este AL(Xt+1 X) =
X) (deoarece variabilele sunt conditionat independente!; vezi
lectiile anterioare!) = E(jh Q X) . Apoi premiul Esscher este AL(Xt+1 X) =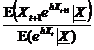 . Numitorul este deja calculat: este E(jh Q X). In ce priveste
numaratorul , folosim aceeasi metoda: Dar
. Numitorul este deja calculat: este E(jh Q X). In ce priveste
numaratorul , folosim aceeasi metoda: Dar ![]() = E(
= E(![]() X) = E(
X) = E(![]() X
) = E(yh Q X
X
) = E(yh Q X
Pentru primele exponentiale nu se pot calcula estimatori liniari de tip Buhlman. Pentru premiile Esscher, acest lucru se poate face insa. Prezentam fara demonstratie urmatoarea formula (sunt calcule analoge celor din capitolele anterioare).
TEOREMA 6.5. Presupunem ca variabilele aleatoare (Xr)r sunt conditionat i.i.d. daca se da Q q. Fie t un numar natural si X = (Xr)1 r t . Atunci estimatorul optim liniar h(X) pentru Esschh(Xt+1 X ) este
h(X) = z*M + (B - z*)C
unde M este media de selectie (X1 + . + Xt)/t iar
B = 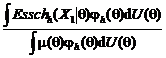
C = ![]()
Esschh(X1 q) = 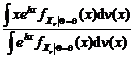 este premiul Esscher calculat in ipoteza ca Q q
este premiul Esscher calculat in ipoteza ca Q q
jh q) = ![]() este functia
generatoare de momente a lui Xr
calculata in ipoteza ca Q q
este functia
generatoare de momente a lui Xr
calculata in ipoteza ca Q q
z* = ![]() unde asteriscul inseamna ca media se
calculeayza fata de probabilitatea r U
unde r q) = const jh q
unde asteriscul inseamna ca media se
calculeayza fata de probabilitatea r U
unde r q) = const jh q
|
Politica de confidentialitate |
| Copyright ©
2025 - Toate drepturile rezervate. Toate documentele au caracter informativ cu scop educational. |
Personaje din literatura |
| Baltagul caracterizarea personajelor |
| Caracterizare Alexandru Lapusneanul |
| Caracterizarea lui Gavilescu |
| Caracterizarea personajelor negative din basmul |
Tehnica si mecanica |
| Cuplaje - definitii. notatii. exemple. repere istorice. |
| Actionare macara |
| Reprezentarea si cotarea filetelor |
Geografie |
| Turismul pe terra |
| Vulcanii Și mediul |
| Padurile pe terra si industrializarea lemnului |
| Termeni si conditii |
| Contact |
| Creeaza si tu |